






需求背景:
资源监控和告警
1. 可以监控 CPU 内存 磁盘 等系统指标的占用
2. 可以设定阈值,对异常的情况进行告警,如磁盘占用超过90%告警等
方案:Prometheus+Grafana
Prometheus
Prometheus是一个具有活跃生态系统的开源系统监控和告警工具包。一言以蔽之,它是一套开源监控解决方案。
Grafana
Grafana是一个仪表盘,用来展示。
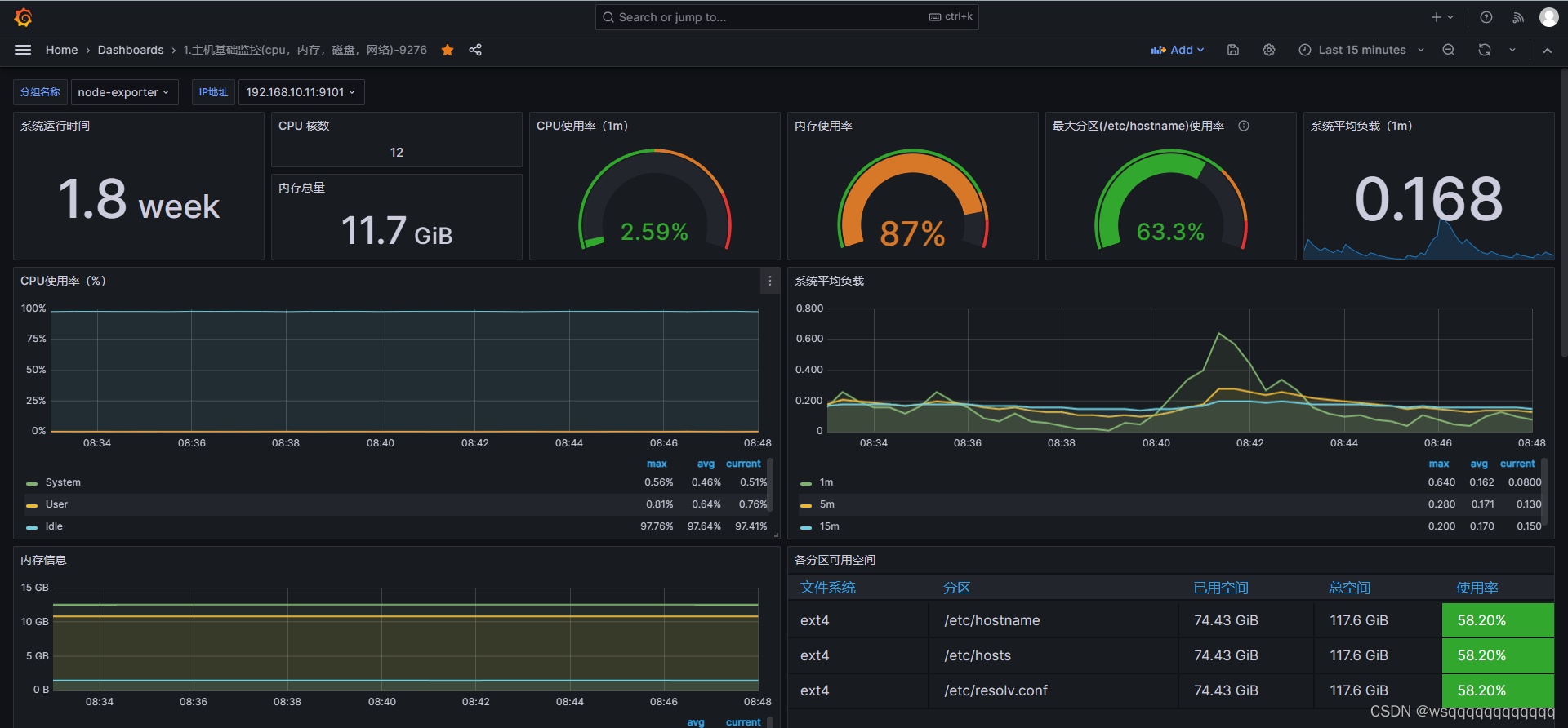
开搞!!!
一、Springboot整合
需要两个引入两个依赖,如下:(请注意选择正确的版本,最后会提到)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<version>1.1.4</version>
</dependency>application.yml或bootstrap.yml配置文件如下:
#Prometheus springboot监控配置
management:
endpoints:
web:
exposure:
include: '*'
metrics:
export:
prometheus:
enabled: true
tags:
application: ${spring.application.name}二、docker部署prometheus+grafana
使用docker-compose方式部署,比较方便。部署包结构如下:

docker-compose.yml配置文件,如下:
version: '3.3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
ports:
- "9890:9090"
volumes:
- "./config/prometheus.yml:/etc/prometheus/prometheus.yml"
- "./config/node_exporter_rules.yml:/etc/prometheus/node_exporter_rules.yml"
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9101:9100"
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
volumes:
- "./config/alertmanager.yml:/etc/alertmanager/alertmanager.yml"
ports:
- "9093:9093"
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- "3000:3000"
networks:
default:
name: my-bridge
node_exporter:用于监控Linux系统的指标采集器。
常用指标:CPU、内存、硬盘、 网络流量、文件描述符、 系统负载、系统服务
配置指标告警规则文件node_exporter_rules.yml
# 服务器资源告警策略
groups:
- name: 服务器资源监控
rules:
- alert: 内存使用率过高
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 90
for: 5m # 告警持续时间,超过这个时间才会发送给alertmanager
labels:
severity: 严重告警
annotations:
summary: "{{ $labels.instance }} 内存使用率过高,请尽快处理!"
description: "{{ $labels.instance }}内存使用率超过90%,当前使用率{{ $value }}%."
- alert: 服务器宕机
expr: up == 0
for: 3m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 服务器宕机,请尽快处理!"
description: "{{$labels.instance}} 服务器延时超过3分钟,当前状态{{ $value }}. "
- alert: CPU高负荷
expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"
description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "
- alert: 磁盘IO性能
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."
- alert: 网络流入
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."
- alert: 网络流出
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
- alert: TCP连接数
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: 严重告警
annotations:
summary: " TCP_ESTABLISHED过高!"
description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
for: 1m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."alertmanager.yml告警通知文件,可使用qq等邮箱、短信、企业微信通知告警消息。下面示例使用邮件或企业微信通知
global:
smtp_smarthost: 'mail.xx.com:465'
smtp_from: 'sys@xx.com'
smtp_auth_username: 'sys@xx.com'
smtp_auth_password: 'oCeLfAsISpeaViDeSYCHERoOMaManger,%,48'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 24h
receiver: 'wechat'
# 警报接收者
receivers:
- name: 'mail'
email_configs:
- to: 'sys@gurenkai.com'
- name: 'wechat'
wechat_configs:
- corp_id: 'id'
agent_id: 1000030
api_secret: 'Cjyv9QzdPIbu05xXv_xxxxxxxx'
to_user: 'wxuserid'
send_resolved: true
prometheus.yml
# 全局配置
global:
scrape_interval: 15s # 全局默认的数据拉取间隔
evaluation_interval: 15s # 全局默认的规则(主要是报警规则)拉取间隔
# scrape_timeout:10s # 全局默认的单次数据拉取超时,当报context deadline exceeded错误时需要在特定的job下配置该字段
# 告警插件
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# 告警规则
rule_files:
- "node_exporter_rules.yml"
# - "second_rules.yml"
# 采集配置
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node-exporter"
static_configs:
- targets: ["192.168.10.11:9101"]
- job_name: "alertmanager"
static_configs:
- targets: ["192.168.10.11:9093"]
- job_name: "spring-boot"
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
["192.168.10.111:8080","192.168.10.111:9355","192.168.10.111:9542","192.168.10.111:9300","192.168.10.111:9203","192.168.10.111:9892","192.168.10.111:9330","192.168.10.111:9322"]#多个服务模块对应端口使用方式如下:
1、将文件夹放到服务器,如:/data目录下
2、切换到docker-compose.yml文件的目录,执行docker-compose up -d命令,开始部署
三、验证
访问prometheus,点击“Status-Targets”,看对应端点的state是否为up状态。为up说明已成功监控,其他状态说明有问题,需排查。

点击Alert,可以看到我们配置的告警通知。如果被监控的目标超过阈值,则会按规则发送通知。

访问Grafana
配置data source,选Promethus

配置刚才能访问的prometheus地址
到Dashboards导入一个仪表盘模板:12856、12377(含温度指标)
到这里就部署整合完毕了。
参考:(32条消息) Prometheus+SpringBoot应用监控全过程详解_普通网友的博客-CSDN博客
(33条消息) docker-compose部署Prometheus监控springboot_it噩梦的博客-CSDN博客
总结问题:
部署过程中遇到的问题:

state为down,spring对应的端点/actuator/prometheus为404

原因:主要是spring-boot版本和micrometer版本没有对应上
参考:Springboot 集成 micrometer(actuator/prometheus) 接口报 404_spring_kainx-华为云开发者联盟 (csdn.net)
















 3032
3032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









