







Kafka介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
集群架构
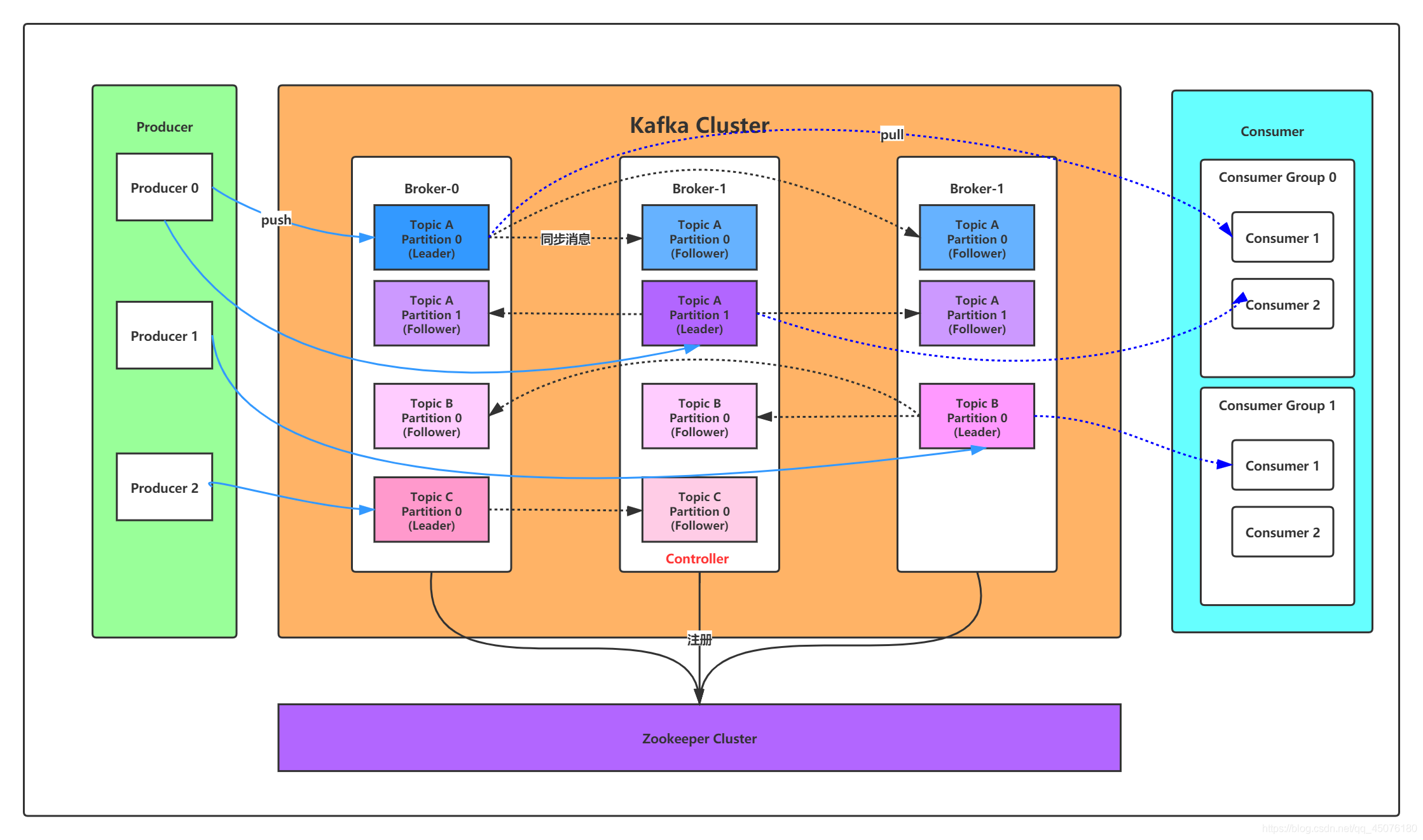
kafka集群整体运作如上图所示,来看一下kafka的相关术语
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群Topic |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topicProducer |
| Producer | 消息生产者,向Broker发送消息的客户端Consumer |
| Consumer | 消息消费者,从Broker读取消息的客户端ConsumerGroup |
| ConsumerGroup | 消费者组,每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息Partition |
| Partition | 分区,物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
Kafka主要特点
- 同时为发布和订阅提供高吞吐量。Kafka 每秒可以生产约25万条消息(50MB),每秒处理55万条消息(110MB)。
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费(例如ETL)以及实时 应用程序。通过将数据持久化到硬盘以及replication, 以防止数据丢失。
- 分布式系统,易于向外扩展。所有的Podcer. Broker 和Consumer都会有多个,均为分布式的,无须停机即可扩展机器。
- 消息被处理状态是在Consumer端维护,而不是由Server端维护,当失败时能自动平衡。
- 支持online (在线)和offline (离线)的场景。
设计理念
Kafka之所以和其他绝大多数信息系统不同,是由下面这几个为数不多的比较重要的设计理念 :
- Kafka 在设计之时,就将持久化消息作为通常的使用情况进行考虑。
- Kafka 主要的设计约束是吞吐量而不是功能。
- 和Kaka有关的那些已经被使用了的状态信息保存为数据消费者(Consumer)的一部分,而不是保存在服务器之上。
- Kafka是一种显式的分布式系统。它假设数据生产者(Producer)。代理(Broker)和数据消费者(Consumer) 分散于多台机器之上。
ZooKeeper在Kafka的作用
ZooKeeper在Kafka的作用如下:
- 无论是Kafka集群还是Producer 和Consumer, 都靠ZooKeeper来保证系统可用性,集群保存一些meta元信息。
- Kafka使用ZooKeeper作为其分布式协调框架,很好地将消息生产、消息存储、消息消费的过程结合在一起。
- 借助ZooKeeper的作用,Kafka能够将生产者、消费者和Broker在内的所有组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均街。
- Kafka 增加和减少服务器都会在ZooKeper节点上触发相应的事件,Kafka系统会捕获这些事 件,进行新一轮的负载均街,客户端也会捕获这些事件来进行新一轮的处理。
Kafka在ZooKeeper的执行流程
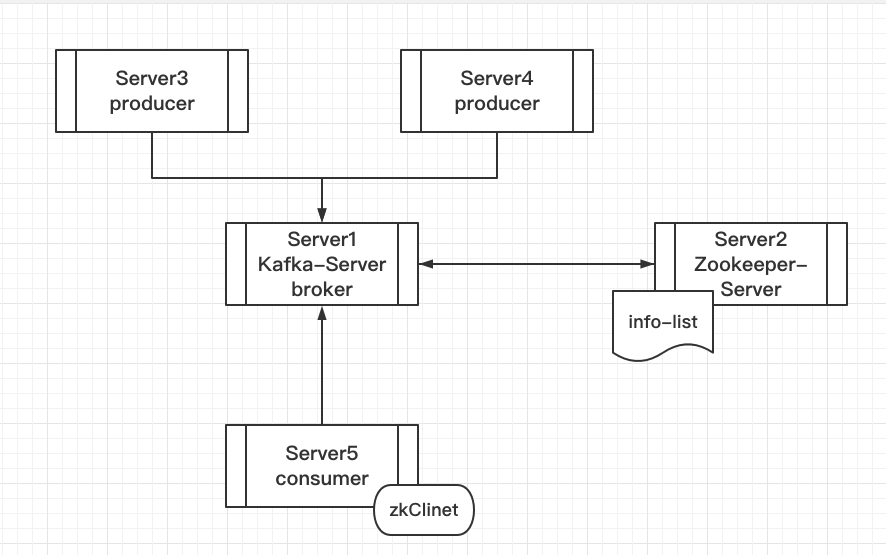
- Server1就是Kafka的Server, 因为Producer 和Consumer 都要使用它,Broker主要还是作为存储使用。
- Server2 是ZooKeeper的Sever端,记录了各个节点的IP、端口等信息。
- Server3、Server4、Server5的共同之处就是都配置了zkClient,更明确地说就是运行前必须配置ZooKeeper的地址,这之间的连接都需要ZooKeeper来进行分发。
- Server1和Server2可以放在一台机器上,页可以分开放。Zookeeper也可以配成集群,目的是防止某一台Zookeeper服务器异常宕机,出现单点故障。
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











