






Mysql的运行顺序
from>where>group by>having>select>order by>limit
Select from语句
去重:select distinct ziduan from distinct要跟在select后
select distinct ziduan1,ziduan2 from distinct 对ziduan1,ziduan2组合数据去重,即两个字段数据都一样的两条数据中去除一条数据
select ziduan1, distinct ziduan2 from distinct #会报错,跟在select后
select中用计算字段 SELECT name,gdp,population,gdp/population 人均gdp from world
SELECT name,gdp,population,(gdp/population)*gdp 人均gdp from world *不能丢
Where语句:
进行筛选选出合适的条件,SELECT name FROM world WHERE population > 200000000
不等于 <>或!= between… and…(包含端点两值)
如果是字符串需要加英文引号
筛选出三个国家的人口数:
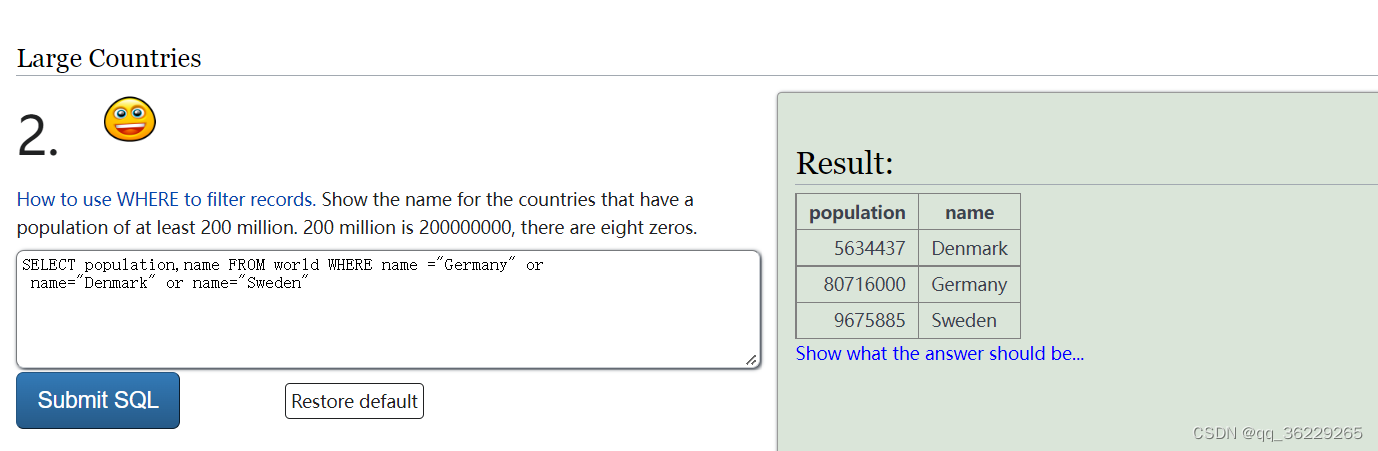
1.SELECT population,name FROM world WHERE name ="Germany" or
name="Denmark" or name="Sweden" #注意每个条件前面都要加“字段名称=”,否则出来的只有第一个条件的结果
Wrong: 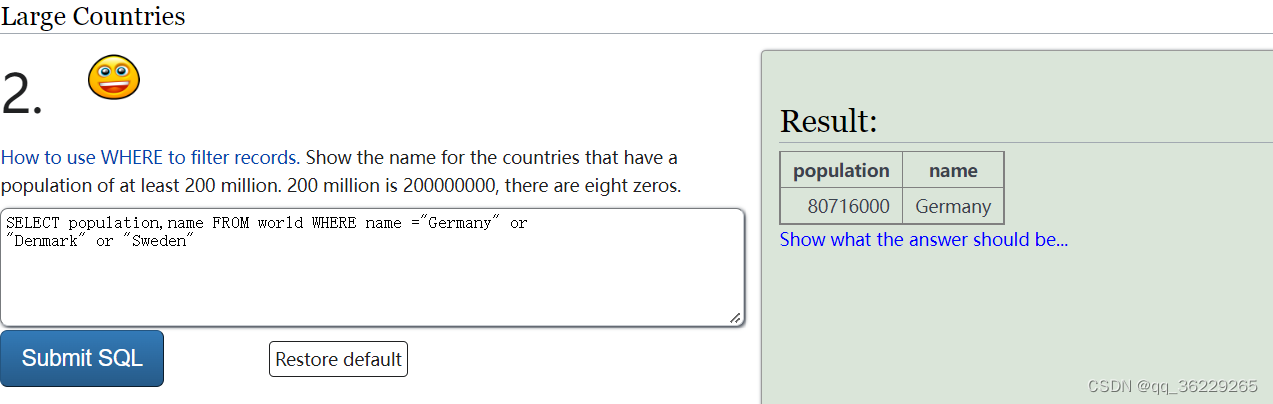
2. SELECT population,name FROM world WHERE name in ("Germany","Denmark","Sweden")
In+(1,2,3)筛选出包含条件一二三的数据
模糊查询:where 字段名 like '通配符+字符'

%:代表任意多个字符;_代表一个字符
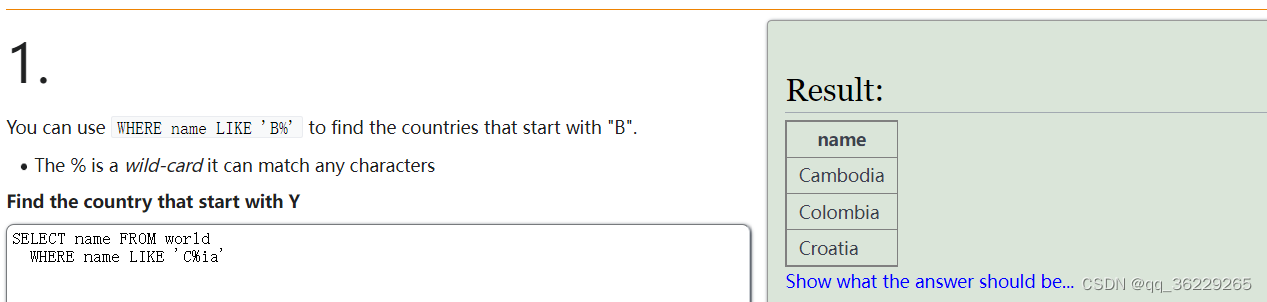
查询以C开头,ia为结尾的国家名称:
And和or并列出现,and优先级高于or,先运行and后运行or
(A and B) or (C and D)
In可以和or互换,between and可以和>=<and>互换
查询国家名称中包含aeiou五个字母且不含空格的国家。
- select name from world where name like'%a%' and name like'%e%' and name like'%i%' and name like'%o%' and name like'%u%' and name not like'% %'
Order by:放在语句最后
排序:默认升序 如order by name des,subject 为先按照姓名降序排序再按照学科升序排序

题目:查询1984年所有获奖者的姓名和奖项。结果将诺贝尔化学奖和物理学奖排在最后,然后按照奖项排序,再按照获奖者姓名排序
SELECT winner, subject from nobel where yr=1984 order by subject in ('chemistry','physics'),subject,winner 此处,subject in (A,B),括号里的A和B被默认复制为1,括号外的subject字段其它数据默认为0,然后再升序排序,将0排在前面,1排在最后从而实现将A,B排在最后的效果
Limit:
最后写limit n 如limit 3表示筛选出排名前三的,与order by 排序配合使用
若想要筛选出第四到第七的,limit x , n(表示从第x+1行开始往下运行n行,如第四行到第七行即为limit 3,4
Group by:
Group by 某字段,进行聚合运算.常常和聚合函数连用
如求非洲大陆的人口总数,select sum(population) from world where continent = “Africa”
计算总行数 select count(*) from world 如果count某字段,若该字段有空值则自动跳过空值可能使结果不准确
注意,sum,avgmax,min函数必须指定字段进行运算,无法使用通配符*且都会忽略空行
Group by起聚合作用有点相当于数据透视表
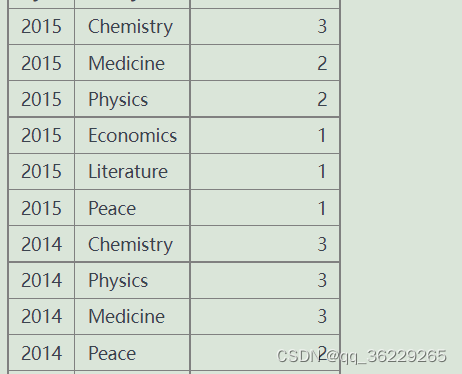
查询2013-2015年每个科目的获奖人数,结果按年份从大到小,人数从大到小排序。
select yr,subject,count(winner) from nobel where yr between 2013 and 2015 group by yr,subject order by yr desc,count(winner) desc 每年每个科目两个分组两个group by
使用group by时,select后的字段只能写group by中出现过的字段和聚合函数,否则就会出现错误(再group by运行后表的结构就固定了,没法弄出没有的字段来)
select sum(population) from world where continent = “Africa” 若此处想添加非聚合字段,如select name,sum(population) from world where continent = “Africa”则必须和group by联合使用,即非聚合字段和聚合字段同时出现在select后必须和group by一起。
Having:聚合后筛选。即在group by之后运行。Where是在聚合之前筛选。
只能用聚合字段和group by的字段,将聚合以前的字段用where筛选,聚合以后的字段用having筛选
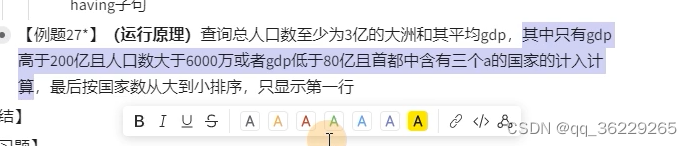
select continent,avg(gdp) from world where gdp > 20000000000 and population >60000000 or gdp<8000000000 and capital like "%a%a%a%" group by continent having sum(population) >=300000000 order by count(name) desc limit 1
#正确理解运行顺序
基本常见函数:

浅浅了解一下
窗口函数:
运行原理
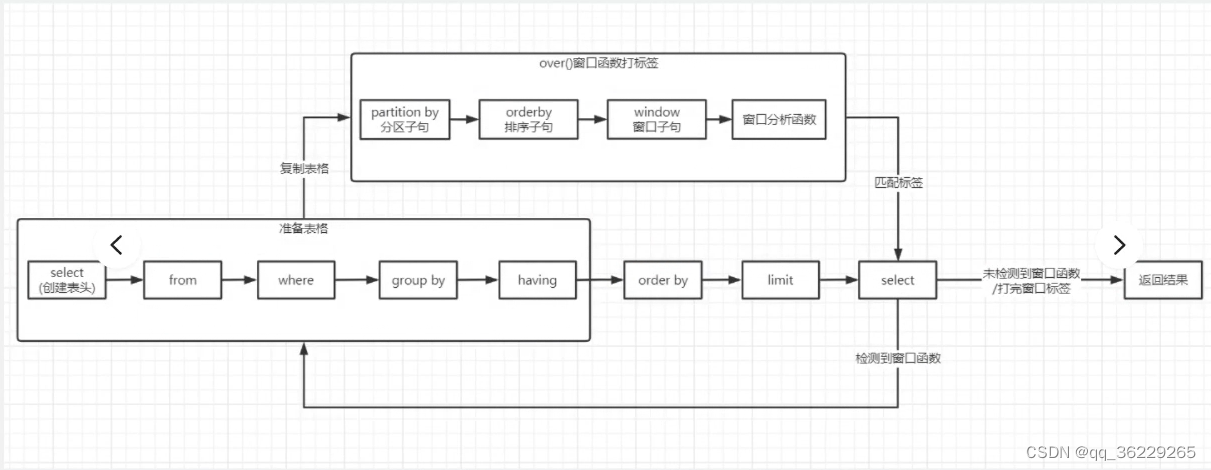
窗口函数会复制一个表格,利用partition by 重新分区,order by赋予名词之后将结果匹配回原表格,不会影响原表格的排序。

窗口函数rank()over()是在指定分区(partition by)对指定字段排序(order by)然后依次赋予排名的函数。窗口函数跟在select子句后。
本题:select yr,party, votes,rank()over(partition by yr,order by votes desc) as posn from ag where constituency = 'S14000021' order by party,yr 以年为分区,以选票多少排序,选票高的赋值1,往下类推。若没有partition by默认对整个表格排序。
Rank() 1 1 34
Dense_rank() 1 1 2 3
偏移分析函数语法:
Lag(字段名,偏移量)over(partition by 字段名 order by 字段名desc/asc)
对于每一行来说都向上取一行
Lead(字段名,偏移量)over(partition by 字段名 order by 字段名desc/asc)
对于每一行来说都向下取一行

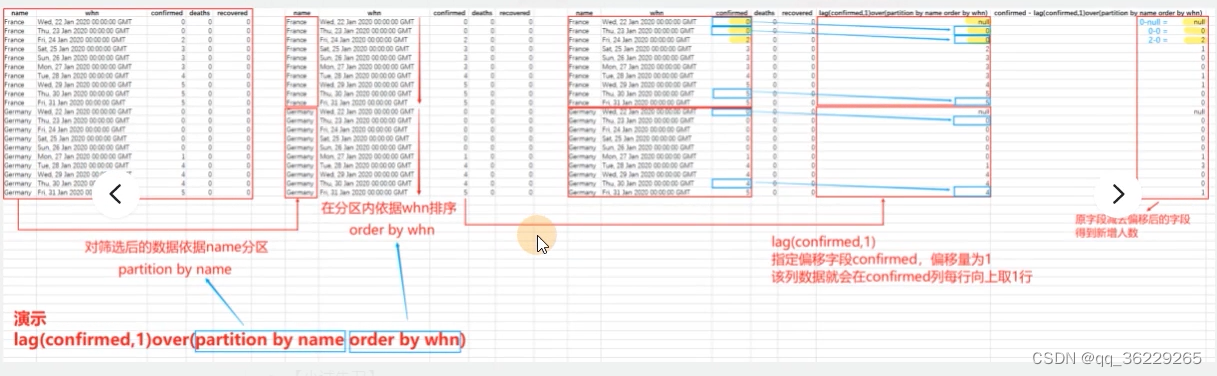
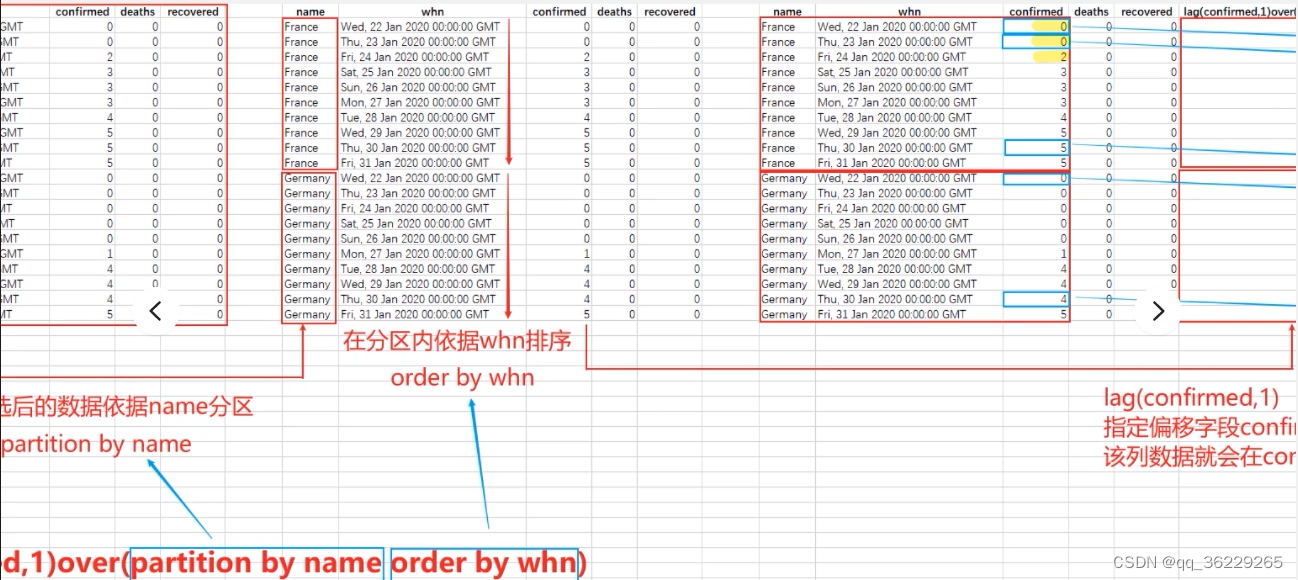
Select name,date_format(whn,'%y-%m-%d')date,confirmed 当天截止时间累计确诊人数,lag(confirmed,1)over(partition by name order by whn) 昨天截止时间累计确诊人数 from covid where name in ('France','Germany') and month(whn)=1 order by whn
Date_format()将whn字段转化为日期格式。Lag(confirmed,1)取confirmed字段的上一行
剖析题目意思,求每天新增确诊只需要用今天的减去前一天的,即按照国家分区后按照日期从小到大排序,再用当前行confirmed减去前一行confirmed即可。
- 查询意大利每周新增确诊数(显示每周一的数值 weekday(whn) = 0)
- 最后显示国家名,标准日期(2020-01-27),每周新增人数
- 按照更新时间排序
SELECT name, DATE_FORMAT(whn,'%Y-%m-%d'), (confirmed-LAG(confirmed, 1) OVER (PARTITION BY name ORDER BY whn)) FROM covid
WHERE name = 'Italy'
AND WEEKDAY(whn) = 0 AND YEAR(whn) = 2020
ORDER BY whn
每周新增人数,用本周一确诊人数减上周一确诊人数。这里做了一个非常巧妙的处理,用weekday(whn)=0,只筛选出每周一的数据再用lag(confirmed,1)就能写出上周一人数。

















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









