






- 现象
Prometheus所有的监控项在页面上均显示无数据,查看Prometheus pod的日志发现,该日志报“out of bounds”错误:

- 排查
看到out of bounds,第一感知是Prometheus tsdb存满了,导致数据无法存储。但是,Prometheus设置了storage.tsdb.retention.time,定期会去清理,理论上是不应该出现tsdb存满的情况。
接下来进入Prometheus pod的tsdb存储路径看下,发现其block和wal目录的更新时间全部为2029年。然而查看当前服务器时间却是与本地同步的。所以现在可以确认的是之前服务器时间是被修改过的。
到此,结合Prometheus tsdb存储原理也就能解释清楚为什么出现了“out of bounds”的原因了。示意图如下所示:
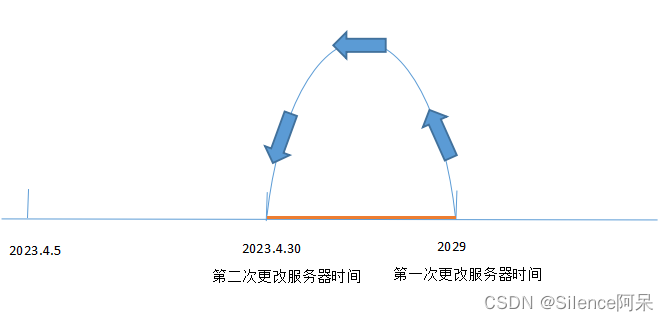
也就是说,第一次更改服务器时间为2029年,那么tsdb时间序列即从当前时间直接跳转到2029年开始存储,如果一直保持这样下去,也不会出现什么大问题,顶多时间序列会出现断裂,即当前时间序列对应的metric查出来是no data;然而,又把服务器时间与本地做了同步,时间序列从2029年一下子回到了2023年,那么当每次向tsdb存数据的时候,发现最近一次的时间序列大于当前的时间序列,无法满足tsdb递增存储时间序列的原则。所以报了"out of bounds"的错误。
Prometheus的监控项,是基于当前时间去查询,那当然查出来的是no data,因为当前时间序列对应的metric根本没有存入到tsdb中。第一次更改服务器时间,时间序列断裂,当前时间序列对应的metric是no data。第二次更改服务器时间后,虽然存的是本地时间,但是存入tsdb失败了,当前时间序列对应的metric仍然是no data;
- 解决方法
上面提到Prometheus tsdb的存储路径下block和wal目录,其中wal(write ahead logging),这个目录是用于metric写入TSDB的Head内存块时,为了防止内存数据丢失先做一次预写日志。当时间序列对应的metric写入Head中的chunk,超过2小时或120样本,即做内存映射,落盘到block中。
为了解决这个问题,把Prometheus pod的tsdb的存储路径下wal目录删除掉,然后把更新时间为非本地时间的block目录删掉。保证tsdb最近一次存储的时间序列不会大于当前的时间序列,即可解决上述问题。
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









