







文章目录
背概念容易,能结合实际串通难,平常调优较少的话 东西比较容易忘记,特此写篇博客进行分析、总结;
手写不易,文章中有博主经过分析、查阅书籍资料得来的结论,尽博主所能保证内容准确性,如有错误 非常欢迎评论指正。
jvm的五大区域基本概念
存放内容:
类对象 (通俗解释:例如Test.java文件中, 我们写的new Test();)
成员变量
特点:线程共享 (所以会有线程安全问题)
存放内容:
基本类型局部变量 (如 method a() 中定义的 int a = 1; a和1都在栈中)
对象引用 (例如Test t = new Test() 的 t 存在栈中)
特点: 线程不共享 (所以局部变量没有线程安全问题)
关于线程不共享引发的思考:
栈,也可以称为线程栈,每个线程执行进来,都会开辟一个独立的线程栈区域
栈帧
栈包含栈帧,一个方法对应一块栈帧区域,如下代码 main方法调用test()方法,
首先开辟main()对应的栈帧,再开辟test()方法的栈帧,
test()方法先执行完,栈帧先释放,main()后执行完,后释放,
这和数据结构中的栈 采用的FILO (frist in last out )保持一致。
// Test.java
public static void main(String[] args){
// t 位于栈 , new Test()位于堆
Test t = new Test();
int res = t.test();
System.println.out(res);
}
public int test(){
// a ,1 位于栈
int a = 1;
int b = 2;
int c = a+b;
return c;
}
拓展: 什么时候会引起Stack Overflow 栈溢出?
官话:
如果线程请求分配的栈容量超过java虚拟机栈允许的最大容量的时候,
java虚拟机将抛出一个StackOverFlowError异常
理解: 调用的方法过多(栈帧过多),不断压栈,直到超出了栈容量的时候 就会抛出该异常,
所以这也是为什么递归容易栈溢出,因为递归在不断的重复调用方法。
栈帧又包含以下几部分:
1. 局部变量表 : 局部变量赋值
2. 操作数栈 : 数据运算临时存储空间
3. 动态链接: 其它代码,例如test()方法中的打印语句
4. 方法出口 方法执行完后,返回主方法
例如 int a = 1;
流程: 1 压入操作数栈 , a位于局部变量表,
接着 1 出栈,给局部变量表分配的空间赋值
我们可以借助jdk自带的工具命令 : javap -c xxx.class > xx.txt 进行反汇编,
打开xx.txt 观察指令,去oracle官方查阅指令手册分析整个过程
方法句柄
博主有另外一篇博客专门介绍了,方法句柄可以理解为方法地址的指针。
-
本地方法栈
调用native方法的栈内存 即通过JNI (jna.jar包) 调用dll的方法,线程私有, 同样是一个后入先出栈, 本地方法栈会抛出 StackOverflowError 和 OutOfMemoryError 异常 -
程序计数器
虚拟机字节码指令的地址 即和CPU交互相关 为什么有程序计数器:记录线程被挂起前的一行地址值,多线程切换时 恢复执行 -
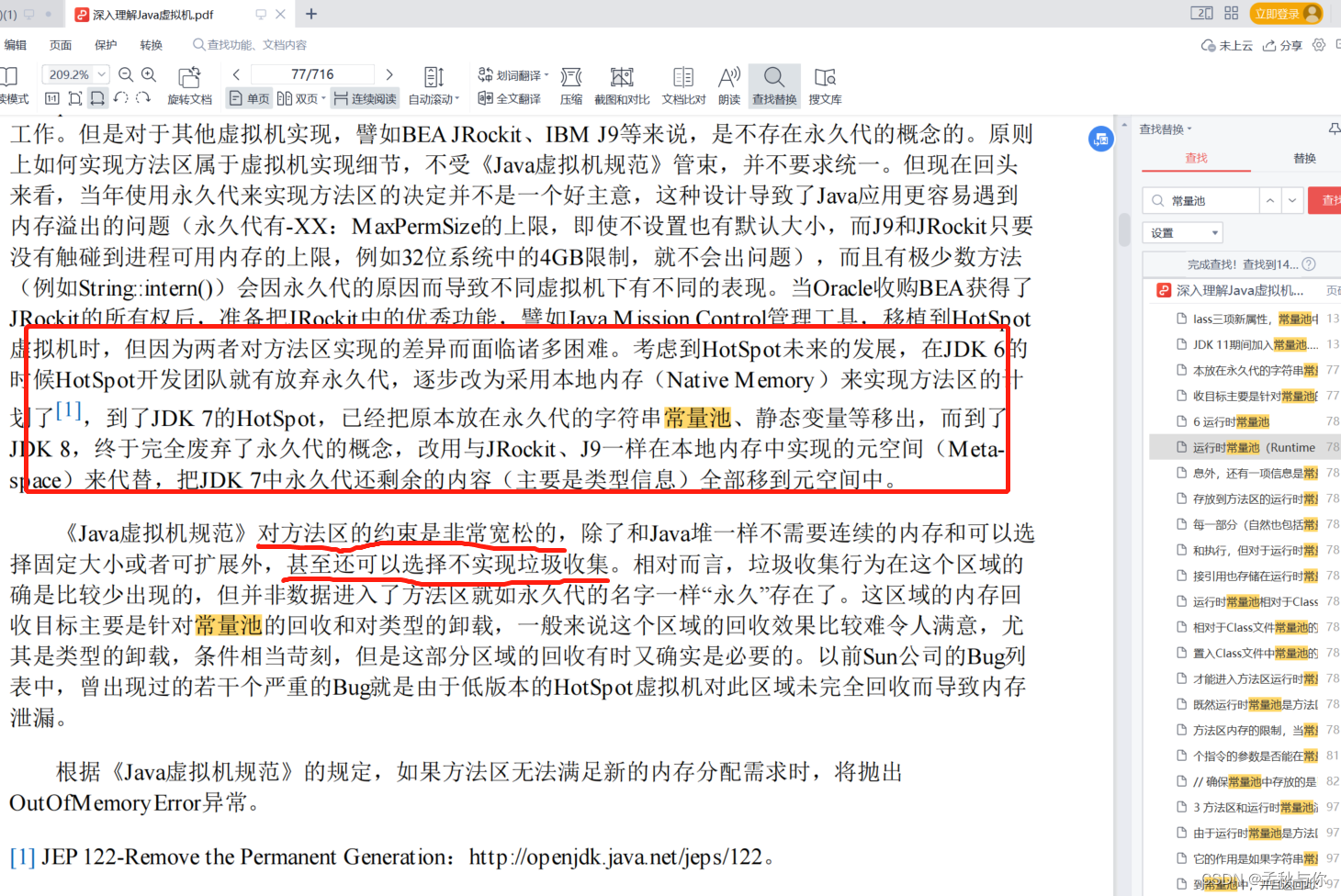
方法区
又叫静态存储区,存放class文件和静态数据,线程共享; 常量池在方法区里面
提到常量池,比较典型的就是String类型,再典型一点的例子 经典面试题:
new String("abc"); 创建了几个对象?
答案:1个或2个 如果"abc"已在常量池,那么只创建一个,
如果不存在常量池 则会先在常量池创建一个对象,再new一个对象到堆中
如果题目换成:
String str = "abc";
str = new String("abc); // 此时new的这步只创建一个对象 因为"abc"已位于常量池
答案就是1 会先去检索常量池是否存在,存在则不再常量池创建新的对象。
GC相关
jvm gc回收的是堆、方法区的对象, jvm调优 基本也是针对堆内存进行调优。
我们首先按照jvm内存 堆内存heap和非堆内存 non-heap的维度来划分
heap区又分为:
Eden Space(伊甸园)、(新生代的一部分)
Survivor Space(幸存者区)、(新生代的一部分)
Old Gen(老年代)。
非heap区又分为:
Code Cache(代码缓存区) :HotSpot Java虚拟机包括一个用于编译和保存本地代码(native code)的内存。
Perm Gen(永久代)/ Metaspace (元空间)(JDK1.8之后被元空间替代);
Jvm Stack(java虚拟机栈 也就是上文说的栈);
Local Method Statck(本地方法栈);
程序计数器内存较小 几乎可以忽略不计 所以这种划分中 基本也看不到它的身影。
堆内存包含 新生代(new ),老年代 (tenured ),
需要注意的是 不包括永久代 (perm), 永久代是方法区的一种实现
tips:
(新生代、年轻代、new、Young Generation 是一个意思;
年长代,老年代、tenured 、old gen是一个意思 。
因为翻译不同 可能你在不同地方看到不同的词汇 会比较懵)
新生代(new)
新生代包括 伊甸园区 (PS Eden Space) 和 幸存区(PS Survivor Space)
PS Eden Space:
JVM年轻代的伊甸园区,当一个对象new 出来后会在Eden Space 。
直到GC到来,GC会逐一问清楚每个对象是否存在引用,
每个对象是gc roots ,进入Survivor Space(幸存区)没有引用将被kill。
PS Survivor Space:
JVM年轻代的幸存区,用于保存在eden space内存池中经过垃圾回收后没有被回收的对象,
幸存区的对象可以存活一段时间。 幸存区有2个,伊甸园 :幸存区1 : 幸存区2 的大小推荐为8:1:1
GC会定期(可以自定义)会对这些对象进行访问,
如果该对象的引用不存在了将被kill,
一直存在引用的(如果分代次数超过15,包括大对象),将被转移到老年代。
此外,还有一个对象动态年龄判断机制,例如一批对象 age1 ,age2...,age n 位于某块幸存区时,
且总大小超过该幸存区内存的50%时,会将age > n的对象 直接放入老年代,
这个机制是希望那些可能是长期存活的对象 尽早进入老年代
对象动态年龄判断一般是在minor gc后触发的
老年代(tenured)
幸存区一直存在引用的,或如果分代次数超过15(CMS收集器默认为6 不同收集器可能略有不同),
以及包括大对象,将被转移到老年代。
Q: 为什么默认是15
A:因为age信息存放在对象头的Mark Word中,不论是32位还是64位,这个age都是4个bit,最大值二进制1111=十进制15
元空间(Metaspace)
在jdk1.7开始 部分永久代的数据就迁移到了元空间,在jdk1.8 已取代。
永久代内存位于方法区。
元空间,大部分类元数据都在本地内存中分配。
默认情况下,类元数据只受可用的本地内存限制
(容量取决于是32位或是64位操作系统的可用虚拟内存大小)。
Minor GC
Minor GC是发生在新生代中的垃圾收集,(年轻代和幸存者区域)采用的复制算法;
Full GC
老年代中使用Full GC,采用的标记-清除算法;
老年代满的时候 会进行一次full gc(三大区域都回收)
且会触发stw (stop the world) , 停止线程运行
正常系统一般几天或几周一次full gc
Q: 为什么要设计stw
A: 对象状态一直在变 可能一会是垃圾 一会不是垃圾,所以需要停止运行进行一次回收。
调优目的
知道stw的特性后,我们应该能明白 调优目的其实就是为了减少stw, 因为系统停止运行,给用户的体验是非常不好的。
调优技巧
并发量高时 可以给年轻代调大空间,否则频繁触发minor gc,最后瞬间没执行完的变量会进入幸存区,幸存区一满进入老年代,老年代过段时间可能就满了 则会频繁触发full gc。
并发量比较大时,结合业务分析,预估一批对象占用大小,不会超过每个幸存区内存的一半。
在jdk9后,默认开始使用G1垃圾收集器,不等到用满再gc ,
分块回收,因为gc时间长 可能导致客户端连接超时;
jdk自己本身就帮我们调优程度提升了一个台阶
常用jvm参数及默认大小
-Xms 初始堆大小,默认物理内存的1/64 -Xms512M
-Xmx 最大堆大小,默认物理内存的1/4 -Xms2G
-Xmn 新生代内存大小,官方推荐为整个堆的3/8 -Xmn512M
-Xss 线程堆栈大小,jdk1.5及之后默认1M,之前默认256k -Xss512k
-XX:NewRatio=n 设置新生代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:NewRatio=3
-XX:SurvivorRatio=n 年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:8,表示Eden:Survivor=8:1:1,一个Survivor区占整个年轻代的1/8 -XX:SurvivorRatio=8
-XX:PermSize=n 永久代初始值,默认为物理内存的1/64 -XX:PermSize=128M
-XX:MaxPermSize=n 永久代最大值,默认为物理内存的1/4
如 -XX:MaxPermSize=256M
-verbose:class 在控制台打印类加载信息
-verbose:gc 在控制台打印垃圾回收日志
-XX:+PrintGC 打印GC日志,内容简单
-XX:+PrintGCDetails 打印GC日志,内容详细
-XX:+PrintGCDateStamps 在GC日志中添加时间戳
-Xloggc:filename 指定gc日志路径 如 -Xloggc:/data/jvm/gc.log
-XX:+UseSerialGC 年轻代设置串行收集器Serial
-XX:+UseParallelGC 年轻代设置并行收集器Parallel Scavenge
-XX:ParallelGCThreads=n 设置Parallel Scavenge收集时使用的CPU数。并行收集线程数。如 -XX:ParallelGCThreads=4
-XX:MaxGCPauseMillis=n 设置Parallel Scavenge回收的最大时间(毫秒)
如: -XX:MaxGCPauseMillis=100
-XX:GCTimeRatio=n 设置Parallel Scavenge垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) -XX:GCTimeRatio=19
-XX:+UseParallelOldGC 设置老年代为并行收集器ParallelOld收集器
-XX:+UseConcMarkSweepGC 设置老年代并发收集器CMS
-XX:+CMSIncrementalMode 设置CMS收集器为增量模式,适用于单CPU情况。
-XX:MaxTenuringThreshold 设置晋升到老年代的年龄阈值 例如 -XX:MaxTenuringThreshold=15
工具使用
jdk自带命令查看堆栈信息:
jcmd -l 查看当前所有虚拟机及pid
jmap -heap pid 查看pid信息
jstack pid 查看线程状态信息
jstat -gc pid 统计gc信息
或直接jdk路径下jconsole 可视化查看
arthas 使用
- java -jar arthas-boot.jar
- 输入(项目)顺序号 按下回车
- 连接成功
命令
thread -b 检查死锁线程
jad 全路径名 反编译 如:jad com.xx.cotroller.TestContrlloer 按下回车
retransform 替换字节码 如 retransform C:/Users/Administrator/desktop/demo/ThreadPoolController.class (自动寻找替换名字相同的类)
String常量池的存储位置分析及GC管理
首先有个经典面试题,String a = new String(“abc”); 创建了几个对象, 我们都知道答案为:1个或2个。
博主认为这个问题很无聊,如果有面试官提问,博主希望你能反客为主 吊打面试官。
我们网上搜到的答案:如果常量池中,没有 “abc”, 是两个(new String() 和 “abc”),
如果常量池中已经有"abc” 那么只会创建 new String()一个对象。
于是就有了一个延申:String字符串的存储位置以及是否触发GC。博主的标题并不严谨,不应该是“String常量池的存储位置分析”,应该为"String字符串的存储位置分析", 之所以取这个标题 是为了让大家知道博主分析的内容是什么,如果单纯说字符串存储位置,可能大家联想不到。
我们拿字符串 String str = “xx” 举例,
jdk6(及之前): 位于常量池中,而常量池位于方法区中的永久代中 不会触发GC
jdk7: 常量池移到了堆内存
jdk8: 位于堆内存,原来永久代除了字符串常量池大部分内容都位于元空间中,元空间直接使用本地内存(系统内存),不限于jvm内存,
也就是说 不恶意写代码情况下 元空间基本不会发生内存溢出的问题。
jdk9: 位于堆内存中,可以GC
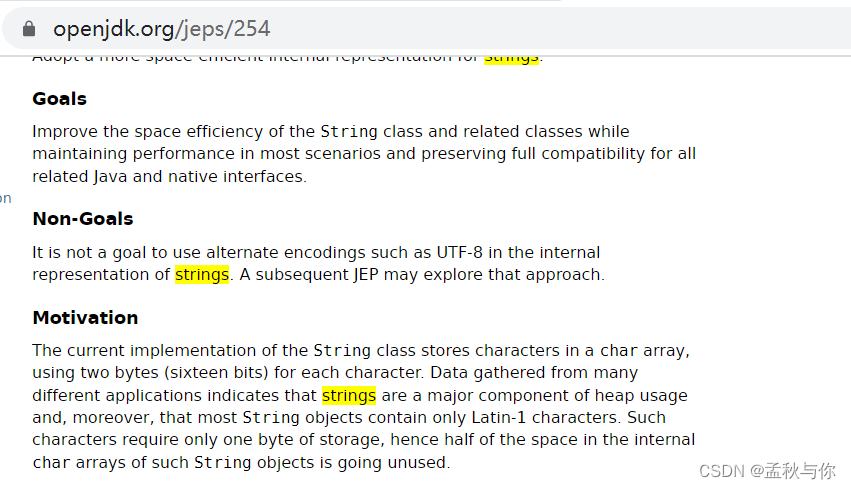
JDK 9 中引入了一种叫做 G1(Garbage First)的垃圾回收器,
可以更好的管理字符串常量,元数据等
(博主看了openjdk 和 oracle gc文档中 都表明 strings 是heap的一部分)
参考资料:深入理解java虚拟机 第二章2.2.5 方法区
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











