






案例是从诸葛老师那边看来的,感觉这些分析的过程,让人受益良多,特此总结并加上一些自己的理解,做篇记录。
这是段从redis获取库存数量,当库存数量大于0时,库存减1 并将新的库存值设置回redis的代码
代码分析并解决超卖问题
Q1: 这段代码有问题吗?

A1: 在高并发的场景下会有问题。
这里有个概念,我们都知道堆是线程共享的,而栈是线程不共享的,我们说栈是线程安全的,但是这个安全是怎么理解呢?我们先来看看下列一段简单的代码:
@Slf4j
@RestController
@RequestMapping("/stack")
public class StackController {
@GetMapping
public void test() {
int a = 0;
for (int i = 0; i < 10; i++) {
a = i;
// 记录a的输出值
log.error(String.valueOf(a));
}
}
}
在这段代码中,我们知道日志中记录从0到9次数都是相等的,一个线程执行下来 那就是各记录一次,根据我们日常开发经验 ,也从不会去怀疑这种写法有什么问题,这就是因为栈内是安全的,带给我们足够的安全感。
接着我们使用jmeter模拟高并发场景:
0秒内访问200次
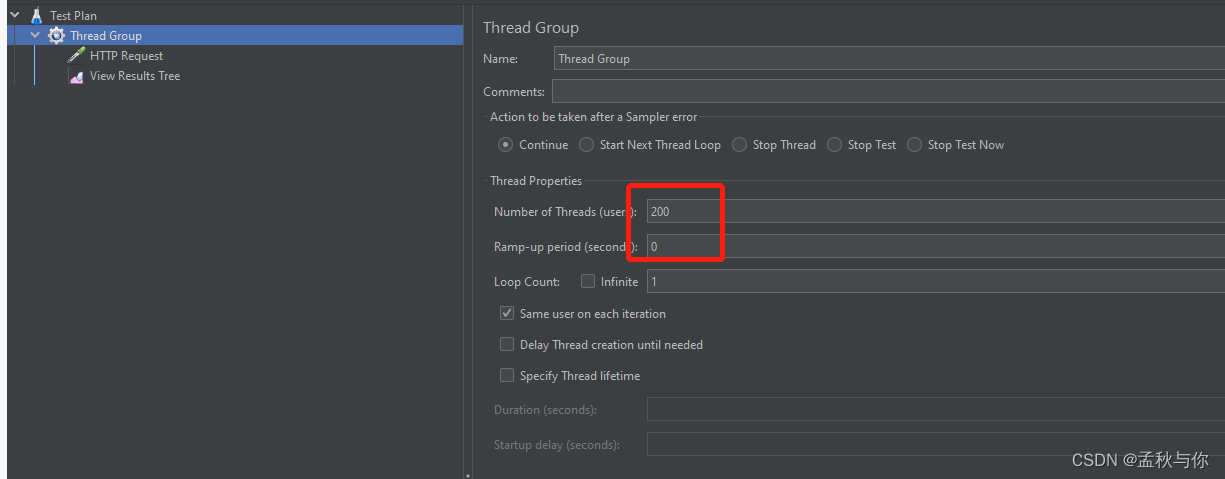
我们将日志结果复制到notepad++中,便于观察:
这个有个notepad++使用的小细节,我们日志格式输出是这样的
(当然 你去修改日志格式也可以)

我们可以在notepad++中使用正则表达式,例如我使用的是
// 第一个 'r'之前的字符
^([^s]*)r
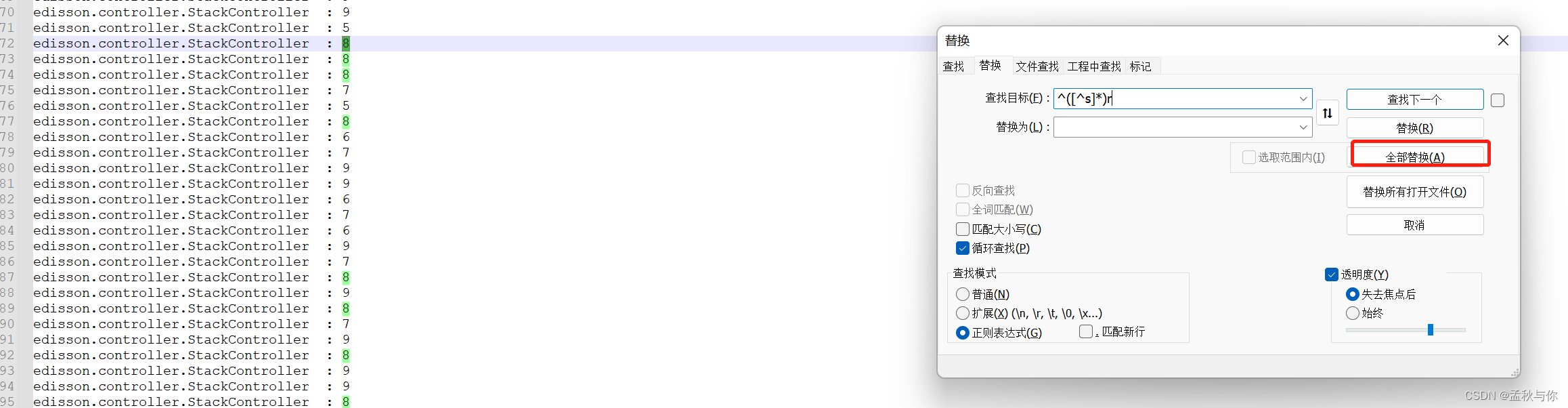
这样就没有多余的其它数字干扰我们
我们从0到9分别计数,发现数量都为200(不一 一截图了 感兴趣可以去自己操作一遍)
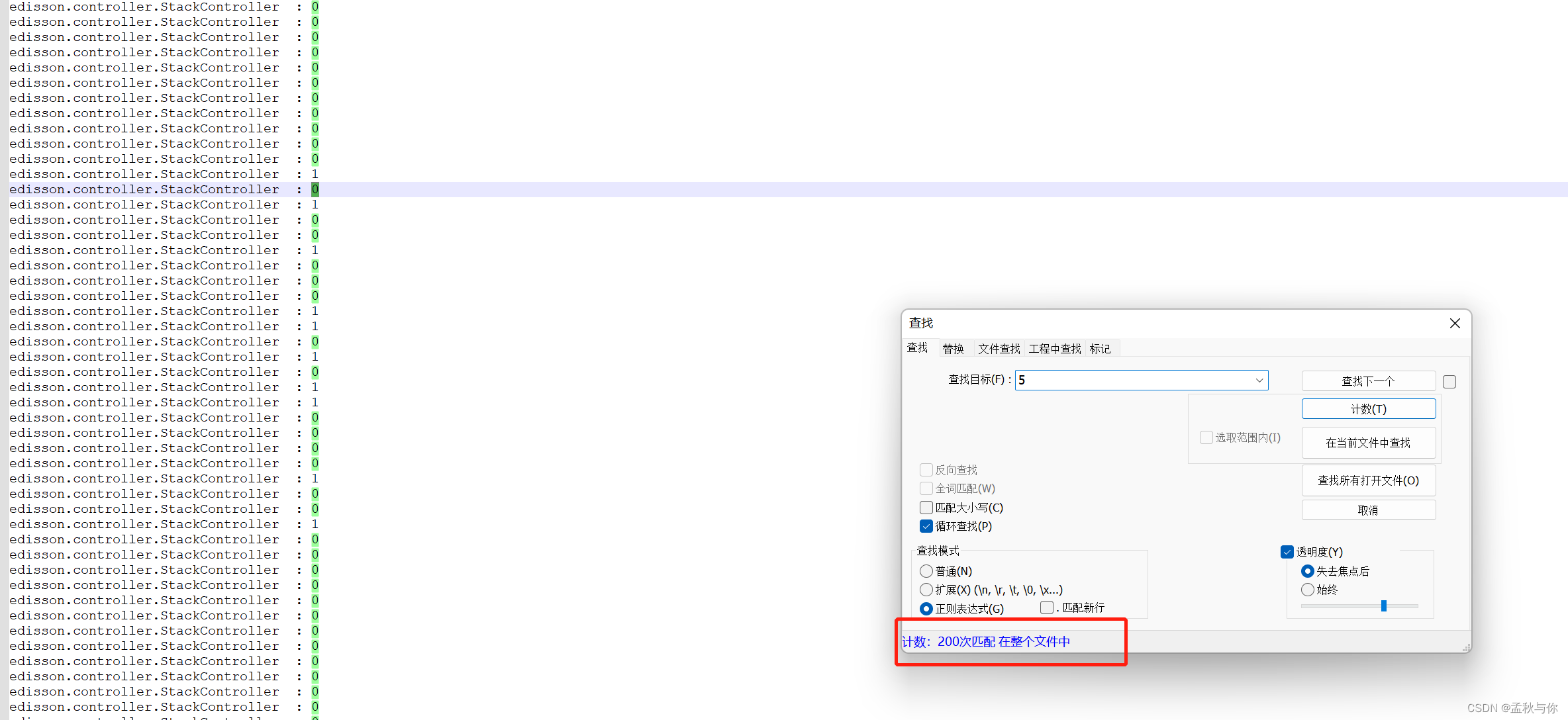
假设线程不是安全的,那么次数就可能出现不等。
我们知道 堆内存是线程共享,不安全的,如果我们将代码改成如下:
@Slf4j
@RestController
@RequestMapping("/stack")
public class StackController {
// 成员变量 位于堆内存
int a = 0;
@GetMapping
public void test() {
for (int i = 0; i < 10; i++) {
a = i;
log.error(String.valueOf(a));
}
}
}
此时计数就出现了不相等的情况,出现了线程安全问题。
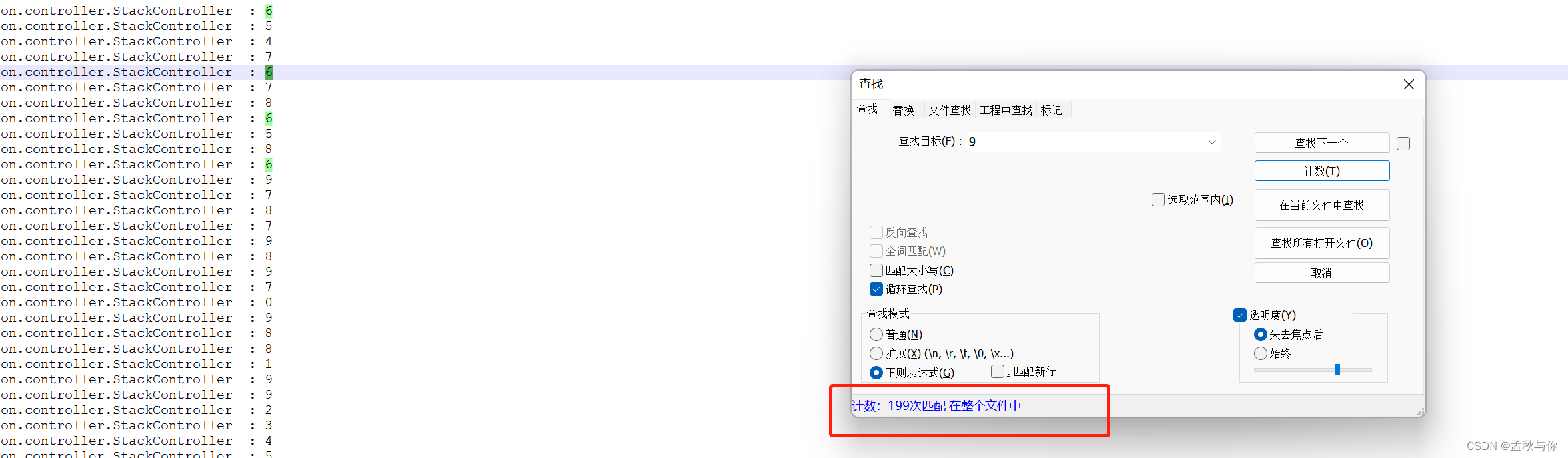
回到一开始的问题,线程安全怎么理解?thread1读到了thread2修改后的值,和我们要的结果产生了偏差。那我们Q1中的代码片段,明明在栈内存中,为什么会有问题呢? 这就只可意会 , 不可言传了~
咳咳,正经分析:
我们假设thread1 和 thread2 同时查询redis,stock都为200,那么realStock都为199, 那么将数据set回redis的时候,明明是2个线程减库存了,值正确应该是198,而不是199。在这个过程中,严格来说是并发安全问题,和上面我们举例的线程安全问题还是有那么点区别的,每个线程它计算的199有错吗?没有错。对它自己来说,结果是正确的,问题就出现在并发场景下,两个结果都没错的线程 set回redis的数值 也是每个线程的库存-1的结果,可惜的是redis需要的正确结果应该是各个线程一共减去了多少库存。
(这个其实很好理解,但是相信同学们都会有这种体验,很容易有的时候陷入误区拔不出来 俗称脑袋转不过弯 就比如 明明是栈 明明说栈是安全的 为什么又不安全了 这是因为涉及到了外部共享资源 恰是因为栈是安全的 导致了外部资源的不安全)
那么我们该怎么解决呢?首先最容易想到的 应该就是加锁了
Q2: 这段代码会有问题吗? (除性能问题外)

A2: 在跨进程中会有问题(分布式场景下),上面代码只能锁同一个jvm。
在分布式环境中,处理跨进程的任务 我们一般都需要借助第三方工具,例如分布式事务中,我们使用seata,seata起到一个调度的功能;例如集群环境中,我们可以使用注册中心 作为一个容器 从而对每次客户端的访问进行分发请求。 同样的,我们要实现分布式锁,那同样的需要借助外部的力量。
redis自带一个命令: setnx (set if not exist),如果存在则不再插入; 区别于set命令插入并替换。
接着将代码稍作修改 如下:
Q3: 这段代码有什么问题?
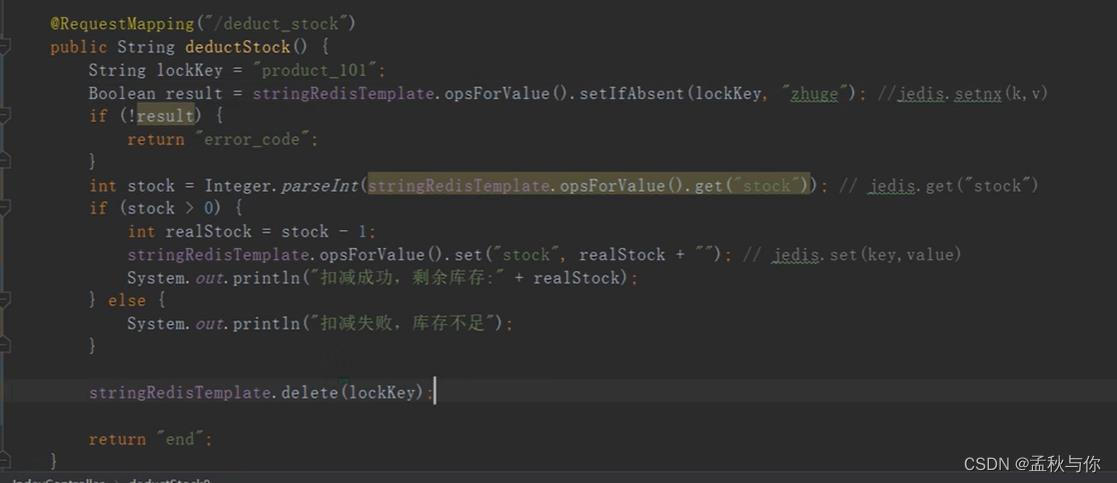
A3:可能出现锁无法释放的问题,在delete执行前,出现了异常,那这个锁就无法删除了。
这个时候,我们或许能想起 在IO流中,我们close方法一定要写在finally中, 这里锁释放也是一样的,我们再将代码修改一下
Q4: 这段代码有什么问题
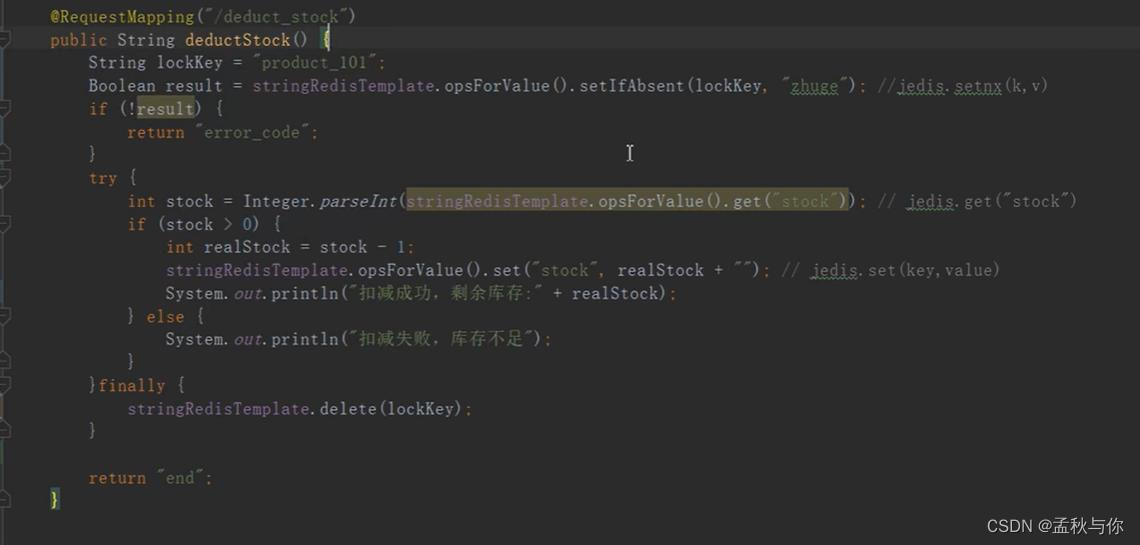
A4: 仍然可能出现锁释放的问题,例如在极端环境下,执行到finally突然服务挂了,那锁就没有成功释放
这个时候我们或许能想到设置超时时间, 这就和java中的 ReenttrantLock 锁,有点类似。如果熟悉阿里规范的同学,或许知道 写ReenttrantLock锁时,规定加锁的业务代码必须写在try catch里面, 锁释放写在finally里面。
Q5: 这段代码有问题吗
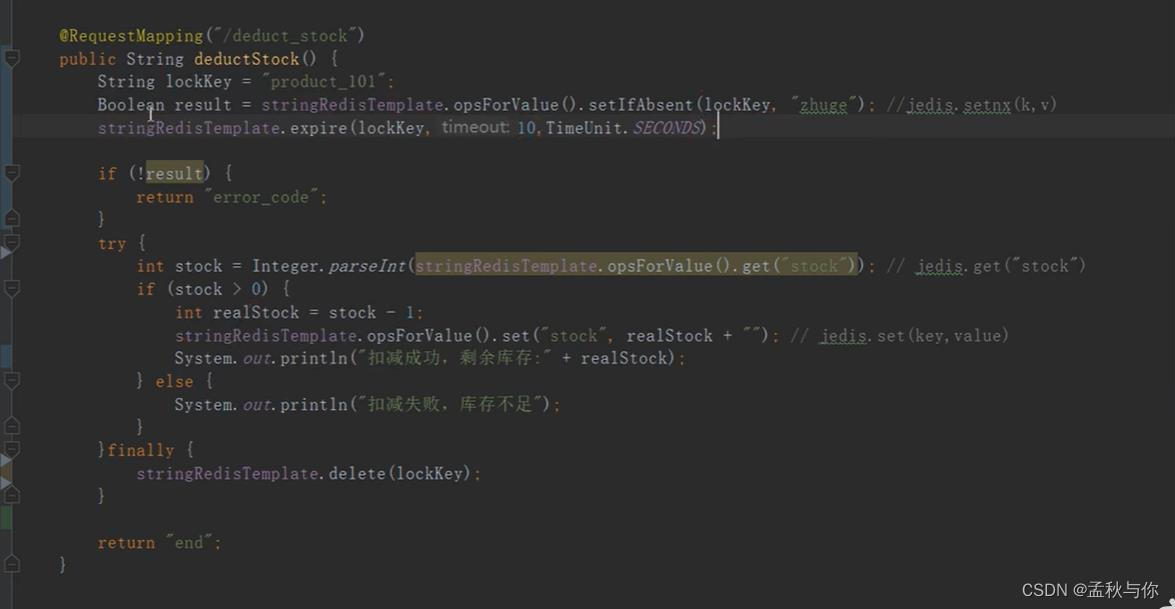
A5: 当代码执行完set,并即将设置过期时间时,如果这时服务挂了,那过期时间就设置失败,和Q4是一样的问题,根本原因在于set和expire不是原子执行的。
那么我们将set和expire原子执行一下,redisTemplate也提供了这个方法,把代码再改造一下
Q6: 这段代码有什么问题?
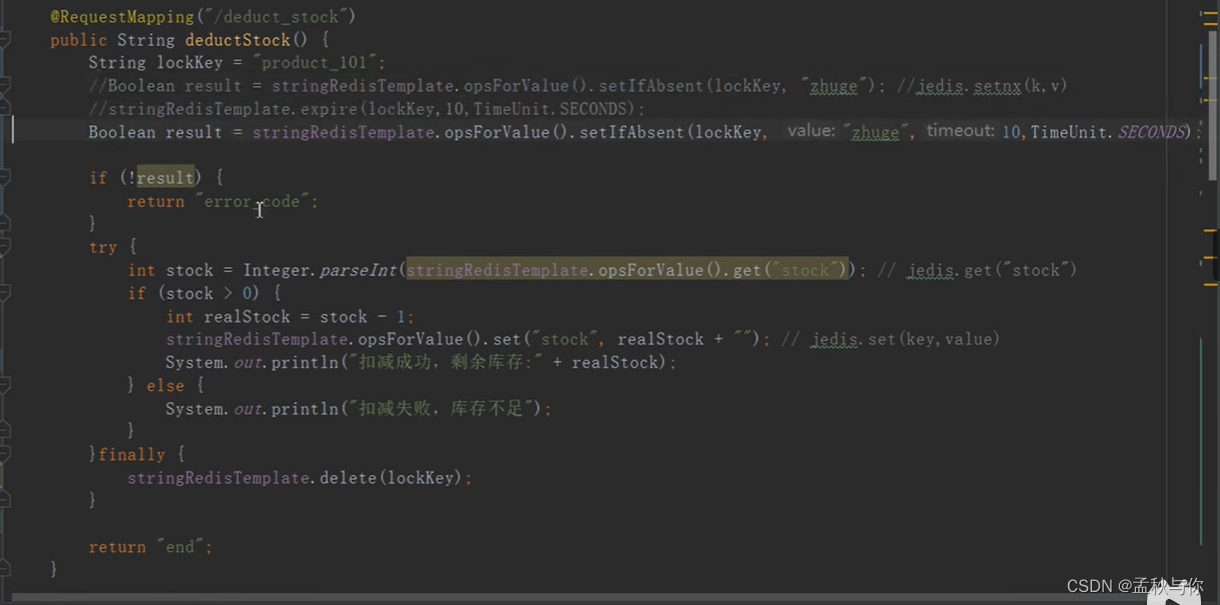
A6: 可能会删除其它线程的锁。
例如thread1 总共需要执行15s, 而锁在10s就过期了;假设在第10s时thread2执行进来,加锁成功,接着thread1就把thread2加的锁给删除了。那有同学可能就会说,把时间设置长一些,可即使是时间设置长,也只是减小概率,并没有完全解决问题,在高并发场景下,数据库资源紧张、Full Gc 等各种原因 都可能导致暂时卡顿,请求时间延长。
既然删掉了别人的锁,那么带上自己的id ,删除的时候 把自己id对应的锁删除 是不是就解决了呢?
Q7: 这段代码有什么问题?
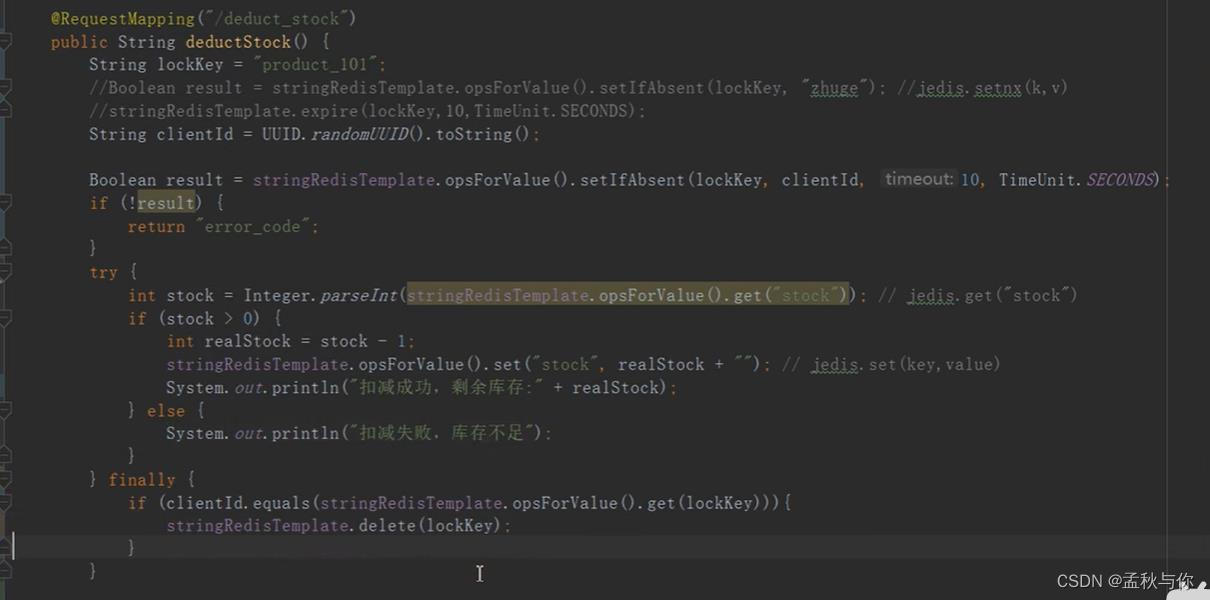
A7 :这里虽然加上了UUID(不考虑UUID重复),但如果执行完equlas判断,突然卡顿,准备执行delete方法时 超时时间过了,一样会删除别的线程的锁, equals和delete也需要原子执行。
当然 到这里为止,应对并发量不高的情况,那已经够了。
如果继续优化,这时候我们就可以引入redisson了,三行代码完成我们上述逻辑,并解决超时问题。
getLock 获取锁,lock 加锁,unlock 释放锁。
最终代码:
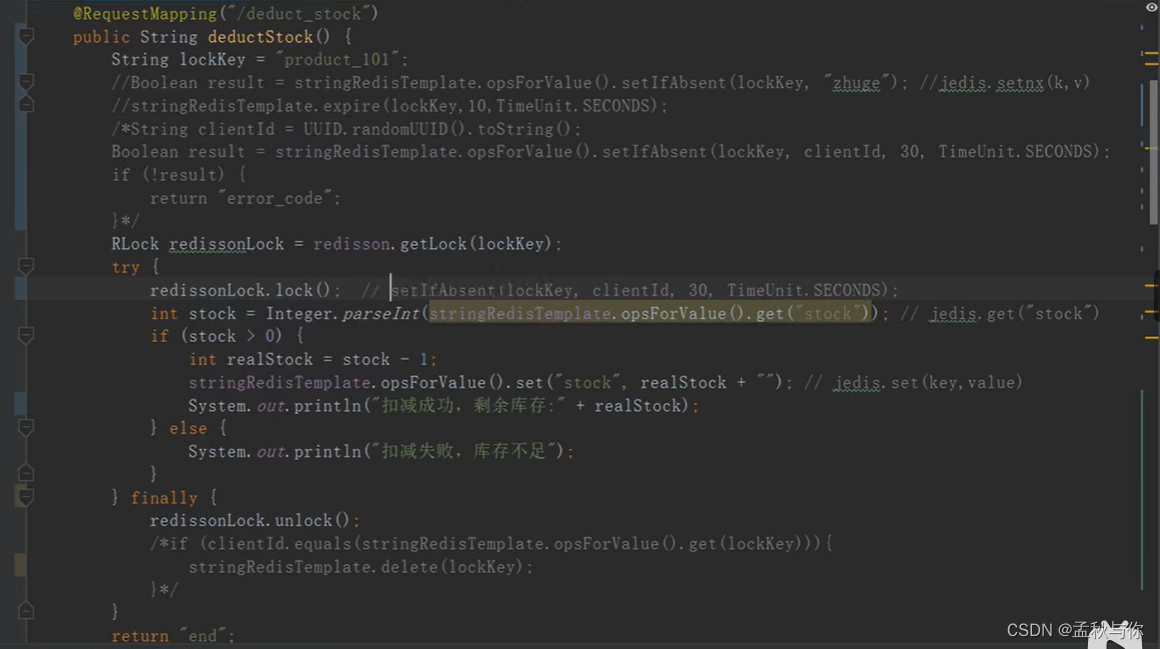
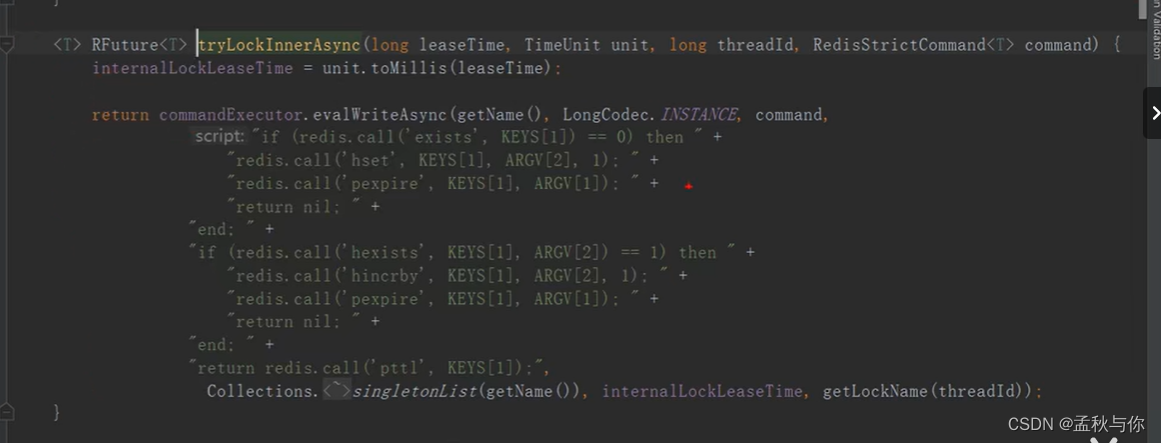
redisson是如何实现分布式锁的?
第一步: 加锁时使用lua脚本,lua脚本是原子执行的 ,带上当前线程id
设置过期时间(默认是30s,可以修改)
第二步: 开启一个新的线程(定时器),在过期时间的1/3 (10s)检查主线程是否还持有锁,如果持有,将过期时间重新设置为30s,实现锁续命。
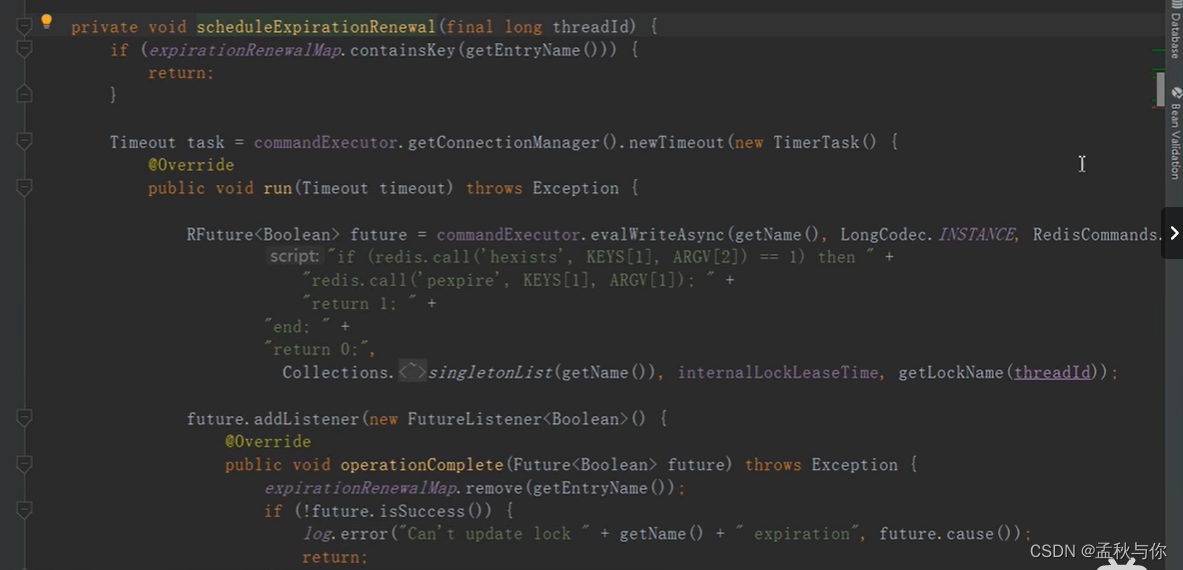
那最终代码有没有问题呢?但问题仍然存在,我们知道分布式环境中,redis会有主从节点,当主节点加锁成功,会马上返回结果,这时还没将key同步到从节点,如果这个瞬间 主节点挂了,那就会出现 主从锁失效 问题。
主从锁失效问题如何解决
这里我们引入一个概念:CAP原则
CAP原则,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
很显然 redisson满足的是AP原则, 如果要完全保证一致性,我们可以使用zookeeper,
zk满足CP原则,zk需要同步至少半数以上节点同步成功,才会返回结果。
那如果我们即想用redisson 又想解决主从锁丢失问题,该怎么办呢?
我们可以引入 redlock ,实现思想和zk类似, 不过redlock的redis都是对等节点,不是主从节点。根据诸葛老师的话,虽然可以解决 但是不推荐,redlock还有些待商榷的问题。
加锁后如何提升效率
现在问题解决了,那么性能问题如何优化呢?
我们可以采用分段锁的思想,在库存初始化的时候,就进行分段,例如200的库存,分成10份20的库存,分别进行加锁。
分段锁的几个重点:拆库存,随机扣减(单个库存够的情况),合并扣减(单个库存不够的情况)
缓存、数据库双写不一致问题如何解决
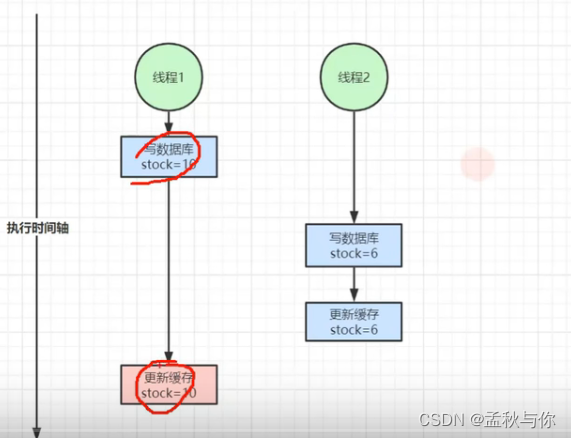
场景还原1:
例如 thread1 执行两步操作:写数据库stock = 10 , 更新缓存 stock = 10;
thread2 执行两步操作: stock = 6 ,更新缓存 stock = 6;
thread1 执行完写数据库后,发生了卡顿,这时thread2执行完了,实际库存应该是6,但接着thread1恢复执行,将缓存修改为10。
场景还原2:
基于上述方式的改进,
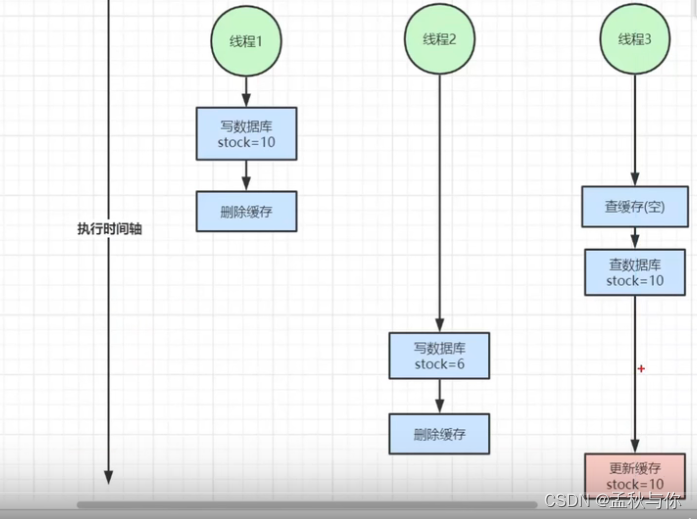
既然写入时 缓存会有问题 那写入时就把缓存删除,读时再缓存,那么这种方式会有什么问题呢?
thread1 写数据库stock = 10 ,删除缓存,
thread2 写数据库 stock=6 ,删除缓存
thread3查缓存(空),查数据库 stock = 10 ,更新缓存
如果thread2 在thread3 查数据库和更新缓存过程中执行完毕,那一样出现了不一致的问题。
解决方案:
1.延迟双删 (同样可能会有问题 就像上文提到的超时问题,时间是不可控的)
2. 内存队列 针对同一个key的操作 串行化运行 (但有性能问题)
3. 分布式锁 和内存队列类似,也有性能问题
补充:数据库的校验
在mysql8中,可以使用check对字段校验,例如我们store字段必须大于等于0
建表sql示例如下:
CREATE TABLE s_store(
id INT PRIMARY KEY,
store INT CHECK (store >= 0)
);















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











