







参考:https://blog.csdn.net/qq_29519041/article/details/81428934
http://c.biancheng.net/view/3398.html
什么是哈夫曼树
哈夫曼树,即最优二叉树,是一类带权路径长度最短的树
所谓树的带权路径长度,就是树中所有的叶节点的权值,乘上其到根节点的路径长度(若根节点为0层,页结点到根节点的路径长度为叶节点的层数)。整个树的带权路径长度是从树根到每一结点的带权路径长度之和。
怎么理解这句话:以下图为例:
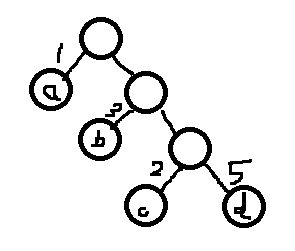
上面这颗二叉树的叶节点为a,b,c,d, 则各个叶节点的路径长度分别为:
a->1;b->2;c->3;d->3;
且叶结点a的带权路径长度为 1x1;叶节点b的带权路径长度为3x2;叶节点c的带权路径长度为2x3;叶节点d的带权路径长度为5x3;
那么整颗数的带权路径长度为1x1+3x2+2x3+5x3 = 28
那么什么是哈夫曼树呢? 就是当n个带权的叶节点试图构建一棵树时,所构建的所有树中带权路径长度最小的那个树就是哈夫曼树。
如何实现哈夫曼树
构建哈夫曼树,就要满足权值较高的那个离根节点更近的原则。
具体的构建流程大致如下:
假设将n个带权叶节点进行构建,如:A->31;B->62;c->26;D->12;E->42;F->34;
1:首先,从这n个结点中选两个权值最小的结点,将这两个结点作为一个新结点的孩子结点。小的在右,大的在左。这个新结点的权值为这两个结点权值之和。然后将这两个结点从这n个结点中删除。将新结点放到其余结点集合中。
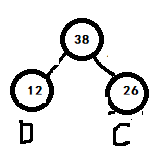
那么剩下的结点为:A->31;B->62;E->42;F->34;DC->38
构建的二叉树为:
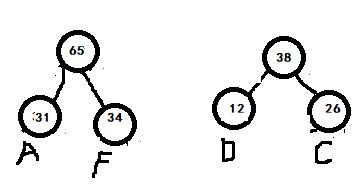
重复1过程,则剩下的结点为:B->62;E->42;DC->38;AF->65;
构建的树形结构为:
继续重复1过程,则剩下的结点为:B->62;AF->65;DCE->80;
构建的树形结构为:

继续重复1过程,则剩下的结点为:BAF>127;DCE->80;
构建的树形结构为:

重复1过程,则剩下的结点为:DCEBAF->207,构建的树形结构为

那么DCEBAF结点就位根节点。并且此时构建 的树就为哈夫曼树。
哈夫曼树的代码实现:
//首先要使用一个结构来作为哈夫曼树的结点,由哈夫曼树的构建过程我们可以知道,这个结点包含:权重,父节点,左子节点,右子节点
typedef struct
{
int weight;//结点权重
int parent, left, right;//父结点、左孩子、右孩子在数组中的位置下标
}HTNode, *HuffmanTree;//定义结点以及结点数组
//然后我们要构建一个函数来得到n个结点中最小的两个结点,其思想为;
//从结点起始位置开始,首先找到两个无父结点的结点(说明还未使用其构建成树),
//然后和后续无父结点的结点依次做比较,有两种情况需要考虑:
//如果比两个结点中较小的那个还小,就保留这个结点,删除原来较大的结点;
//如果介于两个结点权重值之间,替换原来较大的结点;
//函数实现为:
//HT数组中存放的哈夫曼树,end表示HT数组中存放结点的最终位置,s1和s2传递的是HT数组中权重值最小的两个结点在数组中的下标
void Select(HuffmanTree HT, int end, int &s1, int &s2)
{
int min1, min2;//两个结点的权重,
//遍历数组初始下标为 1
int i = 1;
//找到还没构建树的结点
while (HT[i].parent != 0 && i <= end)
{
i++;
}//一直遍历到当HT中的结点没有父节点时(parent==0),且保证i不到达没有存储结点的位置
min1 = HT[i].weight;//先找到其中一个叶节点,将权值赋值给min1
s1 = i;
i++;//i+1表示找下一个叶节点
while (HT[i].parent != 0 && i <= end)
{
i++;
}//此时的i为下一个叶节点的下标
//对找到的两个结点比较大小,让min2为大的,min1为小的
if (HT[i].weight < min1)
{
min2 = min1;
s2 = s1;
min1 = HT[i].weight;
s1 = i;
}
else
{
min2 = HT[i].weight;
s2 = i;
}
//两个结点和后续的所有未构建成树的结点做比较
for (int j = i + 1; j <= end; j++)
{
//如果有父结点,直接跳过,进行下一个
if (HT[j].parent != 0)
{
continue;
}
//如果比最小的还小,将min2=min1,min1赋值新的结点的下标
if (HT[j].weight < min1)
{
min2 = min1;
min1 = HT[j].weight;
s2 = s1;
s1 = j;
}
//如果介于两者之间,min2赋值为新的结点的位置下标
else if (HT[j].weight >= min1 && HT[j].weight < min2)
{
min2 = HT[j].weight;
s2 = j;
}
}
}
//接下来创建哈夫曼树
//HT为哈夫曼树的数组,w为存储结点权重值的数组,n为结点个数
void CreateHuffmanTree(HuffmanTree &HT, int *w, int n)
{
if (n <= 1) return; // 如果只有一个编码就相当于0
int m = 2 * n - 1; // 哈夫曼树总节点数,n就是叶子结点
HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode)); //因为我们要让parent的下标为0,所以0号位置不用
HuffmanTree p = HT;
// 初始化哈夫曼树中的所有叶子结点
for (int i = 1; i <= n; i++)
{
(p + i)->weight = *(w + i - 1);
(p + i)->parent = 0;
(p + i)->left = 0;
(p + i)->right = 0;
}
//从树组的下标 n+1 开始初始化哈夫曼树中除叶子结点外的结点
for (int i = n + 1; i <= m; i++)
{
(p + i)->weight = 0;
(p + i)->parent = 0;
(p + i)->left = 0;
(p + i)->right = 0;
}
//构建哈夫曼树
//构建哈夫曼树
for (int i = n + 1; i <= m; i++)//每构建一次都要产生一个新结点
{
int s1, s2;
Select(HT, i - 1, s1, s2);//得到最下结点的下标
(HT)[s1].parent = (HT)[s2].parent = i;//将这两个结点的父节点共同表示为新结点
//新结点的左右孩子及新权重
(HT)[i].left = s1;
(HT)[i].right = s2;
(HT)[i].weight = (HT)[s1].weight + (HT)[s2].weight;
}
}
哈夫曼编码

如上图,将0放左边,1放右边,则ABCDEF的编码为:
A:110
B:10
C:001
D:000
E:01
F:111















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









