






kafka笔记
1、消息队列的模式
(1)点对点模式
一个生产者生产数据,发送到消息队列,然后由另一个消费者进行消费,消费后,消息就会删除。
(2)发布订阅模式
生产者生产数据,可以发送给多个分区,消费者可以为多个,并且多个消费者消费同一个分区的数据。而且数据消费后并不进行删除
2、kafka基础架构
(1)为了方便扩展,一个topic分为多个partition
(2)配合分区的设计,提出消费组的概念,组内每个消费者并行消费。(组内的一个消费者只能消费一个分区)、
(3)为了提高可用性,kafka为每个partition增加若干副本。消费数据只会针对leader,flower作为备份,当leader挂了之后,flower会成为leader,重新提供消费者进行消息消费
(4)zookeeper中记录了谁是leader的信息,但是2.8版本后,可以配置不采用zookeeper
3、发送流程
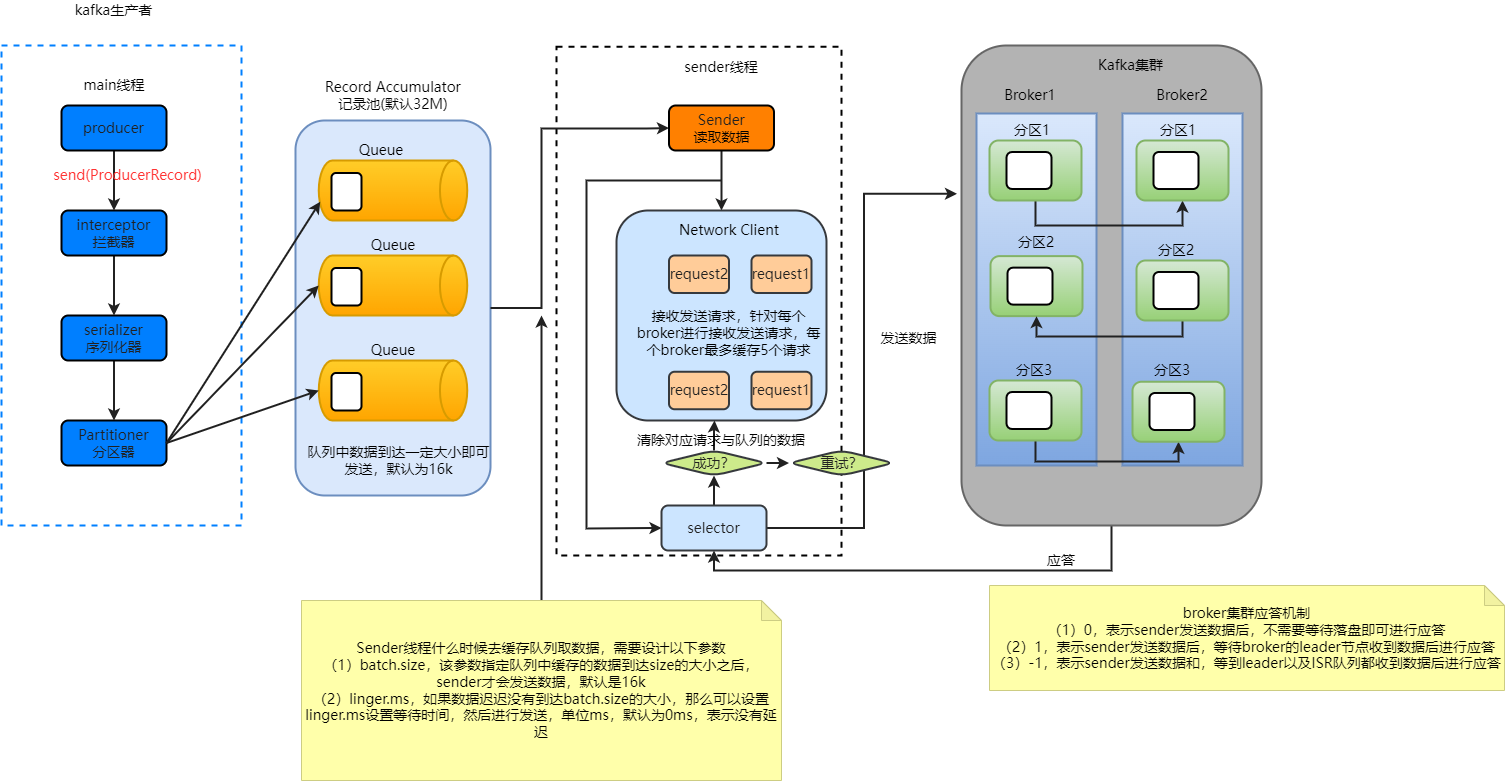
注意两个参数(吞吐量)与应答机制(数据可靠性)
4、生产者如何提高吞吐量
首先,影响发送数据的吞吐量有batch.size和linger.ms。除此之外,还可以设定数据压缩的参数:
-
compression.type: 压缩snappy
-
同时还可以设定缓冲区大小:
RecordAccumulator,缓冲区大小,默认为32M
5、数据可靠性分析
(1)ack=0
当生产者发送数据之后,即进行应答。可靠性最差,效率最高
(2)ack=1
当生产者发送数据到达leader,leader收到数据后,进行应答,效率中等,可靠性中等
但是如果leader应答之后落盘前挂了,那么数据会丢失
(3)ack=-1
当生产者发送数据到达leader,并且leader和isr都收到数据后,然后进行应答。效率最差,可靠性最高
6、由于ack应答导致的数据重复的问题
当ack=-1的情况下,leader和isr收到数据之后,但是在应答之前,leader挂了,那么新的leader选举之后,生产者会重新发送原来的数据,那么会导致节点数据重复
7、数据传递语义
-
至少一次(At Least One)= ACK 级别设置为-1+分区副本大于等于2+ISR应答最小副本数大于等于2。保证数据不丢失,但是会重复
-
最多一次(At Most one)= ACK设置为0,不保证数据不丢失
-
精确一次(Exactly one) = 幂等性+至少一次
8、幂等性(解决至少一次的数据重复问题)
无论生产者发送多少条重复的数据,broker都只会持久化一条,保证不重复。
判断重复的标准:具有<PID, Partition, SeqNumber>相同主键消息的情况下,broker只会保存其中一条:
-
PID:生产者id,每次启动的时候,会分配一个新的PID,重启后会重新分配
-
Partition:分区
-
SeqNumber:序列号,单调递增
所以,幂等性能保证单会话数据的不重复,但是无法保证多会话的数据不重复
想要在多会话情况下保证数据不重复,那么需要kafka的事务进行解决
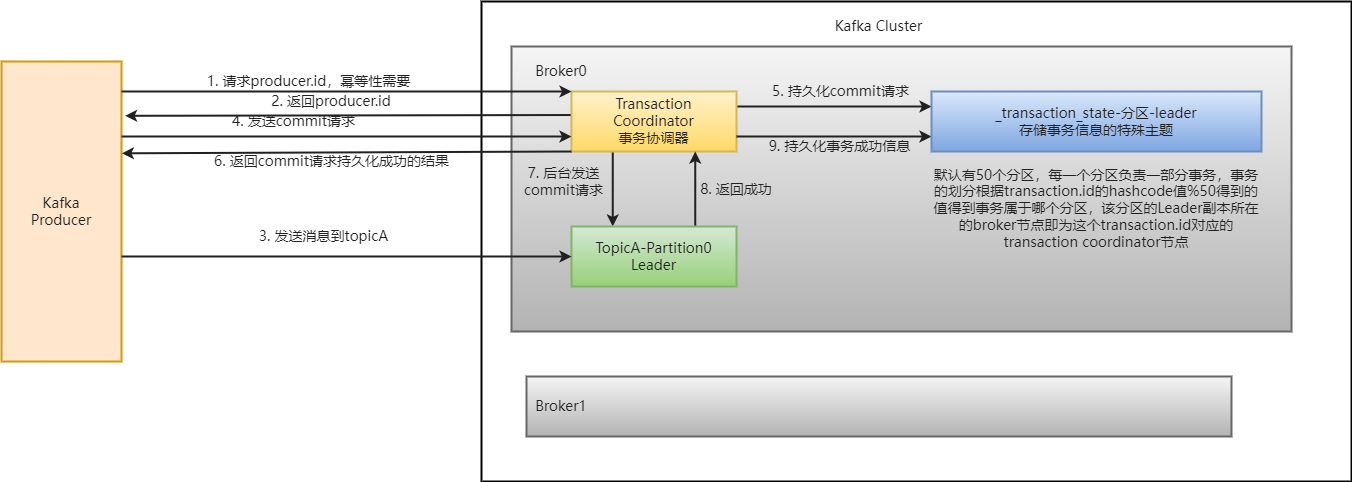
9、kafka事务
说明,开启事务,必须开启幂等性,因为事务底层是依赖幂等性实现的。
生产者在使用事务前,必须自定义一个唯一的事务id:transactional.id,即使broker挂了,也能处理未完成的事务
10、数据乱序问题
kafka在但分区有序(有条件的),但是无法保证分区与分区之间的数据的有序性。
(1)在kafka1.x之前,如果需要保证但分区内的数据的有序性,那么需要设置以下参数:
max.in.flight.request.per.connection=1(不需要考虑幂等性)
该参数是设置发送线程当发送数据到broker时没有收到回应时,最多能缓存多少个请求(最多能使用sender线程发送多少个请求)
(2)在kafka1.x之后的版本保证分区内数据的有序,需要以下条件
-
如果没有开启幂等性,那么需要把
per.connection=1 -
如果开启了幂等性,那么per.connection设置的值需要设置小于等于5
因为kafka会缓存发送过来的5个请求的元数据,能保证这5个元数据的有序。通过seqNumber排序,可以判断数据的顺序性。
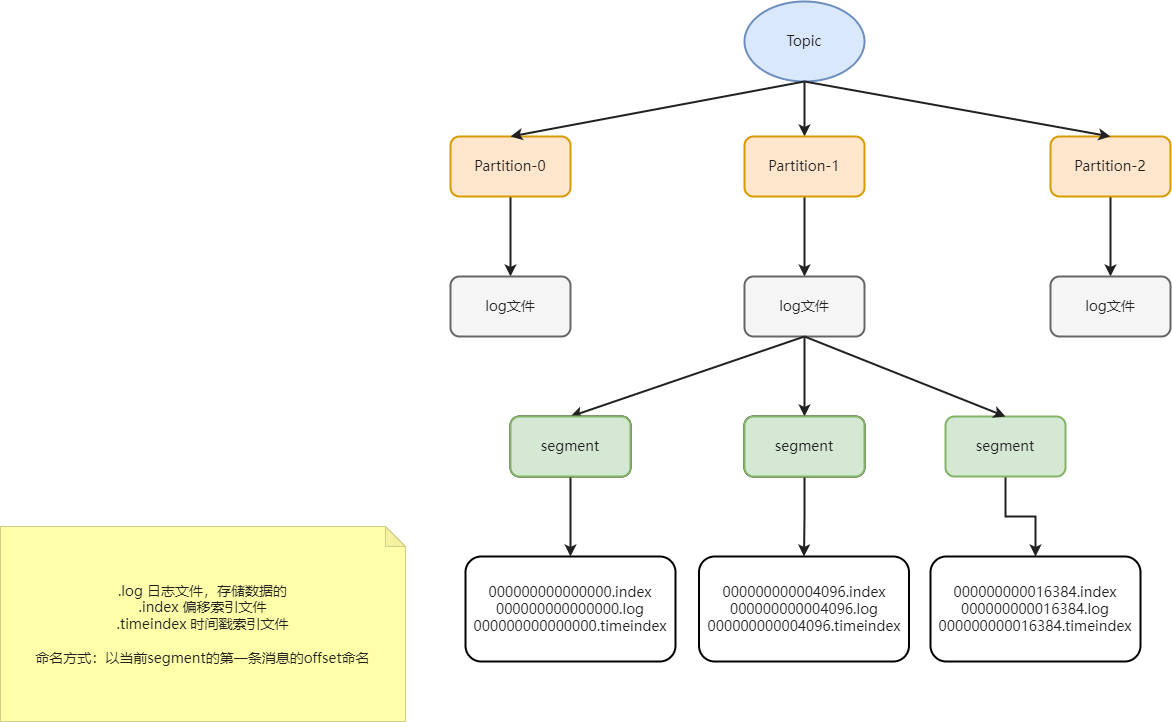
11、kafka文件存储机制
topic是逻辑上的概念,而partition是物理上的概念,每一个partition对应一个log文件,而log文件存储的就是生产者发送过来的数据。生产者发送过来的数据是采用追加的方式写入到log文件中的,为了防止文件过大导致的数据查找效率低下的问题,kafka采用了分片和索引的机制将每个partition的数据分为多个segment,每个segment文件默认1G。segment包含:.index、.log、.timeindex三个文件。这些文件处于同一个文件夹内,文件夹命名规则是:topic-分区序号,比如:topicA-0
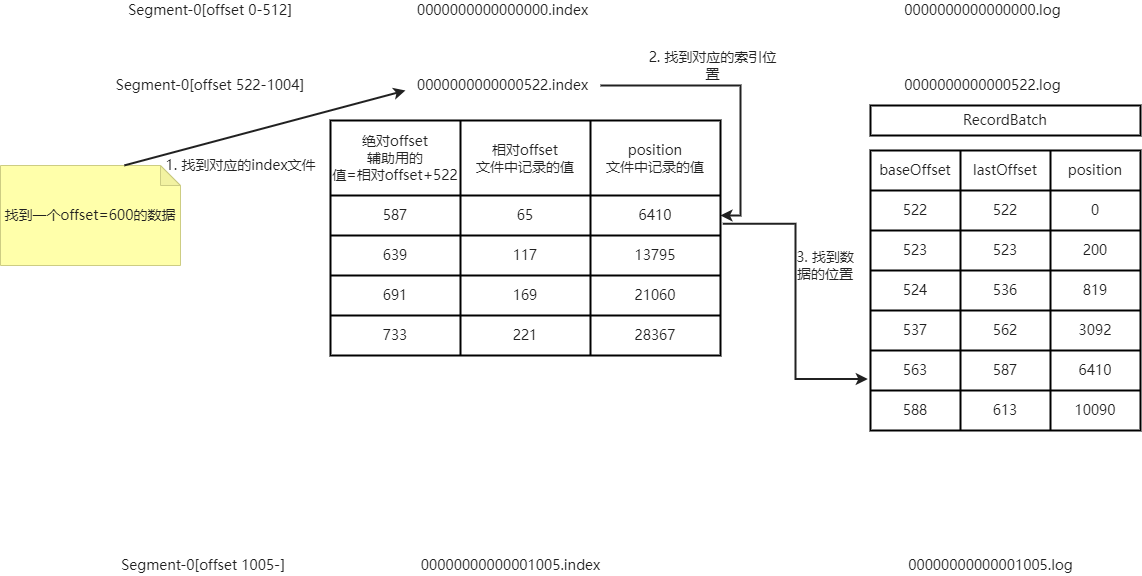
(1)log文件和index文件详解
1)index为稀疏索引,大约每往log文件中写入4k的数据,就会往index文件中写入一条索引。参数设置log.index.interval.bytes,默认4Kb
2)index文件中存储的offset为相对offset,这样保证offset的值不会占用过大的空间。绝对offset=相对offset+文件offset的大小,比如相对offset=10,文件名为0000000004096.index,那么绝对offset=10+4096=4106
3)查找对应offset的数据的时候,根据目标offset查找对应的segment文件,然后在index文件中找到目标索引,然后找到数据的位置
12、文件清理策略
kafka中,文件默认保存7天,但是可以通过参数进行设置
log.retention.hour 优先级最低,默认七天
log.retention.minutes 优先级比hour高,按分钟设置时间
log.retention.ms 优先级最高,按照毫秒设置时间
log.retention.check.interval.ms 设置检查数据过期的周期时间,默认是5分钟
(1)日志清除策略
可以通过设置参数log.cleanup.policy设置策略,有delete和compact两种方式
1)delete删除
当时间超过了设置的过期时间,则采用直接删除数据的方式删除数据。
-
基于时间删除:默认打开,以所有segment中记录的最大最大时间戳作为该文件的时间戳,就是segment中最后一个插入的数据的时间戳为准
-
基于大小删除:默认关闭,超过设置所有日志总大小,删除最早的segment
2)compact 压缩
日志压缩,对于相同key的value,只保留最后的一个版本
13、kafka高效读写
(1)kafka本身是支持集群部署,可以采用分区技术,提高并行度
(2)读取数据采用稀疏索引,可以快速定位到消费的数据
(3)顺序写磁盘
(4)页缓存+零拷贝
-
零拷贝,kafka的数据加工与处理都是在生产者或者消费者端完成,broker不需要关心数据的处理,所以数据不需要走应用层,可以直接从内核(缓存叶)直接通过网关传递给消费者
-
缓存叶
kafka严重依赖系统的缓存叶技术,当有数据写入的时候,直接把数据写入到缓存叶中。数据读取的时候,直接从缓存叶中获取,如果找不到就读取磁盘的数据写入到缓存叶。
14、消息队列消费方式
(1)pull(拉)方式消费
消费者主动从broker中拉取数据,kafka采用这种方式。
缺点:如果broker中没有数据,那么消费者会陷入循环中,一直返回空数据。
(2)push(推)方式消费
broker主动推送消息给消费者,但是如果broker决定消息消费速度,很难适应所有的消费者的消费速度,所以kafka没有采用这种方式
15、kafka消费者流程
(1)总流程
1)每一个消费者可以消费多个分区,多个消费者之间互不影响
2)一个消费组内,一个分区的数据只能由消费组内的一个消费者消费
3)消费者消费到具体消息的位置,成为offset,这个offset会存储在系统主题中_consummer_offsets
(2)消费者组
消费者组,是由多个消费者组成的消费者组,形成一个消费者组的条件是groupid是相同的
1)消费者组内的消费者负责消费不同分区的数据,一个分区的数据只能由消费者组的一个消费者消费,但是一个消费者可以消费多个分区的数据。
2)消费者组之间的消息消费互不影响,所有消费者都属于某个消费者组
3)如果消费者组内的消费者数量超过了主题分区数量,那么多出来的一部分消费者将不会接收到消息,会闲置
(3)消费者组初始化流程
1)coordinator:辅助完成消费者组的初始化和分区分配的
coordinator对节点的分配,对groupid的hashCode的值进行%50(默认50,consumer默认分区数量),得到的值就是分区号,然后把该分区的cooridinator作为消费者组的老大,消费者组内所有的消费者提交offset都提交到该分区
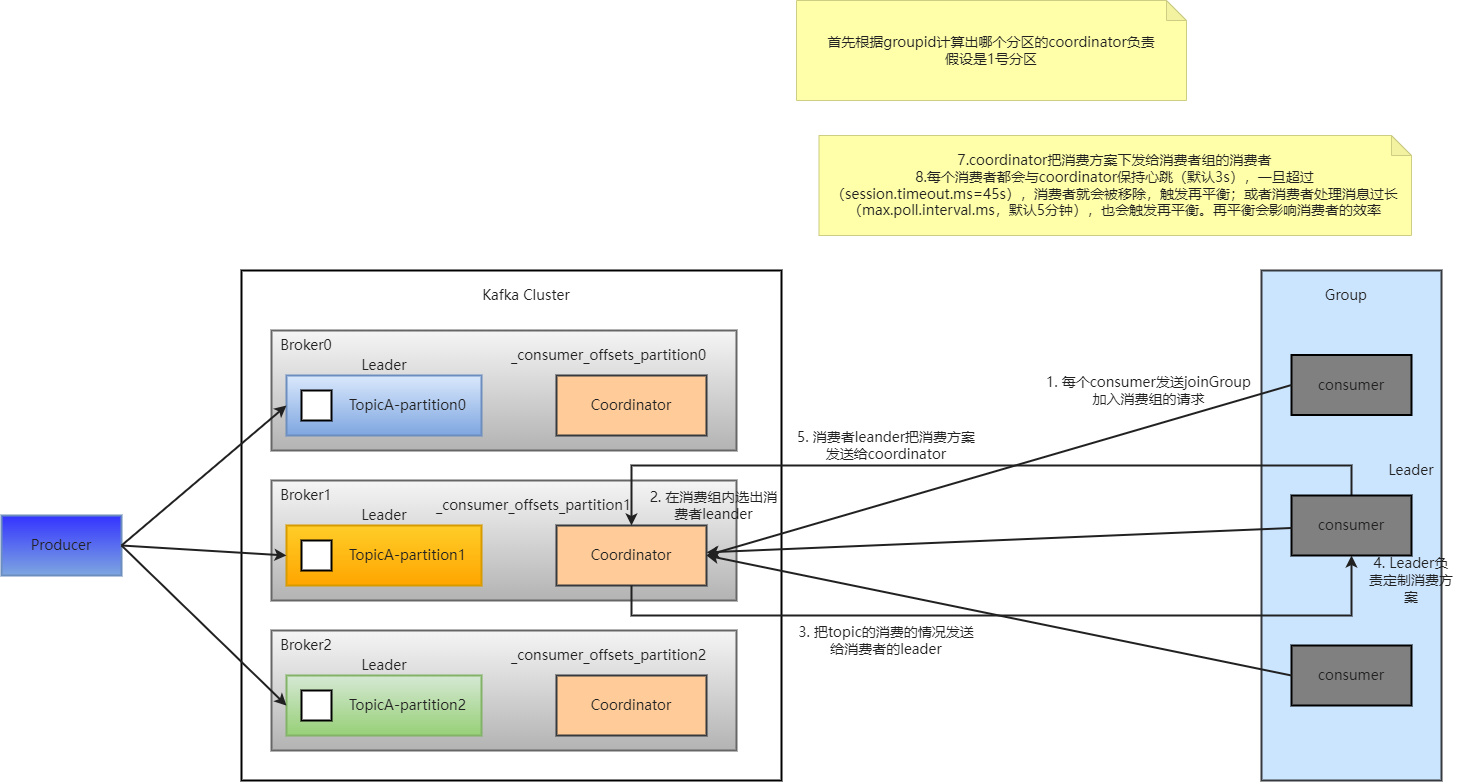
重点注意:每一个消费者都会与coordinator保持心跳(3s),一旦超过(session.timeout.ms=45s),消费者就会被移除,触发再平衡;或者当消费者处理消息过长(max.poll.interval.ms,默认5分钟),也会触发再平衡。
(4)消费者组详细消费过程
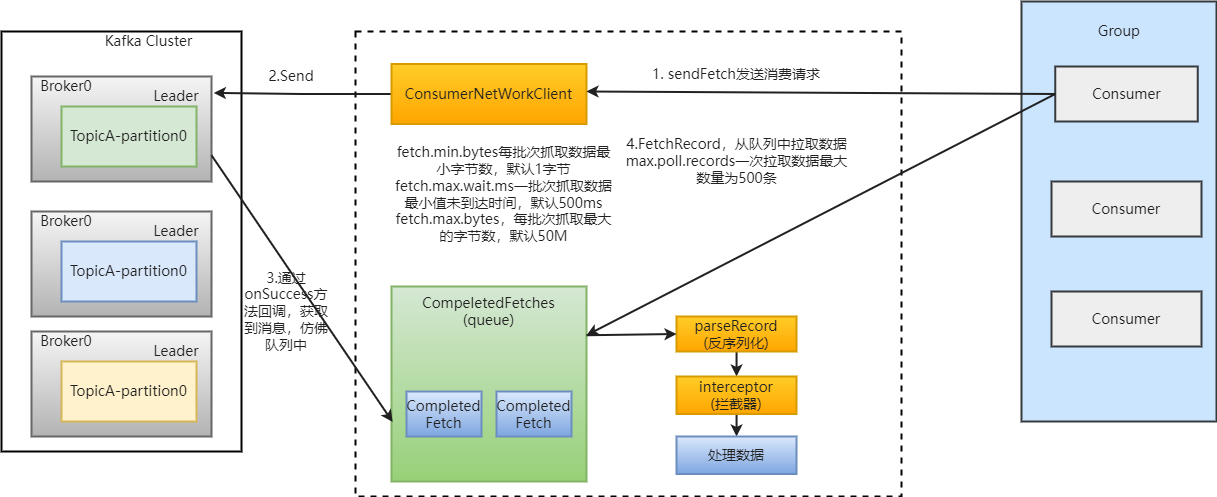














 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









