







文章目录
- Java
- 基础
- 集合
- 集合框架底层数据结构
- 线程安全容器
- ArrayList和LinkedList区别
- ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢
- ArrayList扩容机制
- HashMap 和 HashSet区别
- HashSet如何检查重复
- HashMap底层实现
- HasMap扩容
- HashMap 的长度为什么是2的幂次方
- HashMap中hash算法
- HashMap 多线程操作导致死循环问题
- HashMap和HashTable、ConcurrentMap区别
- ConcurrentHashMap 和 Hashtable 的区别
- ConcurrentHashMap线程安全的具体实现方式/底层具体实
- Java并发
- IO
- Java注解
- Java动态代理
- JVM
- JDK1.8特性
- Servlet
- JDBC
- Spring
- 什么是 Spring 框架
- Spring模块
- Spring的启动过程
- Springboot自动配置原理
- Spring依赖注入方式
- Spring事务的传播性
- Spring中的隔离级别
- Spring通知类型
- SpringMVC原理
- Spring AOP
- Spring IOC
- SpringBean作用域
- Spring支持Bean的作用域
- Spring框架中的单例Beans线程安全
- Spring如何处理线程并发问题
- Spring自动装配
- spring控制bean加载顺序
- Spring@Component和@Bean区别
- Spring中BeanFactory和FactoryBean区别
- BeanFactory和ApplicationContext有什么区别?
- MySQL
- Redis
- Mybatis
- 微服务
- 数据结构
- 加密
Java
基础
基本数据类型
| 序号 | 数据类型 | 位数 | 默认值 | 取值范围 | 举例说明 |
|---|---|---|---|---|---|
| 1 | byte(位) | 8 | 0 | -2^7 - 2^7-1 | byte b = 10; |
| 2 | short(短整数) | 16 | 0 | -2^15 - 2^15-1 | short s = 10; |
| 3 | int(整数) | 32 | 0 | -2^31 - 2^31-1 | int i = 10; |
| 4 | long(长整数) | 64 | 0 | -2^63 - 2^63-1 | long l = 10l; |
| 5 | float(单精度) | 32 | 0.0 | -2^31 - 2^31-1 | float f = 10.0f; |
| 6 | double(双精度) | 64 | 0.0 | -2^63 - 2^63-1 | double d = 10.0d; |
| 7 | char(字符) | 16 | 空 | 0 - 2^16-1 | char c = ‘c’; |
| 8 | boolean(布尔值) | 8 | false | true、false | boolean b = true; |
float和double区别
01.在内存中占有的字节数不同
单精度浮点数在机内存占4个字节
双精度浮点数在机内存占8个字节
02.有效数字位数不同
单精度浮点数有效数字8位
双精度浮点数有效数字16位
03.数值取值范围
单精度浮点数的表示范围:-3.40E+38~3.40E+38
双精度浮点数的表示范围:-1.79E+308~-1.79E+308
04.在程序中处理速度不同
一般来说,CPU处理单精度浮点数的速度比处理双精度浮点数快
如果不声明,默认小数为double类型,所以如果要用float的话,必须进行强转
例如:float a=1.3; 会编译报错,正确的写法 float a = (float)1.3;或者float a = 1.3f;(f或F都可以不区分大小写)
注意:float是8位有效数字,第7位数字将会四舍五入,所以float会丢失精度
Object 常见方法
public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了 final关键字修饰,故不允许子类重写。
public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的 HashMap。
public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户 比较字符串的值是否相等。
protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回 当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生 CloneNotSupportedException异常。
public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方 法。
public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视 器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒 在此对象监视器上等待的所有线程,而不是一个线程。
public final native void wait(long timeout) throws InterruptedException//native方法,并且不能 重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数, 这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等 待,没有超时时间这个概念
protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
Java中数据结构
Java工具包提供了强大的数据结构。在Java中的数据结构主要包括以下几种接口和类:
- 枚举(Enumeration)
- 位集合(BitSet)
- 向量(Vector)
- 栈(Stack)
- 字典(Dictionary)
- 哈希表(Hashtable)
- 属性(Properties)
Java中异常处理
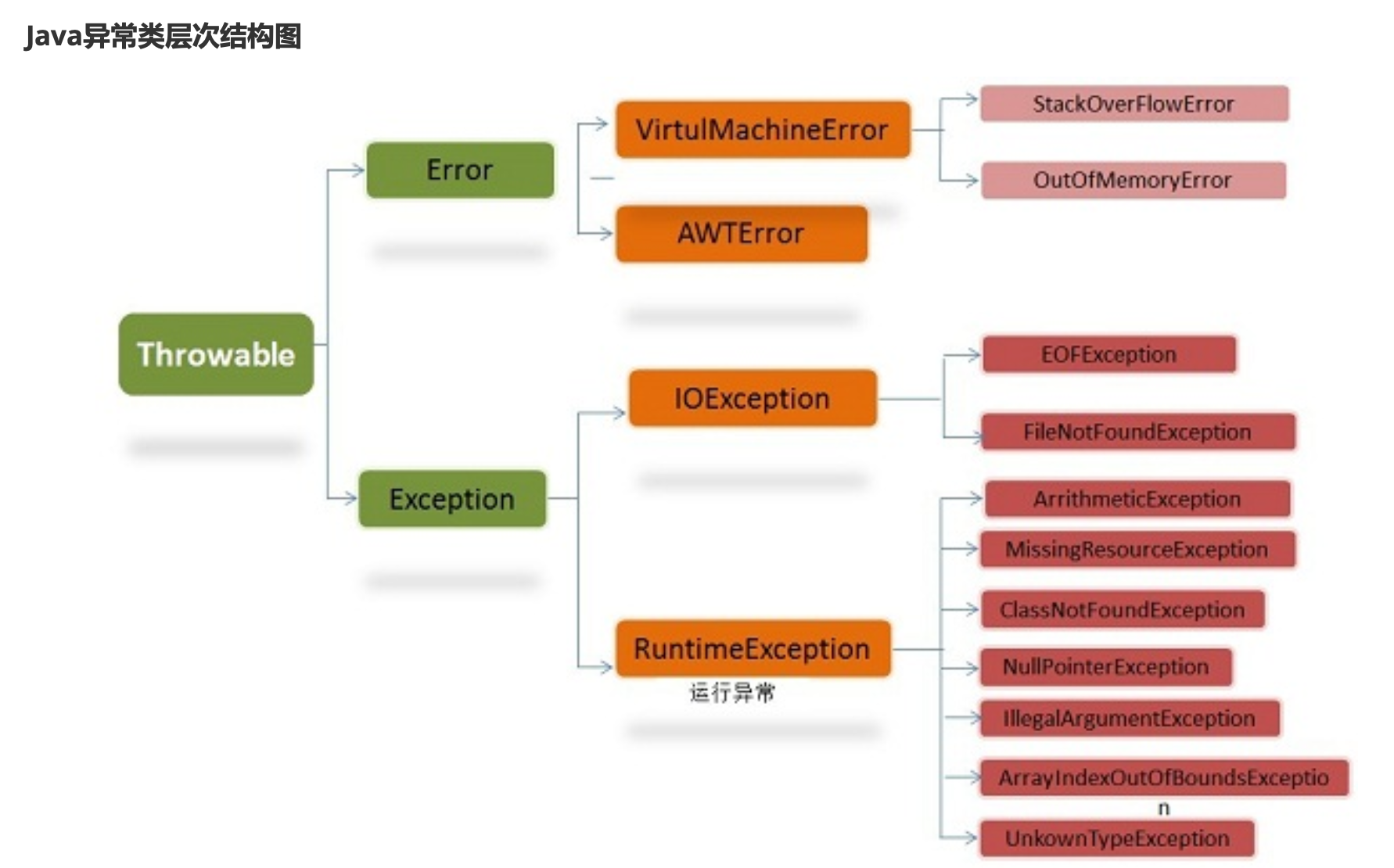
在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 Throwable类。Throwable: 有两个重要的子类: Exception(异常) 和 Error(错误) ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无 关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一 般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和 处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错 误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。Exception 类有一个重要的子类 RuntimeException。 RuntimeException 异常由Java虚拟机抛出。NullPointerException(要访问的变量没有引用任何对象时,抛出该 异常)、ArithmeticException(算术运算异常,一个整数除以0时,抛出该异常)和 ArrayIndexOutOfBoundsException (下标越界异常)。
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。 Throwable类常用方法
public string getMessage():返回异常发生时的详细信息
public string toString():返回异常发生时的简要描述
public string getLocalizedMessage():返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可 以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同 public void printStackTrace():在控制台上打印Throwable对象封装的异常信息
异常处理总结
try 块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
catch 块:用于处理try捕获到的异常。
finally 块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句 时,finally语句块将在方法返回之前被执行。
在以下4种特殊情况下,finally块不会被执行:
- 在finally语句块中发生了异常。
- 在前面的代码中用了System.exit()退出程序。 3. 程序所在的线程死亡。
- 关闭CPU。
StackOverFlowError和**OutOfMemoryError
- StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 异常。
- OutOfMemoryError: 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出 OutOfMemoryError 异常。
访问控制修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
- public : 对所有类可见。使用对象:类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
== 与 equals区别
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型比较的是 值,引用数据类型比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相 等,则返回 true (即,认为这两个对象相等)。
举个例子:
public class test1 {
public static void main(String[] args) {
} }
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
if (aa == bb) // true
System.out.println("aa==bb"); if (a == b) // false,非同一对象
System.out.println("a==b"); if (a.equals(b)) // true
System.out.println("aEQb"); if (42 == 42.0) { // true
System.out.println("true"); }
String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有 就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
重写equals方法,为什么要重写hashcode
- hashCode是不是重写需要看业务,开放开发人员可以重写这个方法,可能有这种情况,比如我们仅仅对比object的部分属性,就认为两者相等,而不对比其其他属性。
- 重写java object hashCode方法,是为了在一些算法中避免我们不想要的冲突和碰撞。比如其HashMap,HashSet的使用中。
final 关键字的一些总结
final关键字主要用在三个地方:变量、方法、类。
-
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的 变量,则在对其初始化之后便不能再让其指向另一个对象。
-
当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
-
使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。
在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的 任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地 指定为fianl。
String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?
可变性
简单的来说:String 类中使用 final 关键字字符数组保存字符串, private final char value[] ,所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串 char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自 行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共 方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对 方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。 StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据 = String
- 单线程操作字符串缓冲区下操作大量数据 = StringBuilder 3. 多线程操作字符串缓冲区下操作大量数据 = StringBuffer
集合
集合框架底层数据结构
1. List
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
2. Set
- HashSet(无序,唯一): 基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
3. Map
- HashMap: JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
- LinkedHashMap: LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- Hashtable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap: 红黑树(自平衡的排序二叉树)
线程安全容器
JDK 提供的这些容器大部分在 java.util.concurrent 包中。
-
**Vector **
-
HashTable
-
ConcurrentHashMap: 线程安全的 HashMap
-
CopyOnWriteArrayList: 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vector.
-
ConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,这是一个非阻塞队列。
-
BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
-
ConcurrentSkipListMap: 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找。
ArrayList和LinkedList区别
- 底层数据结构:ArrayList是对象数组,所以查询效率很高,通过下标查询;LinkedList采用的是双向链表,添加删除效率很高。两者皆为线程不安全。
ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
ArrayList扩容机制
- 初始化时,有三种方式(无参,传入容量,传入集合),如果是无参的话,默认是大小为10的容量
- add()方法存在扩容机制,grow()方法里面,每次扩容的大小为之前的1.5倍(int newCapacity = oldCapacity + (oldCapacity >> 1)😉
HashMap 和 HashSet区别
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
| HashMap | HashSet |
|---|---|
| 实现了Map接口 | 实现Set接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向map中添加元素 | 调用 add()方法向Set中添加元素 |
| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
HashSet如何检查重复
HashSet通过对象的hashcode值来判断,如果没有相同的hashcode,就添加进去。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,就无法添加。
HashMap底层实现
数组+链表,1.8
如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过链表解决冲突。
JDK1.8之后,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经 过扰动函数处理过后得到 hash 值,然后通过 判断当前元素存放的位置(这里的 n 指的是数组的 长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的 话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
HasMap扩容
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。
0.75这个值成为负载因子,那么为什么负载因子为0.75呢?这是通过大量实验统计得出来的,如果过小,比如0.5,那么当存放的元素超过一半时就进行扩容,会造成资源的浪费;如果过大,比如1,那么当元素满的时候才进行扩容,会使get,put操作的碰撞几率增加。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果当前的数组长度已经达到最大值,则不在进行调整
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//根据传入参数的长度定义新的数组
Entry[] newTable = new Entry[newCapacity];
//按照新的规则,将旧数组中的元素转移到新数组中
transfer(newTable);
table = newTable;
//更新临界值
threshold = (int)(newCapacity * loadFactor);
}
//旧数组中元素往新数组中迁移
void transfer(Entry[] newTable) {
//旧数组
Entry[] src = table;
//新数组长度
int newCapacity = newTable.length;
//遍历旧数组
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);//放在新数组中的index位置
e.next = newTable[i];//实现链表结构,新加入的放在链头,之前的的数据放在链尾
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
HashMap 的长度为什么是2的幂次方
为了存取效率高,尽量较少碰撞,数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
HashMap中hash算法
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
HashMap 多线程操作导致死循环问题
并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap
HashMap和HashTable、ConcurrentMap区别
- HashMap线程不安全
- HashTable线程安全,添加了同步锁
- ConcurrentMap线程安全,ReentrantLock实现线程安全
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别是线程安全实现不同。
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对数组进行了分割分段(Segment)处理,每个锁,只锁部分数据,多线程访问不同分段段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
ConcurrentHashMap线程安全的具体实现方式/底层具体实
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
Java并发
为什么使用多线程
- 提高程序效率
- 充分利用cpu资源
线程安全
多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
线程安全问题大多是由全局变量及静态变量引起的,局部变量逃逸也可能导致线程安全问题。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
类要成为线程安全的,首先必须在单线程环境中有正确的行为。如果一个类实现正确(这是说它符合规格说明的另一种方式),那么没有一种对这个类的对象的操作序列(读或者写公共字段以及调用公共方法)可以让对象处于无效状态,观察到对象处于无效状态、或者违反类的任何不可变量、前置条件或者后置条件的情况。
此外,一个类要成为线程安全的,在被多个线程访问时,不管运行时环境执行这些线程有什么样的时序安排或者交错,它必须仍然有如上所述的正确行为,并且在调用的代码中没有任何额外的同步。其效果就是,在所有线程看来,对于线程安全对象的操作是以固定的、全局一致的顺序发生的。
正确性与线程安全性之间的关系非常类似于在描述 ACID(原子性、一致性、独立性和持久性)事务时使用的一致性与独立性之间的关系:从特定线程的角度看,由不同线程所执行的对象操作是先后(虽然顺序不定)而不是并行执行的。
线程状态
NEW ---- 创建了线程对象但尚未调用start()方法时的状态。
RUNNABLE ---- 线程对象调用start()方法后,线程处于可运行状态,此时线程等待获取CPU执行权。
BLOCKED ---- 线程等待获取锁时的状态。
WAITING ---- 线程处于等待状态,处于该状态标识当前线程需要等待其他线程做出一些特定的操作唤醒自己。
TIME_WAITING ---- 超时等待状态,与WAITING不同,在等待指定的时间后会自行返回。
TERMINATED ---- 终止状态,表示当前线程已执行完毕。
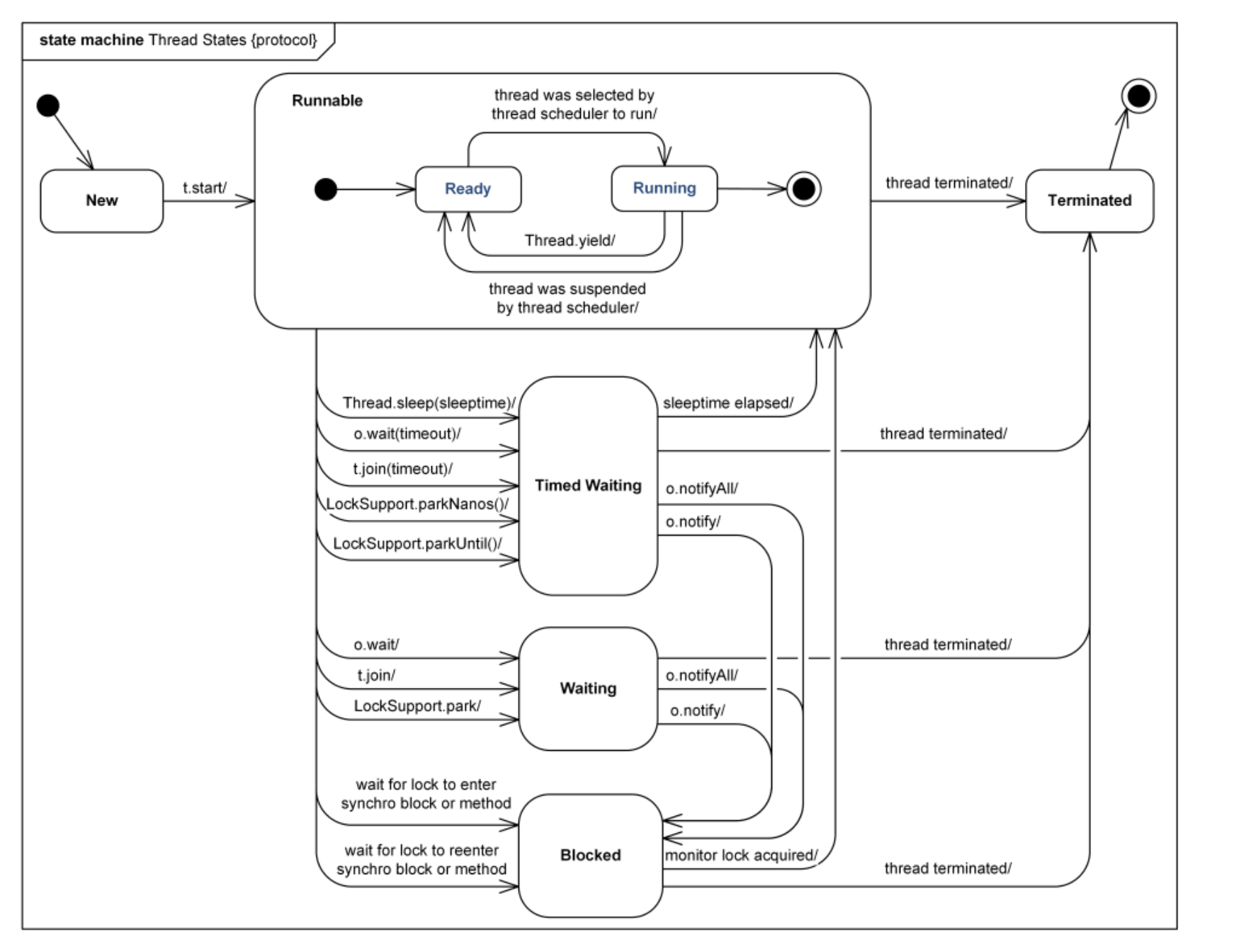
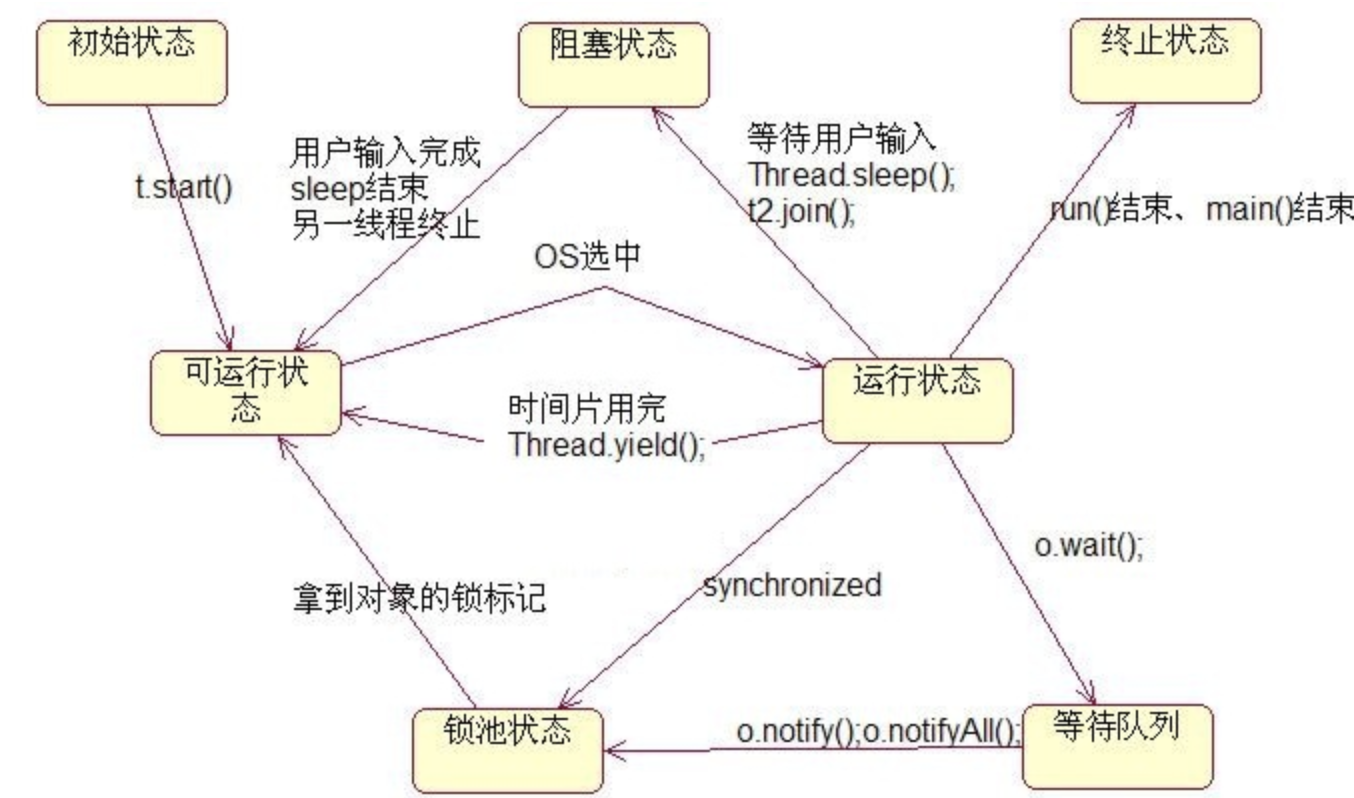
1、当线程调用了自身的sleep()方法或其他线程的join()方法,就会进入阻塞状态(该状态既停止当前线程,但并不释放所占有的资源) 。当sleep()结束或join()结束后,该线程进入可运行状态,继续等待OS分配时间片;
2、线程调用了yield()方法,意思是放弃当前获得的CPU时间片,回到可运行状态 ,这时与其他进程处于同等竞争状态,OS有可能会接着又让这个进程进入运行状态;
3、当线程刚进入可运行状态(即就绪状态),发现将要调用的资源被synchroniza(同步),获取不到锁标记,将会立即进入锁池状态,等待获取锁标记(这时的锁池里也许已经有了其他线程在等待获取锁标记,这时它们处于队列状态,既先到先得),一旦线程获得锁标记后,就转入可运行状态,等待 OS分配CPU时间片;
Wait()方法和notify()方法:当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去了对象的锁。当它被一个notify()方法唤醒时,等待池中的线程就被放到了锁池中。该线程从锁池中获得锁,然后回到wait()前的中断现场 。
4、当线程调用wait()方法后会进入等待队列(进入这个状态会释放所占有的所有资源,与阻塞状态不同),进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify()或notifyAll()方法才能被唤醒 ( wait(1000)时可以自动唤醒 ) (由于notify()只是唤醒一个线程,但我们由不能确定具体唤醒的是哪一个线程,也许我们需要唤醒的线程不能够被唤醒,因此在实际使用时,一般都用notifyAll()方法,唤醒有所线程),线程被唤醒后会进入锁池,等待获取锁标记。
使用线程池的好处
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
Executor 框架
框架组成
- 任务(
Runnable/Callable)
执行任务需要实现的 Runnable 接口 或 Callable接口。Runnable 接口或 Callable 接口 实现类都可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。
- 任务的执行(
Executor)
如下图所示,包括任务执行机制的核心接口 Executor ,以及继承自 Executor 接口的 ExecutorService 接口。ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 这两个关键类实现了 ExecutorService 接口。
这里提了很多底层的类关系,但是,实际上我们需要更多关注的是 ThreadPoolExecutor 这个类,这个类在我们实际使用线程池的过程中,使用频率还是非常高的。
注意: 通过查看
ScheduledThreadPoolExecutor源代码我们发现ScheduledThreadPoolExecutor实际上是继承了ThreadPoolExecutor并实现了 ScheduledExecutorService ,而ScheduledExecutorService又实现了ExecutorService,正如我们下面给出的类关系图显示的一样。
ThreadPoolExecutor 类描述:
//AbstractExecutorService实现了ExecutorService接口
public class ThreadPoolExecutor extends AbstractExecutorService
ScheduledThreadPoolExecutor 类描述:
//ScheduledExecutorService实现了ExecutorService接口
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService
- 异步计算的结果(
Future)
Future 接口以及 Future 接口的实现类 FutureTask 类都可以代表异步计算的结果。
当我们把 Runnable接口 或 Callable 接口 的实现类提交给 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 执行。(调用 submit() 方法时会返回一个 FutureTask 对象)
Executor 使用流程
- 主线程首先要创建实现
Runnable或者Callable接口的任务对象。 - 把创建完成的实现
Runnable/Callable接口的 对象直接交给ExecutorService执行:ExecutorService.execute(Runnable command))或者也可以把Runnable对象或Callable对象提交给ExecutorService执行(ExecutorService.submit(Runnable task)或ExecutorService.submit(Callable task))。 - 如果执行
ExecutorService.submit(…),ExecutorService将返回一个实现Future接口的对象(我们刚刚也提到过了执行execute()方法和submit()方法的区别,submit()会返回一个FutureTask 对象)。由于 FutureTask实现了Runnable,我们也可以创建FutureTask,然后直接交给ExecutorService执行。 - 最后,主线程可以执行
FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
ThreadPoolExecutor
ThreadPoolExecutor 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize: 核心线程数线程数定义了最小可以同时运行的线程数量。maximumPoolSize: 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
keepAliveTime:当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁;unit:keepAliveTime参数的时间单位。threadFactory:executor 创建新线程的时候会用到。handler:饱和策略。关于饱和策略下面单独介绍一下。
ThreadPoolExecutor 饱和策略定义:
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor 定义一些策略:
ThreadPoolExecutor.AbortPolicy:抛出RejectedExecutionException异常。ThreadPoolExecutor.CallerRunsPolicy:提交线程的任务,自己执行。调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃队列中最靠前的任务,然后执行此任务。
ThreadPoolExecutor 使用示例
首先创建一个 Runnable 接口的实现类(当然也可以是 Callable 接口,我们上面也说了两者的区别。)
MyRunnable.java
import java.util.Date;
/**
* 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
* @author shuang.kou
*/
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
编写测试程序,我们这里以阿里巴巴推荐的使用 ThreadPoolExecutor 构造函数自定义参数的方式来创建线程池。
ThreadPoolExecutorDemo.java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
可以看到我们上面的代码指定了:
corePoolSize: 核心线程数为 5。maximumPoolSize:最大线程数 10keepAliveTime: 等待时间为 1L。unit: 等待时间的单位为 TimeUnit.SECONDS。workQueue:任务队列为ArrayBlockingQueue,并且容量为 100;handler:饱和策略为CallerRunsPolicy。
Output:
pool-1-thread-2 Start. Time = Tue Nov 12 20:59:44 CST 2019
pool-1-thread-5 Start. Time = Tue Nov 12 20:59:44 CST 2019
pool-1-thread-4 Start. Time = Tue Nov 12 20:59:44 CST 2019
pool-1-thread-1 Start. Time = Tue Nov 12 20:59:44 CST 2019
pool-1-thread-3 Start. Time = Tue Nov 12 20:59:44 CST 2019
pool-1-thread-5 End. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-3 End. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-2 End. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-4 End. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-1 End. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-2 Start. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-1 Start. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-4 Start. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-3 Start. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-5 Start. Time = Tue Nov 12 20:59:49 CST 2019
pool-1-thread-2 End. Time = Tue Nov 12 20:59:54 CST 2019
pool-1-thread-3 End. Time = Tue Nov 12 20:59:54 CST 2019
pool-1-thread-4 End. Time = Tue Nov 12 20:59:54 CST 2019
pool-1-thread-5 End. Time = Tue Nov 12 20:59:54 CST 2019
pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
Runnable vs Callable
Runnable 接口不会返回结果或抛出检查异常,但是**Callable 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口,这样代码看起来会更加简洁。
工具类 Executors 可以实现 Runnable 对象和 Callable 对象之间的相互转换。(Executors.callable(Runnable task)或 Executors.callable(Runnable task,Object resule))。
Runnable.java
@FunctionalInterface
public interface Runnable {
/**
* 被线程执行,没有返回值也无法抛出异常
*/
public abstract void run();
}
Callable.java
@FunctionalInterface
public interface Callable<V> {
/**
* 计算结果,或在无法这样做时抛出异常。
* @return 计算得出的结果
* @throws 如果无法计算结果,则抛出异常
*/
V call() throws Exception;
}
execute() vs submit()
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;submit()方法用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象可以判断任务是否执行成功,并且可以通过Future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
我们以**AbstractExecutorService**接口中的一个 submit 方法为例子来看看源代码:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
上面方法调用的 newTaskFor 方法返回了一个 FutureTask 对象。
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
我们再来看看execute()方法:
public void execute(Runnable command) {
...
}
shutdown() vs shutdownNow()
shutdown():关闭线程池,线程池的状态变为SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。shutdownNow():关闭线程池,线程的状态变为STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List。
isTerminated() vs isShutdown()
isShutDown当调用shutdown()方法后返回为 true。isTerminated当调用shutdown()方法后,并且所有提交的任务完成后返回为 true
为什么不推荐使用FixedThreadPool
FixedThreadPool 使用无界队列 LinkedBlockingQueue(队列的容量为 Intger.MAX_VALUE)作为线程池的工作队列会对线程池带来如下影响 :
- 当线程池中的线程数达到
corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过 corePoolSize; - 由于使用无界队列时
maximumPoolSize将是一个无效参数,因为不可能存在任务队列满的情况。所以,通过创建FixedThreadPool的源码可以看出创建的FixedThreadPool的corePoolSize和maximumPoolSize被设置为同一个值。 - 由于 1 和 2,使用无界队列时
keepAliveTime将是一个无效参数; - 运行中的
FixedThreadPool(未执行shutdown()或shutdownNow())不会拒绝任务,在任务比较多的时候会导致 OOM(内存溢出)。
线程池大小确定
有一个简单并且适用面比较广的公式:
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
线程创建的方式
- 继承Thread类
- 实现Runnable接口
- Excutor创建一个线程的线程池
线程池的创建方式
- newCachedThreadPool(可以自动扩展或者回收)
- newFixedThreadPool (设定固定长度线程池,超出则会放在队列钟等待)
- newScheduledThreadPool(创建一定长度线程,周期性执行任务)
- newSingleThreadExecutor(创建单个线程的线程池)
java中有哪些锁
公平锁、非公平锁、可重入锁、自旋锁、独占锁、共享锁
-
公平锁:是指多个线程按照申请的顺序来获取值
-
非公平锁:是值多个线程获取值的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并 发的情况下,可能会造成优先级翻转或者饥饿现象
区别
公平锁:在并发环境中,每一个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一 个就占有锁,否者就会加入到等待队列中,以后会按照 FIFO 的规则获取锁
非公平锁:一上来就尝试占有锁,如果失败在进行排队
-
重入锁(递归锁):指的是同一个线程外层函数获得锁之后,内层仍然能获取到该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法或会自动获取该锁。也就是说,线程可以进入任何一个他已经拥有的锁的同步代码块。ReentrantLook / Synchronized就是一个典型的可重入锁,作用:防止死锁
-
synchronized
- 是一个关键字
- 程序执行完毕之后才会释放锁
-
lock
- 是一个接口,其中实现就有 ReentrantLock
- 手动释放锁
synchronized关键字最主要的三种使用方式
- 修饰实例方法,作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
- 修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁 。也就是给当前类加锁,会作 用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态 资源,不管new了多少个对象,只有一份,所以对该类的所有对象都加了锁)。所以如果一个线程A调用一个实 例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允 许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
- 修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。 和 synchronized 方 法一样,synchronized(this)代码块也是锁定当前对象的。synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。这里再提一下:synchronized关键字加到非 static 静态 方法上是给对象实例上锁。另外需要注意的是:尽量不要使用 synchronized(String a) 因为JVM中,字符串常量 池具有缓冲功能!
synchronized和lock区别
1.首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
2.synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
3.synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
4.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
5.synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
6.Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
原理区别
Lock锁使用的是CAS和volatile来实现同步的,CAS使用硬件命令实现缓存一致性保证了原子性,volatile保证了可见性,所线程环境下所有的线程通过CAS进行竞争资源,只能有一个成功,其它的都会自旋
Volatile 变量
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile 变量的最新值。Volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
- 禁止进行指令重排序。(实现有序性)
- volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
悲观锁与乐观锁
乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。。
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
乐观锁常见的两种实现方式
版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
CAS算法
即compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
CAS与synchronized的使用情景
简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
- 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
IO
同步与异步
- 同步: 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
- 异步: 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
阻塞和非阻塞
- 阻塞: 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- 非阻塞: 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(同步阻塞)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
BIO (Blocking I/O)
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
示例:
客户端
/**
*
* @author 闪电侠
* @date 2018年10月14日
* @Description:客户端
*/
public class IOClient {
public static void main(String[] args) {
// TODO 创建多个线程,模拟多个客户端连接服务端
new Thread(() -> {
try {
Socket socket = new Socket("127.0.0.1", 3333);
while (true) {
try {
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
Thread.sleep(2000);
} catch (Exception e) {
}
}
} catch (IOException e) {
}
}).start();
}
}
服务端
/**
* @author 闪电侠
* @date 2018年10月14日
* @Description: 服务端
*/
public class IOServer {
public static void main(String[] args) throws IOException {
// TODO 服务端处理客户端连接请求
ServerSocket serverSocket = new ServerSocket(3333);
// 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
new Thread(() -> {
while (true) {
try {
// 阻塞方法获取新的连接
Socket socket = serverSocket.accept();
// 每一个新的连接都创建一个线程,负责读取数据
new Thread(() -> {
try {
int len;
byte[] data = new byte[1024];
InputStream inputStream = socket.getInputStream();
// 按字节流方式读取数据
while ((len = inputStream.read(data)) != -1) {
System.out.println(new String(data, 0, len));
}
} catch (IOException e) {
}
}).start();
} catch (IOException e) {
}
}
}).start();
}
}
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (New I/O)
NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。
NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
代码示例:
/**
*
* @author 闪电侠
* @date 2019年2月21日
* @Description: NIO 改造后的服务端
*/
public class NIOServer {
public static void main(String[] args) throws IOException {
// 1. serverSelector负责轮询是否有新的连接,服务端监测到新的连接之后,不再创建一个新的线程,
// 而是直接将新连接绑定到clientSelector上,这样就不用 IO 模型中 1w 个 while 循环在死等
Selector serverSelector = Selector.open();
// 2. clientSelector负责轮询连接是否有数据可读
Selector clientSelector = Selector.open();
new Thread(() -> {
try {
// 对应IO编程中服务端启动
ServerSocketChannel listenerChannel = ServerSocketChannel.open();
listenerChannel.socket().bind(new InetSocketAddress(3333));
listenerChannel.configureBlocking(false);
listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT);
while (true) {
// 监测是否有新的连接,这里的1指的是阻塞的时间为 1ms
if (serverSelector.select(1) > 0) {
Set<SelectionKey> set = serverSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
try {
// (1) 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
clientChannel.configureBlocking(false);
clientChannel.register(clientSelector, SelectionKey.OP_READ);
} finally {
keyIterator.remove();
}
}
}
}
}
} catch (IOException ignored) {
}
}).start();
new Thread(() -> {
try {
while (true) {
// (2) 批量轮询是否有哪些连接有数据可读,这里的1指的是阻塞的时间为 1ms
if (clientSelector.select(1) > 0) {
Set<SelectionKey> set = clientSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isReadable()) {
try {
SocketChannel clientChannel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// (3) 面向 Buffer
clientChannel.read(byteBuffer);
byteBuffer.flip();
System.out.println(
Charset.defaultCharset().newDecoder().decode(byteBuffer).toString());
} finally {
keyIterator.remove();
key.interestOps(SelectionKey.OP_READ);
}
}
}
}
}
} catch (IOException ignored) {
}
}).start();
}
}
NIO的特性/NIO与IO区别
1. IO流是阻塞的,NIO流是不阻塞的。
Java NIO使我们可以进行非阻塞IO操作。比如说,单线程中从通道读取数据到buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程再继续处理数据。写数据也是一样的。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
Java IO的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write() 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
2. Buffer(缓冲区)
IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
Buffer是一个对象,它包含一些要写入或者要读出的数据。在NIO类库中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中·可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
在NIO厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
最常用的缓冲区是 ByteBuffer,一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了ByteBuffer,还有其他的一些缓冲区,事实上,每一种Java基本类型(除了Boolean类型)都对应有一种缓冲区。
3. Channel (通道)
NIO 通过Channel(通道) 进行读写。
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
4. Selector (选择器)
NIO有选择器,而IO没有。
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
NIO 读数据和写数据方式
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
AIO (Asynchronous I/O)
AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。
Java注解
自定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
通过反射机制,和动态代理机制
Java动态代理
实现原理
通过拦截器和反射技术实现
- 需要实现InvocationHandler 接口
- Proxy来创建实例
cglib动态代理区别
cglib是通过修改字节码生成子类处理
-
JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
-
如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
JVM
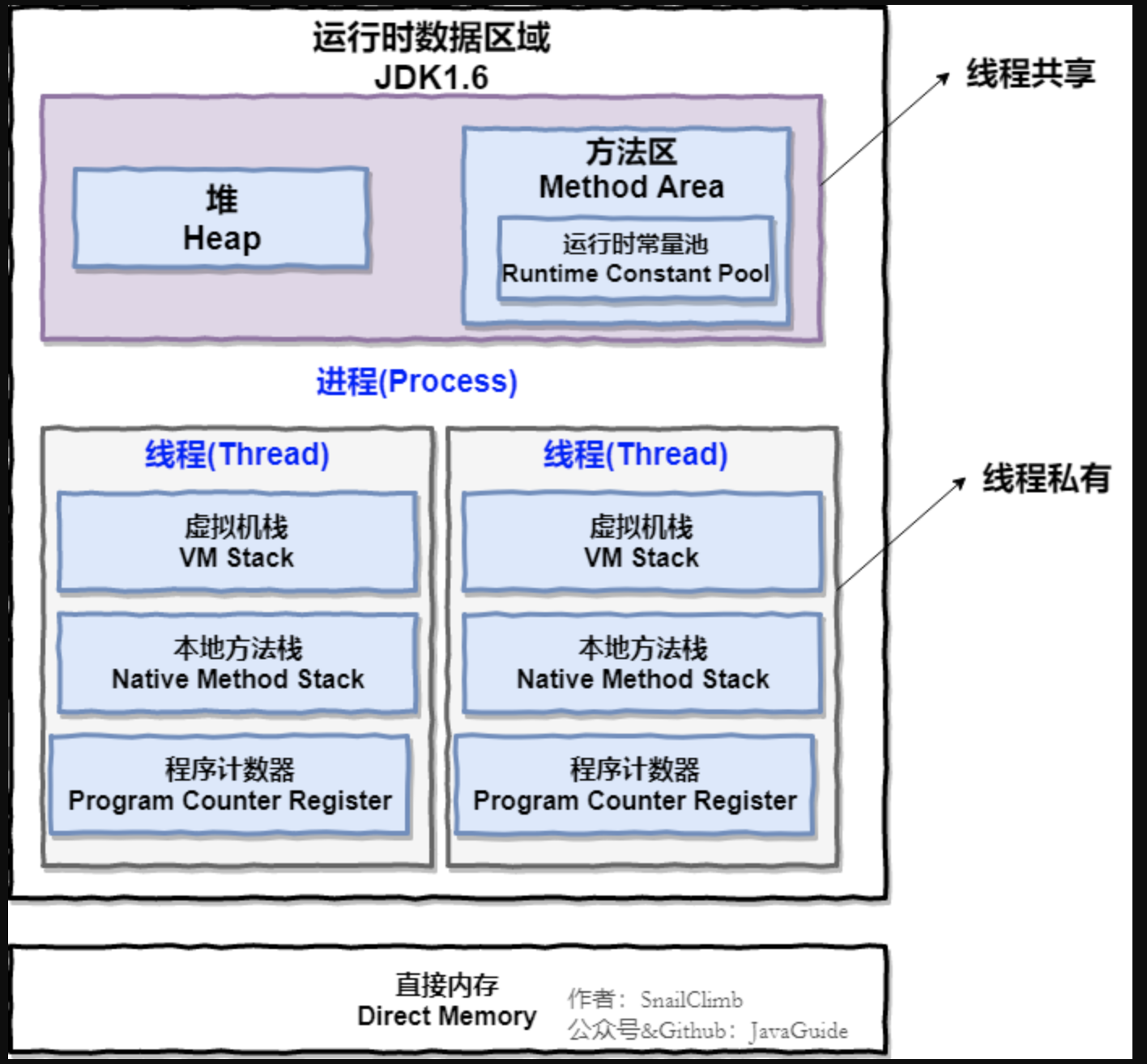
JVM内存模型
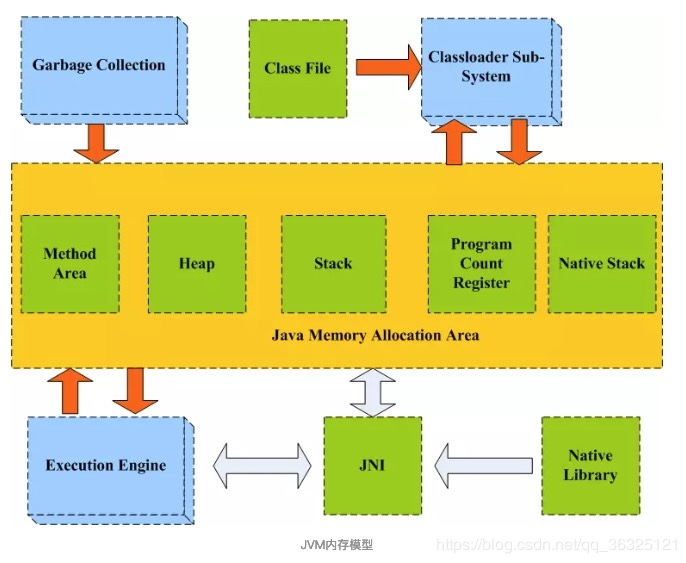
-
方法区(Method Area): 静态变量,常量,类,共享区域。
与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。
Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。 (实际上,Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。
- StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 异常。
- OutOfMemoryError: 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出 OutOfMemoryError 异常。
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
-
堆(Heap):存放实例,数组,垃圾回收。
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC 堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
上图所示的 eden 区、s0 区、s1 区都属于新生代,tentired 区属于老年代。大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数
-XX:MaxTenuringThreshold来设置。 -
栈(Stack): 每个线程一个栈区,用于基本类型,及对象的应用。
与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。
Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。 (实际上,Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。
- StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 异常。
- OutOfMemoryError: 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出 OutOfMemoryError 异常。
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
扩展:那么方法/函数如何调用?
Java 栈可用类比数据结构中栈,Java 栈中保存的主要内容是栈帧,每一次函数调用都会有一个对应的栈帧被压入 Java 栈,每一个函数调用结束后,都会有一个栈帧被弹出。
Java 方法有两种返回方式:
- return 语句。
- 抛出异常。
不管哪种返回方式都会导致栈帧被弹出。
-
本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种异常。
-
程序寄存器(ProgramCountRegister): 记录每个线程的位置
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
另外,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
从上面的介绍中我们知道程序计数器主要有两个作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
注意:程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
常用参数
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
-XX:PermSize=N //方法区 (永久代) 初始大小
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
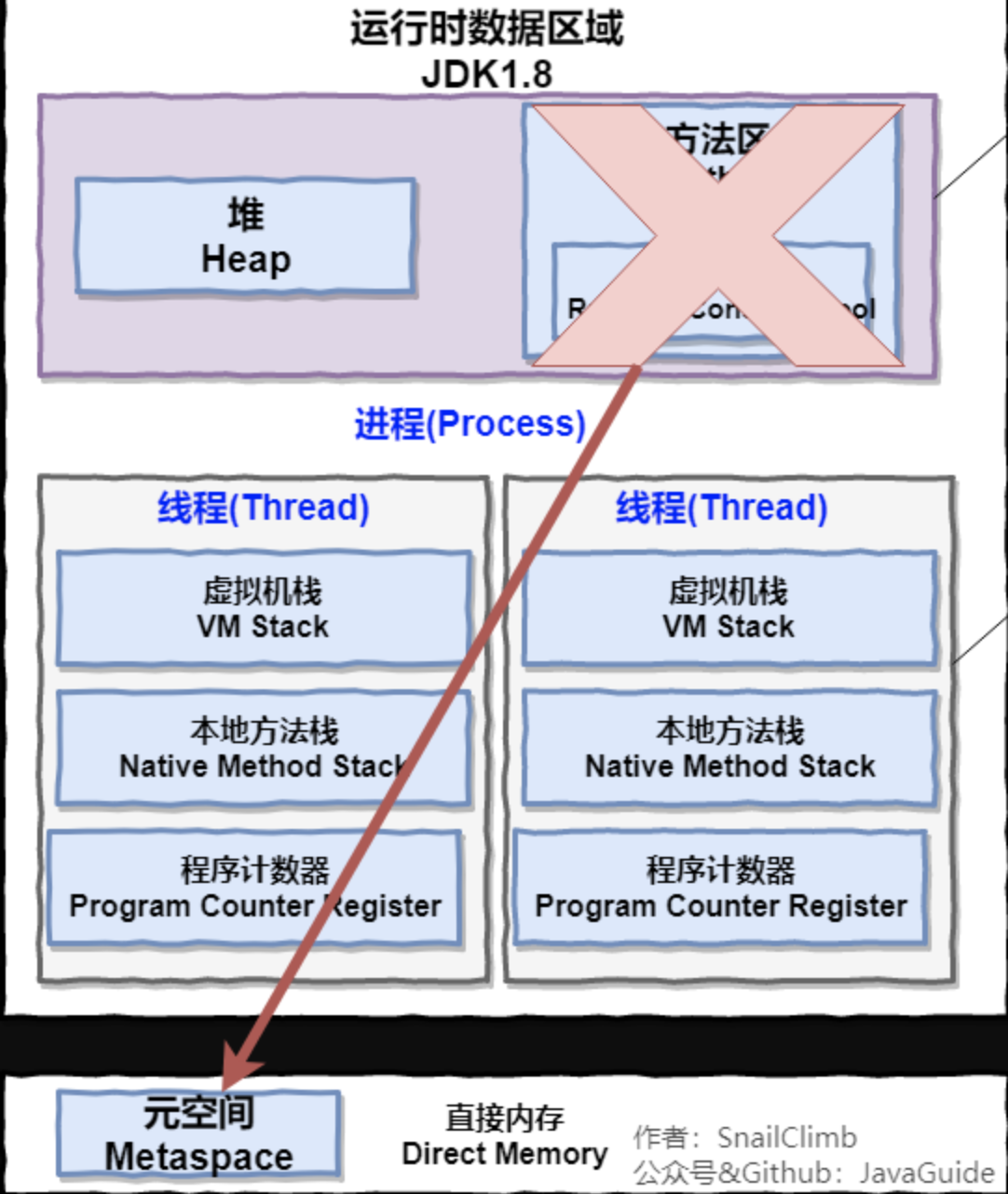
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
下面是一些常用参数:
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace)
永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,并且永远不会得到 java.lang.OutOfMemoryError。你可以使用 -XX:MaxMetaspaceSize 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。-XX:MetaspaceSize 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
JVM如何加载类
类加载过程
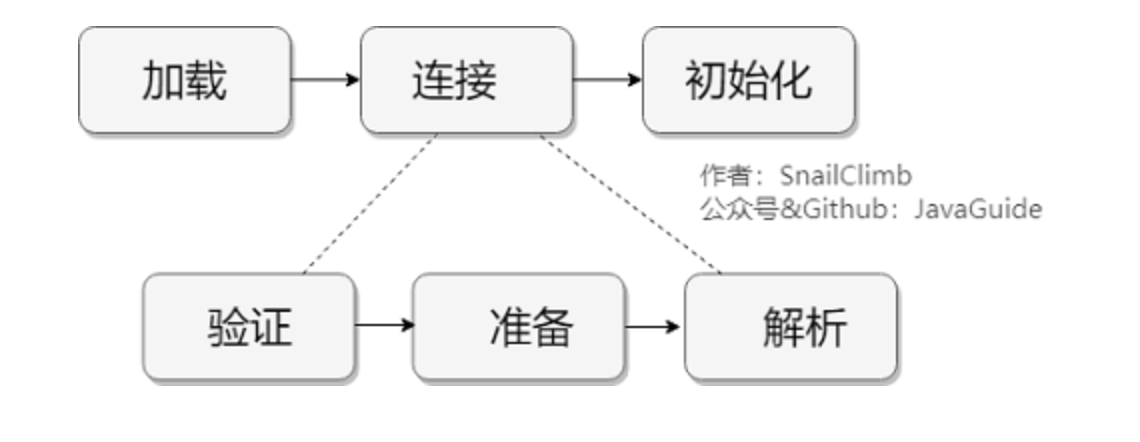
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
系统加载 Class 类型的文件主要三步:加载->连接->初始化。连接过程又可分为三步:验证->准备->解析。
加载
类加载过程的第一步,主要完成下面3件事情:
- 通过全类名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:“通过全类名获取定义此类的二进制字节流” 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 loadClass() 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
类加载器、双亲委派模型也是非常重要的知识点,这部分内容会在后面的文章中单独介绍到。
加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
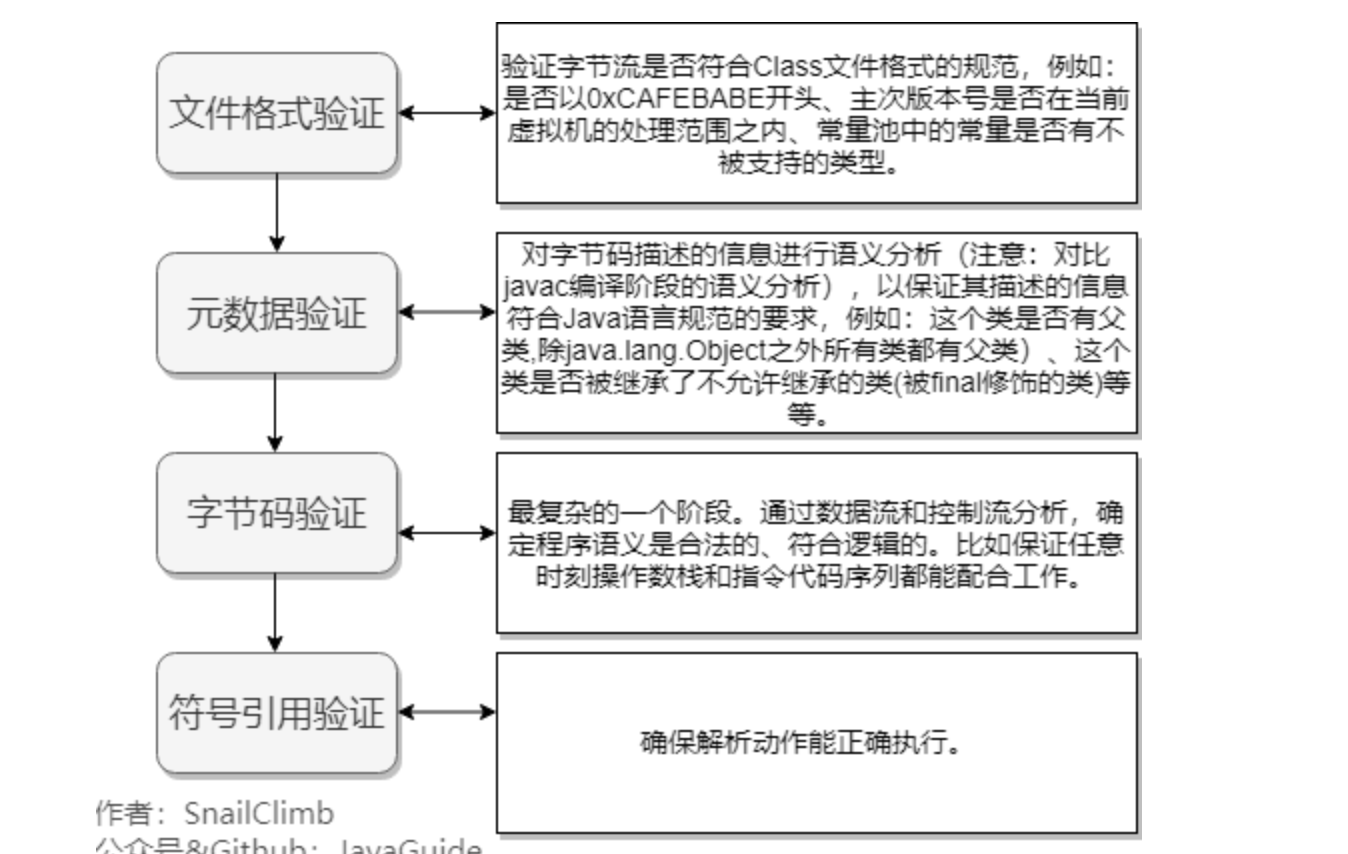
验证
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
- 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
- 这里所设置的初始值"通常情况"下是数据类型默认的零值(如0、0L、null、false等),比如我们定义了
public static int value=111,那么 value 变量在准备阶段的初始值就是 0 而不是111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 fianl 关键字public static final int value=111,那么准备阶段 value 的值就被赋值为 111。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
符号引用就是一组符号来描述目标,可以是任何字面量。直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方发表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
综上,解析阶段是虚拟
初始化
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ()方法的过程。
对于() 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 () 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化:
- 当遇到 new 、 getstatic、putstatic或invokestatic 这4条直接码指令时,比如 new 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
- 使用
java.lang.reflect包的方法对类进行反射调用时 ,如果类没初始化,需要触发其初始化。 - 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
- 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
- 当使用 JDK1.7 的动态动态语言时,如果一个 MethodHandle 实例的最后解析结构为 REF_getStatic、REF_putStatic、REF_invokeStatic、的方法句柄,并且这个句柄没有初始化,则需要先触发器初始化。
类加载器
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader:
-
Bootstrap (加载核心库,lib下面的所有jar)
最顶层的加载类,由C++实现,负责加载
%JAVA_HOME%/lib目录下的jar包和类或者或被-Xbootclasspath参数指定的路径中的所有类-
Extention (加载lib/ext下面的所有jar,及自定义目录的jar)
主要负责加载目录
%JRE_HOME%/lib/ext目录下的jar包和类,或被java.ext.dirs系统变量所指定的路径下的jar包。 -
Appclass Loader (最后加载classpath下面所有文件)
面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
-
双亲委派模型
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 双亲委派模型 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派该父类加载器的 loadClass() 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 BootstrapClassLoader 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为null时,会使用启动类加载器 BootstrapClassLoader 作为父类加载器。
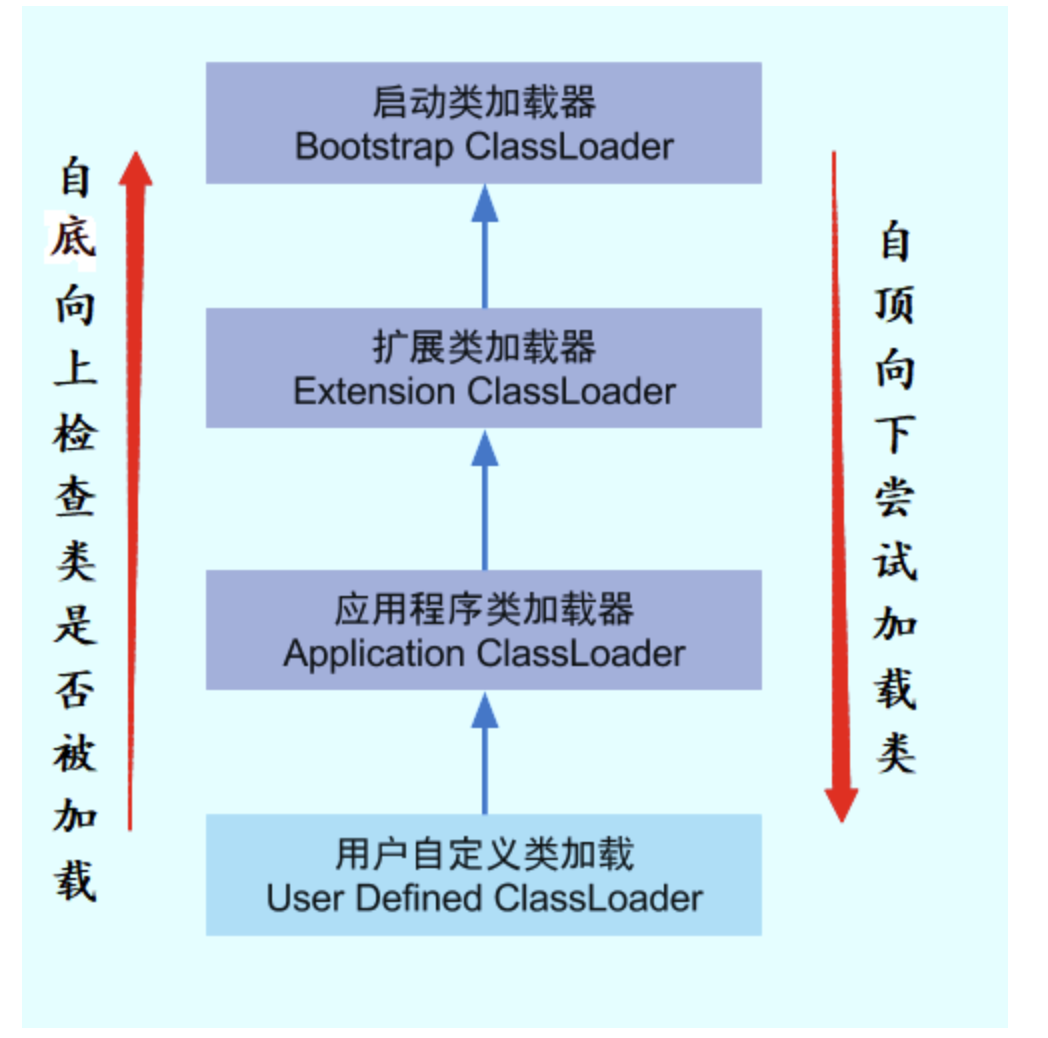
作用
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类。
若不使用双亲委派模型
我们可以自己定义一个类加载器,然后重写 loadClass() 即可。
自定义类加载器
除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader。如果我们要自定义自己的类加载器,很明显需要继承 ClassLoader。
GC垃圾回收
GC介绍
Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 堆 内存中对象的分配与回收。
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC 堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
堆空间结构
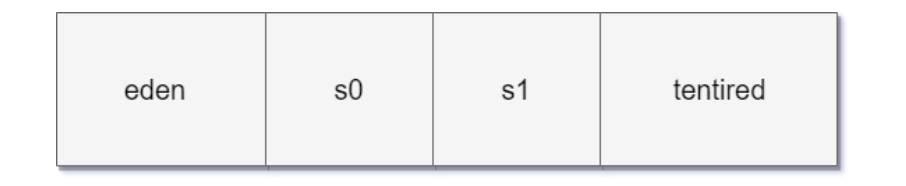
eden 区、s0(“From”) 区、s1(“To”) 区都属于新生代,tentired 区属于老年代。
- 对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s1(“To”),并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数
-XX:MaxTenuringThreshold来设置。 - 经过这次GC后,Eden区和"From"区已经被清空。这个时候,“From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的“From”,新的"From"就是上次GC前的"To”。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。
对象死亡判断
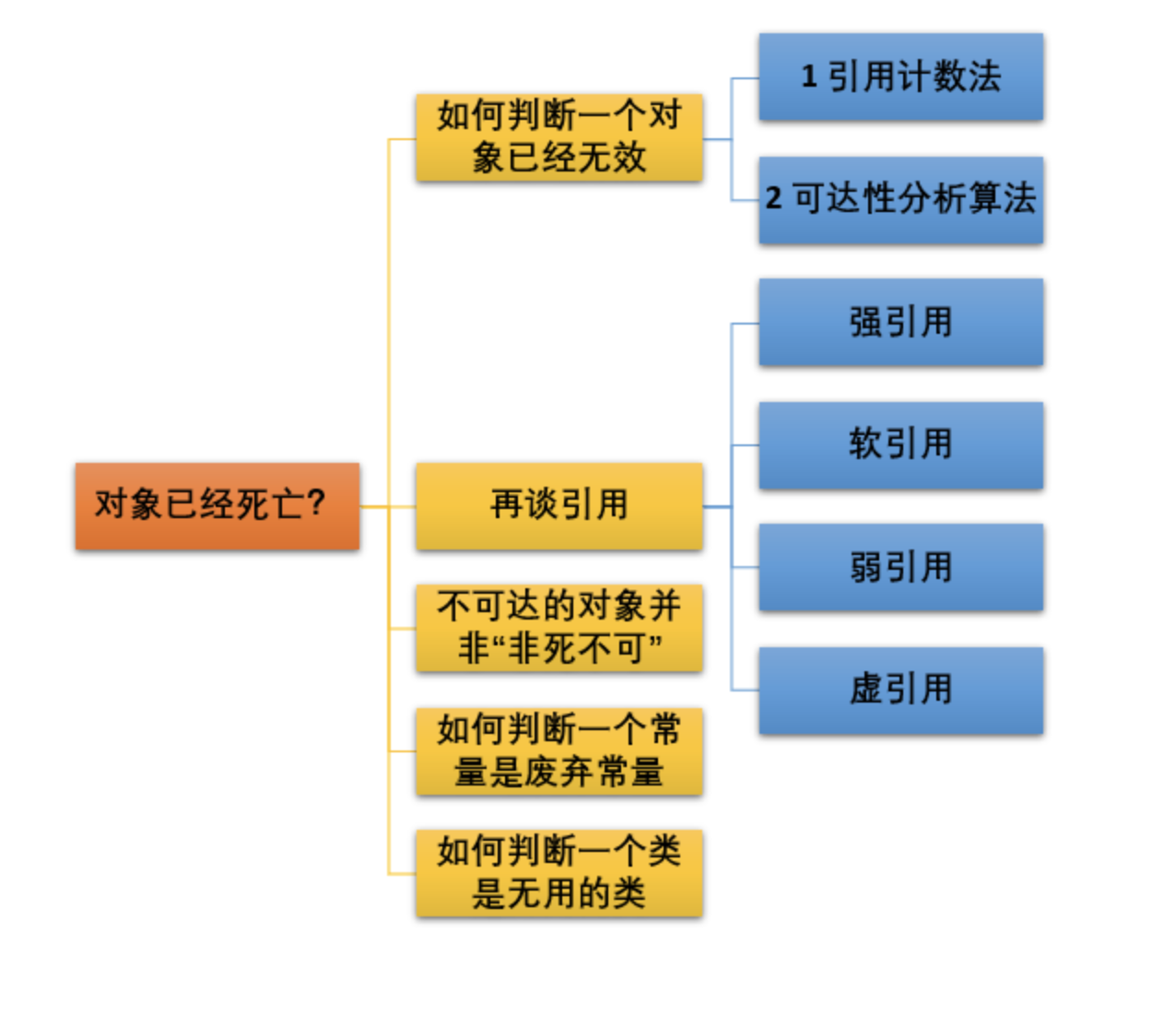
-
应用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。
这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。 所谓对象之间的相互引用问题,如下面代码所示:除了对象 objA 和 objB 相互引用着对方之外,这两个对象之间再无任何引用。但是他们因为互相引用对方,导致它们的引用计数器都不为 0,于是引用计数算法无法通知 GC 回收器回收他们。
-
可达性分析算法
这个算法的基本思想就是通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
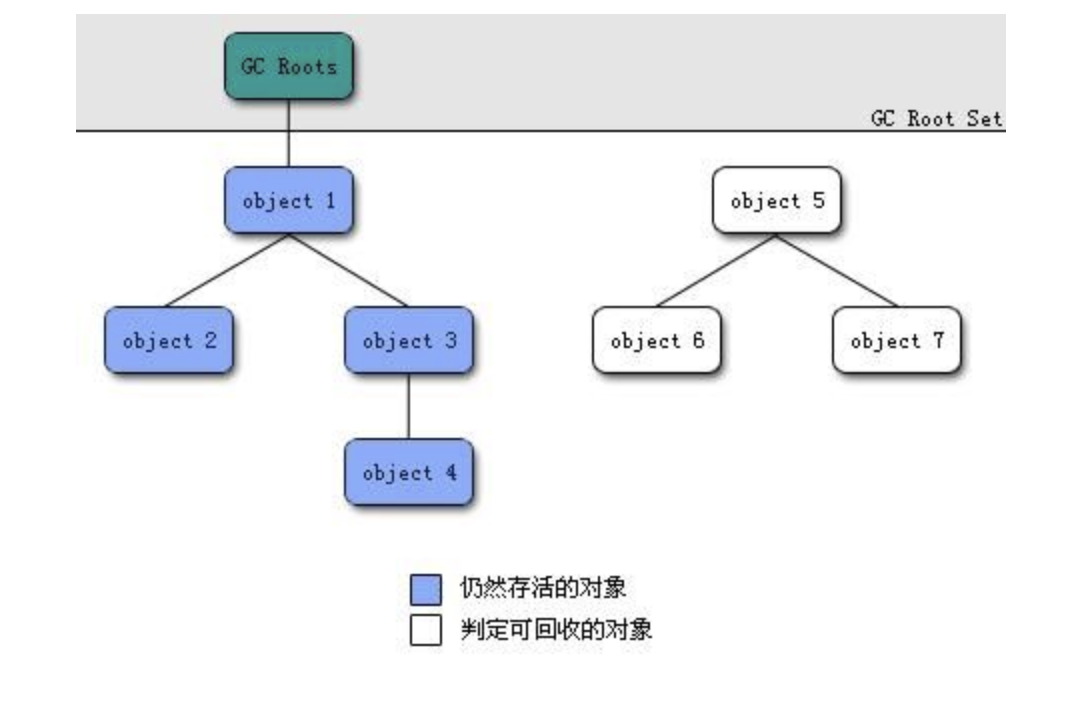
-
引用
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
1.强引用(StrongReference)
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可无的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
如何判断几个常量是废弃的
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
假如在常量池中存在字符串 “abc”,如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 “abc” 就是废弃常量,如果这时发生内存回收的话而且有必要的话,“abc” 就会被系统清理出常量池。
JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
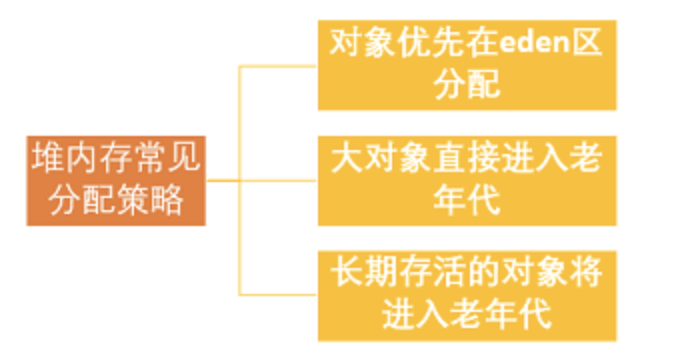
如何判断一个类是无用的
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
垃圾收集算法
- 标记-清除法
- 复制算法
- 标记-整理算法
- 分代收集算法
标记-清除算法
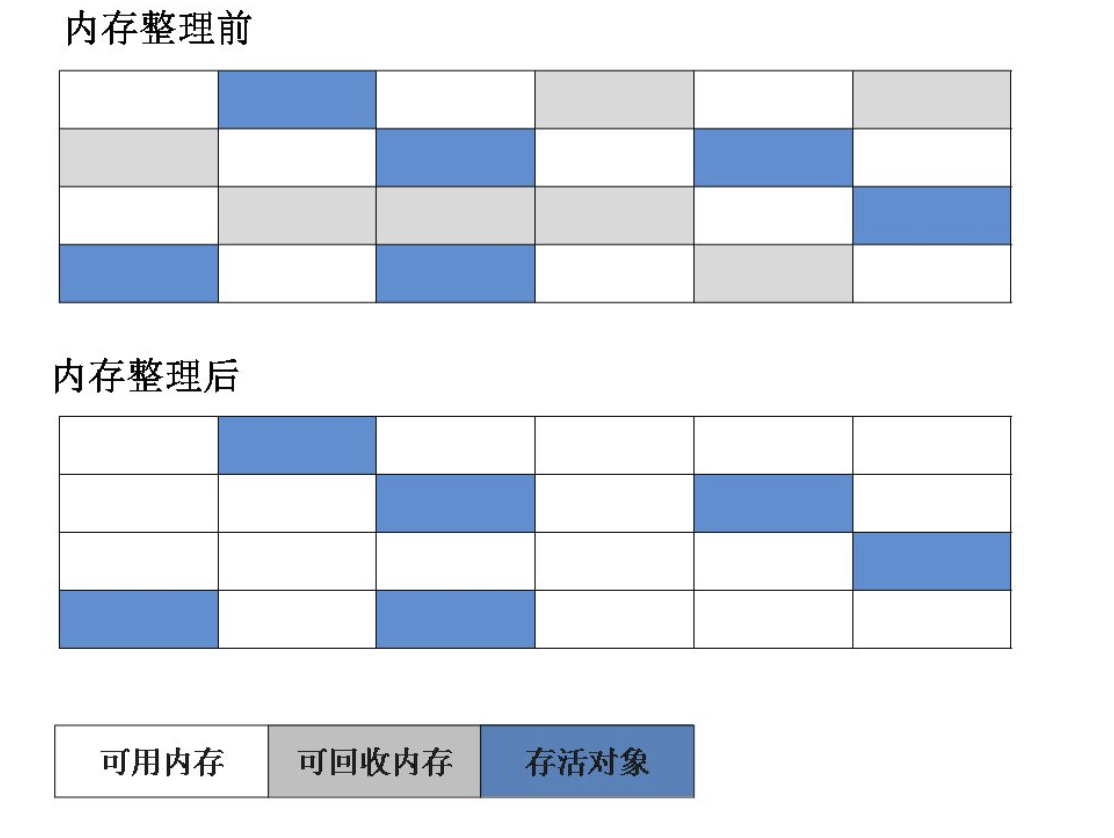
该算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
- 效率问题
- 空间问题(标记清除后会产生大量不连续的碎片)
复制算法
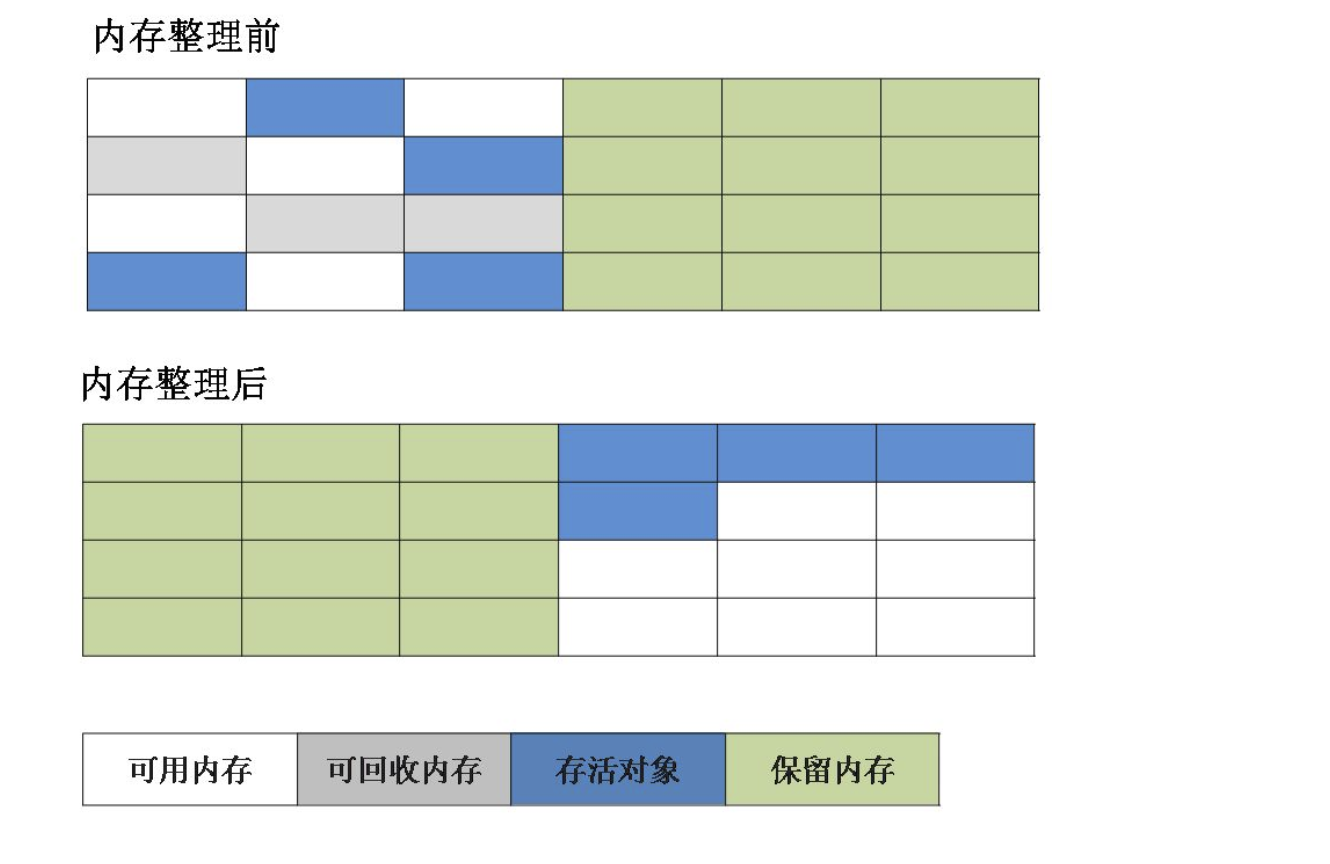
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
标记-整理法
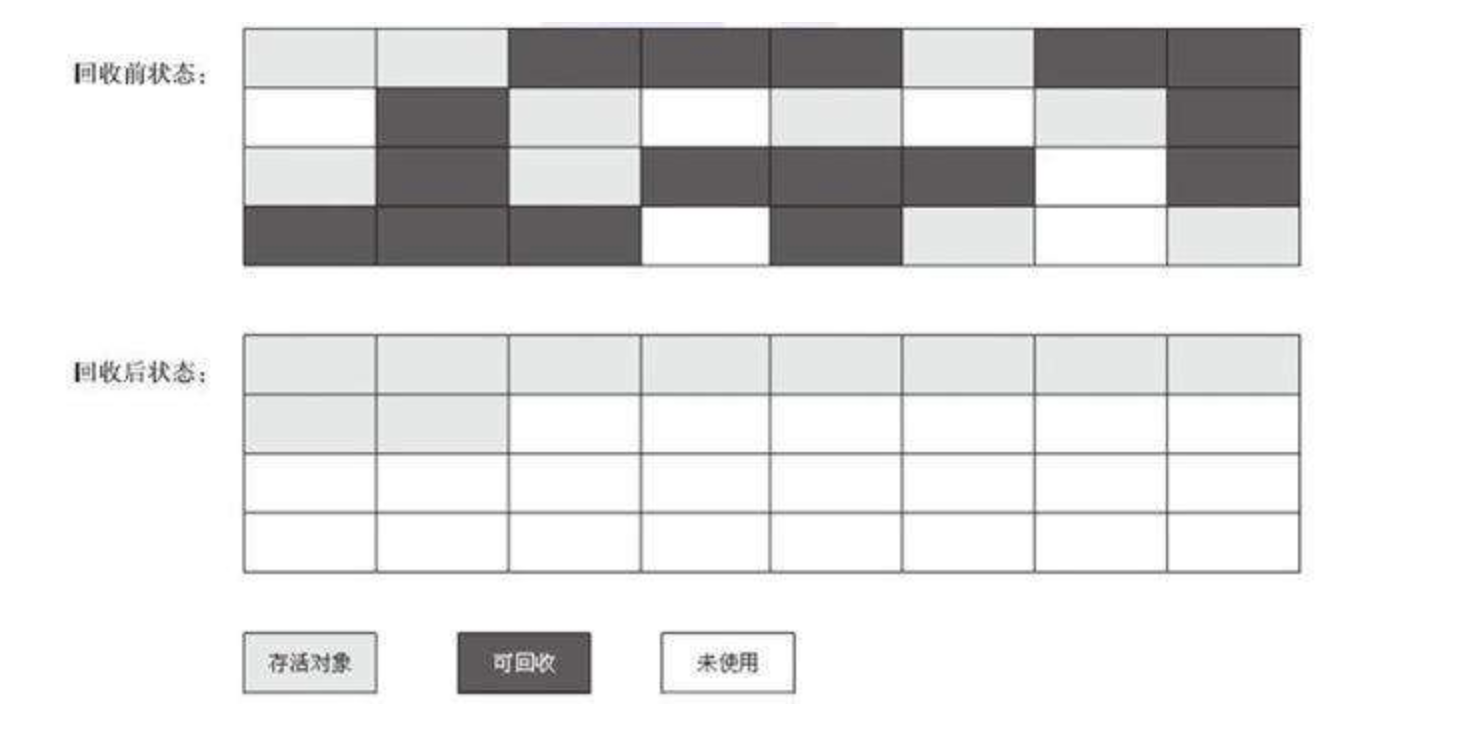
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
新生代:每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
老年代:对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择标记-清除或标记-整理算法进行垃圾收集。
延伸面试问题: HotSpot 为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,我们能做的就是根据具体应用场景选择适合自己的垃圾收集器。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
Serial收集器
Serial(串行)收集器是一个单线程收集器。它在进行垃圾收集工作的时候必须暂停其他所有的工作线程,直到它收集结束。
虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它简单而高效(与其他收集器的单线程相比)。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
特点
- 针对新生代的收集器;
- 采用复制算法;
- 单线程收集;
- 进行垃圾收集时,必须暂停所有工作线程,直到完成;
即会"Stop The World";
应用场景
依然是HotSpot在Client模式下默认的新生代收集器;
简单高效(与其他收集器的单线程相比);
对于限定单个CPU的环境来说,Serial收集器没有线程交互(切换)开销,可以获得最高的单线程收集效率;
在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的
设置
添加该参数来显式的使用串行垃圾收集器:
-XX:+UseSerialGC
ParNew 收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
并行和并发概念补充:
- 并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
特点
- 除了多线程外,其余的行为、特点和Serial收集器一样;
- 如Serial收集器可用控制参数、收集算法、Stop The World、内存分配规则、回收策略等;
- Serial收集器共用了不少代码;
应用场景
在Server模式下,ParNew收集器是一个非常重要的收集器,因为除Serial外,目前只有它能与CMS收集器配合工作;
但在单个CPU环境中,不会比Serail收集器有更好的效果,因为存在线程交互开销。
Parallel Scavenge 收集器
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew都一样。 那么它有什么特别之处呢?
-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
使用 Parallel 收集器+ 老年代并行
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。 Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
特点
- 新生代收集器;
- 采用复制算法;
- 多线程收集;
- CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间;而Parallel Scavenge收集器的目标则是达一个可控制的吞吐量(Throughput)
####CMS(Concurrent Mark Sweep)收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
从名字中的Mark Sweep这两个词可以看出,CMS 收集器是一种 “标记-清除”算法实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
- 初始标记: 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- 并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- 重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
- 并发清除: 开启用户线程,同时 GC 线程开始对为标记的区域做清扫。
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。
指定使用CMS收集器
"-XX:+UseConcMarkSweepGC"
特点
- 针对老年代
- 基于"标记-清除"算法(不进行压缩操作,会产生内存碎片)
- 以获取最短回收停顿时间为目标
- 并发收集、低停顿
- 需要更多的内存
G1 (Garbage-First)收集器
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
- 并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
- 分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
- 空间整合:与 CMS 的“标记–清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
- 可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
G1 收集器的运作大致分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 GF 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
GC调优
显示指定堆内存-Xms和-Xmx
与性能有关的最常见实践之一是根据应用程序要求初始化堆内存。如果我们需要指定最小和最大堆大小(推荐显示指定大小),以下参数可以帮助你实现:
-Xms<heap size>[unit]
-Xmx<heap size>[unit]
- heap size 表示要初始化内存的具体大小。
- unit 表示要初始化内存的单位。单位为***“ g”*** (GB) 、*“ m”*(MB)、*“ k”*(KB)。
如果我们要为JVM分配最小2 GB和最大5 GB的堆内存大小,我们的参数应该这样来写:
-Xms2G -Xmx5G
显示新生代内存
根据Oracle官方文档,在堆总可用内存配置完成之后,第二大影响因素是为 Young Generation 在堆内存所占的比例。默认情况下,YG 的最小大小为 1310 MB,最大大小为无限制。
一共有两种指定 新生代内存(Young Ceneration)大小的方法:
1.通过-XX:NewSize和-XX:MaxNewSize指定
-XX:NewSize=<young size>[unit]
-XX:MaxNewSize=<young size>[unit]
举个栗子🌰,如果我们要为 新生代分配 最小256m 的内存,最大 1024m的内存我们的参数应该这样来写:
-XX:NewSize=256m
-XX:MaxNewSize=1024m
2.通过-Xmn[unit]指定
举个栗子🌰,如果我们要为 新生代分配256m的内存(NewSize与MaxNewSize设为一致),我们的参数应该这样来写:
-Xmn256m
GC 调优策略中很重要的一条经验总结是这样说的:
将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
另外,你还可以通过**-XX:NewRatio=**来设置新生代和老年代内存的比值。
比如下面的参数就是设置新生代(包括Eden和两个Survivor区)与老年代的比值为1。也就是说:新生代与老年代所占比值为1:1,新生代占整个堆栈的 1/2。
-XX:NewRatio=1
显示指定永久代/元空间大小
从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
-XX:PermSize=N //方法区 (永久代) 初始大小
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
下面是一些常用参数:
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用
GC调优策略
**策略 1:**将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
**策略 2:**大对象进入老年代,虽然大部分情况下,将对象分配在新生代是合理的。但是对于大对象这种做法却值得商榷,大对象如果首次在新生代分配可能会出现空间不足导致很多年龄不够的小对象被分配的老年代,破坏新生代的对象结构,可能会出现频繁的 full gc。因此,对于大对象,可以设置直接进入老年代(当然短命的大对象对于垃圾回收来说简直就是噩梦)。-XX:PretenureSizeThreshold 可以设置直接进入老年代的对象大小。
**策略 3:**合理设置进入老年代对象的年龄,-XX:MaxTenuringThreshold 设置对象进入老年代的年龄大小,减少老年代的内存占用,降低 full gc 发生的频率。
**策略 4:**设置稳定的堆大小,堆大小设置有两个参数:-Xms 初始化堆大小,-Xmx 最大堆大小。
**策略5:**注意: 如果满足下面的指标,则一般不需要进行 GC 优化:
MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
JVM配置参数
堆参数

回收器参数
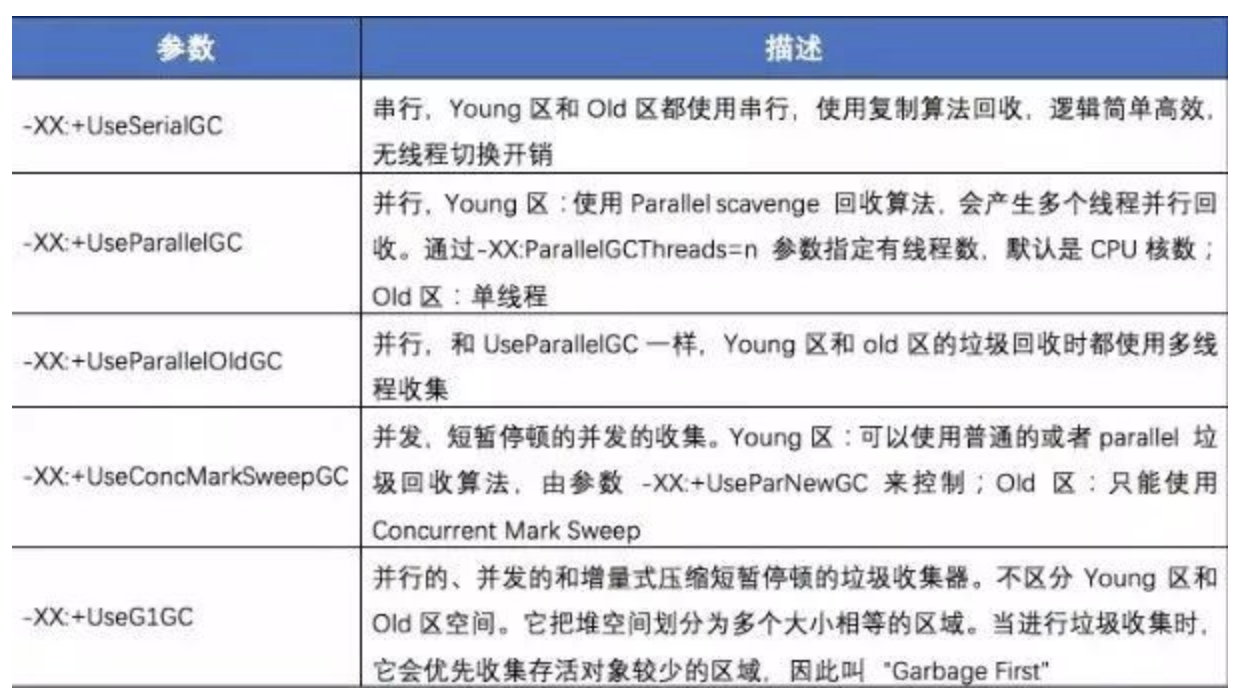
如上表所示,目前主要有串行、并行和并发三种,对于大内存的应用而言,串行的性能太低,因此使用到的主要是并行和并发两种。并行和并发 GC 的策略通过 UseParallelGC和UseConcMarkSweepGC 来指定,还有一些细节的配置参数用来配置策略的执行方式。例如:XX:ParallelGCThreads, XX:CMSInitiatingOccupancyFraction 等。 通常:Young 区对象回收只可选择并行(耗时间),Old 区选择并发(耗 CPU)。
JDK监控工具
这些命令在 JDK 安装目录下的 bin 目录下:
jps(JVM Process Status): 类似 UNIX 的ps命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;jstat( JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;jinfo(Configuration Info for Java) : Configuration Info forJava,显示虚拟机配置信息;jmap(Memory Map for Java) :生成堆转储快照;jhat(JVM Heap Dump Browser ) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;jstack(Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
jps (JVM Process Status)
查看Java进程
jps:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。
jps -q :只输出进程的本地虚拟机唯一 ID。
C:\Users\SnailClimb>jps
7360 NettyClient2
17396
7972 Launcher
16504 Jps
17340 NettyServer
jps -l:输出主类的全名,如果进程执行的是 Jar 包,输出 Jar 路径。
C:\Users\SnailClimb>jps -l
7360 firstNettyDemo.NettyClient2
17396
7972 org.jetbrains.jps.cmdline.Launcher
16492 sun.tools.jps.Jps
17340 firstNettyDemo.NettyServer
jps -v:输出虚拟机进程启动时 JVM 参数。
jps -m:输出传递给 Java 进程 main() 函数的参数。
jstat(JVM Statistics Monitoring Tool)
jstat(JVM Statistics Monitoring Tool) 使用于监视虚拟机各种运行状态信息的命令行工具。 它可以显示本地或者远程(需要远程主机提供 RMI 支持)虚拟机进程中的类信息、内存、垃圾收集、JIT 编译等运行数据,在没有 GUI,只提供了纯文本控制台环境的服务器上,它将是运行期间定位虚拟机性能问题的首选工具。
jstat 命令使用格式:
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
比如 jstat -gc -h3 31736 1000 10表示分析进程 id 为 31736 的 gc 情况,每隔 1000ms 打印一次记录,打印 10 次停止,每 3 行后打印指标头部。
常见的 option 如下:
jstat -class vmid:显示 ClassLoader 的相关信息;jstat -compiler vmid:显示 JIT 编译的相关信息;jstat -gc vmid:显示与 GC 相关的堆信息;jstat -gccapacity vmid:显示各个代的容量及使用情况;jstat -gcnew vmid:显示新生代信息;jstat -gcnewcapcacity vmid:显示新生代大小与使用情况;jstat -gcold vmid:显示老年代和永久代的信息;jstat -gcoldcapacity vmid:显示老年代的大小;jstat -gcpermcapacity vmid:显示永久代大小;jstat -gcutil vmid:显示垃圾收集信息;
另外,加上 -t参数可以在输出信息上加一个 Timestamp 列,显示程序的运行时间。
jinfo
实时查看虚拟机参数
jinfo vmid :输出当前 jvm 进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是 JVM 的参数)。
jinfo -flag name vmid :输出对应名称的参数的具体值。比如输出 MaxHeapSize、查看当前 jvm 进程是否开启打印 GC 日志 ( -XX:PrintGCDetails :详细 GC 日志模式,这两个都是默认关闭的)。
C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340
-XX:MaxHeapSize=2124414976
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数。尤其在线上的环境特别有用,请看下面的例子:
jinfo -flag [+|-]name vmid 开启或者关闭对应名称的参数。
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
C:\Users\SnailClimb>jinfo -flag +PrintGC 17340
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:+PrintGC
jmap
生成堆转储快照
jmap(Memory Map for Java)命令用于生成堆转储快照。 如果不使用 jmap 命令,要想获取 Java 堆转储,可以使用 “-XX:+HeapDumpOnOutOfMemoryError” 参数,可以让虚拟机在 OOM 异常出现之后自动生成 dump 文件,Linux 命令下可以通过 kill -3 发送进程退出信号也能拿到 dump 文件。
jmap 的作用并不仅仅是为了获取 dump 文件,它还可以查询 finalizer 执行队列、Java 堆和永久代的详细信息,如空间使用率、当前使用的是哪种收集器等。和jinfo一样,jmap有不少功能在 Windows 平台下也是受限制的。
示例:将指定应用程序的堆快照输出到桌面。后面,可以通过 jhat、Visual VM 等工具分析该堆文件。
C:\Users\SnailClimb>jmap -dump:format=b,file=C:\Users\SnailClimb\Desktop\heap.hprof 17340
Dumping heap to C:\Users\SnailClimb\Desktop\heap.hprof ...
Heap dump file created
jhat
jhat 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果。
C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof
Reading from C:\Users\SnailClimb\Desktop\heap.hprof...
Dump file created Sat May 04 12:30:31 CST 2019
Snapshot read, resolving...
Resolving 131419 objects...
Chasing references, expect 26 dots..........................
Eliminating duplicate references..........................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
访问 http://localhost:7000/
jstack
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
下面是一个线程死锁的代码。我们下面会通过 jstack 命令进行死锁检查,输出死锁信息,找到发生死锁的线程。
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
Output
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
通过 jstack 命令分析:
C:\Users\SnailClimb>jps
13792 KotlinCompileDaemon
7360 NettyClient2
17396
7972 Launcher
8932 Launcher
9256 DeadLockDemo
10764 Jps
17340 NettyServer
C:\Users\SnailClimb>jstack 9256
输出的部分内容如下:
Found one Java-level deadlock:
=============================
"线程 2":
waiting to lock monitor 0x000000000333e668 (object 0x00000000d5efe1c0, a java.lang.Object),
which is held by "线程 1"
"线程 1":
waiting to lock monitor 0x000000000333be88 (object 0x00000000d5efe1d0, a java.lang.Object),
which is held by "线程 2"
Java stack information for the threads listed above:
===================================================
"线程 2":
at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)
- waiting to lock <0x00000000d5efe1c0> (a java.lang.Object)
- locked <0x00000000d5efe1d0> (a java.lang.Object)
at DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"线程 1":
at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)
- waiting to lock <0x00000000d5efe1d0> (a java.lang.Object)
- locked <0x00000000d5efe1c0> (a java.lang.Object)
at DeadLockDemo$$Lambda$1/1324119927.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
可以看到 jstack 命令已经帮我们找到发生死锁的线程的具体信息。
JDK监控可视化工具
- JConsole
- JProfile
JDK1.8特性
- lambda表达式
- 关键字default: 可以在接口中添加方法的实现,比如Iterator迭代器,里面的foreach
- 函数式接口@FunctionalInterface
- Api的添加,Stream,方便集合的操作
Servlet
Servlet简介
Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层。
Servlet生命周期
Servlet有良好的生存期的定义,包括加载和实例化、初始化、处理请求以及服务结束。这个生存期由javax.servlet.Servlet接口的init,service和destroy方法表达。 Servlet被服务器实例化后,容器运行其init方法,请求到达时运行其service方法,service方法自动派遣运行与请求对应的doXXX方法(doGet,doPost)等,当服务器决定将实例销毁的时候调用其destroy方法。
- 初始化:Web容器加载servlet,调用init()方法
- 处理请求:当请求到达时,运行其service()方法。service()自动派遣运行与请求相对应的doXXX(doGet或者doPost)方法。
- 销毁:服务结束,web容器会调用servlet的distroy()方法销毁servlet。
get提交和post提交有何区别
- get一般用于从服务器上获取数据,post一般用于向服务器传送数据
- 请求的时候参数的位置有区别,get的参数是拼接在url后面,用户在浏览器地址栏可以看到。post是放在http包的包体中。比如说用户注册,你不能把用户提交的注册信息用get的方式吧,那不是说把用户的注册信息都显示在Url上了吗,是不安全的。
- 能提交的数据有区别,get方式能提交的数据只能是文本,且大小不超过1024个字节,而post不仅可以提交文本还有二进制文件。所以说想上传文件的话,那我们就需要使用post请求方式
- servlet在处理请求的时候分别对应使用doGet和doPost方式进行处理请求
doGet与doPost方法的两个参数是什么
HttpServletRequest:封装了与请求相关的信息
HttpServletResponse:封装了与响应相关的信息
forward和redirect的区别
转发与重定向
(1)从地址栏显示来说
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是
新的URL.
(2)从数据共享来说
forward:转发页面和转发到的页面可以共享request里面的数据.
redirect:不能共享数据.
(3)从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
(4)从效率来说
forward:高.
redirect:低.
四种会话跟踪技术作用域
(1)page:一个页面
(2)request::一次请求
(3)session:一次会话
(4)application:服务器从启动到停止。
request.getAttribute()和request.getParameter
(1)有setAttribute,没有setParameter方法
(2)getParameter获取到的值只能是字符串,不可以是对象,而getAttribute获取到的值是Object类型的。
(3)通过form表单或者url来向另一个页面或者servlet传递参数的时候需要用getParameter获取值;getAttribute只能获取setAttribute的值
(4)setAttribute是应用服务器把这个对象放到该页面所对应的一块内存当中,当你的页面服务器重定向到另一个页面的时候,应用服务器
会把这块内存拷贝到另一个页面对应的内存当中。通过getAttribute可以取得你存下的值,当然这种方法可以用来传对象。
用session也是一样的道理,这是说request和session的生命周期不一样而已。
JDBC
JDBC的全称是Java DataBase Connection,也就是Java数据库连接,我们可以用它来操作关系型数据库。JDBC接口及相关类在java.sql包和javax.sql包里。我们可以用它来连接数据库,执行SQL查询,存储过程,并处理返回的结果。
JDBC接口让Java程序和JDBC驱动实现了松耦合,使得切换不同的数据库变得更加简单。
JDBC连接数据库的步骤
public static void main(String[] args) throws Exception {
//1.加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
//2. 获得数据库连接
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
//3.操作数据库,实现增删改查
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT user_name, age FROM imooc_goddess");
//如果有数据,rs.next()返回true
while(rs.next()){
System.out.println(rs.getString("user_name")+" 年龄:"+rs.getInt("age"));
}
}
- 注册驱动
- 获取连接
- 创建一个Statement语句对象
- 执行SQL语句
- 处理结果集
- 关闭资源
有哪些不同类型的JDBC驱动
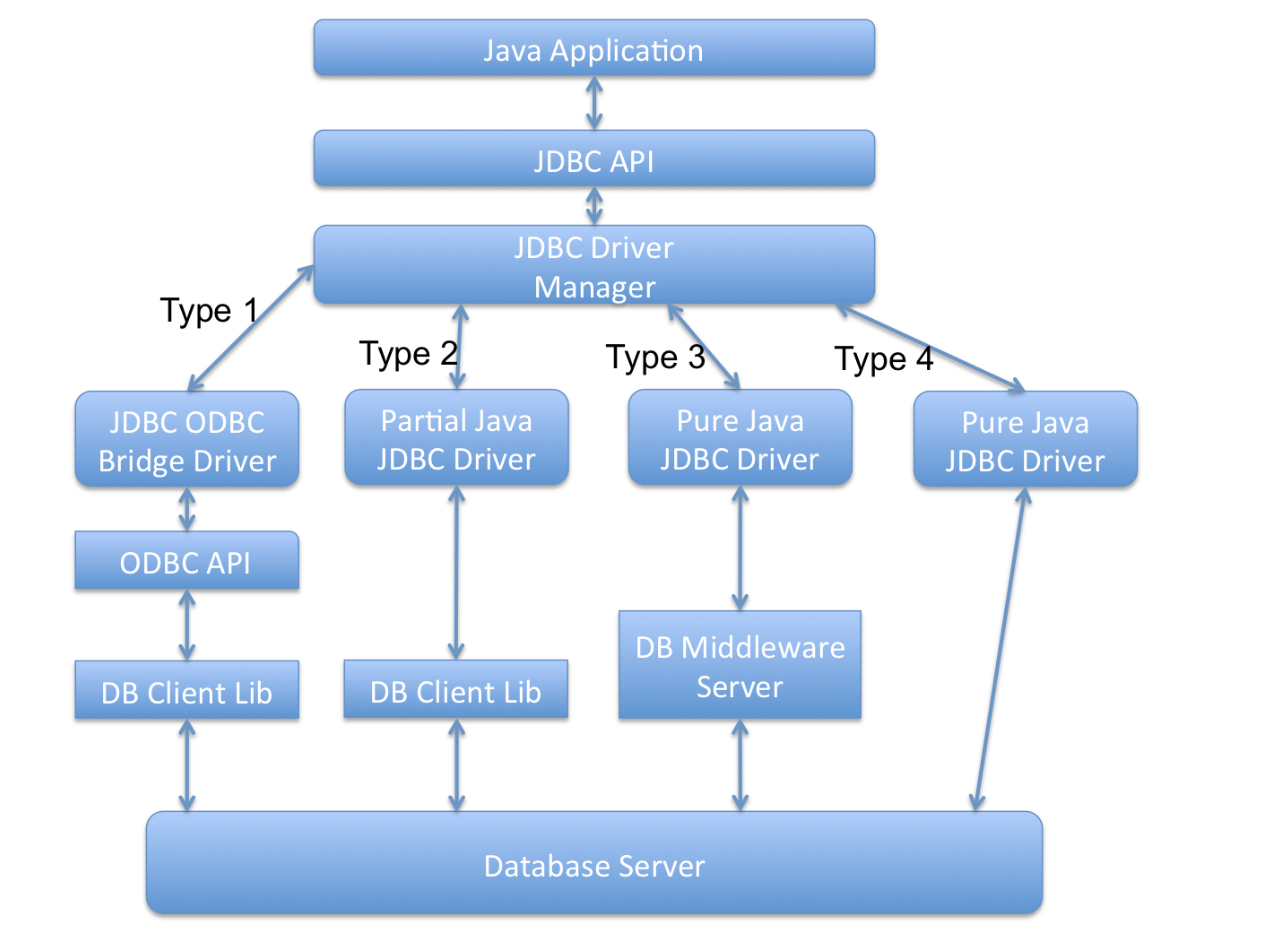
A JDBC-ODBC Bridge plus ODBC Driver(类型1):它使用ODBC驱动连接数据库。需要安装ODBC以便连接数据库,正因为这样,这种方式现在已经基本淘汰了。
B Native API partly Java technology-enabled driver(类型2):这种驱动把JDBC调用适配成数据库的本地接口的调用。
C Pure Java Driver for Database Middleware(类型3):这个驱动把JDBC调用转发给中间件服务器,由它去和不同的数据库进行连接。用这种类型的驱动需要部署中间件服务器。这种方式增加了额外的网络调用,导致性能变差,因此很少使用。
D Direct-to-Database Pure Java Driver(类型4):这个驱动把JDBC转化成数据库使用的网络协议。这种方案最简单,也适合通过网络连接数据库。不过使用这种方式的话,需要根据不同数据库选用特定的驱动程序,比如OJDBC是Oracle开发的Oracle数据库的驱动,而MySQL Connector/J是MySQL数据库的驱动。
JDBC是如何实现Java程序和JDBC驱动的松耦合的
DBC API使用Java的反射机制来实现Java程序和JDBC驱动的松耦合。随便看一个简单的JDBC示例,你会发现所有操作都是通过JDBC接口完成的,而驱动只有在通过Class.forName反射机制来加载的时候才会出现。
我觉得这是Java核心库里反射机制的最佳实践之一,它使得应用程序和驱动程序之间进行了隔离,让迁移数据库的工作变得更简单。
JDBC的DriverManager是用来做什么的
JDBC的DriverManager是一个工厂类,我们通过它来创建数据库连接。当JDBC的Driver类被加载进来时,它会自己注册到DriverManager类里面,你可以看下JDBC Driver类的源码来了解一下。
然后我们会把数据库配置信息传成DriverManager.getConnection()方法,DriverManager会使用注册到它里面的驱动来获取数据库连接,并返回给调用的程序。
JDBC的Statement是什么
Statement是JDBC中用来执行数据库SQL查询语句的接口。通过调用连接对象的getStatement()方法我们可以生成一个Statement对象。我们可以通过调用它的execute(),executeQuery(),executeUpdate()方法来执行静态SQL查询。
由于SQL语句是程序中传入的,如果没有对用户输入进行校验的话可能会引起SQL注入的问题,默认情况下,一个Statement同时只能打开一个ResultSet。如果想操作多个ResultSet对象的话,需要创建多个Statement。Statement接口的所有execute方法开始执行时都默认会关闭当前打开的ResultSet。
execute,executeQuery,executeUpdate的区别
Statement的execute(String query)方法用来执行任意的SQL查询,如果查询的结果是一个ResultSet,这个方法就返回true。如果结果不是ResultSet,比如insert或者update查询,它就会返回false。我们可以通过它的getResultSet方法来获取ResultSet,或者通过getUpdateCount()方法来获取更新的记录条数。
Statement的executeQuery(String query)接口用来执行select查询,并且返回ResultSet。即使查询不到记录返回的ResultSet也不会为null。我们通常使用executeQuery来执行查询语句,这样的话如果传进来的是insert或者update语句的话,它会抛出错误信息为 “executeQuery method can not be used for update”的java.util.SQLException。
Statement的executeUpdate(String query)方法用来执行insert或者update/delete(DML)语句,或者 什么也不返回DDL语句。返回值是int类型,如果是DML语句的话,它就是更新的条数,如果是DDL的话,就返回0。
只有当你不确定是什么语句的时候才应该使用execute()方法,否则应该使用executeQuery或者executeUpdate方法。
JDBC的ResultSet是什么
在查询数据库后会返回一个ResultSet,它就像是查询结果集的一张数据表。
ResultSet对象维护了一个游标,指向当前的数据行。开始的时候这个游标指向的是第一行。如果调用了ResultSet的next()方法游标会下移一行,如果没有更多的数据了,next()方法会返回false。可以在for循环中用它来遍历数据集。
默认的ResultSet是不能更新的,游标也只能往下移。也就是说你只能从第一行到最后一行遍历一遍。不过也可以创建可以回滚或者可更新的ResultSet,像下面这样。
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
当生成ResultSet的Statement对象要关闭或者重新执行或是获取下一个ResultSet的时候,ResultSet对象也会自动关闭。
可以通过ResultSet的getter方法,传入列名或者从1开始的序号来获取列数据。
有哪些不同的ResultSet
根据创建Statement时输入参数的不同,会对应不同类型的ResultSet。如果你看下Connection的方法,你会发现createStatement和prepareStatement方法重载了,以支持不同的ResultSet和并发类型。
一共有三种ResultSet对象。
- ResultSet.TYPE_FORWARD_ONLY:这是默认的类型,它的游标只能往下移。
- ResultSet.TYPE_SCROLL_INSENSITIVE:游标可以上下移动,一旦它创建后,数据库里的数据再发生修改,对它来说是透明的。
- ResultSet.TYPE_SCROLL_SENSITIVE:游标可以上下移动,如果生成后数据库还发生了修改操作,它是能够感知到的。
ResultSet有两种并发类型。
- ResultSet.CONCUR_READ_ONLY:ResultSet是只读的,这是默认类型。
- ResultSet.CONCUR_UPDATABLE:我们可以使用ResultSet的更新方法来更新里面的数据。
JDBC中的Statement 和PreparedStatement的区别
- PreparedStatement 继承于 Statemen
- Statement 一般用于执行固定的没有参数的SQL
- PreparedStatement 一般用于执行有?参数预编译的SQL语句。
- PreparedStatement支持?操作参数,相对于Statement更加灵活。
- PreparedStatement可以防止SQL注入,安全性高于Statement。
JDBC的事务管理是什么
JDBC接口提供了一个setAutoCommit(boolean flag)方法,我们可以用它来关闭连接自动提交的特性。我们应该在需要手动提交时才关闭这个特性,不然的话事务不会自动提交,每次都得手动提交。数据库通过表锁来管理事务,这个操作非常消耗资源。因此我们应当完成操作后尽快的提交事务。
如何回滚事务
通过Connection对象的rollback方法可以回滚事务。它会回滚这次事务中的所有修改操作,并释放当前连接所持有的数据库锁。
JDBC的保存点(Savepoint)是什么,如何使用?
有时候事务包含了一组语句,而我们希望回滚到这个事务的某个特定的点。JDBC的保存点可以用来生成事务的一个检查点,使得事务可以回滚到这个检查点。
一旦事务提交或者回滚了,它生成的任何保存点都会自动释放并失效。回滚事务到某个特定的保存点后,这个保存点后所有其它的保存点会自动释放并且失效。
Spring
什么是 Spring 框架
Spring 是一种轻量级开发框架,旨在提高开发人员的开发效率以及系统的可维护性。Spring 官网:https://spring.io/。
我们一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。这些模块是:核心容器、数据访问/集成,、Web、AOP(面向切面编程)、工具、消息和测试模块。比如:Core Container 中的 Core 组件是Spring 所有组件的核心,Beans 组件和 Context 组件是实现IOC和依赖注入的基础,AOP组件用来实现面向切面编程。
Spring 官网列出的 Spring 的 6 个特征:
- 核心技术 :依赖注入(DI),AOP,事件(events),资源,i18n,验证,数据绑定,类型转换,SpEL。
- 测试 :模拟对象,TestContext框架,Spring MVC 测试,WebTestClient。
- 数据访问 :事务,DAO支持,JDBC,ORM,编组XML。
- Web支持 : Spring MVC和Spring WebFlux Web框架。
- 集成 :远程处理,JMS,JCA,JMX,电子邮件,任务,调度,缓存。
- 语言 :Kotlin,Groovy,动态语言。
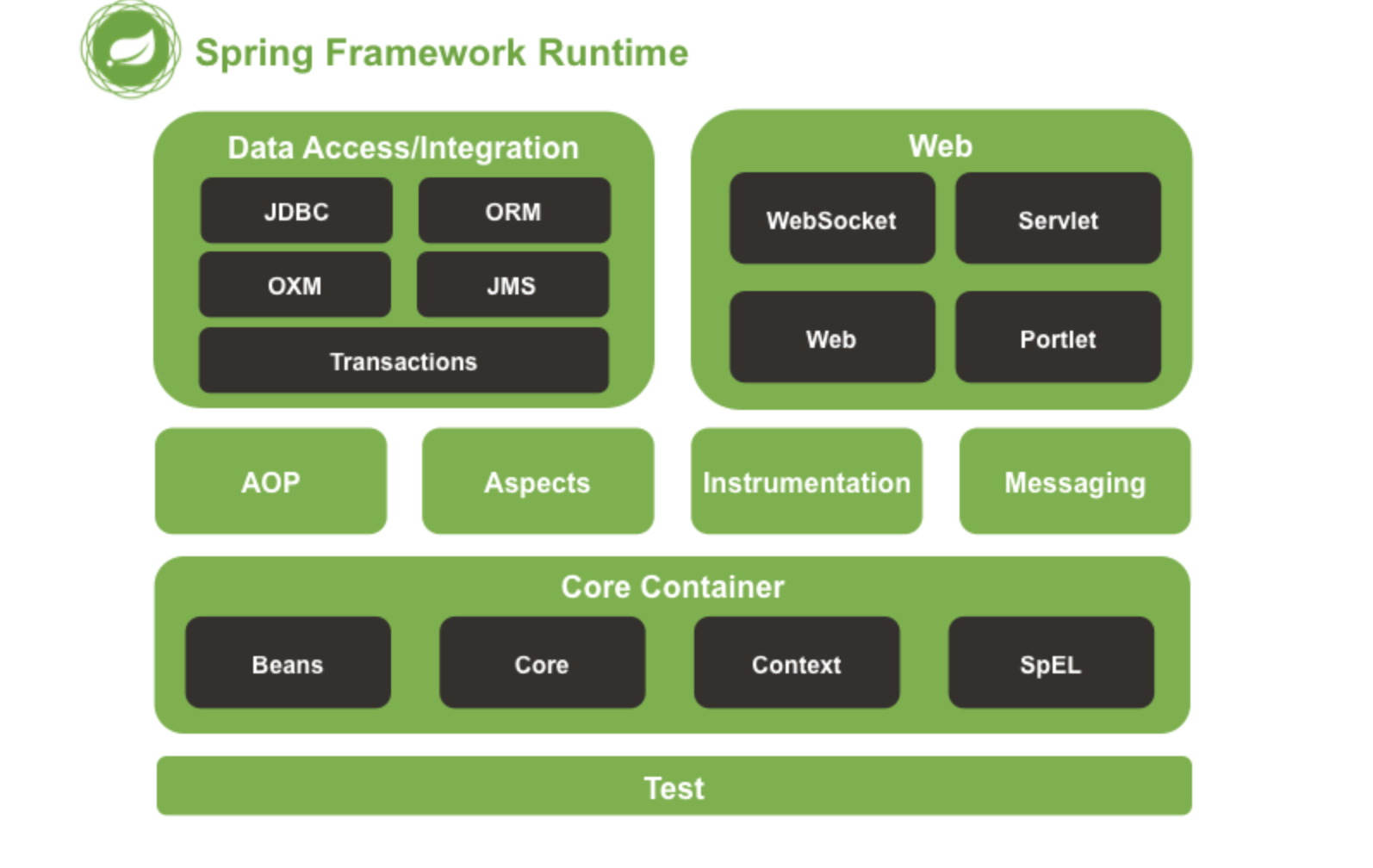
Spring模块
- Spring Core: 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IoC 依赖注入功能。
- Spring Aspects : 该模块为与AspectJ的集成提供支持。
- Spring AOP :提供了面向切面的编程实现。
- Spring JDBC : Java数据库连接。
- Spring JMS :Java消息服务。
- Spring ORM : 用于支持Hibernate等ORM工具。
- Spring Web : 为创建Web应用程序提供支持。
- Spring Test : 提供了对 JUnit 和 TestNG 测试的支持。
Spring的启动过程
- 通过SpringbootApplication注解启动
- @SpringBootConfiguration(加载所有配置,@Configuration定义配置类,@Bean注解定义的方法,加载到容器中,实例名为方法名)
- @EnableAutoConfiguration(Spring框架自动配置,自动配置包,自动配置组件)打开自动配置的功能
- @ComponentScan(组件扫描,自动装配)
Spring Boot能根据当前类路径下的类、jar包来自动配置bean,如添加一个spring-boot-starter-web启动器就能拥有web的功能,无需其他配置。
Springboot自动配置原理
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,首先它得是一个配置文件,其次根据类路径下是否有这个类去自动配置
SpringBoot 自动配置主要通过 @EnableAutoConfiguration, @Conditional, @EnableConfigurationProperties 或者 @ConfigurationProperties 等几个注解来进行自动配置完成的。
@EnableAutoConfiguration 开启自动配置,主要作用就是调用 Spring-Core 包里的 loadFactoryNames(),将 autoconfig 包里的已经写好的自动配置加载进来。
@Conditional 条件注解,通过判断类路径下有没有相应配置的 jar 包来确定是否加载和自动配置这个类。
@EnableConfigurationProperties的作用就是,给自动配置提供具体的配置参数,只需要写在application.properties 中,就可以通过映射写入配置类的 POJO 属性中。
1. new Tomcat() ,设置相关属性值 。
2. 写一个 WebApplicationInitializer 接口的实现类(Servlet规范会自动加载指定接口的所有实现类,WebApplicationInitializer就是其中一个接口)。WebApplicationInitializer可以看做是Web.xml的替代。通过实现WebApplicationInitializer,在其中可以添加servlet,listener等,在加载Web项目的时候会加载这个接口实现类,从而起到web.xml相同的作用。
3. 加载实例化 ApplicationContext , 从而创建管理Bean (Bean是Spring管理的基本单位,在基于Spring的Java EE应用中,所有的组件都被当成Bean处理)。
4. 创建初始化 DispatcherServlet 。
Spring依赖注入方式
-
构造器注入
public class UserService implements IUserService { private IUserDao userDao; public UserService(IUserDao userDao) { this.userDao = userDao; } public void loginUser() { userDao.loginUser(); } } -
Setter注入
public class UserService implements IUserService { private IUserDao userDao1; public void setUserDao(IUserDao userDao1) { this.userDao1 = userDao1; } public void loginUser() { userDao1.loginUser(); } } -
注解注入
@Autowired @Qualifier("userDaoJdbc") private IUserDao userDao;
Spring事务的传播性
| 事务传播行为类型 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
Spring中的隔离级别
① ISOLATION_DEFAULT:这是个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别。
② ISOLATION_READ_UNCOMMITTED:读未提交,允许另外一个事务可以看到这个事务未提交的数据。
③ ISOLATION_READ_COMMITTED:读已提交,保证一个事务修改的数据提交后才能被另一事务读取,而且能看到该事务对已有记录的更新。
④ ISOLATION_REPEATABLE_READ:可重复读,保证一个事务修改的数据提交后才能被另一事务读取,但是不能看到该事务对已有记录的更新。
⑤ ISOLATION_SERIALIZABLE:一个事务在执行的过程中完全看不到其他事务对数据库所做的更新。
Spring通知类型
(1)前置通知(Before advice):在某连接点(join point)之前执行的通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)。
(2)返回后通知(After returning advice):在某连接点(join point)正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回。
(3)抛出异常后通知(After throwing advice):在方法抛出异常退出时执行的通知。
(4)后通知(After (finally) advice):当某连接点退出的时候执行的通知(不论是正常返回还是异常退出)。
(5)环绕通知(Around Advice):包围一个连接点(join point)的通知,如方法调用。这是最强大的一种通知类型。 环绕通知可以在方法调用前后完成自定义的行为。它也会选择是否继续执行连接点或直接返回它们自己的返回值或抛出异常来结束执行。 环绕通知是最常用的一种通知类型。大部分基于拦截的AOP框架
SpringMVC原理
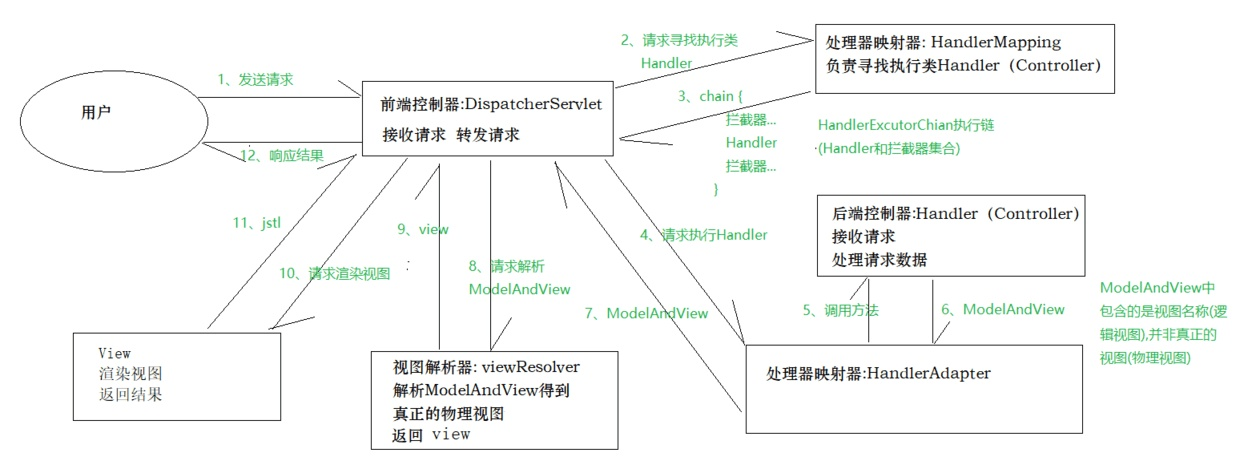
客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Moder)->将得到视图对象返回给用户
Spring AOP
AOP思想的实现一般都是基于 代理模式 ,在JAVA中一般采用JDK动态代理模式,但是我们都知道,JDK动态代理模式只能代理接口而不能代理类。因此,Spring AOP 会这样子来进行切换,因为Spring AOP 同时支持 CGLIB、ASPECTJ、JDK动态代理。
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证、日志、事务处理。
-
如果目标对象的实现类实现了接口,Spring AOP 将会采用 JDK 动态代理来生成 AOP 代理类;
- 如果目标对象的实现类没有实现接口,Spring AOP 将会采用 CGLIB 来生成 AOP 代理类——不过这个选择过程对开发者完全透明、开发者也无需关心。
应用场景
- 日志记录
- 事务管理
- 权限监控
- 方法监控
实现原理
- JDK动态代理
- Cglib动态代理
Spring IOC
IoC(Inverse of Control:控制反转)是一种设计思想,就是 将原本在程序中手动创建对象的控制权,交由Spring框架来管理。 IoC 在其他语言中也有应用,并非 Spirng 特有。 IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。 在实际项目中一个 Service 类可能有几百甚至上千个类作为它的底层,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
实现原理
1.读取bean的XML配置文件
2.使用beanId查找bean配置,并获取配置文件中class地址。
3.使用Java反射技术实例化对象
4.获取属性配置,使用反射技术进行赋值。
详细流程
1.利用传入的参数获取xml文件的流,并且利用dom4j解析成Document对象
2.对于Document对象获取根元素对象后对下面的标签进行遍历,判断是否有符合的id.
3.如果找到对应的id,相当于找到了一个Element元素,开始创建对象,先获取class属性,根据属性值利用反射建立对象.
4.遍历标签下的property标签,并对属性赋值.注意,需要单独处理int,float类型的属性.因为在xml配置中这些属性都是以字符串的形式来配置的,因此需要额外处理.
5.如果属性property标签有ref属性,说明某个属性的值是一个对象,那么根据id(ref属性的值)去获取ref对应的对象,再给属性赋值.
6.返回建立的对象,如果没有对应的id,或者下没有子标签都会返回nul
- 通过容器初始化实例和配置
- 如何设计
- 容器工厂
- 应用上下文
SpringBean作用域
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session : 每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
##SpringBean生命周期
Servlet的生命周期:实例化,初始init,接收请求service,销毁destroy;
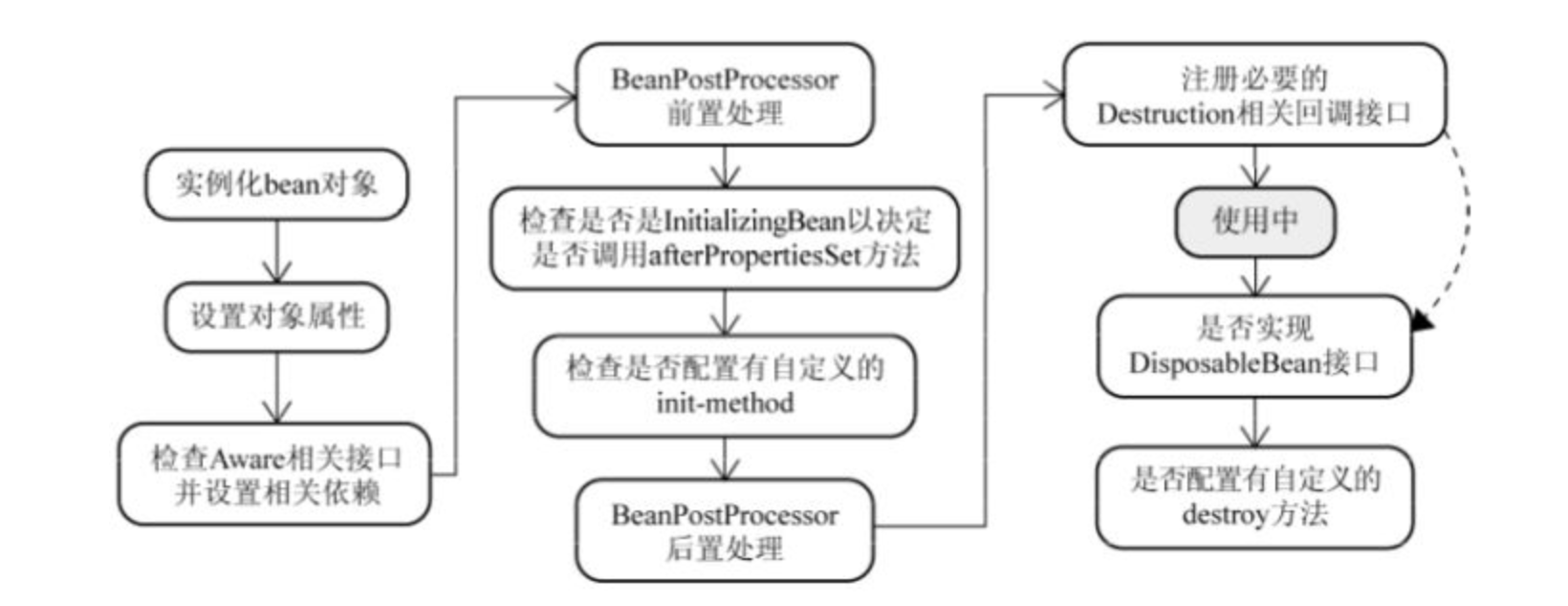
- Bean 容器找到配置文件中 Spring Bean 的定义。
- Bean 容器利用 Java Reflection API 创建一个Bean的实例。
- 如果涉及到一些属性值 利用
set()方法设置一些属性值。 - 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法。 - 如果Bean实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
- 如果有和加载这个 Bean的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法 - 当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 - 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
(1)实例化Bean:
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
(2)设置对象属性(依赖注入):
实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完成依赖注入。
(3)处理Aware接口:
接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
①如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的就是Spring配置文件中Bean的id值;
②如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor:
如果想对Bean进行一些自定义的处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。
(5)InitializingBean 与 init-method:
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(6)如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(7)DisposableBean:
当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(8)destroy-method:
最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
Spring支持Bean的作用域
Spring容器中的bean可以分为5个范围:
(1)singleton:默认,每个容器中只有一个bean的实例,单例的模式由BeanFactory自身来维护。
(2)prototype:为每一个bean请求提供一个实例。
(3)request:为每一个网络请求创建一个实例,在请求完成以后,bean会失效并被垃圾回收器回收。
(4)session:与request范围类似,确保每个session中有一个bean的实例,在session过期后,bean会随之失效。
(5)global-session:全局作用域,global-session和Portlet应用相关。当你的应用部署在Portlet容器中工作时,它包含很多portlet。如果你想要声明让所有的portlet共用全局的存储变量的话,那么这全局变量需要存储在global-session中。全局作用域与Servlet中的session作用域效果相同。
Spring框架中的单例Beans线程安全
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的Spring bean并没有可变的状态(比如Serview类和DAO类),所以在某种程度上说Spring的单例bean是线程安全的。如果你的bean有多种状态的话,就需要自行保证线程安全。最浅显的解决办法就是将多态bean的作用域由“singleton”变更为“prototype”。
Spring如何处理线程并发问题
在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空间换时间”的方式。
ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
Spring自动装配
在spring中,对象无需自己查找或创建与其关联的其他对象,由容器负责把需要相互协作的对象引用赋予各个对象,使用autowire来配置自动装载模式。
在Spring框架xml配置中共有5种自动装配:
(1)no:默认的方式是不进行自动装配的,通过手工设置ref属性来进行装配bean。
(2)byName:通过bean的名称进行自动装配,如果一个bean的 property 与另一bean 的name 相同,就进行自动装配。
(3)byType:通过参数的数据类型进行自动装配。
(4)constructor:利用构造函数进行装配,并且构造函数的参数通过byType进行装配。
(5)autodetect:自动探测,如果有构造方法,通过 construct的方式自动装配,否则使用 byType的方式自动装配。
基于注解的方式:
使用@Autowired注解来自动装配指定的bean。在使用@Autowired注解之前需要在Spring配置文件进行配置,<context:annotation-config />。在启动spring IoC时,容器自动装载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied、@Resource或@Inject时,就会在IoC容器自动查找需要的bean,并装配给该对象的属性。在使用@Autowired时,首先在容器中查询对应类型的bean:
如果查询结果刚好为一个,就将该bean装配给@Autowired指定的数据;
如果查询的结果不止一个,那么@Autowired会根据名称来查找;
如果上述查找的结果为空,那么会抛出异常。解决方法时,使用required=false。
@Autowired可用于:构造函数、成员变量、Setter方法
注:@Autowired和@Resource之间的区别
(1) @Autowired默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false)。
(2) @Resource默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
spring控制bean加载顺序
Bean上使用@Order注解,如@Order(2)。数值越小表示优先级越高。默认优先级最低。
##Spring注解@Resource和@Autowired区别
@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入
1、共同点
两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。
2、 @Autowired默认按类型装配(这个注解是属业spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
@Autowired()
@Qualifier(“baseDao”)
private BaseDao baseDao;
3、@Resource(这个注解属于J2EE的),默认安装名称进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource(name=”baseDao”)
private BaseDao baseDao;
Spring@Component和@Bean区别
- 作用对象不同:
@Component注解作用于类,而@Bean注解作用于方法。 @Component通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(我们可以使用@ComponentScan注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了Spring这是某个类的示例,当我需要用它的时候还给我。@Bean注解比Component注解的自定义性更强,而且很多地方我们只能通过@Bean注解来注册bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
@Bean注解使用示例:
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
上面的代码相当于下面的 xml 配置
<beans>
<bean id="transferService" class="com.acme.TransferServiceImpl"/>
</beans>
Spring中BeanFactory和FactoryBean区别
1、 BeanFactory
BeanFactory定义了IOC容器的最基本形式,并提供了IOC容器应遵守的的最基本的接口,也就是Spring IOC所遵守的最底层和最基本的编程规范。
它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。
在Spring代码中,BeanFactory只是个接口,并不是IOC容器的具体实现,
但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,都是附加了某种功能的实现。
2、FactoryBean
一般情况下,Spring通过反射机制利用的class属性指定实现类实例化Bean,在某些情况下,实例化Bean过程比较复杂,
如果按照传统的方式,则需要在中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。
Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。
FactoryBean接口对于Spring框架来说占用重要的地位,Spring自身就提供了70多个FactoryBean的实现。
BeanFactory和ApplicationContext有什么区别?
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
(1)BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
①继承MessageSource,因此支持国际化。
②统一的资源文件访问方式。
③提供在监听器中注册bean的事件。
④同时加载多个配置文件。
⑤载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
(2)①BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
②ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
③相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
(3)BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
(4)BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册
MySQL
什么是MySQL
MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是3306。
存储引擎
InnoDB
- InnoDB存储引擎支持事务,回滚以及系统崩溃修复能力和多版本迸发控制的事务的安全。
- InnoDB支持自增长列(auto_increment),支持外键(foreignkey)
- InnoDB支持mvcc的行级锁
- InnoDB存储引擎索引使用的是B+Tree,聚集索引
MyISAM
- MyISAM 这种存储引擎不支持事务,不支持行级锁,只支持并发插入的表锁,主要用于高负载的select。
- MyISAM 类型的表支持三种不同的存储结构:静态型(表列大小固定)、动态型(空间少,但碎片造成性能降低)、压缩型(只读表,减少占用空间)。
- MyISAM也使用B+tree索引但和Innodb的在具体实现上有些不同,是非聚集索引。
MEMORY
- 基于memory存储引擎的表实际对应一个磁盘文件,该文件只存储表的结构,而其数据文件都是存储在内存中,这样有利于对数据的快速处理,提高整个表的处理能力。
- memory存储引擎文件数据都存储在内存中,如果mysqld进程发生异常,重启或关闭机器这些数据都会消失。所以memory存储引擎中的表的生命周期很短,一般只使用一次。
- memory存储引擎默认使用哈希(HASH)索引,其速度比使用B-+Tree型要快,如果读者希望使用B树型,则在创建的时候可以引用。
Mysql事务
-
原子性
事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-
一致性
执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
-
隔离性
并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-
隔离级别
-
未提交读 read-uncommitted 存在脏读,不可重复读,幻读
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-
已提交读 read-committed 存在不可重复读
允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-
可重复读 repeatable read 存在幻读, MySQL默认级别
对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-
串行化 Serializable
最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
-
-
-
持久性
一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
可能出现问题
- 脏读:指一个线程中的事务读取到了另外一个线程中未提交的数据。
- 不可重复读(虚读):指一个线程中的事务读取到了另外一个线程中提交的update的数据。
- 幻读:指一个线程中的事务读取到了另外一个线程中提交的insert的数据。
锁机制和InnoDB锁算法
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
表级锁和行级锁对比:
- 表级锁: MySQL中锁定 粒度最大 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
- 行级锁: MySQL中锁定 粒度最小 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
InnoDB存储引擎的锁的算法有三种:
- Record lock:单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
- Next-key lock:record+gap 锁定一个范围,包含记录本身
相关知识点:
- innodb对于行的查询使用next-key lock
- Next-locking keying为了解决Phantom Problem幻读问题
- 当查询的索引含有唯一属性时,将next-key lock降级为record key
- Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
- 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
索引
MySQL索引使用的数据结构主要有BTree索引 和 哈希索引 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
-
MyISAM: B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
-
InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
索引的类型
- 普通索引(Normal)
- 唯一索引(Unique)
- 全文索引(Fulltext)
- 组合索引(Spatail)
索引方法
- Btree
- Hash
索引为什么有效
如果没有索引我们查询数据是需要遍历双向链表来定位对应的page,现在通过索引创建的“目录”就可以很快定位对应页上了!
其实底层实现的结构就是B+树,B+树作为树的一种实现能够让我们很快查找出对应内容。
B树和B+树不同点
- 所有叶子节点中包含了全部关键字的信息。
- 各叶子节点用指针进行连接。
- 非叶子节点上只存储 key 的信息,这样相对 B 树,可以增加每一页中存储 key 的数量。
- B 树是纵向扩展,最终变成一个“瘦高个”,而 B+ 树是横向扩展的,最终会变成一个“矮胖子”。在 B+ 树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上。B+ 树中的 B 不是代表二叉(binary) 而是代表(balance),B+ 树并不是一个二叉树。
B+与B树最大的区别就是:B+树它的键一定会出现在叶子节点上,同时也有可能在非叶子节点中重复出现。而 B 树中同一键值不会出现多次。
覆盖索引和联合索引
覆盖索引
select的数据列仅从索引中就能够取得并且不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
例子:如以country表a(表示城市)、b(表示省)两列做复合索引,select a from country where b=‘浙江省’
覆盖索引就是从辅助索引中就能直接得到查询结果,而不需要回表到聚簇索引中进行再次查询,所以可以减少搜索次数(不需要从辅助索引树回表到聚簇索引树),或者说减少IO操作(通过辅助索引树可以一次性从磁盘载入更多节点),从而提升性能。
联合索引
联合索引是指对表上的多个列进行索引。下面以一个例子进行说明。假设有下面这样一张表,有这样一个需求,我们需要查询某个用户的购物情况,并按照时间进行排序,取出某用户近几次的购物情况。
联合索引(a, b)是根据a, b进行排序(先根据a排序,如果a相同则根据b排序)。因此,下列语句可以直接使用联合索引得到结果(事实上,也就是用到了最左前缀原则)
最左前缀原则
对于有很多字段的一张表,查询的方式是多样的,难道要为了每一种可能的查询都定义索引吗?这样岂不是很浪费空间,毕竟建索引也是需要一些空间的。事实上,B+ 树这种索引结构,可以利用索引的“最左前缀”原则来定位记录,避免重复定义索引。
索引项是按照索引定义里面出现的字段顺序排序的
只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
Explian
explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
概要描述:
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
一、id
SELECT识别符。这是SELECT的查询序列号
我的理解是SQL执行的顺序的标识,SQL从大到小的执行
SELECT识别符。这是SELECT的查询序列号
我的理解是SQL执行的顺序的标识,SQL从大到小的执行
-
id相同时,执行顺序由上至下
-
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
-
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
二、select_type**
示查询中每个select子句的类型
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
(6) SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
三、table
显示这一步所访问数据库中表名称(显示这一行的数据是关于哪张表的),有时不是真实的表名字,可能是简称,例如上面的e,d,也可能是第几步执行的结果的简称
四、type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: **ALL、index、range、 ref、eq_ref、const、system、**NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
五、possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
六、Key
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
七、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
不损失精确性的情况下,长度越短越好
八、ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
九、rows
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
十、Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
-- 测试Extra的filesort
explain select * from emp order by name;
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
大表优化
-
查询时通过条件查询
-
读写分离
经典的数据库拆分方案,主库负责写,从库负责读;
-
垂直分区
根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。
- 垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
- 垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
-
水平分区
保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
**分库分表ID处理
- UUID:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
- 数据库自增 id : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
- 利用 redis 生成 id : 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
- Twitter的snowflake算法 :Github 地址:https://github.com/twitter-archive/snowflake。
- 美团的Leaf分布式ID生成系统 :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
SQL优化
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0 - in 和 not in 也要慎用,否则会导致全表扫描, exists 代替 in 是一个好的选择,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3 - 数据多,可以条件查询
- 不能使用select*from查询
- 尽可能使用varchar代替char,因为首先变长字段存储空间小,可以节省存储空间,且搜索效率高
- union代替or,or操作会全表扫描
- Not运算,无法使用索引
- 表连接
- 连接的表越多,性能越差
- 可能的话,将连接拆分成若干个过程逐一执行
- 优先执行可显著减少数据量的连接,既降低了复杂度,也能够容易按照预期执行
- 如果不可避免多表连接,很可能是设计缺陷
- 外链接效果差,因为必须对左右表进行表扫描
- 尽量使用inner join查询
索引失效情况
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
3.like查询以%开头
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
6.不在索引列上做任何操作(计算,函数,(自动或者手动)类型装换),会导致索引失效而导致全表扫描。
7. is null或者is not null 也会导致无法使用索引
8. 字符串不加单引号索引失效。
Redis
Redis简介
redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis作用
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
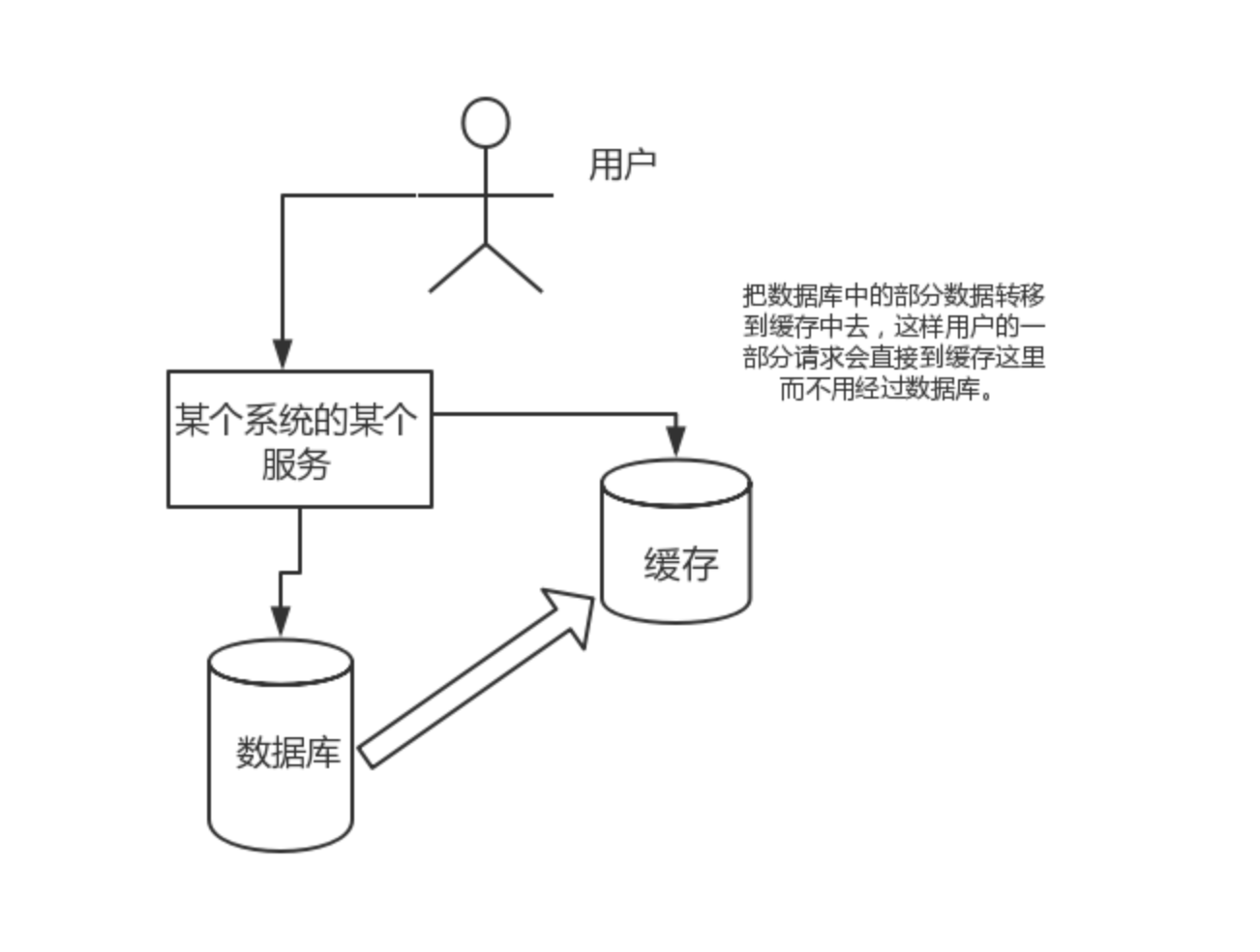
Redis线程模型
edis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
Redis常见数据结构及使用场景
1.String
常用命令: set,get,decr,incr,mget 等。
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。 常规key-value缓存应用; 常规计数:微博数,粉丝数等。
2.Hash
常用命令: hget,hset,hgetall 等。
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型存放了我本人的一些信息:
key=JavaUser293847
value={
“id”: 1,
“name”: “SnailClimb”,
“age”: 22,
“location”: “Wuhan, Hubei”
}
3.List
常用命令: lpush,rpush,lpop,rpop,lrange等
list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,这个很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
4.Set
常用命令: sadd,spop,smembers,sunion 等
set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程,具体命令如下:
sinterstore key1 key2 key3 将交集存在key1内
5.Sorted Set
常用命令: zadd,zrange,zrem,zcard等
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
举例: 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 Sorted Set 结构进行存储。
Redis设置过期时间
Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
定期删除+惰性删除。
通过名字大概就能猜出这两个删除方式的意思了。
- 定期删除:redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
- 惰性删除 :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? redis 内存淘汰机制。
Redis内存淘汰机制
redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
Redis持久化机制
Redis支持持久化,而且支持两种不同的持久化操作。Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
快照(snapshotting)持久化(RDB)
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
AOF(append-only file)持久化
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
appendonly yes
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
补充内容:AOF 重写
AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
Redis事务
Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
##Redis实现分布式锁
利用Redis的setnx命令。此命令同样是原子性操作,只有在key不存在的情况下,才能set成功。(setnx命令并不完善,后续会介绍替代方案)
1.加锁
最简单的方法是使用setnx命令。key是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给key命名为 “lock_sale_商品ID” 。而value设置成什么呢?锁的value值为一个随机生成的UUID。我们可以姑且设置成1。加锁的伪代码如下:
setnx(key,1)
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败。
2.解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行del指令,伪代码如下:
del(key)
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3.锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx的key必须设置一个超时时间,单位为second,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放,避免死锁。setnx不支持超时参数,所以需要额外的指令,伪代码如下:
expire(key, 30)
缓存雪崩和缓存穿透问题处理
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间
(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法:
大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开。
缓存雪崩
什么是缓存雪崩?
简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
有哪些解决办法?
(中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到):
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
缓存穿透
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。下面用图片展示一下(这两张图片不是我画的,为了省事直接在网上找的,这里说明一下):
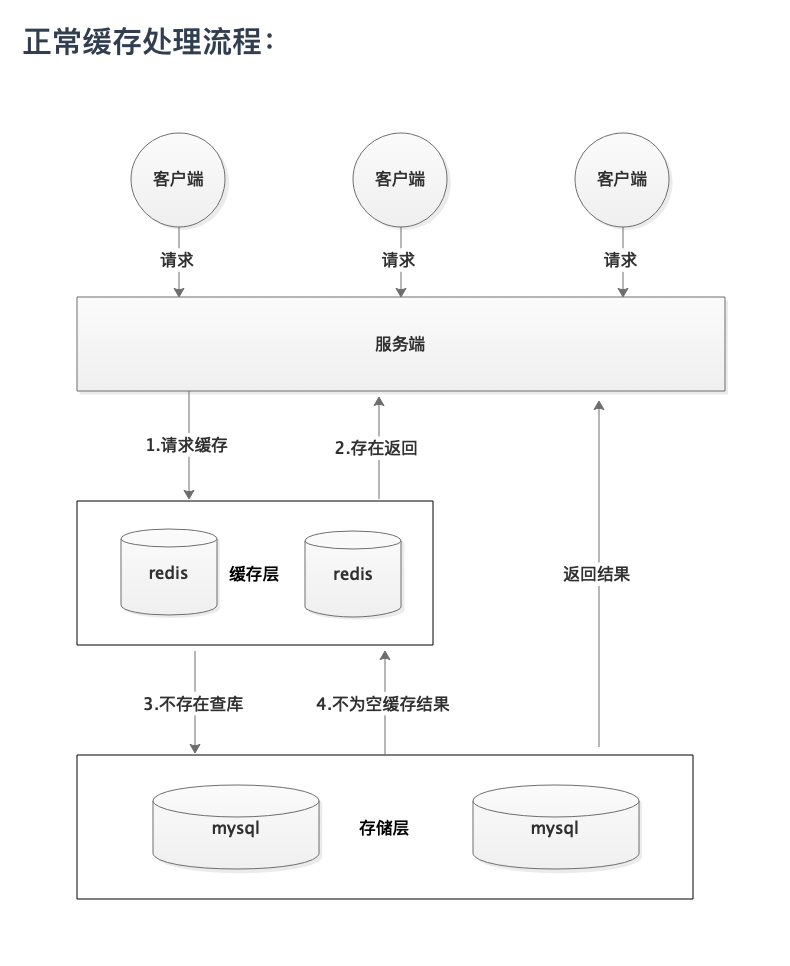
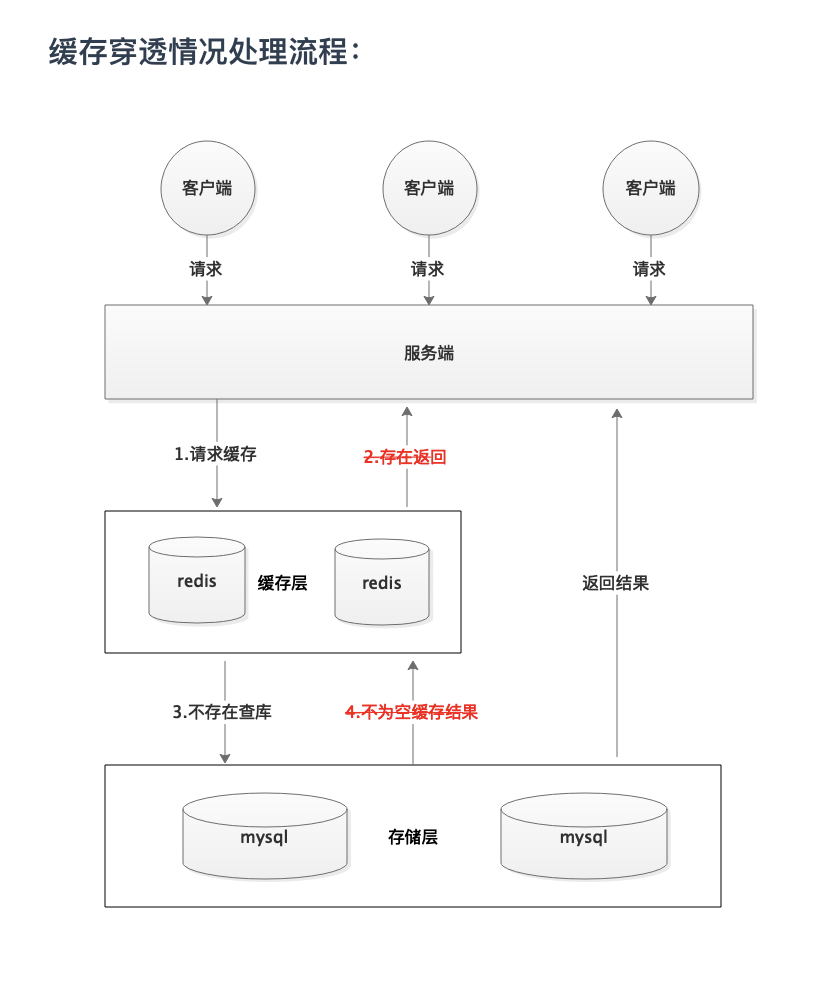
一般MySQL 默认的最大连接数在 150 左右,这个可以通过 show variables like '%max_connections%';命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
解决方法
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
缓存无效 key : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:SET key value EX 10086。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: 表名:列名:主键名:主键值。
**布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程
布隆过滤器(推荐)
就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
如何解决Redis并发竞争Key问题
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
如何保持缓存与数据库双写一致性
一般情况下我们都是这样使用缓存的:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。这种方式很明显会存在缓存和数据库的数据不一致的情况。
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
Mybatis
Mybatis简述
-
Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql执行性能,灵活度高。
-
MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
-
通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和 statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执行sql到返回result的过程)。
#{}和${}的区别是什么
${}是字符串替换,#{}是预编译处理。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
Xml和Mapper接口对应实现原理
Mapper 接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象proxy,代理对象会拦截接口方法,转而执行MapperStatement所代表的sql,然后将sql执行结果返回。
Mybatis 一二级缓存
- 一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
- 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear 掉并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新。
微服务
SpringlCloud组件及作用
-
Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
-
Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
-
Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
-
Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
-
Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
-
Sleuth和Zipkin :链式追踪排查服务
-
Oauth2 授权协议
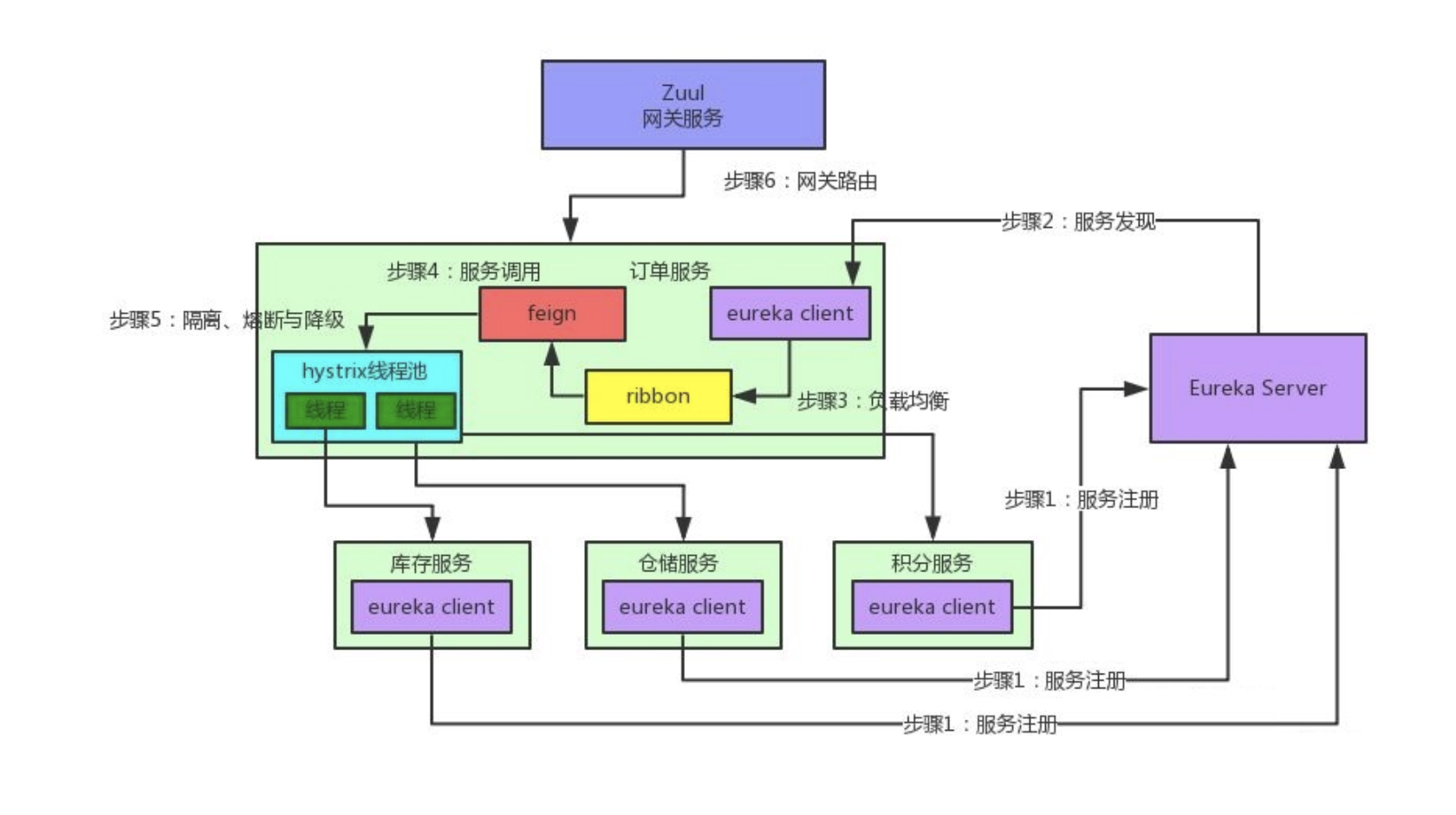
实现分布式锁的方式
- 基于DB的唯一索引。
- 基于ZK的临时有序节点。
- 基于Redis的NX、EX参数。
分布式事务解决方案
tx-lcn
LCN分布式事务框架其本身并不创建事务,而是基于对本地事务的协调从而达到事务一致性的效果
实现步骤
- 创建事务组
是指在事务发起方开始执行业务代码之前先调用TxManager创建事务组对象,然后拿到事务标示GroupId的过程。 - 添加事务组
添加事务组是指参与方在执行完业务方法以后,将该模块的事务信息添加通知给TxManager的操作。 - 关闭事务组
是指在发起方执行完业务代码以后,将发起方执行结果状态通知给TxManager的动作。当执行完关闭事务组的方法以后,TxManager将根据事务组信息来通知相应的参与模块提交或回滚事务。
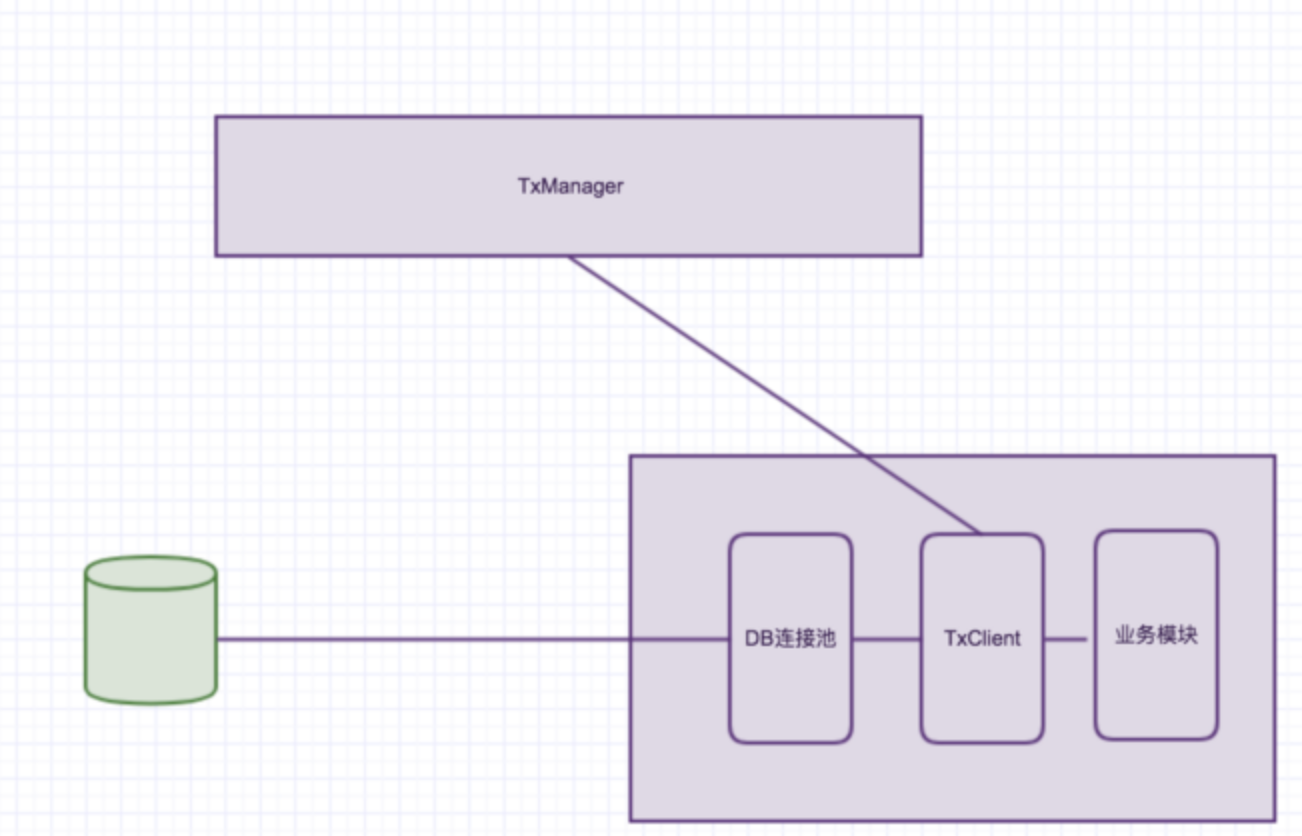
TxClient的代理连接池实现了javax.sql.DataSource接口,并重写了close方法,事务模块在提交关闭以后TxClient连接池将执行"假关闭"操作,等待TxManager协调完成事务以后在关闭连接。
事务补偿机制
为什么需要事务补偿?
事务补偿是指在执行某个业务方法时,本应该执行成功的操作却因为服务器挂机或者网络抖动等问题导致事务没有正常提交,此种场景就需要通过补偿来完成事务,从而达到事务的一致性。
补偿机制的触发条件?
当执行关闭事务组步骤时,若发起方接受到失败的状态后将会把该次事务识别为待补偿事务,然后发起方将该次事务数据异步通知给TxManager。TxManager接受到补偿事务以后先通知补偿回调地址,然后再根据是否开启自动补偿事务状态来补偿或保存该次切面事务数据。
补偿事务机制?
LCN的补偿事务原理是模拟上次失败事务的请求,然后传递给TxClient模块然后再次执行该次请求事务。
Activemq消息队列
实现原理
ActiveMQ 在 queue 中存储 Message 时,采用先进先出顺序(FIFO)存储。同一时间一个消息被分派给单个消费者,且只有当 Message 被消费并确认时,它才能从存储中删除。
对于持久化订阅者来说,每个消费者获得 Message 的副本。为了节省存储空间,Provider 仅存储消息的一个副本。持久化订阅者维护了指向下一个 Message 的指针,并将其副本分派给消费者。以这种方式实现消息存储,因为每个持久化订阅者可能以不同的速率消费 Message,或者它们可能不是全部同时运行。此外,因每个 Message 可能存在多个消费者,所以在它被成功地传递给所有持久化订阅者之前,不能从存储中删除。
DispatchPolcicy:转发策略
-
RoundRobinDispatchPolicy: “轮询”,消息将依次发送给每个“订阅者”。“订阅者”列表默认按照订阅的先后顺序排列,在转发消息时,对于匹配消息的第一个订阅者,将会被移动到“订阅者”列表的尾部,这也意味着“下一条”消息,将会较晚的转发给它。
-
StrictOrderDispatchPolicy: 严格有序,消息依次发送给每个订阅者,按照“订阅者”订阅的时间先后。它和RoundRobin最大的区别是,没有移动“订阅者”顺序的操作。
-
PriorityDispatchPolicy: 基于“property”权重对“订阅者”排序。它要求开发者首先需要对每个订阅者指定priority,默认每个consumer的权重都一样。
-
SimpleDispatchPolicy: 默认值,按照当前“订阅者”列表的顺序。其中PriorityDispatchPolicy是其子类。
SubscriptionRecoveryPolicy: 恢复策略(Topic)
在非耐久订阅者“失效”期间或一个新的Topic,broker可以保留的可追溯的消息量。前提是Topic必须是“retroactive”,我们可以在distination地址中指定此属性,例如:“order.topic?consumer.retroactive=true”。默认情况下,订阅者只能获取“订阅”开始之后的消息,如果Retroactive=true,那么订阅者就可以获取其创建之前的消息列表。此Policy就是用来控制“retroactive”的消息量。
- FixedSizedSubscriptionRecoveryPolicy: 保存一定size的消息,broker将为此Topic开辟定额的RAM用来保存最新的消息。
2) FixedCountSubscriptionRecoveryPolicy: 保存一定条数的消息。
3) LastImageSubscriptionRecoveryPolicy: 只保留最新的一条数据
4) QueryBasedSubscriptionRecoveryPolicy: 符合置顶selector的消息都将被保存,具体能够“恢复”多少消息,由底层存储机制决定;比如对于非持久化消息,只要内存中还存在,则都可以恢复。
5) TimedSubscriptionRecoveryPolicy: 保留最近一段时间的消息。
6) NoSubscriptionRecoveryPolicy: 关闭“恢复机制”。默认值。
ActiveMQ 常用的存储方式
1.KahaDB
ActiveMQ 5.3 版本起的默认存储方式。KahaDB存储是一个基于文件的快速存储消息,设计目标是易于使用且尽可能快。它使用基于文件的消息数据库意味着没有第三方数据库的先决条件。
要启用 KahaDB 存储,需要在 activemq.xml 中进行以下配置:
2.AMQ与 KahaDB 存储一样,AMQ存储使用户能够快速启动和运行,因为它不依赖于第三方数据库。AMQ 消息存储库是可靠持久性和高性能索引的事务日志组合,当消息吞吐量是应用程序的主要需求时,该存储是最佳选择。但因为它为每个索引使用两个分开的文件,并且每个 Destination 都有一个索引,所以当你打算在代理中使用数千个队列的时候,不应该使用它。
3.JDBC选择关系型数据库,通常的原因是企业已经具备了管理关系型数据的专长,但是它在性能上绝对不优于上述消息存储实现。事实是,许多企业使用关系数据库作为存储,是因为他们更愿意充分利用这些数据库资源。
4.内存存储内存消息存储器将所有持久消息保存在内存中。在仅存储有限数量 Message 的情况下,内存消息存储会很有用,因为 Message 通常会被快速消耗。在 activema.xml 中将 broker 元素上的 persistent 属性设置为 false 即可。
其他框架
mybatis
tkmapper
xxljob 任务调度
logback 日志管理
tx-lcn 事务框架
redis 缓存,分布式锁
幂等性问题
什么是幂等性
一个请求,不管重复来多少次,结果是不会改变的。就是管多少次掉用接口的,最终接口返回的结果是一致的。
解决方案
-
全局唯一ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、Redis等。如果存在则表示该方法已经执行。
使用全局唯一ID是一个通用方案,可以支持插入、更新、删除业务操作。但是这个方案看起来很美但是实现起来比较麻烦,下面的方案适用于特定的场景,但是实现起来比较简单。
-
多版本控制
这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号
微服保护机制(熔断)
熔断
当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用(hytrix自动测试请求,请求在阈值内恢复调用)。
服务降级
当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
数据结构
数据结构概述
什么是数据结构
数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成。
数据存储结构
顺序存储结构(数组)
是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。数组就是顺序存储结构的典型代表。
链式存储(链表)
是把数据元素存放在内存中的任意存储单元里,也就是可以把数据存放在内存的各个位置。这些数据在内存中的地址可以是连续的,也可以是不连续的。
数据逻辑结构
集合结构
集合结构中的数据元素同属于一个集合,他们之间是并列的关系,除此之外没有其他关系。
线性结构
线性结构中的元素存在一对一的相互关系。
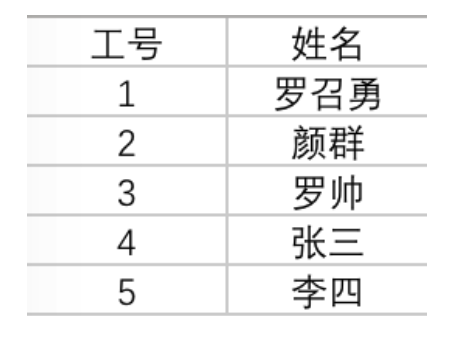
树结构
树形结构中的元素存在一对多的相互关系。
图形结构
图形结构中的元素存在多对多的相互关系。
加密
散列算法
-
MD5(Message-Digest Algorithm)
用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。将数 据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和 MD4。广泛用于加密和解密技术,常用于文件校验。校验?不管文件多大,经过MD5后都能生成唯一的MD5值。好比现在的ISO校验,都是MD5校验。怎 么用?当然是把ISO经过MD5后产生MD5的值。一般下载linux-ISO的朋友都见过下载链接旁边放着MD5的串。就是用来验证文件是否一致的。
-
SHA(Secure Hash Algorithm)
主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。该算法经过加密专家多年来的发展和改进已日益完善,并被广泛使用。该算 法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为 长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。散列函数值可以说是对明文的一种“指纹”或是“摘要”所以对散列值的数字 签名就可以视为对此明文的数字签名。
对称加密
-
DES
DES(Data Encryption Standard)是一种对称加密算法,所谓对称加密就是加密和解密都是使用同一个密钥。
DES 使用一个 56 位的密钥以及附加的 8 位奇偶校验位,产生最大 64 位的分组大小。这是一个迭代的分组密码,使用称为 Feistel 的技术,其中将加密的文本块分成两半。使用子密钥对其中一半应用循环功能,然后将输出与另一半进行"异或"运算;接着交换这两半,这一过程会继续下去,但最后一个循环不交换。DES 使用 16 个循环,使用异或,置换,代换,移位操作四种基本运算。
-
3DES
3DES是三重数据加密,且可以逆推的一种算法方案。但由于3DES的算法是公开的,所以算法本身没有密钥可言,主要依靠唯一密钥来确保数据加解密的安全,其具体实现如下:设Ek()和Dk()代表DES算法的加密和解密过程,K代表DES算法使用的密钥,M代表明文,C代表密文:
3DES加密过程为:C=Ek3(Dk2(Ek1(M)))
3DES解密过程为:M=Dk1(EK2(Dk3©))
SecretKeyFactory.getInstance(“DESede”)
DESede 相比 DES ,多出的ede,正好是encrypt - decrypt -encrypt,使用3条56位的密钥对数据进行三次加密
-
AES
AES加密属于对称加密算法,可以使用相同的密码反向解密出来。另外,AES加密属于典型的块加密算法,其中常用的块加密的工作模式包含:
ECB模式:又称电码本(ECB,Electronic Codebook Book)模式。这是最简单的块密码加密模式,加密前根据加密块大小(如AES为128位)分成若干块,之后将每块使用相同的密钥单独加密,解密同理。
CBC模式:又称密码分组链接(CBC,Cipher-block chaining)模式。在这种加密模式中,每个密文块都依赖于它前面的所有明文块。同时,为了保证每条消息的唯一性,在第一个块中需要使用初始化向量IV。
非对称加密
-
RSA
1.RSA是基于大数因子分解难题。目前各种主流计算机语言都支持RSA算法的实现
2.java6支持RSA算法
3.RSA算法可以用于数据加密和数字签名
4.RSA算法相对于DES/AES等对称加密算法,他的速度要慢的多
5.总原则:公钥加密,私钥解密 / 私钥加密,公钥解密RSA算法构建密钥对简单的很,这里我们还是以甲乙双方发送数据为模型
1.甲方在本地构建密钥对(公钥+私钥),并将公钥公布给乙方
2.甲方将数据用私钥进行加密,发送给乙方 -
ECC
Base64
Base64是一种能将任意Binary资料用64种字元组合成字串的方法,而这个Binary资料和字串资料彼此之间是可以互相转换的,十分方便。在实际应用上,Base64除了能将Binary资料可视化之外,也常用来表示字串加密过后的内容。如果要使用Java 程式语言来实作Base64的编码与解码功能
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来标识二进制数据的方法。
Base64是一种可逆的编码方式,是一种用64个Ascii字符来表示任意二进制数据的方法。
主要用于将不可打印字符转换为可打印字符,或者简单的说将二进制数据编码为Ascii字符
- **基本:**输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/。
- **URL:**输出映射到一组字符A-Za-z0-9+_,输出是URL和文件。
- **MIME:**输出隐射到MIME友好格式。输出每行不超过76字符,并且使用’\r’并跟随’\n’作为分割。编码输出最后没有行分割。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











