






论文介绍
2018年CVPR vos论文
论文地址
目的是针对现有vos方法的问题做出改进:现有性能最好的vos方法使用CNN进行fine-tune,这种方法除了昂贵之外,不能将online fine-tune整合到offline中,从而不能实现真正意义上的end-to-end训练。
作者为了解决这个问题,提出的模型可以在一次forward pass中学习target和background。给定一个新图像,模型可以得到类别的后验概率,从而给前/背景提供提示。实现真正意义上的end-to-end.
大致流程
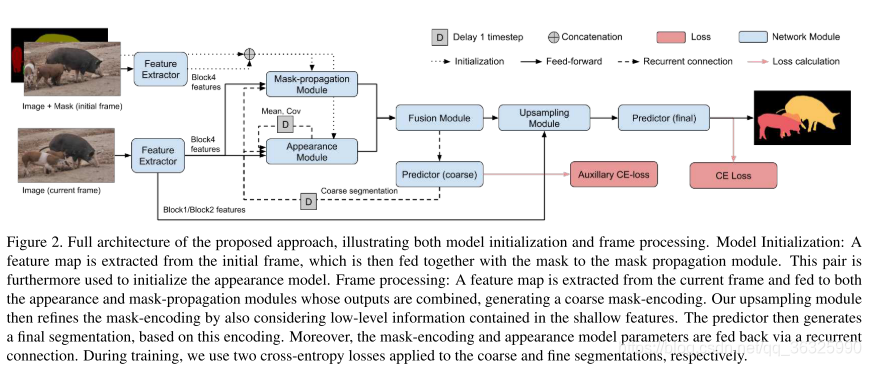
第一帧精确标记的mask和feature map对Mask-propagation Module和Appearance Module初始化。
图像经过backbone生成的feature map交由Mask-propagation Module和Appearance Module进行处理,随后进行融合,在Fusion layer生成粗粒度预测(同时fusion module的结果反馈给mask-propagation module和appearance module在下一阶段使用),Fusion Module的输出结果结合初级特征在Upsampling Module进行优化,最后再通过predictor module进行精准分割。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









