









 本文提出一种保护语言模型API的无盒水印方法,能在保证水印添加前后词汇分布接近的同时,有效验证水印存在,还可抵抗模型窃取攻击。该方法通过设置临近词词性和前序依存关系等条件约束嵌入水印,实验证明其有效性、保真度和安全性良好。
本文提出一种保护语言模型API的无盒水印方法,能在保证水印添加前后词汇分布接近的同时,有效验证水印存在,还可抵抗模型窃取攻击。该方法通过设置临近词词性和前序依存关系等条件约束嵌入水印,实验证明其有效性、保真度和安全性良好。

目录
论文信息
论文名称:CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks
作者:Xuanli He, et al. University of College London
发表年份:2022
发表会议:NeurIPS
开源代码:https://github.com/xlhex/cater_neurips
文章简介
本文提出一种保护语言模型API的无盒水印方法,能够在保证水印添加前后词汇分布接近的同时,有效验证水印的存在,且本文提出方法能有效抵抗模型窃取攻击。
研究动机
现有的语言模型水印方法或是无法抵抗模型窃取攻击[47],或是因隐蔽性较低容易被攻击者移除[13],本文提出一种隐蔽的无盒水印嵌入方法,同时满足有效性与隐蔽性。
研究方法
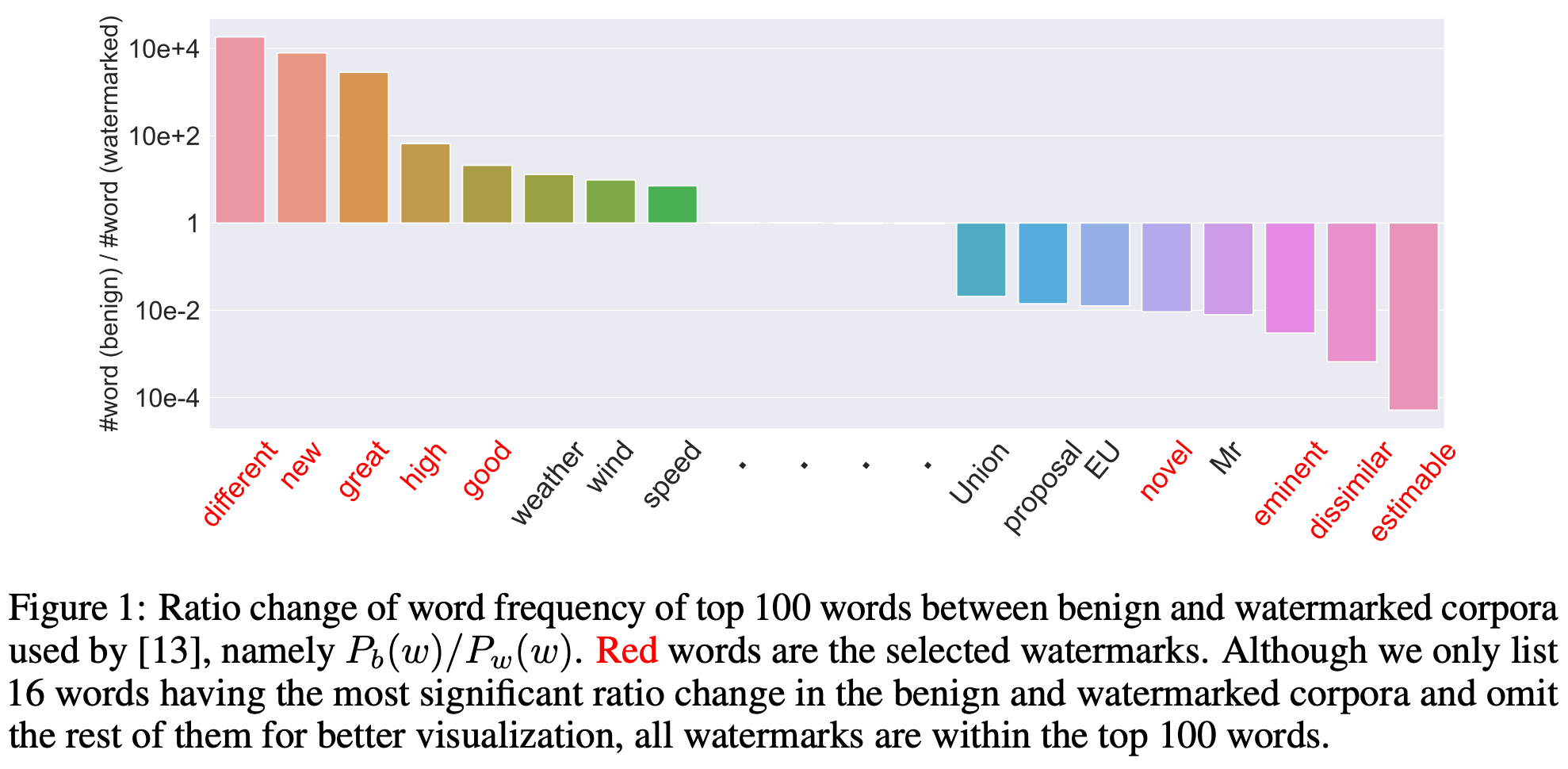
Figure 1 展示了使用[13]方法嵌入水印前后词表中词汇的频率变化,可以看到,使用这种单词替代的方法嵌入水印,会有很大风险被攻击者发现,从而通过逃逸攻击躲避水印的验证,基于这一现象,本文提出一种隐蔽的水印嵌入方法,下面对该方法进行说明。
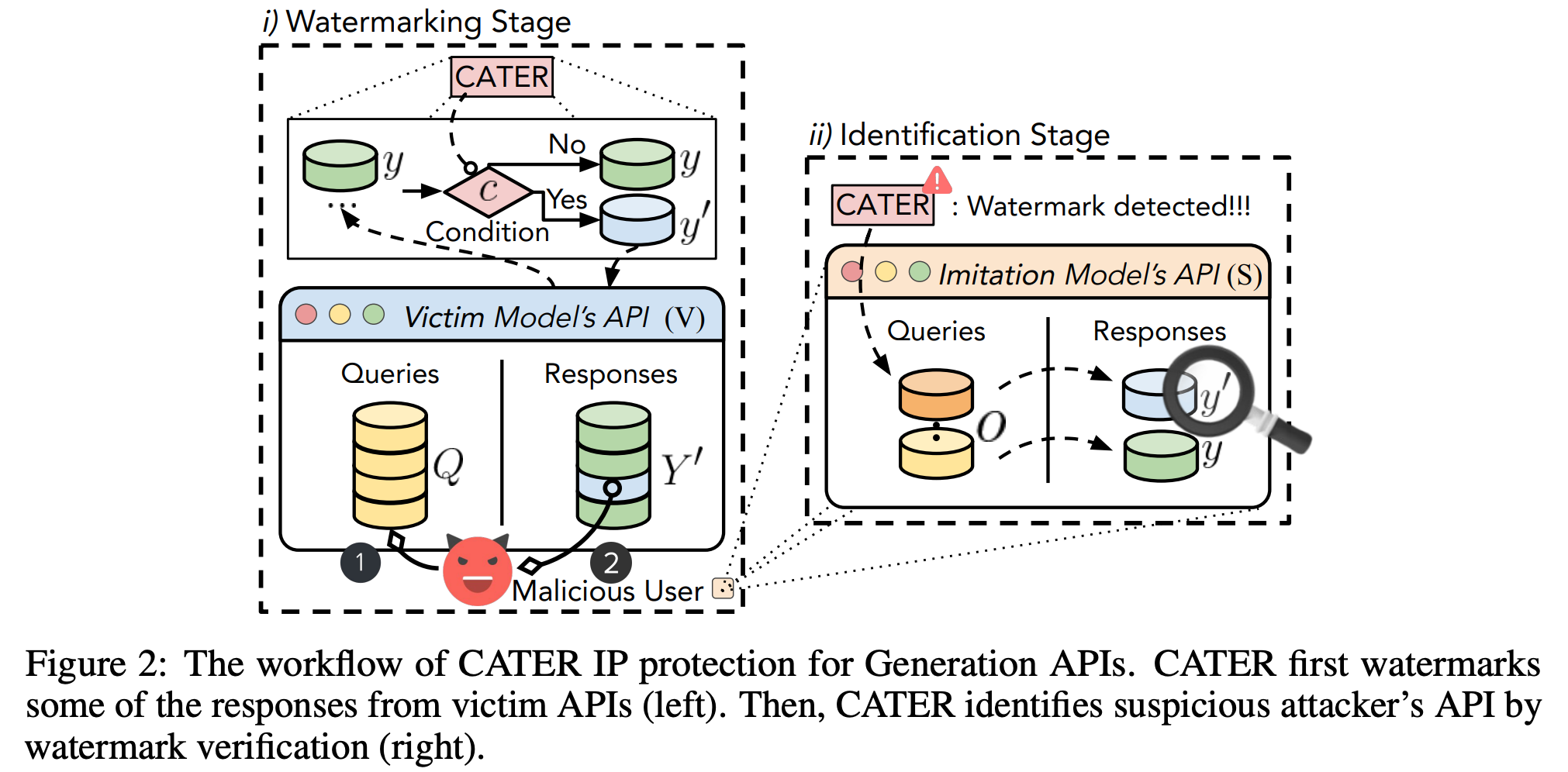
本文提出的水印嵌入和提取流程如 Figure 2 所示。水印嵌入阶段,在条件约束下对模型API的输出结果
y
y
y进行二次处理得到
y
′
y'
y′进行输出,这使得攻击者只能得到二次处理之后的输出结果;水印验证阶段,通过检测可疑模型的输出在多大程度上是二次处理之后的输出,验证可疑模型的版权。
水印嵌入
与[13]中的做法类似,本文还是通过对模型API的原始输出中的某些单词进行替换来嵌入水印;与[13]不同的是,本文不再使用高频形容词作为触发词,而是首先选择一组同义词集
G
=
{
W
i
}
i
=
1
∣
G
∣
\mathcal G=\{\mathcal W^{i}\}_{i=1}^{|\mathcal G|}
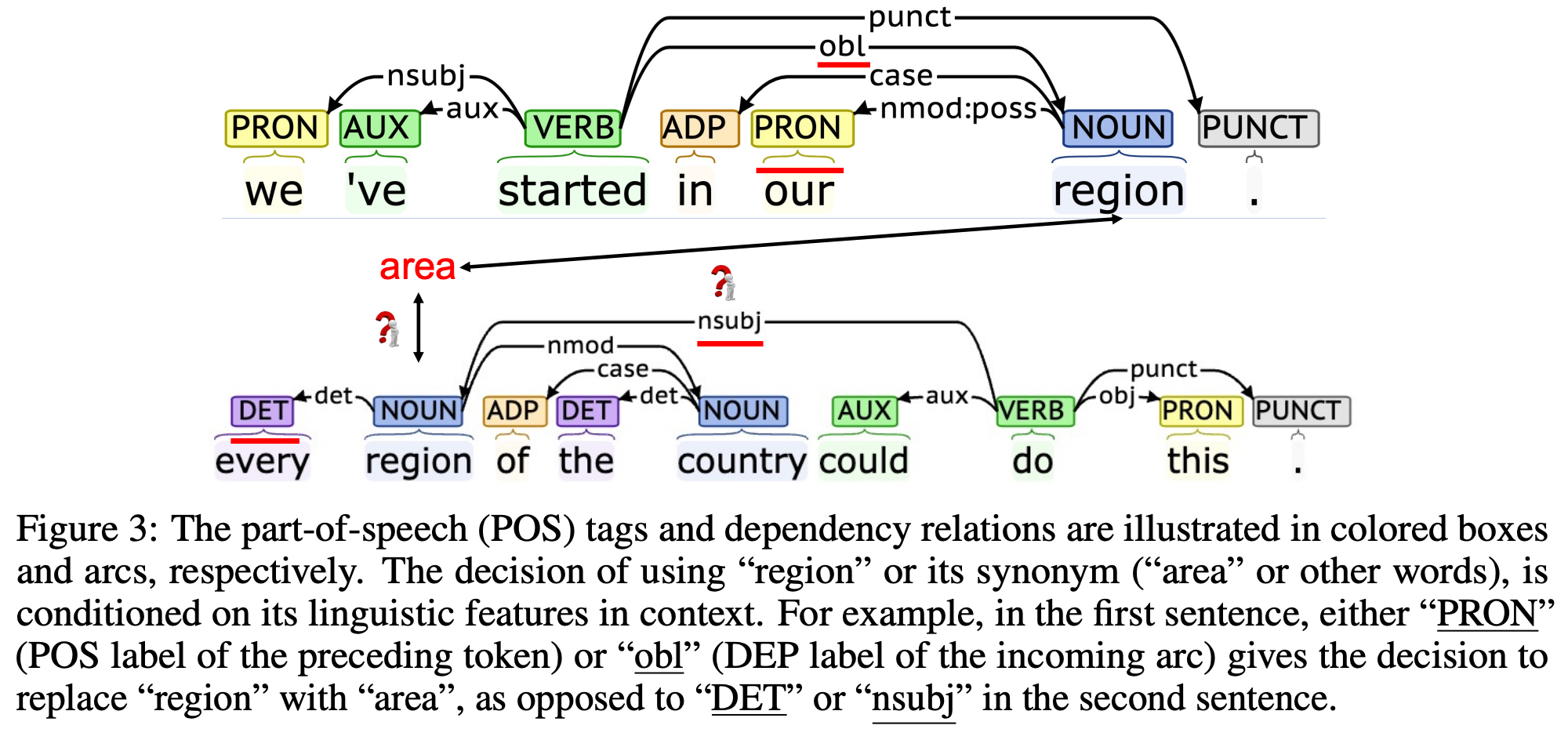
G={Wi}i=1∣G∣,然后根据当前输出文本的语言特性,寻找满足高阶条件约束的候选词汇进行替换。本文设置了两种形式的条件约束:临近词词性和前序依存关系,如 Figure 3 所示。
Part of Speech (POS)
给定句子中一个单词 w w w,假设它在句子中的词性为 l 0 l_{0} l0,则将 l − 1 l_{-1} l−1,即 w w w前面的第一个词的词性作为一阶条件,将 ( l − 1 , l + 1 ) (l_{-1}, l_{+1}) (l−1,l+1),即 w w w前后的各一个词的词性作为二阶条件,将 ( l − 2 , l − 1 , l + 1 ) (l_{-2},l_{-1}, l_{+1}) (l−2,l−1,l+1),即 w w w前面2个词以及后面一个词的词性作为三阶条件,以此类推。
Dependency Tree (DEP)
Figure 3 中第一句的 we 与 started 为名词主语的关系,即 nsubj,更多依存关系信息可参考依存关系分析。根据依存关系,可以为当前文本构建一颗依赖树,依赖树能够模拟词汇间的二元语法关系,一个依赖树可以表示为一个有向无环图。根据这个有向无环图,可以定义高阶条件约束。例如,给定一个单词
w
w
w以及抵达该单词的弧
a
r
c
arc
arc,使用该弧的DEP标签作为一阶条件约束
d
1
d_{1}
d1,通过递归的方式可以建立二阶条件约束
(
d
1
,
d
2
)
(d_{1},d_{2})
(d1,d2)……
版权验证
对于可疑模型 S \mathcal S S,模型所有者可以通过向 S \mathcal S S喂入一些验证查询 O = { o i } i = 1 ∣ O ∣ O=\{o_{i}\}_{i=1}^{|O|} O={oi}i=1∣O∣,得到输出文本 Y = { y i } i = 1 ∣ O ∣ Y=\{y_{i}\}_{i=1}^{|O|} Y={yi}i=1∣O∣,通过比对受害模型API V \mathcal V V 的输出结果,验证可疑模型 S \mathcal S S的版权。
实验结果
数据集:
任务选取:机器翻译(WMT14)、文档摘要(CNN/DM)、文本精简以及释义生成。
Baselines:[13], [47]
有效性&保真度&虚警率
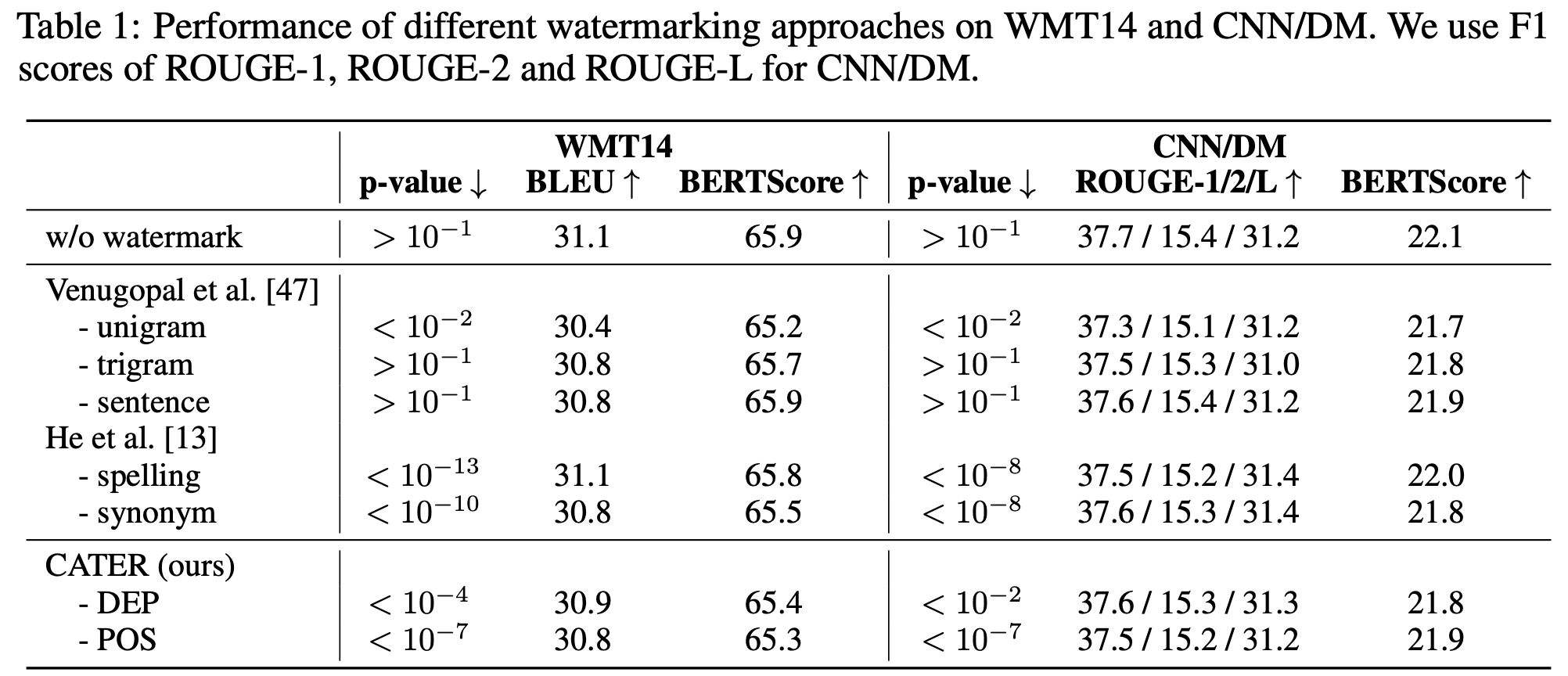
Table 1 表明,本文提出的方法能够有效嵌入水印,且保证虚警率在较低水平,同时,模型在原始任务上的性能下降范围在可接受范围内。
Mixture of human- and machine-labeled data
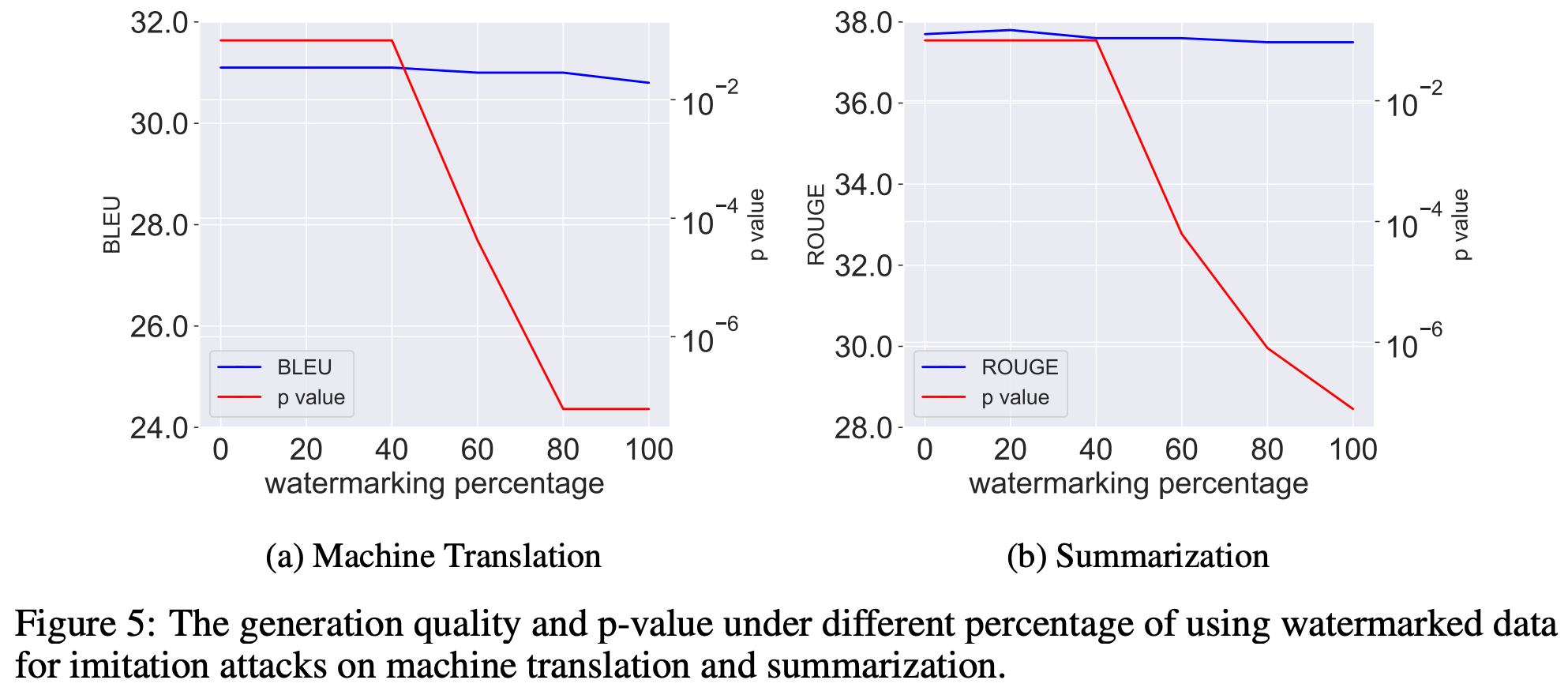
安全性
抗模型提取攻击(Imitation Attack / Model Extraction)
Table 2 展示了该水印方法抵抗模型提取攻击的能力。可以看出,在原始模型的输出文本嵌入水印之后,使用含水印输出文本训练后的模型同样能够检测到水印的存在,说明该水印方法对于模型窃取攻击具有一定的鲁棒性。
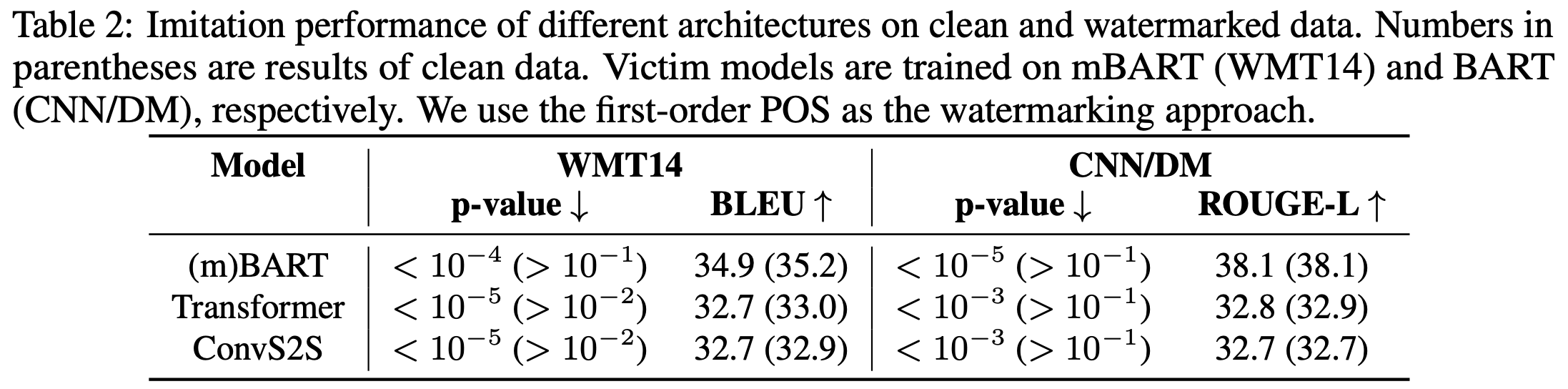
Cross-Domain Imitation
实际场景中,攻击者查询的文本可能不是来自训练数据,因此,该实验想要验证:对于在某一训练数据上得到的含水印的模型,若攻击者使用来自训练数据分布之外的查询以及得到的输出进行模型窃取,攻击是否能够成功。Table 3 证明,即使攻击者使用的查询数据不是来自原始模型的训练数据,模型API返回的结果一样含有水印信号,证实了水印的鲁棒性。

抗移除攻击(Removal Attack)
攻击者可能使用 ONION 检测异常词来移除水印,但 Table 4 表明,这种攻击对于本文提出的水印方法无效。

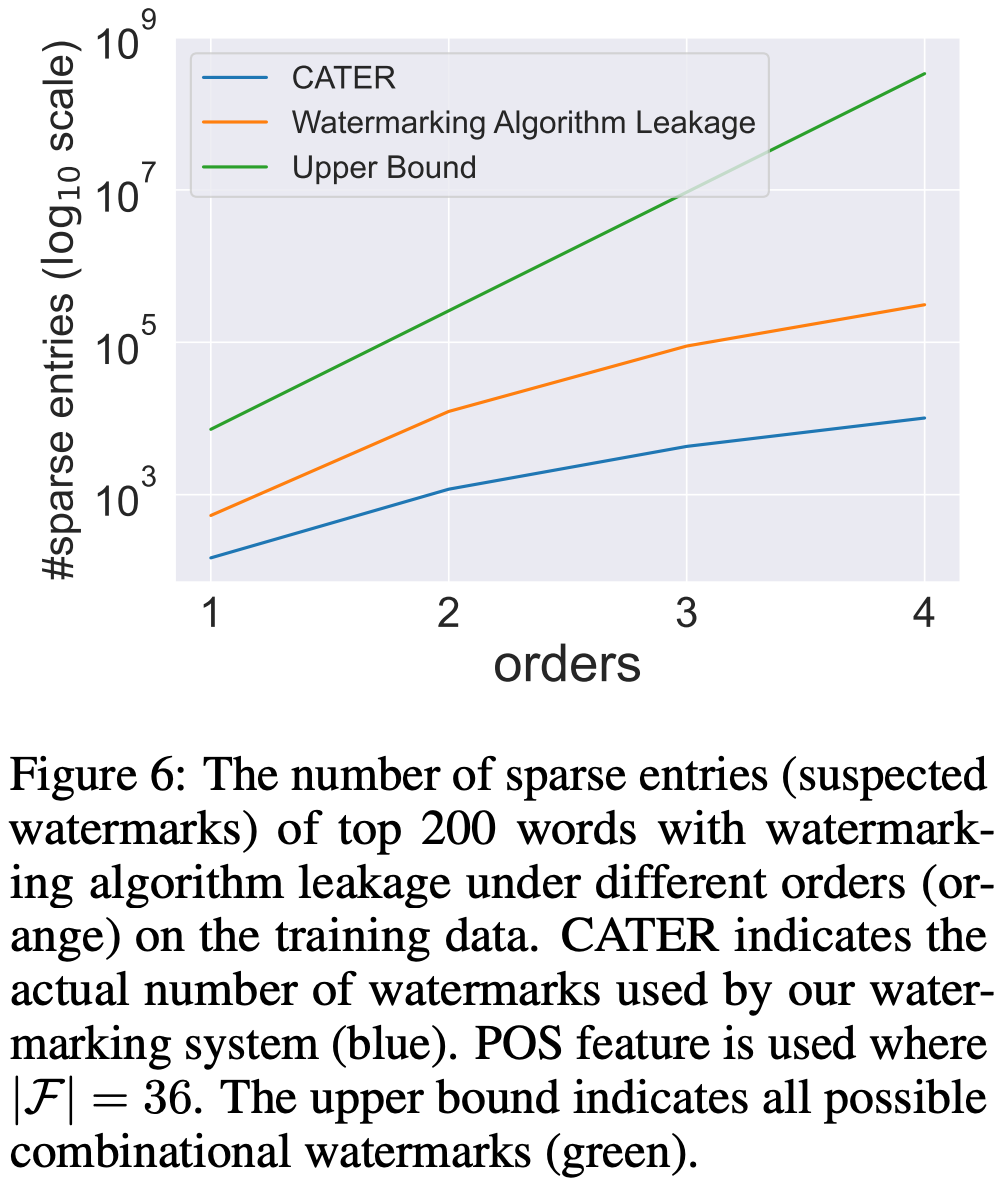
水印算法泄漏(Watermark Algorithm Leakage)
假设攻击者已知候选词集和水印嵌入使用的POS和DEP特征,但不清楚具体的水印嵌入规则,这时,攻击者准确猜到触发词的难度随着条件约束阶数的增加不断加大,如 Figure 6 所示。具体证明可参考文章 Section 3.3.(本人没怎么看懂😭)
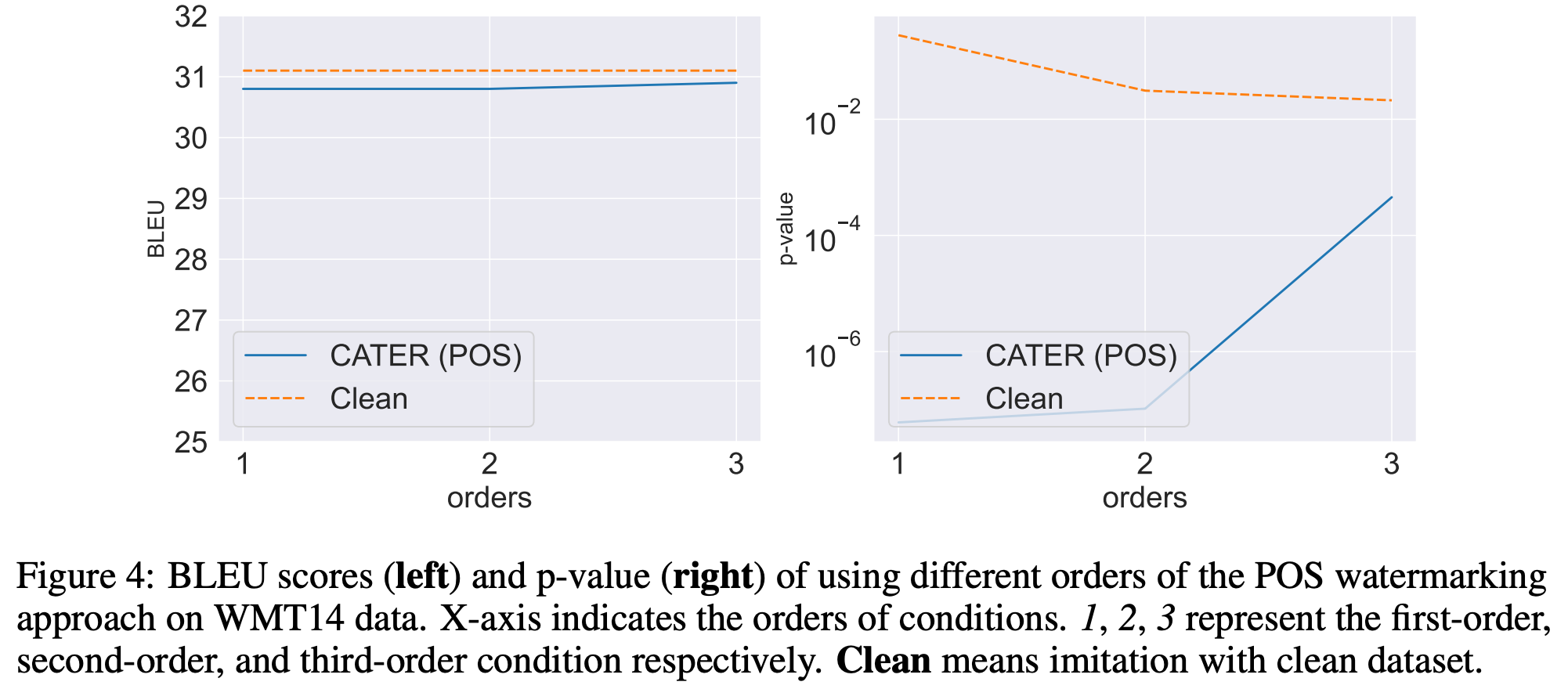
消融实验
Figure 4 展示了使用不同等级条件约束对保真度和有效性的影响,可以发现一阶条件约束能够使水印的有效性达到最高。
方法评估
这项工作是作者对这篇文章的升级版,同样是无盒水印方法,只不过在选择候选词集时添加了特定条件的加持,以保证嵌入水印的隐蔽性。
这篇文章的理论证明非常充实,咱就是说符合NeurIPS接受稿件的风格~
相关文献
[13] Xuanli He, Qiongkai Xu, Lingjuan Lyu, Fangzhao Wu, and Chenguang Wang. Protecting intellectual property of language generation apis with lexical watermark. AAAI, 2022.
[47] Ashish Venugopal, Jakob Uszkoreit, David Talbot, Franz Och, and Juri Ganitkevitch. Watermarking the outputs of structured prediction with an application in statistical machine translation. EMNLP, 2011.
[33] Fanchao Qi, Yangyi Chen, Mukai Li, Yuan Yao, Zhiyuan Liu, and Maosong Sun. Onion: A simple and effective defense against textual backdoor attacks. EMNLP, 2021.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











