







java中的io编程主要分为三大部分。
File,字节流,字符流
java IO 概述
常用概念
* IO流用来处理设备之间的数据传输
* Java对数据的操作是通过流的方式
* Java用于操作流的类都在IO包中
* 流按流向分为两种:输入流,输出流。
* 流按操作类型分为两种:
* 字节流 : 字节流可以操作任何数据,因为在计算机中任何数据都是以字节的形式存储的
* 字符流 : 字符流只能操作纯字符数据,比较方便。
IO流常用父类
字节流的抽象父类:
* InputStream
* OutputStream
字符流的抽象父类:
* Reader
* Writer
字节流入门
在IO字节流中,又分为InputStream(输入流)、OutputStream(输出流)。
输入流:我们从流的角度来想,输入流就是将文件中的内容输入到流中,及读(read)文件。
输出流:还是从流的角度来看,输出流就是将文件从流中输出到文件中,及写(write)文件。
FileInputStream:实现了InputStream接口,主要通过read()方法来读文件,read很多重载方法可以实现一次读取多个或特定位数的方法。
read()一次读取一个字节返回int 返回的范围是从0~255的范围。
FileInputStream fis = new FileInputStream("aaa.txt"); //创建一个文件输入流对象,并关联aaa.txt
int b; //定义变量,记录每次读到的字节
while((b = fis.read()) != -1) { //将每次读到的字节赋值给b并判断是否是-1
System.out.println(b); //打印每一个字节
}
fis.close();
FileOutputStream:实现了OutputStream接口,主要通过write()方法写文件,write很多重载方法可以实现一次读取多个或特定位数的方法。
write()一次写出一个字节
FileOutputStream fos = new FileOutputStream("bbb.txt"); //如果没有bbb.txt,会创建出一个
//fos.write(97); //虽然写出的是一个int数,但是在写出的时候会将前面的24个0去掉,所以写出的是一个byte
fos.write(98);
fos.write(99);
fos.close();
read()方法读取的是一个字节,为什么返回是int,而不是byte?
因为字节输入流可以操作任意类型的文件,比如图片音频等,这些文件底层都是以二进制形式的存储的,如果每次读取都返回byte,有可能在读到中间的时候遇到111111111那么这11111111是byte类型的-1,我们的程序是遇到-1就会停止不读了,后面的数据就读不到了,所以在读取的时候用int类型接收,如果11111111会在其前面补上24个0凑足4个字节,那么byte类型的-1就变成int类型的255了这样可以保证整个数据读完,而结束标记的-1就是int类型。
字节流拷贝文件的四种方式
方式一:单字节拷贝,如下图一,缺点:效率低。

方式二:一次性整体拷贝,如下图二,缺点:当拷贝文件过大时,容易造成内存溢出。
* int read(byte[] b):一次读取一个字节数组
* write(byte[] b):一次写出一个字节数组
* available()获取读的文件所有的字节个数

方式三:小数组分批拷贝,如下图三。(推荐)

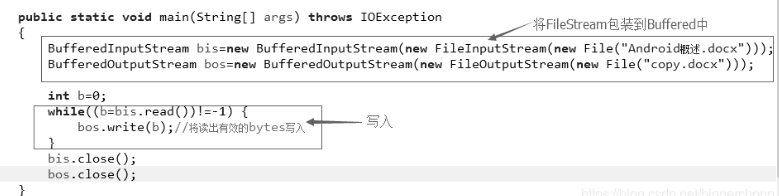
方式四:BufferedInputStream&BufferedOutputStream包装拷贝,如下图四。(推荐)
缓冲思想
* 字节流一次读写一个数组的速度明显比一次读写一个字节的速度快很多,
* 这是加入了数组这样的缓冲区效果,java本身在设计的时候,
* 也考虑到了这样的设计思想(装饰设计模式后面讲解),所以提供了字节缓冲区流
BufferedInputStream
* BufferedInputStream内置了一个缓冲区(数组)
* 从BufferedInputStream中读取一个字节时
*** BufferedInputStream会一次性从文件中读取8192个, 存在缓冲区中, 返回给程序一个**
* 程序再次读取时, 就不用找文件了, 直接从缓冲区中获取
* 直到缓冲区中所有的都被使用过, 才重新从文件中读取8192个
BufferedOutputStream
* BufferedOutputStream也内置了一个缓冲区(数组)
* 程序向流中写出字节时, 不会直接写到文件, 先写到缓冲区中
* 直到缓冲区写满, BufferedOutputStream才会把缓冲区中的数据一次性写到文件里















 8207
8207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









