







JAVA学习笔记
软件工程
软件生命周期
1.问题定义
2.可行性研究
3.需求分析
4.总体设计
5.详细设计
6.编码测试
7.验收
8.运维
Java基础
java三大特性
封装:
将类的某些信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问,常见的实现方式就是:getter、setter。
封装遵循了“开闭原则”,禁止外部直接访问和修改类的信息。
继承:
继承是类与类的一种关系,子类拥有父类的所有属性和方法(除了private修饰的属性不能拥有)从而实现了实现代码的复用。
多态:
多态主要指引用多态和方法多态
引用多态:父类引用指向子类对象
方法多态:方法重写、重载
对象的概念
万物皆可为对象,对象是类的实例,什么是类呢,类就是拥有相等功能和相同的属性的对象的集合是一个抽象的概念,假如说人是一个类,那你我就是一个对象他具体到了真实世界存在的一个实体。
创建对象
1.使用new关键字创建对象
Student s = new Student();
2.使用Class类的newInstance方法(反射)
Student s = (Student)Class.forName("Student包名.类名").newInstance();
或者
Student s = Student.class.newInstance();
3.使用Constructor类的newInstance方法(反射)
Constructor<Stundent> constructor = Stundent.class.getConstructor.newInstance("构造方法的参数");
Student s = constructor.newInstance();
4.使用ClassLoader类的loadClass转class的newInstance方法(反射)
ClassLoader cl = this.getClass().getClassLoader();
Class c = cl.loadClass("com.smartyouth.controller.Person");
Person p = (Person)c.newInstance();
5.使用Clone方法创建对象(要实现Cloneable接口重写clone方法)
public class Student implements Cloneable{
private int id;
public Student(Integer id) {
this.id = id;
}
@Override
protected Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
return super.clone();
}
public static void main(String[] args) throws Exception {
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class);
Student stu3 = constructor.newInstance(123);
Student stu4 = (Student) stu3.clone();
}
}
6.使用(反)序列化机制创建对象(必须实现Serializable接口)
当 Java 对象需要在网络上传输 或者 持久化存储到文件中时,就需要对 Java 对象进行序列化处理
public class Student implements Serializable {
private int id;
public Student(Integer id) {
this.id = id;
}
@Override
public String toString() {
return "Student [id=" + id + "]";
}
public static void main(String[] args) throws Exception {
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class);
Student stu3 = constructor.newInstance(123);
// 写对象
ObjectOutputStream output = new ObjectOutputStream(
new FileOutputStream("student.bin"));
output.writeObject(stu3);
output.close();
// 读对象
ObjectInputStream input = new ObjectInputStream(new FileInputStream(
"student.bin"));
Student stu5 = (Student) input.readObject();
System.out.println(stu5);
}
}
深克隆和浅克隆
1.浅克隆:只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用。
2.深克隆:是在引用类型的类中也实现了clone,是clone的嵌套,复制后的对象与原对象之间完全不会影响。
3.使用序列化也能完成深复制的功能:对象序列化后写入流中,此时也就不存在引用什么的概念了,再从流中读取,生成新的对象,新对象和原对象之间也是完全互不影响的。
4.使用clone实现的深克隆其实是浅克隆中嵌套了浅克隆,与toString方法类似
基本类型与封装类
byte(8),short(16),int(32),long(64),float(32),double(64),boolean,char(16位unicode)
区别
基本类型只能按值传递,封装类都是按引用传递
封装类可以更精确的对其变量控制,具有基本类型不具备的方法例如xxxValue(),toString(),Integer.parseInt()
Integer.valueOf()
int在**[-128,127]之间的时候他会直接拿缓存,而不会new Integer(),Integer.valueOf()方法基于减少对象创建次数和节省内存的考虑,缓存了[-128,127]之间的数字。此数字范围内传参则直接返回缓存中的对象**
类型转换
byte,short,char—> int — > long—> float —> double
低转高自动类型转换;高转低强制类型转换(xxx)
String,StringBuilder,StringBuffer
区别
String:值是不可变的,每次操作都会生成新的String对象,效率低
StringBuffer:值可变,是线程安全的字符串操作类
StringBuilder: 值可变,线程不安全效率快
String常用方法:
charAt(int index) 返回指定索引处的值
concat(String str) 将指定字符串连接到该字符串的末尾
contains(CharSequence cs) 字符串包含指定的char值序列时返回true
equals(Object anObject) 将此字符串与指定对象进行比较
getBytes(String chatsetName) 使用给定的编码将String编码为字节序列,存储到新的字节数组中
replace(char oldChar,char newChar) 返回替换后的字符串
split(String regex,int limit) 将此字符串拆分为数组
substring(int beginIndex,int endIndex) 返回两个索引之间的字符串
toLowerCase() toUpperCase() 小写 大写展示
trim() 删除前后空格
ValueOf(int i) 返回int参数的字符串其他类型相同
StringBuffer、StringBuilder常用方法:
append(String str) 将String类型的字符串添加到序列中
insert(int index,String str) 在指定序列添加字符串
reverse() 将字符串序列反转
Date格式化
String format = "yyyy-MM-dd";
String str = "20090909";
DateFormat df = new SimpleDateFormat("yyyyMMdd");
DateFormat df2 = new SimpleDateFormat(format);
try {
Date d = df.parse(str);
System.out.println(df2.format(d));
} catch (ParseException e) {
e.printStackTrace();
}
组合与继承
组合将所有部分类对象创建在组合类中,具有良好的扩展性,松耦合
继承子类继承了父类的接口,子类依赖父类高耦合
凡是需要向上转型的必须使用继承
向上转型
父类引用指向子类对象
public class Father{
public static void test(Father father){
System.out.println("子类对象向上转型为父类");
}
}
public class Son extends Father{
public static void main(String args[]){
Son son = new Son();
Father.test(son);
}
}
接口与类的区别
- 接口不能实例化。
- 接口没有构造方法。
- 接口中所有的方法必须是抽象方法。
- 接口不能包含成员变量,除了 static 和 final 变量。
- 接口不是被类继承了,而是要被类实现。
- 接口支持多继承(接口的继承)。
抽象类和接口的区别
- 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
- 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
static关键字
static修饰的方法或变量不需要依赖对象去访问,直接通过类名去访问
static方法内部不能调用非静态方法和非静态变量,反过来则可以。(初始化时间不同)
静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化
java内存机制
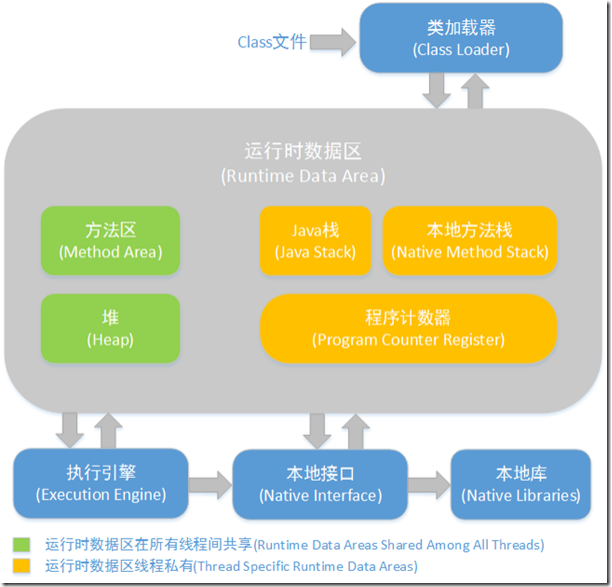
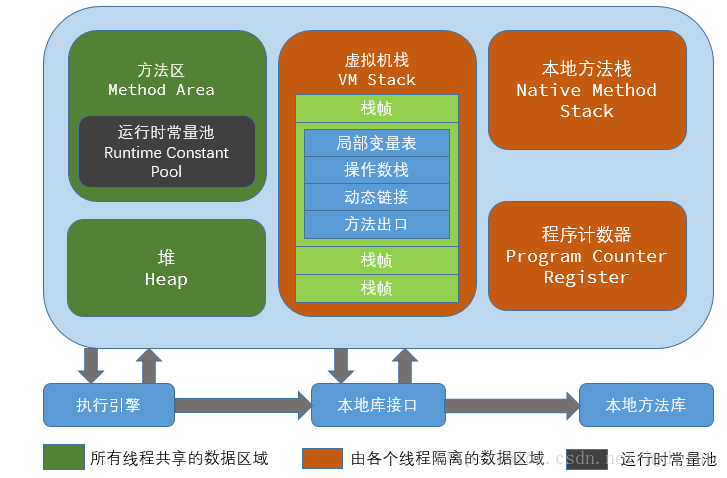
程序计数器(线程私有)
一块较小的内存空间, 是当前线程所执行的字节码的行号指示器,每条线程都要有一个独立的程序计数器,这类内存也称为“线程私有”的内存。
正在执行 java 方法的话,计数器记录的是虚拟机字节码指令的地址(当前指令的地址)。如果还是 Native 方法,则为空。
这个内存区域是唯一一个在虚拟机中没有规定任何OutOfMemoryError 情况的区域。
虚拟机栈(线程私有)
是描述java 方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame) 用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
栈帧( Frame)是用来存储数据和部分过程结果的数据结构,同时也被用来处理动态链接(Dynamic Linking)、 方法返回值和异常分派( Dispatch Exception)。栈帧随着方法调用而创建,随着方法结束而销毁——无论方法是正常完成还是异常完成(抛出了在方法内未被捕获的异常)都算作方法结束。
本地方法栈(线程私有)
本地方法区和Java Stack 作用类似, 区别是虚拟机栈为执行 Java 方法服务, 而本地方法栈则为Native 方法服务, 如果一个VM 实现使用C-linkage 模型来支持Native 调用, 那么该栈将会是一个C 栈,但 HotSpot VM 直接就把本地方法栈和虚拟机栈合二为一。
堆(Heap-线程共享)运行时数据区
是被线程共享的一块内存区域,创建的对象和数组都保存在 Java 堆内存中,也是垃圾收集器进行垃圾收集的最重要的内存区域。由于现代 VM 采用分代收集算法, 因此 Java 堆从GC 的角度还可以细分为: 新生代(Eden 区、From Survivor 区和 To Survivor 区)和老年代。
方法区/永久代(线程共享)
即我们常说的永久代(Permanent Generation), 用于存储被JVM 加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. HotSpot VM 把GC 分代收集扩展至方法区, 即使用Java堆的永久代来实现方法区, 这样 HotSpot 的垃圾收集器就可以像管理 Java 堆一样管理这部分内存, 而不必为方法区开发专门的内存管理器(永久带的内存回收的主要目标是针对常量池的回收和类型的卸载, 因此收益一般很小)。
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述等信息外,还有一项信息是常量池
(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。 Java 虚拟机对 Class 文件的每一部分(自然也包括常量池)的格式都有严格的规定,每一个字节用于存储哪种数据都必须符合规范上的要求,这样才会被虚拟机认可、装载和执行。
内部类
如果你需要生成对外部类对象的引用,可使用外部类的名字后面紧跟圆点和this。这样产生的引用自动地具有正确的类型。
public class Outer{
class Inner{
Outer getOut(){
return Outer.this;
}
}
}
如果你想告知其他对象,去创建其某个内部类的对象,要实现此目的必须在new表达式中提供对其他外部类的引用,这就需要使用.new语法。(但是你这个内部类是个嵌套类的话(静态内部类)正常创建即可)
public class Outer{
class Inner{
}
public static void main(String[] args){
Outer o = new Outer();
Outer.Inner i = o.new Inner();
}
}
集合
数组与集合
区别
1.数组是大小固定的,一旦创建无法扩容;集合大小不固定,
2.数组的存放的类型只能是一种,集合存放的类型可以不是一种(不加泛型时添加的类型是Object);
3.数组是java语言中内置的数据类型,是线性排列的,执行效率或者类型检查,都是最快的.
转换
List<String> list = Arrays.asList("1","2","3");
//此方法转的list不能被修改
String[] array = (String[]) list.toArray();
LinkedList与ArrayList的区别
ArrayList基于动态数组实现,LinkedList基于链表实现
LinkedList增加、删除快(类中包含了 first 和 last 两个指针(Node)。Node 中包含了上一个节点和下一个节点的引用,这样就构成了双向的链表),相反ArrayList增删必须重新copy数组效率低下
ArrayList随机访问查询快(其实就是对数组的封装,通过数组下标)
HashSet、LinkedHashSet和TreeSet区别
数据是唯一的(这是因为HashSet中定义了一个HashMap对象,调用add方法的时候用的HashMap将set中的值当做key来存储,问题来到Map的key值为什么是唯一的因为key是用hash值来对比的,相同的后边的会将前边的替换,所以当set存储对象和map存储key键对象的时候,那个类必须要重写equals和hashcode否则会将相同对象都添加到集合当中去产生hash冲突)
HashSet存储的数据过程中是无序的(但是我之前发现过它存储的数据是根据hash值大小排列的)
LinkedHashSet(继承了HashSet类)存储的数据是按照插入顺序来排序的
HashSet增删改查效率都是相对快的(LinkedHashSet毕竟又增添了一层链表数据结构)
TreeSet其实是个TreeMap底层是一个红黑树是一棵二叉搜索树,如果需要一个排序的Set,选择TreeSet
HashMap夺命问
https://mp.weixin.qq.com/s/eYDsVJF05t9DeSgtuJ9lvw
HashMap、LinkedHashMap和TreeMap的区别
Map中作为对象作为key键来存储必须重写equals和hashcode
HashMap中key的值没有顺序(其实内部是按hash值排序的),常用来做统计,查询快。
LinkedHashMap继承了HashMap。它内部有一个链表,保持Key插入的顺序。迭代的时候,也是按照插入顺序迭代,而且迭代比HashMap快。
循环遍历
1.在 for 循环中使用 entries 实现 Map 的遍历(最常见和最常用的)。
Map<String, String> map = new HashMap<String, String>();
map.put("Java入门教程", "http://c.biancheng.net/java/");
map.put("C语言入门教程", "http://c.biancheng.net/c/");
for (Map.Entry<String, String> entry : map.entrySet()) {
String mapKey = entry.getKey();
String mapValue = entry.getValue();
System.out.println(mapKey + ":" + mapValue);
}
2.使用 for-each 循环遍历 key 或者 values,一般适用于只需要 Map 中的 key 或者 value 时使用。性能上比 entrySet 较好。
Map<String, String> map = new HashMap<String, String>();
map.put("Java入门教程", "http://c.biancheng.net/java/");
map.put("C语言入门教程", "http://c.biancheng.net/c/");
// 打印键集合
for (String key : map.keySet()) {
System.out.println(key);
}
// 打印值集合
for (String value : map.values()) {
System.out.println(value);
}
3.使用迭代器(Iterator)遍历
Map<String, String> map = new HashMap<String, String>();
map.put("Java入门教程", "http://c.biancheng.net/java/");
map.put("C语言入门教程", "http://c.biancheng.net/c/");
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
4.通过键找值遍历,这种方式的效率比较低,因为本身从键取值是耗时的操作。
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
Collections
fill(List<? super T> list, T obj) 用指定元素代替指定列表的所有元素
shuffle(List<List<?> list) 打乱排序
sort(List<List<?> list) 排序
swap(List<?> list,int i,int j) 交换指定列表中指定位置的元素
synchronizedXxx(Xxx xx) 返回线程同步集合
unmodifiableCollection(Collection c) 使集合不能被修改
集合算法
排序、洗牌、搜索、常规数据操作、构成、找极值
集合数据结构
动态数组\哈希表\链表\红黑树\二叉树
异常和错误
异常类的根类为Throw
Error:应用程序非常严重的错误,不可修复
Exception:程序正常运行可预料的,可修复的。
Exception又分为
“受检查的异常”例如io异常,中断异常会自动提醒你抛出异常。
“不受检查的异常”例如数组下标越界 空指针等异常。
常见的Error:
OutOfMemoryError 内存不足
ThreadDeath 线程死亡
VirtualMachineError 虚拟机错误
常见的Exception:
NullPointerException 空指针异常 ArrayIndexOutOfBoundsException 数组下标越界异常, ArithmaticException 算数异常 如除数为零 IllegalArgumentException 不合法参数异常 InterruptedException 中断异常
ParseException 解析异常
ConcurrentModificationException异常
初始化迭代器会对ArrayList中的迭代器里的modCount赋值,由于add()在其之后会为modCount+1,当用it.next()会检查modCount的值,不同就会抛出此异常
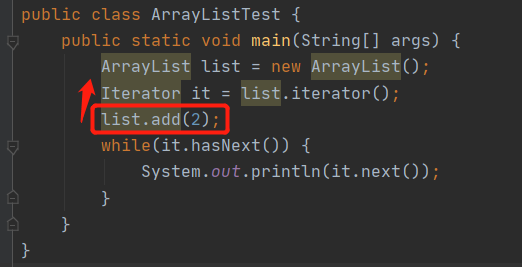
IO
字符流与字节流的差异
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。
所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点
读文件的差异
当每次读取的数据量很小时,FileInputStream每次都是从硬盘读入,而BufferedInputStream大部分是从缓冲区读入。读取内存速度比读取硬盘速度快得多,因此BufferedInputStream效率高。
BufferedInputStream的默认缓冲区大小是8192字节。当每次读取数据量接近或远超这个值时,两者效率就没有明显差别了。
File常用方法
createTempFile(String prefix, String suffix) // 在默认临时文件目录创建一空文件,使用给定的前缀和后缀
delete() //删除文件或目录
exists() //判断路径是否存在
getAbsolutePath //返回绝对路径的字符串
mkdir() //创建目录
BIO、NIO、AIO有什么区别?
BIO:线程发起IO请求,不管内核是否准备好IO操作,从发起请求起,线程一直阻塞,直到操作完成。
NIO:线程发起IO请求,立即返回;内核在做好IO操作的准备之后,通过调用注册的回调函数通知线程做IO操作,线程开始阻塞,直到操作完成。
AIO:线程发起IO请求,立即返回;内存做好IO操作的准备之后,做IO操作,直到操作完成或者失败,通过调用注册的回调函数通知线程做IO操作完成或者失败。
BIO是一个连接一个线程。
NIO是一个请求一个线程。
AIO是一个有效请求一个线程。
BIO:同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO:异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
适用场景分析
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
多线程
进程和线程
线程是进程的基本执行单元,一个进程的所有任务都在线程中执行;
进程是指在系统中正在执行的一个应用程序
并发和并行
并发是多个线程被(一个)cpu轮流切换执行
并行是多个线程同时被(多个)cpu执行
守护线程(daemon thread)
专门服务其他线程;它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。在 Java 中垃圾回收线程就是特殊的守护线程。
如果其他的线程(即用户自定义线程)都执行完毕,连main线程也执行完毕,那么jvm就会退出(即停止运行),此时连jvm都停止运行了,守护线程当然也就停止执行了。
线程的生命周期
线程要经历新建、就绪、运行(活动)、阻塞和死亡五种不同的状态。
这五种状态都可以通过Thread类中的方法进行控制。
① 新建状态 、使用new 操作符创建一个线程后,该线程仅仅是一个空对象,这时的线程处于创建状态。
② 就绪状态 、使用start()方法启动一个线程后,系统为该线程分配了除CPU外的所需资源,使该线程处于就绪状态。
③ 运行状态 、系统真正执行线程的run()方法。
④ 阻塞和唤醒线程阻塞状态 、使用sleep(),wait()方法进行操作。
⑤ 死亡状态 、线程执行了interrupt()或stop()方法,那么它也会以异常退出的方式进入死亡状态。
同步式线程调度 VS 抢占式线程调度
| 协同式线程调度 | 抢占式线程调度 | |
|---|---|---|
| 控制权 | 线程本身(线程执行完后,主动通知系统切换) | 系统决定 |
| 优点 | 1.切换操作线程已知,控制简单 2.不存在线程同步问题 | 线程执行时间可控,不会因为一个线程耽误整个进程 |
| 缺点 | 执行时间不可控,一个线程可能耽误整个进程 | 1.切换控制复杂 2.存在线程同步问题 |
创建线程的方式
1.继承Thread类
public class ThreadSon extends Thread{
public static void main(String[] args) {
ThreadSon ts = new ThreadSon();
ts.start();
}
}
2.实现Runable接口
public class RunableImpl implements Runnable{
@Override
public void run() {
System.out.println("RunableImpl");
}
public static void main(String[] args) {
Thread t = new Thread(new RunableImpl(),"RunableImpl");
t.start();
}
}
3.实现Callable接口(带有返回值)
public class CallableImpl implements Callable<String> {
@Override
public String call() throws Exception {
return "CallableImpl";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallableImpl ci = new CallableImpl();
FutureTask<String> ft = new FutureTask<>(ci);
new Thread(ft,"CallableImpl").start();
/*ExecutorService executorService = Executors.newCachedThreadPool();
executorService.submit(ft);//实现Callable接口的只能用submit*/
System.out.println(ft.get());
//executorService.shutdown();
}
}
4.通过线程池
public class ExecutorServiceTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
//executorService.execute(()-> System.out.println("Lambda Create Thread"));
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("线程池");
}
});
executorService.shutdown();
}
}
sleep()和wait()区别
sleep():
让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。
他不能改变对象的机锁,当一个synchronized块中调用了sleep() 方法,线程虽然进入休眠,但是对象的机锁没有被释放,其他线程依然无法访问这个对象。
wait():
wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
**区别:**调用sleep方法的线程不会释放对象锁,而调用wait() 方法会释放对象锁
java程序怎么抱枕多线程运行安全
线程的安全性问题体现在:
原子性:一个或者多个操作在 CPU 执行的过程中不被中断的特性
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到
有序性:程序执行的顺序按照代码的先后顺序执行
导致原因:
缓存导致的可见性问题
线程切换带来的原子性问题
编译优化带来的有序性问题
解决办法:
JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
synchronized、volatile、LOCK,可以解决可见性问题
Happens-Before 规则可以解决有序性问题
Happens-Before 规则如下:
程序次序规则:在一个线程内,按照程序控制流顺序,书写在前面的操作先行发生于书写在后面的操作
管程锁定规则:一个unlock操作先行发生于后面对同一个锁的lock操作
volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作
线程启动规则:Thread对象的start()方法先行发生于此线程的每一个动作
线程终止规则:线程中的所有操作都先行发生于对此线程的终止检测
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始
ThreadLocal是什么?有哪些应用场景?
Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。
ThreadLocal在每个本地线程中创建了一个ThreadLocalMap对象,每个线程可以访问自己内部ThreadLocalMap对象里的value。通过这种方式,实现线程之间的数据隔离。
场景
为每个线程分配一个JDBC连接的Connection。这样可以保证每个线程都在各自的Connection上进行数据库的操作,不会出现A线程关闭了线程B正在使用的Connection。
volatile(内存可见性)
当多个线程操作共享数据时,可以保证内存中的数据可见。用这个关键字修饰共享数据,就会及时的把线程缓存中的数据刷新到主存中去(他可直接操作内存中的数据,而不是拿到自己线程去单独修改再放回主存去)
原子变量
在java.util.concurrent.atomic包下
- 有volatile保证内存可见性。
- 用CAS算法保证原子性。
public class TestIcon {
public static void main(String[] args){
AtomicDemo atomicDemo = new AtomicDemo();
for (int x = 0;x < 10; x++){
new Thread(atomicDemo).start();
}
}
}
class AtomicDemo implements Runnable{
private int i = 0;
public int getI(){
return i++;
}
@Override
public void run() {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getI());
}
}
//会有重复值打印
//改造
//private int i = 0;
AtomicInteger i = new AtomicInteger();
public int getI(){
return i.getAndIncrement();
}
CAS算法
CAS算法是计算机硬件对并发操作共享数据的支持,CAS包含3个操作数:
- 内存值V
- 预估值A
- 更新值B
当且仅当V==A时,才会把B的值赋给V,即V = B,否则不做任何操作。
synchronized
防止多个线程同一时间调用此代码块或者方法.
- 修饰一个类,其作用的范围是synchronized后面括号括起来的部分, 作用的对象是这个类的所有对象。
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法, 作用的对象是调用这个方法的对象;
- 修改一个静态的方法,其作用的范围是整个静态方法, 作用的对象是这个类的所有对象;
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码, 作用的对象是调用这个代码块的对象;
锁分段
ConcurrentHashMap默认分成了16个segment,每个Segment都对应一个Hash表,且都有独立的锁。所以这样就可以每个线程访问一个Segment,就可以并行访问了,从而提高了效率。这就是锁分段。
乐观锁、悲观锁
乐观锁:每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
闭锁
ContDownLatch是一个同步辅助类,在完成某些运算时,只有其他所有线程的运算全部完成,当前运算才继续执行,这就叫闭锁。
由于调用了 countDown() 方法,所以在当前计数到达零之前,await 方法会一直受阻塞。之后,会释放所有等待的线程,await 的所有后续调用都将立即返回。
Lock同步锁
Lock需要通过lock()方法上锁,通过unlock()方法释放锁。为了保证锁能释放,所有unlock方法一般放在finally中去执行。
public class TestLock {
public static void main(String[] args) {
Ticket td = new Ticket();
new Thread(td, "窗口1").start();
new Thread(td, "窗口2").start();
new Thread(td, "窗口3").start();
}
}
class Ticket implements Runnable {
private Lock lock = new ReentrantLock();
private int ticket = 100;
@Override
public void run() {
while (true) {
lock.lock();
try {
//synchronized (TestLock.class) {
if (ticket > 0) {
try {
Thread.sleep(200);
} catch (Exception e) {
}
System.out.println(Thread.currentThread().getName() + "完成售票,余票为:" + (--ticket));
}
//}
}finally {
lock.unlock();
}
}
}
}
可中断锁
响应中断的锁,Lock是可中断锁(体现在**lockInterruptibly()**方法),synchronized不是。如果线程A正在执行锁中代码,线程B正在等待获取该锁。时间太长,线程B不想等了,可以让它中断自己。
公平锁
尽量以请求锁的顺序获取锁。比如同时有多个线程在等待一个锁,当锁被释放后,等待时间最长的获取该锁,跟京牌司法拍卖一个道理。非公平锁可能会导致有些线程永远得不到锁,synchronized是非公平锁,ReentrantLock是公平锁。
可重入锁
可重入就是说某个线程已经获得某个锁,可以再次获取锁而不会出现死锁
ReadWriterLock读写锁
如果有两个线程,写写/读写需要互斥,读读不需要互斥。这个时候可以用读写锁。
public class TestReadWriterLock {
public static void main(String[] args){
ReadWriterLockDemo rw = new ReadWriterLockDemo();
new Thread(new Runnable() {//一个线程写
@Override
public void run() {
rw.set((int)Math.random()*101);
}
},"write:").start();
for (int i = 0;i<100;i++){//100个线程读
Runnable runnable = () -> rw.get();
Thread thread = new Thread(runnable);
thread.start();
}
}
}
class ReadWriterLockDemo{
private int number = 0;
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
//读(可以多个线程同时操作)
public void get(){
readWriteLock.readLock().lock();//上锁
try {
System.out.println(Thread.currentThread().getName()+":"+number);
}finally {
readWriteLock.readLock().unlock();//释放锁
}
}
//写(一次只能有一个线程操作)
public void set(int number){
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName());
this.number = number;
}finally {
readWriteLock.writeLock().unlock();
}
}
}
Synchronized 和ReentrantLock区别
1.synchronized 是Java内置关键字,在jvm层面,Lock是个java类。
2.synchronized 无法判断是否获取锁的状态,Lock 可以判断是否获取到锁。
3.synchronized 会自动释放锁,Lock 需要在 finally 中手工释放锁(unlock() 方法释放锁),否则容易造成线程死锁。
4.synchronized 的锁可重入、不可中断、非公平,而 Lock 锁可重入、可判断、可公平。
5.synchronized 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll();ReentrantLock 控制等待和唤醒需要结合 Condition 的 await() 和 signal()、signalAll() 方法
6.大量线程同时竞争,ReentrantLock要远胜于synchronized。
JDK5中,synchronized是性能低效的,因为这是一个重量级操作,对性能的最大影响是阻塞的实现,挂起线程和恢复线程的操作,都需要转入内核态中完成,给并发带来了很大压力。
JDK6中synchronized加入了自适应自旋、锁消除、锁粗化、轻量级锁、偏向锁等一系列优化,官方也支持synchronized,提倡在synchronized能实现需求的前提下,优先考虑synchronized来进行同步。
死锁
死锁:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
由Edsger Dijkstrar提出的哲学家就餐问题是一个经典的死锁例证。要修正死锁问题,你必须明白,当以下四个条件同时满足时,就会发生死锁:
- 互斥条件:一个资源每次只能被一个进程使用。
- 占有且等待:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不可强行占有:进程已获得的资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
备注:所以要防止死锁的话,只需破坏其中一个即可。防止死锁最容易的方法是破坏第4个条件。
线程池的理解
池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池提供了一种限制、管理资源的策略。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
使用线程池的好处:
- 降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度:当任务到达时,可以不需要等待线程创建就能立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,监控和调优。
newFixThreadPool只有核心线程(数量固定不会被回收),并且数量固定的,也不会被回收,所有线程都活动时,因为队列没有限制大小,新任务会等待执行。
newSingleThreadPool只有一个核心线程,确保所有任务都在同一线程中按顺序执行,不需要处理线程同步的问题
newCachedThreadPool只有非核心线程(闲置超时会被回收),最大线程数非常大,所有线程都活动时,会为新任务创建新线程,否则利用空闲线程(60s空闲时间,过了就会被回收,所以线程池中有0个线程的可能)处理任务。适合执行大量的耗时较少的任务
newScheduledThreadPool核心线程数固定,非核心线程数没有限制。主要用于执行定时任务以及没有固定周期的重复任务。
线程池中 submit() 和 execute()方法有什么区别?
execute() 参数 Runnable ;submit() 参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable)
execute() 没有返回值;而 submit() 有返回值
submit() 的返回值 Future 调用get方法时,可以捕获处理异常
创建多少线程合适

- CPU 密集型程序
- I/O 密集型程序
CPU 密集型程序
一个完整请求,I/O操作可以在很短时间内完成, CPU还有很多运算要处理,也就是说 CPU 计算的比例占很大一部分
多核最大化利用Cpu
对于 CPU 密集型来说,理论上 线程数量 = CPU 核数(逻辑)就可以了,但是实际上,数量一般会设置为 CPU 核数(逻辑)+ 1
原因:计算(CPU)密集型的线程恰好在某时因为发生一个页错误或者因其他原因而暂停,刚好有一个“额外”的线程,可以确保在这种情况下CPU周期不会中断工作。
I/O 密集型程序
与 CPU 密集型程序相对,一个完整请求,CPU运算操作完成之后还有很多 I/O 操作要做,也就是说 I/O 操作占比很大部分
进行I/O操作时cpu处于空闲状态,利用上cpu
最佳线程数 = (1/CPU利用率) = 1 + (I/O耗时/CPU耗时)
线程练习题
顺序打印10以内的奇偶数
public class Demo {
private static int count = 0;
private static final Object lock = new Object();
public static void main (String[] args) {
try {
new Thread(new TurningRunner(),"偶数").start();
Thread.sleep(1);
new Thread(new TurningRunner(),"奇数").start();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class TurningRunner implements Runnable {
@Override
public void run() {
while (count <= 10) {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + ":" + count++);
lock.notifyAll();
try {
if (count <= 10) {
lock.wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}
public class SortPrintNum {
private static int count = 0;
private static Lock lock = new ReentrantLock();
static class TurningRunner implements Runnable {
@Override
public void run() {
while (count <= 10) {
lock.lock();
try {
System.out.println(count++);
} finally {
lock.unlock();
}
}
}
}
public static void main(String[] args) {
try {
new Thread(new Demo.TurningRunner(),"偶数").start();
Thread.sleep(1);
new Thread(new Demo.TurningRunner(),"奇数").start();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
编写一个程序开三个线程,分别为A,B,C将自己name在屏幕打印10遍,结果按顺序显示如ABCABC
同步方法
public class SortPrintDemo1 {
public static void main(String[] args) {
AlternationDemo ad = new AlternationDemo();
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<10;i++){
ad.printA();
}
}
},"A").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<10;i++) {
ad.printB();
}
}
},"B").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<10;i++) {
ad.printC();
}
}
},"C").start();
}
static class AlternationDemo{
private int i = 1;
public synchronized void printA() {
while (i!=1) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName());
i = 2;
this.notifyAll();
}
public synchronized void printB() {
while (i!=2) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName());
i = 3;
this.notifyAll();
}
public synchronized void printC() {
while (i!=3) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName());
i = 1;
this.notifyAll();
}
}
}
Lock锁
public class SortPrintDemo2 {
public static void main(String[] args) {
AlternationDemo ad = new AlternationDemo();
new Thread(() -> {
for (int i=0;i<10;i++){
ad.printA();
}
},"A").start();
new Thread(() -> {
for (int i=0;i<10;i++) {
ad.printB();
}
},"B").start();
new Thread(()-> {
for (int i=0;i<10;i++) {
ad.printC();
}
},"C").start();
}
static class AlternationDemo{
private int flag = 1;
private Lock lock = new ReentrantLock();
Condition condition1 = lock.newCondition();
Condition condition2 = lock.newCondition();
Condition condition3 = lock.newCondition();
public void printA() {
lock.lock();
try {
while (flag != 1) {
condition1.await();
}
System.out.println(Thread.currentThread().getName());
flag = 2;
condition2.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printB() {
lock.lock();
try {
while (flag != 2) {
condition2.await();
}
System.out.println(Thread.currentThread().getName());
flag = 3;
condition3.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printC() {
lock.lock();
try {
while (flag != 3) {
condition3.await();
}
System.out.println(Thread.currentThread().getName());
flag = 1;
condition1.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
JVM
调优
https://www.jianshu.com/p/a2a6a0995fee
反射
类的加载
java文件是咱们编写的代码文件,.class文件是字节码文件是由java源文件通过JVM编译后生成的文件。
当一个类未被加载到内存中,JVM会通过加载、连接、初始化三步对类进行初始化。
1.加载:将类的class文件读入到内存中,通过类加载器加载你所需要的类并将类的信息加载到jvm方法区中,然后在堆中实例化一个class对象,并为之创建一个class对象,作为方法区中这个类信息的入口。
2.连接:细分为三步。
验证:验证这个类是否合法,是否符合字节码格式、变量名是否重复
准备:为类的静态变量分配内存并设为jvm的初值(int 就是0),对于非静态变量不会为他们分配内存
解析:jvm会将所有的类或接口名、字段名、方法名转换为具体的内存地址。
3.初始化:
- 通过new关键字实例化对象、读取或设置类的静态变量、调用类的静态方法。
- 通过class的newInstance()方法。
- 使用Constructor类的newInstance方法。
- 使用Clone方法创建对象
- 使用(反)序列化机制创建对象
双亲委派
当一个类收到了类加载请求,他首先不会尝试自己去加载这个类,而是把这个请求委派给父类去完成
优点:使用不同的类加载器最终得到的都是同样一个 Object 对象。
获取class实例
Person person = new Person();
//1
Class c = Person.class;
//2
Class d = person.getClass();
//3
Class e = Class.forName("com.smartyouth.controller.Person");
//4
ClassLoader cl = c.getClassLoader();
Class f = cl.loadClass("com.smartyouth.controller.Person");
Person p = (Person)f.newInstance();
注解
@Override:用在方法上,表示方法重写了父类的方法,若父类没有此方法编译无法通过
@Deprecated 表示这个方法已经过期,不建议开发者使用
@SuppressWarnings({ “rawtypes”, “unused” })英文的意思是抑制的意思,这个注解的用处是忽略警告信息。
比如大家使用集合的时候,有时候为了偷懒,会不写泛型
@SafeVarargs 这是1.7 之后新加入的基本注解. 如例所示,当使用可变变量参数的时候,而参数的类型又是泛型T的话,就会出现警告。 这个时候,就使用@SafeVarargs来去掉这个警告
@FunctionalInterface这是Java1.8 新增的注解,用于约定函数式接口(接口只有一个抽象方法),主要配合Lambda表达式
网络编程
在网络通信协议下,实现网络互连的不同计算机上运行的程序间进行数据交换。
网络编程三要素
IP地址、端口、协议(UDP、TCP)
IP地址

InetAddress

端口

协议


UDP
- 用户数据报协议(User Datagram Protocol)
- UDP是无连接通信协议,在数据传输时,数据的发送端和接受端不建立逻辑连接。(即大送端不会确认接收端是否存在,就会发出数据;接收端收到数据时,也不会向发送端反馈是否收到数据。
- UDP协议消耗资源小,通信效率高,通常会用于音频、视频和普通数据的传输。
- UDP面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议
TCP
-
传输控制协议(Transimission Control Protocol)
-
TCP协议是面向连接的通信协议,即发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。TCP连接中需明确客户端与服务器端,每次连接的创建都需要经过“三次握手”
-
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠
第一次:客户端向服务器发出连接请求,等待服务器的确认
第二次:服务端向客户端会送一个响应,通知客户端收到了连接请求
第三次:客户端再次向服务器端发送确认信息,确认连接
UDP
它在通信的两端各建立一个Socket对象,但这两个Socket只是发送,接受数据的对象
Java提供了DatagramSocket类作为基于UDP协议的Socket
UDP发送数据
1.创建发送端的Socket对象(DatagramSocket)
DatagramSocket()
2.创建数据,并把数据打包(DatagramPacket)
DatagramPacket(byte[] buf, int length, InetAddress address, int port)
构造用于发送长度的分组的数据报包 length指定主机上到指定的端口号。
3.调用DatagramSocket对象的方法发送数据
send(DatagramPacket p)
4.关闭发送端
UDP接收数据
1.创建接收端的Socket对象(DatagramSocket)
DatagramSocket(int port)
2.创建一个数据包,用于接受数据
DatagramPacket(byte[] buf, int length)
构造一个 DatagramPacket用于接收长度的数据包 length 。
3.调用DatagramSocket对象的方法接收数据
receive(DatagramPacket p)
4.解析数据包(把数据在控制台显示)
5.关闭接收端
Send:
DatagramSocket ds = new DatagramSocket();
DatagramPacket dp = new DatagramPacket(bys,bys.length,inetAddress,port);
ds.send(dp);
Receive:
DatagramSocket ds = new DatagramSocket();
DatagramPacket dp = new DatagramPacket(bys,bys.length);
ds.receive(dp);
TCP
在通信的两端各建立一个Socket对象,从而在通信的两端形成网咯虚拟链路,一旦建立了虚拟的网络链路,两端的程序就可以通过虚拟链路进行通信。
java对基于TCP协议的网络提供了良好的封装,使用Socket对象来代表两端的通信端口,并通过Socket产生IO流来进行网路通信,java为客户端提供了Socket类,为服务器提供了ServerSocket类。
TCP发送数据
1.创建客户端的Socket对象(Socket)
Socket(String host,int port)
2.获取输出流,写数据
OutputStream getOutputStream()
3.释放资源
void close()
TCP接收数据
-
创建服务器端的Socket对象(ServerSocket)
ServerSocket(int port)
-
监听客户端连接,返回一个Socket对象
Scoket accept()
-
获取输入流,读数据,并把数据显示在控制台
InputStream getInputStream()
-
释放资源
void close()
Server:
ServerSocket ss = new ServerScoket(PORT);
Socket s = ss.accept();
Client:
Socket s = new Socket(IP,PORT)
TCP三次握手
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O2wmxiBQ-1620630936768)(https://i.loli.net/2021/03/18/4dNrgkX17pQsotK.jpg)]
- 第一次握手:客户端尝试连接服务器,向服务器发送 syn 包(同步序列编号Synchronize Sequence Numbers),syn=j,客户端进入 SYN_SEND 状态等待服务器确认
- 第二次握手:服务器接收客户端syn包并确认(ack=j+1),同时向客户端发送一个 SYN包(syn=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态
- 第三次握手:第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手
HTTP 与 HTTPS 区别
- HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
- 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等。
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
- http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
- HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
JavaWeb
servlet的生命周期
初始化 连接 销毁 回收
Servlet 通过调用 init () 方法进行初始化。
Servlet 调用 service() 方法来处理客户端的请求。
Servlet 通过调用 destroy() 方法终止(结束)。
最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
Servlet单实例,减少了产生servlet的开销;
Get与Post区别
安全性post高,get请求参数显示在地址栏上
携带的数据量post高,get跟url地址栏长度相关(65000)
get请求用来从服务器上获得资源,而post是用来向服务器提交数据
Session和Cookie的区别
Session保存在服务端,Cookie保存在客户端
Session的安全性要高于Cookie
session 能够存储任意的 java 对象,cookie 只能存储 String 类型的对象
Session占用服务器性能,Session过多,增加服务器压力
Session生命周期一般是半个小时,当会话域结束session也会随之消失
单个Cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个Cookie,Session是没有大小限制和服务器的内存大小有关。
Cookie应用场景判断用户是否登录网站,便于下次登录直接登录。
Forward和Redirect
转发在服务器端完成的;重定向是在客户端完成的
转发的速度快;重定向速度慢
转发的是同一次请求;重定向是两次不同请求
转发地址栏没有变化;重定向地址栏有变化
转发必须是在同一台服务器下完成;重定向可以在不同的服务器下完成
JSP有哪些内置对象?以及这些对象的作用分别是什么?
- request:封装客户端的请求,其中包含来自GET或POST请求的参数;
- response:封装服务器对客户端的响应;
- pageContext:通过该对象可以获取其他对象;
- session:封装用户会话的对象;
- application:封装服务器运行环境的对象;
- out:输出服务器响应的输出流对象;
- config:Web应用的配置对象;
- page:JSP页面本身(相当于Java程序中的this);
- exception:封装页面抛出异常的对象。
MySql
事务四个特性(ACID)
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。(转账金钱是不变的)
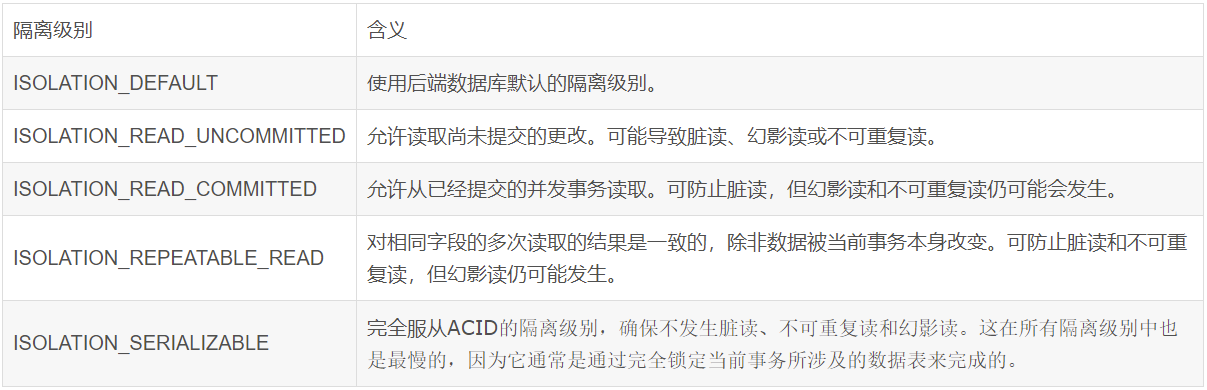
- **隔离性:**数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- **持久性:**事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
主流数据库的区别分页
Mysql
Mysql:使用limit关键字
Select * from 表名 where 条件 limit 开始位置,结束位置。通过动态的改变开始和结束位置的值来实现分页。
Oracle
提供了rownum伪列,oracle系统自动为查询返回结果的每行分配的编号
SELECT * FROM (
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
WHERE ROWNUM <= 40
)
WHERE RN >= 21
sqlserver
分页方案二:(利用ID大于多少和SELECT TOP分页)效率最高,需要拼接SQL语句
分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句
select top 20 * from addressbook where id not in (select top 10 id from addressbook)
分页方案三:(利用SQL的游标存储过程分页) 效率最差,但是最为通用
防止sql注入
网页获取用户输入的数据并将其插入一个MySQL数据库,那么就有可能发生SQL注入安全的问题
通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令
- 1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双"-"进行转换等。
- 2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
- 3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
- 4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
- 5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
- 6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
sql语句优化
1.尽量避免使用*
2.避免在 where 子句中对字段进行 null 值判断(select id from t where num is null )
可在num上设置默认值0(select id from t where num=0)
3.尽量避免在 where 子句中使用!=或<>操作符
4.应尽量避免在 where 子句中对字段进行表达式操作(select id from t where num/2=100 )
应改为(select id from t where num=100*2)
5.使用union all(最好)或者是union(必要的时候)的方式来代替“or”会得到更好的效果。
MySql优化
通常以以下几种原则来进行
- 找出系统瓶颈,提高MySQL数据库整体的性能;
- 合理的结构设计和参数调整,提高数据库操作的相应速度;
- 最大限度节省系统资源,以便系统可以提供更大负荷的服务。
索引为啥用B+树
- B+树能显著减少IO次数,提高效率
- B+树的查询效率更加稳定,因为数据放在叶子节点
- B+树能提高范围查询的效率,因为叶子节点指向下一个叶子节点
存储引擎
1、InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),其它存储引擎都是非事务安全表,支持行锁定和外键,MySQL5.5以后默认使用InnoDB存储引擎。
InnoDB特点: 支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。
如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
2、MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事务,不支持外键。
MyISAM特点: 插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用
3、MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,为查询和引用其他表数据提供快速访问。
MEMORY特点: 所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。
它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Gk5WMwv-1620630936769)(https://i.loli.net/2021/03/18/kdYOzAcLRyNIMi5.png)]
扩展资料:
mysql其余不太常见的存储引擎如下:
1、BDB: 源自Berkeley DB,事务型数据库的另一种选择,支持COMMIT和ROLLBACK等其他事务特性
2、Merge :将一定数量的MyISAM表联合而成一个整体,在超大规模数据存储时很有用
3、Archive :非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive拥有高效的插入速度,但其对查询的支持相对较差
4、Federated: 将不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用
5、Cluster/NDB :高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用
6、CSV: 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个.CSV文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV存储引擎不支持索引。
7、BlackHole :黑洞引擎,写入的任何数据都会消失,一般用于记录binlog做复制的中继
Mysql和Orcale区别
1.对事物的提交
MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
2.分页查询
mysql-----limit oracale-------rownum
3.事务隔离级别
MySQL是read commited的隔离级别,而Oracle是repeatable read的隔离级别,同时二者都支持serializable串行化事务隔离级别,可以实现最高级别的
4.自动增长数据类型
MYSQL有自动增长的数据类型,插入记录时不用操作此字段,会自动获得数据值。ORACLE没有自动增长的数据类型,需要建立一个自动增长的序列号,插入记录时要把序列号的下一个值赋于此字段。
5.单引号的处理
MYSQL里可以用双引号包起字符串,ORACLE里只可以用单引号包起字符串。在插入和修改字符串前必须做单引号的替换:把所有出现的一个单引号替换成两个单引号。
6.数据库中表字段类型
mysql:int、float、double等数值型,varchar、char字符型,date、datetime、time、year、timestamp等日期型。
oracle:number(数值型),varchar2、varchar、char(字符型),date(日期型)等…
其中char(2)这样定义,这个单位在oracle中2代表两个字节,mysql中代表两个字符。
其中varchar在mysql中,必须给长度例如varchar(10)不然插入的时候出错。
Oracale死锁处理

分库分表概念及其使用场景
水平分表
水平分表可以很好缓解数据存储大,导致即使使用了索引,那检索很慢的问题. 比如mysql上千万条数据时,使用索引性能也开始下降了,这时候分表,那么每张表只有500万数据,可以很好解决索引瓶颈问题.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6EpV6tE6-1620630936770)(https://i.loli.net/2021/03/28/8U6udsq754aPmLR.png)]
垂直分表
垂直分表有两个好处. 可以一定解决索引的瓶颈,因为可以让一颗b+树存储更多的数据,比如有图片大文本数据,垂直分表,就有主从表的概念,这样大大提高检索效率; 可以提高并发操作,可以达到同时修改两张表的数据,不会局限于行锁.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tPxsJ0rA-1620630936770)(https://i.loli.net/2021/03/28/6vegniDZ98YHCl7.png)]
水平分库
水平分库一般不是因为索引瓶颈导致的, 而是因为业务并发量太大造成的, 一个数据库已经不能够及时处理所有的业务请求了,必须将数据库请求进行分摊处理.如果不是因为数据库处理不过来,一般水平分表就够用了,水平分表只是解决存储量大的索引瓶颈问题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XdQrpKi5-1620630936771)(https://i.loli.net/2021/03/28/y4HClqQsLojp9AN.png)]
垂直分库
垂直分库一般也不是因为索引瓶颈导致的,也是因为业务量大造成的,一般是指单块业务就很大,必须独立使用一台数据库服务才能及时处理. 否则业务量不大情况,所有模块业务表分不同schema即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-udeeMkqH-1620630936771)(https://i.loli.net/2021/03/28/1YDeciSWaQxTNEk.png)]
使用场景
水平分表: 业务并发量不大, 单表数据大,检索数据慢
垂直分表: 业务并发量不大, 大表(列多),存大文本
水平分库:业务并发量大,单表数据大
垂直分库: 业务并发量大, 业务模块分库,单模块业务量大
总结
1.如果只是数据量大,达到了索引瓶颈,那么只需要分表即可
2.如果是数据量和并发量都大, 那么达到了io和cpu瓶颈,那么需要分库
Spring
Spring是J2EE应用程序框架,是轻量级的IOC和AOP的容器框架,主要针对JavaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和其他框架等组合使用。
好处
1.方便解耦,便于开发(Spring就是一个大工厂,可以将所有对象的创建和依赖关系维护都交给spring管理)
2.spring支持aop编程(spring提供面向切面编程,可以很方便的实现对程序进行权限拦截和运行监控等功能)
3.声明式事务的支持(通过配置就完成对事务的支持,不需要手动编程)
4.方便程序的测试,spring 对junit4支持,可以通过注解方便的测试spring 程序
5.方便集成各种优秀的框架()
Spring有哪些版块
\1. Spring AOP 面相切面编程
\2. Spring ORM Hibernate|mybatis|JDO
\3. Spring Core 提供bean工厂 IOC
\4. Spring Dao JDBC支持
\5. Spring Context 提供了关于UI支持,邮件支持等
\6. Spring Web 提供了web的一些工具类的支持
\7. Spring MVC 提供了web mvc , webviews , jsp ,pdf ,export
作用域
Spring 容器在初始化一个 Bean 的实例时,同时会指定该实例的作用域。Spring3 为 Bean 定义了五种作用域,具体如下。
<bean class="com.****.boss.domain.utils.CacheManager" scope="singleton" init-method="init" destroy-method="destory">
</bean>
1)singleton
单例模式,使用 singleton 定义的 Bean 在 Spring 容器中只有一个实例,这也是 Bean 默认的作用域。
2)prototype
原型模式,每次通过 Spring 容器获取 prototype 定义的 Bean 时,容器都将创建一个新的 Bean 实例。
3)request
在一次 HTTP 请求中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Request 内有效。
4)session
在一次 HTTP Session 中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Session 内有效。
5)global Session
在一个全局的 HTTP Session 中,容器会返回该 Bean 的同一个实例。该作用域仅在使用 portlet context 时有效。
IOC(控制反转)
改变了之前原有的通过new构造方式来创建对象而是转由容器来负责控制程序间的关系并来创建对象。控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转
AOP(面向切面编程)
面向切面编程,它将业务逻辑的各个部分进行隔离,使开发人员在编写业务逻辑时可以专心于核心业务,从而提高了开发效率。
我们使用AOP来做:
1)事务处理:执行方法前开启事务,执行完成后关闭事务,出现异常后回滚事务
2)权限判断:在执行方法前,判断是否具有权限
3)日志:在执行前进行日志处理、
4)异常处理
核心概念
1、切面(aspect):类是对物体特征的抽象,切面就是对横切关注点的抽象(切入点和通知的结合)
2、横切关注点:对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点。
3、连接点(joinpoint):被拦截到的点,因为 Spring 只支持方法类型的连接点,所以在 Spring 中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器。
4、切入点(pointcut):指要对哪些 Joinpoint 进行拦截,对连接点进行拦截的定义
5、通知(advice):所谓通知指的就是指拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类。
6、目标对象:代理的目标对象
7、织入(weave):将切面应用到目标对象并导致代理对象创建的过程
8、引入(introduction):在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段。
SpringBean的生命周期
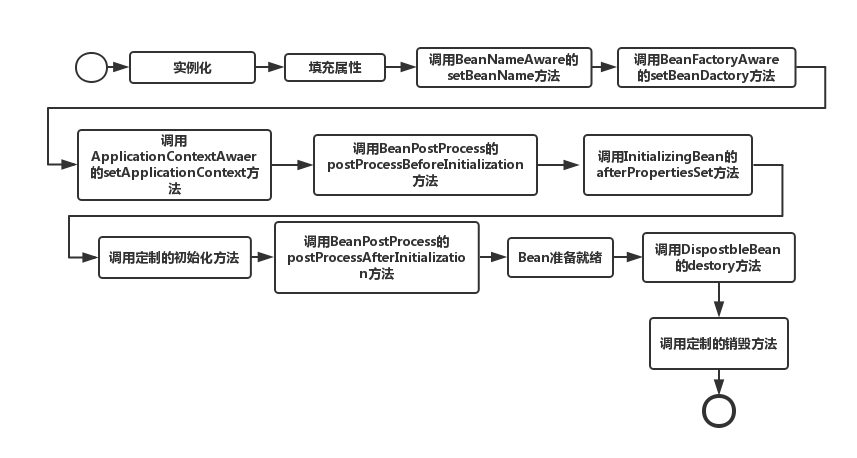
实例化 -> 属性赋值 -> 初始化 -> 销毁
-
根据配置情况调用 Bean 构造方法或工厂方法实例化 Bean,也就是我们通常说的new
-
利用依赖注入完成 Bean 中所有属性值的配置注入。
-
如果Bean实现了BeanNameAware接口,Spring将Bean的ID传递给setBeanName()方法
(实现BeanNameAware清主要是为了通过Bean的引用来获得Bean的ID,一般业务中是很少有用到Bean的ID的) -
如果Bean实现了BeanFactoryAware接口,Spring将调用**setBeanDactory(BeanFactory bf)**方法并把BeanFactory容器实例作为参数传入。
(实现BeanFactoryAware 主要目的是为了获取Spring容器,如Bean通过Spring容器发布事件等) -
如果Bean实现了ApplicationContextAwaer接口,Spring容器将调用setApplicationContext(ApplicationContext ctx)方法,把应用上下文作为参数传入.
(作用与BeanFactory类似都是为了获取Spring容器,不同的是Spring容器在调用setApplicationContext方法时会把它自己作为setApplicationContext 的参数传入,而Spring容器在调用setBeanDactory前需要程序员自己指定(注入)setBeanDactory里的参数BeanFactory ) -
如果Bean实现了BeanPostProcessor接口,Spring将调用它们的postProcessBeforeInitialization(预初始化)方法
(作用是在Bean实例初始化之前进行增强处理,如对Bean进行修改,增加某个功能) -
如果这个Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法
-
如果Bean实现了BeanPostProcess接口,Spring将调用它们的postProcessAfterInitialization(后初始化)方法
(作用与6的一样,只不过6是在Bean初始化前执行的,而这个是在Bean初始化后执行的,时机不同 )注意:以上工作完成以后就可以用这个Bean了,Bean将一直驻留在应用上下文中给应用使用,这个Bean是一个single的,所以一般情况下我们调用同一个ID的Bean会是在内容地址相同的实例
-
当 Bean 不再需要时,会经过清理阶段,如果 Bean 实现了 DisposableBean 这个接口,会调用那个其实现的destroy()方法;
-
最后,如果这个 Bean 的 Spring 配置中配置了 destroy-method 属性,会自动调用其配置的销毁方法。
注释:bean 标签有两个重要的属性(init-method 和 destroy-method)。用它们你可以自己定制初始化和注销方法。它们也有相应的注解(@PostConstruct 和@PreDestroy)。
spring 中的 bean 是线程安全的吗
单例模式不是线程安全的;所有线程共享一个单例实例,当有状态即有数据存储功能时会出现线程安全问题
解决:改为prototype
依赖注入方式(DI)
构造器注入
/*带参数,方便利用构造器进行注入*/ public CatDaoImpl(String message){
this. message = message;
}
<bean id="CatDaoImpl" class="com.CatDaoImpl">
<constructor-arg value=" message "></constructor-arg>
</bean>
setter方法注入
public class Id { private int id;
public int getId() { return id; }
public void setId(int id) { this.id = id; }
}
<bean id="id" class="com.id "> <property name="id" value="123"></property> </bean>
静态工厂注入
public class DaoFactory { //静态工厂
public static final FactoryDao getStaticFactoryDaoImpl(){ return new StaticFacotryDaoImpl();
}
}
public class SpringAction {
private FactoryDao staticFactoryDao; //注入对象
//注入对象的 set 方法
public void setStaticFactoryDao(FactoryDao staticFactoryDao) { this.staticFactoryDao = staticFactoryDao;
}
}
//factory-method="getStaticFactoryDaoImpl"指定调用哪个工厂方法
<bean name="springAction" class=" SpringAction" >
<!--使用静态工厂的方法注入对象,对应下面的配置文件-->
<property name="staticFactoryDao" ref="staticFactoryDao"></property>
</bean>
<!--此处获取对象的方式是从工厂类中获取静态方法-->
<bean name="staticFactoryDao" class="DaoFactory" factory-method="getStaticFactoryDaoImpl"></bean>
实例工厂
public class DaoFactory { //实例工厂public FactoryDao getFactoryDaoImpl(){
return new FactoryDaoImpl();
}
}
public class SpringAction {
private FactoryDao factoryDao; //注入对象
public void setFactoryDao(FactoryDao factoryDao) { this.factoryDao = factoryDao;
}
}
<bean name="springAction" class="SpringAction">
<!--使用实例工厂的方法注入对象,对应下面的配置文件-->
<property name="factoryDao" ref="factoryDao"></property>
</bean>
<!--此处获取对象的方式是从工厂类中获取实例方法-->
<bean name="daoFactory" class="com.DaoFactory"></bean>
<bean name="factoryDao" factory-bean="daoFactory"
factory-method="getFactoryDaoImpl"></bean>
Spring自动装配的方式有哪些?
autowire属性
- byName:根据Bean的名字进行自动装配。
- byType:根据Bean的类型进行自动装配。
- constructor:类似于byType,不过是应用于构造器的参数,如果正好有一个Bean与构造器的参数类型相同则可以自动装配,否则会导致错误。
- autodetect:如果有默认的构造器,则通过constructor的方式进行自动装配,否则使用byType的方式进行自动装配。
<bean id="personService" class="com.mengma.annotation.PersonServiceImpl"
autowire="byName" />
BeanFactory和ApplicationContext的区别
BeanFactory无法支持spring插件,例如:AOP、Web应用等功能。
ApplicationContext是BeanFactory的子类,,以一种更面向框架的工作方式以及对上下文进行分层和实现继承,并在这个基础上对功能进行扩展:
<1>MessageSource, 提供国际化的消息访问
<2>资源访问(如URL和文件)
<3>事件传递
<4>Bean的自动装配
<5>各种不同应用层的Context实现
AOP代理
Spring 提供了两种方式来生成代理对象: JDKProxy 和 Cglib, 具体使用哪种方式生成由AopProxyFactory 根据 AdvisedSupport 对象的配置来决定。默认的策略是如果目标类是接口, 则使用 JDK 动态代理技术,否则使用 Cglib 来生成代理。
静态代理
通常使用AspectJ的编译时增强实现AOP,AspectJ是静态代理的增强,所谓的静态代理就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强。
基于xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<!--目标类 -->
<bean id="customerDao" class="com.mengma.dao.CustomerDaoImpl" />
<!--切面类 -->
<bean id="myAspect" class="com.mengma.aspectj.xml.MyAspect"></bean>
<!--AOP 编程 -->
<aop:config>
<aop:aspect ref="myAspect">
<!-- 配置切入点,通知最后增强哪些方法 -->
<aop:pointcut expression="execution ( * com.mengma.dao.*.* (..))"
id="myPointCut" />
<!--前置通知,关联通知 Advice和切入点PointCut -->
<aop:before method="myBefore" pointeut-ref="myPointCut" />
<!--后置通知,在方法返回之后执行,就可以获得返回值returning 属性 -->
<aop:after-returning method="myAfterReturning"
pointcut-ref="myPointCut" returning="returnVal" />
<!--环绕通知 -->
<aop:around method="myAround" pointcut-ref="myPointCut" />
<!--抛出通知:用于处理程序发生异常,可以接收当前方法产生的异常 -->
<!-- *注意:如果程序没有异常,则不会执行增强 -->
<!-- * throwing属性:用于设置通知第二个参数的名称,类型Throwable -->
<aop:after-throwing method="myAfterThrowing"
pointcut-ref="myPointCut" throwing="e" />
<!--最终通知:无论程序发生任何事情,都将执行 -->
<aop:after method="myAfter" pointcut-ref="myPointCut" />
</aop:aspect>
</aop:config>
</beans>
基于注解
//切面类
@Aspect
@Component
public class MyAspect {
// 用于取代:<aop:pointcut
// expression="execution(*com.mengma.dao..*.*(..))" id="myPointCut"/>
// 要求:方法必须是private,没有值,名称自定义,没有参数
@Pointcut("execution(*com.mengma.dao..*.*(..))")
private void myPointCut() {
}
// 前置通知
@Before("myPointCut()")
public void myBefore(JoinPoint joinPoint) {
System.out.print("前置通知,目标:");
System.out.print(joinPoint.getTarget() + "方法名称:");
System.out.println(joinPoint.getSignature().getName());
}
// 后置通知
@AfterReturning(value = "myPointCut()")
public void myAfterReturning(JoinPoint joinPoint) {
System.out.print("后置通知,方法名称:" + joinPoint.getSignature().getName());
}
// 环绕通知
@Around("myPointCut()")
public Object myAround(ProceedingJoinPoint proceedingJoinPoint)
throws Throwable {
System.out.println("环绕开始"); // 开始
Object obj = proceedingJoinPoint.proceed(); // 执行当前目标方法
System.out.println("环绕结束"); // 结束
return obj;
}
// 异常通知
@AfterThrowing(value = "myPointCut()", throwing = "e")
public void myAfterThrowing(JoinPoint joinPoint, Throwable e) {
System.out.println("异常通知" + "出错了" + e.getMessage());
}
// 最终通知
@After("myPointCut()")
public void myAfter() {
System.out.println("最终通知");
}
}
-------------------------------------------------------
<!--扫描含com.mengma包下的所有注解-->
<context:component-scan base-package="com.mengma"/>
<!-- 使切面开启自动代理 -->
<Serviceaop:aspectj-autoproxy></aop:aspectj-autoproxy>
JDK动态代理
JDK 动态代理主要涉及到 java.lang.reflect 包中的两个类:Proxy 和 InvocationHandler。InvocationHandler 是一个接口,通过实现该接口定义横切逻辑,并通过反射机制调用目标类的代码,动态将横切逻辑和业务逻辑编制在一起。Proxy 利用 InvocationHandler 动态创建一个符合某一接口的实例,生成目标类的代理对象。
public class MyBeanFactory {
public static CustomerDao getBean() {
// 准备目标类
final CustomerDao customerDao = new CustomerDaoImpl();
// 创建切面类实例
final MyAspect myAspect = new MyAspect();
// 使用代理类,进行增强
return (CustomerDao) Proxy.newProxyInstance(
MyBeanFactory.class.getClassLoader(),
new Class[] { CustomerDao.class }, new InvocationHandler() {
public Object invoke(Object proxy, Method method,
Object[] args) throws Throwable {
myAspect.myBefore(); // 前增强
Object obj = method.invoke(customerDao, args);
myAspect.myAfter(); // 后增强
return obj;
}
});
}
}
Cglib
CGLib 全称为 Code Generation Library,是一个强大的高性能,高质量的代码生成类库, 可以在运行期扩展 Java 类与实现 Java 接口,CGLib 封装了 asm,可以再运行期动态生成新的 class。和 JDK 动态代理相比较:JDK 创建代理有一个限制,就是只能为接口创建代理实例, 而对于没有通过接口定义业务方法的类,则可以通过 CGLib 创建动态代理。
Enhancer 类的 setSuperclass()
public class MyBeanFactory {
public static GoodsDao getBean() {
// 准备目标类
final GoodsDao goodsDao = new GoodsDao();
// 创建切面类实例
final MyAspect myAspect = new MyAspect();
// 生成代理类,CGLIB在运行时,生成指定对象的子类,增强
Enhancer enhancer = new Enhancer();
// 确定需要增强的类
enhancer.setSuperclass(goodsDao.getClass());
// 添加回调函数
enhancer.setCallback(new MethodInterceptor() {
// intercept 相当于 jdk invoke,前三个参数与 jdk invoke—致
@Override
public Object intercept(Object proxy, Method method, Object[] args,
MethodProxy methodProxy) throws Throwable {
myAspect.myBefore(); // 前增强
Object obj = method.invoke(goodsDao, args); // 目标方法执行
myAspect.myAfter(); // 后增强
return obj;
}
});
// 创建代理类
GoodsDao goodsDaoProxy = (GoodsDao) enhancer.create();
return goodsDaoProxy;
}
}
通知类型
| 名称 | 说明 |
|---|---|
| org.springframework.aop.MethodBeforeAdvice(前置通知) | 在方法之前自动执行的通知称为前置通知,可以应用于权限管理等功能。 |
| org.springframework.aop.AfterReturningAdvice(后置通知) | 在方法之后自动执行的通知称为后置通知,可以应用于关闭流、上传文件、删除临时文件等功能。 |
| org.aopalliance.intercept.MethodInterceptor(环绕通知) | 在方法前后自动执行的通知称为环绕通知,可以应用于日志、事务管理等功能。 |
| org.springframework.aop.ThrowsAdvice(异常通知) | 在方法抛出异常时自动执行的通知称为异常通知,可以应用于处理异常记录日志等功能。 |
| org.springframework.aop.IntroductionInterceptor(引介通知) | 在目标类中添加一些新的方法和属性,可以应用于修改旧版本程序(增强类)。 |
常用注解
@Component //泛指组件,不知如何归类
@Controller //标注控制层组件,标注在类上分发处理器扫描到检测方法是否使用
@Confuguration //标注为配置类
@Repository //标注dao层,在daoImpl类上注解
@Service //标注服务层组件,在serviceImpl类上
@Bean //会把方法的返回值注入到spring容器
@RestController //@Controller和@ResponseBody的结合体
@ResponseBody //异步请求,用于将Controller方法返回对象通过实地HttpMessageConverter转换指定格式写入Response对象的body数据区
@RequestMapping //用来处理请求地址映射的注解,用于类或方法上,类上表示类中所有响应请求方法都以改地址作为父路径
@GetMapping //等于@requestMapping(method = RequestMethod.Get)
@PathVariable //用于将请求URL中的模板变量映射到功能处理方法的参数上,即取出url模板中的变量为参数
url:/user/1---id
@GetMapping({id})
public User queryUserById(@PathVariable("id")int id){...}
@RequestParam //将查询字符串的参数值绑定到控制器的方法参数,类似一种request.getParameter(“name”)
url: /user/?id=7
@GetMapping
public User queryUserById2(@RequestParam("id") int id){}
@RequestHeader //可以把Request请求header部分的值绑定到方法的参数上。
@Autowired //按照类型装配bean主要用于注入dao,service实例;也可配置在属性,set方法,构造方法
@Qualifier //配合Autowired使用,找到对应类
@Resource //按照name装配
@PropertySource(“classpath:jdbc.properties”) //读取资源文件
@Value("${jdbc.driverClassName}") //获取资源文件属性参数;配置在变量上
@ConfigurationProperties(prefix = “jdbc”) //资源读取application.properties中的jdbc相关配置;作用在类上通过set,get方法配置;作用在方法上直接注入属性
@EnableConfigurationProperties(公共资源读取类名.class) //配合上边注解,启用公共读取类,以便@Autowired注入
@Transactional //添加事务注解
@ModelAttribute //该Controller的所有方法在调用前,先执行@ModeAttribute方法,可用于注解和方法参数中,可把这个@ModelAttribute特性应用在BaseController中,所有Controller继承BaseController,即可实现在调用Controller,先执行@ModelAttribute方法
@SessionAttributes //将值放到session作用域中,写在class上面
@CookieValue //用来获取Cookie中的值
Spring事物实现方式
(1)编程式事务管理对基于 POJO 的应用来说是唯一选择。我们需要在代码中调用beginTransaction()、commit()、rollback()等事务管理相关的方法,这就是编程式事务管理。
(2)基于 TransactionProxyFactoryBean的声明式事务管理
(3)基于 @Transactional 的声明式事务管理(参数可配以下传播行为progation默认为required;isolation默认为default)
(4)基于Aspectj AOP配置事务
Spring传播行为
属性
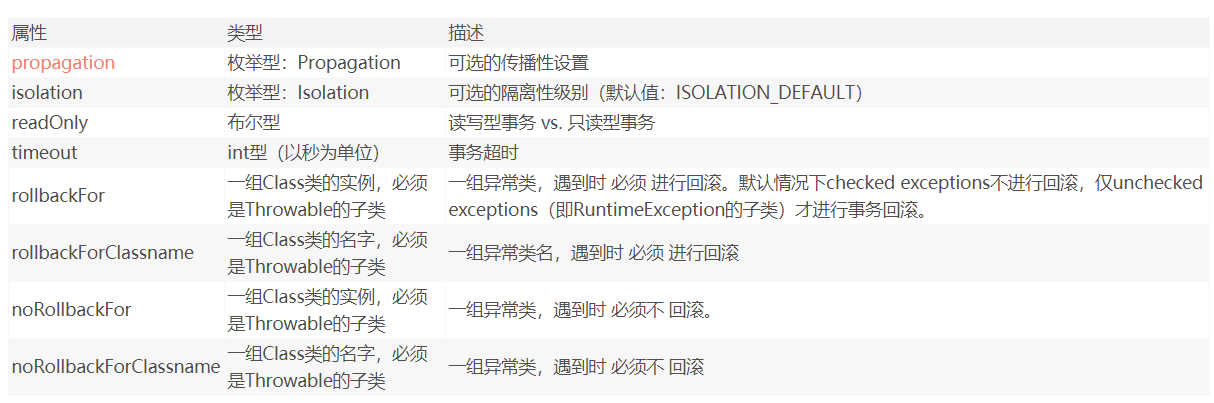

Spring隔离级别
丢失更新:
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,会发生丢失更新问题。每个事务都不知道其它事务的存在。最后的更新将重写由其它事务所做的更新,这将导致数据丢失。
解决办法:对行加锁,只允许并发一个更新事务。
事务1:对一数据修改
事务2:对这一数据修改
2把1顶了
脏读:
一个事务读到另一个事务未提交的更新数据
事务1:更新一条数据
------------->事务2:读取事务1更新的记录
事务1:调用commit进行提交
事务2读取到的数据是事务一尚未提交的数据,称为脏读
不可重复读:
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
事务1:查询一条记录(未结束)
-------------->事务2:更新事务1查询的记录
-------------->事务2:调用commit进行提交
事务1:再次查询上次的记录
幻读:
一个事务读取到另一个事务已提交的insert数据.
事务1:查询表中所有记录
-------------->事务2:插入一条记录
-------------->事务2:调用commit进行提交
事务1:再次查询表中所有记录

分布式事务
分布式事务(Distributed Transaction)包括事务管理器( Transaction Manager ) 和一个或多个支持 XA 协议的资源管理器 ( Resource Manager )。我们可以将资源管理器看做任意类型的持久化数据存储;事务管理器承担着所有事务参与单元的协调与控制。
两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做,所谓的两个阶段是指:第一阶段:准备阶段;第二阶段:提交阶段。
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CpR96qfX-1620630936775)(C:%5CUsers%5CLenovo%5CAppData%5CLocal%5CTemp%5Cksohtml14588%5Cwps1.png)] |
1 准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送 Prepare 消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的 redo 和 undo 日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
2 提交阶段:
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则, 发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过 程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
将提交分成两阶段进行的目的很明确,就是尽可能晚地提交事务,让事务在提交前尽可能地完成所有能完成的工作。
SpringMVC
MVC流程
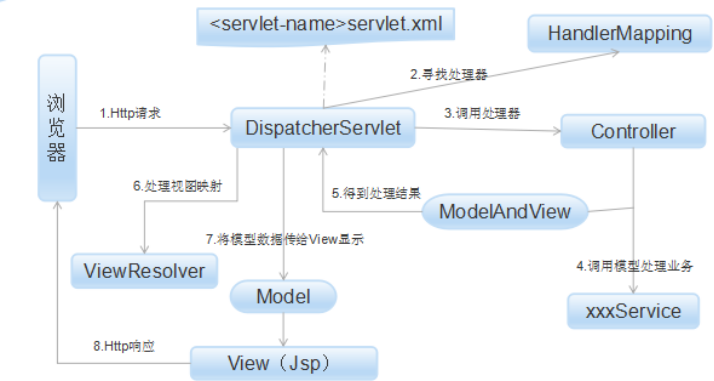
(1) 客户端请求提交到 DispatcherServlet。
(2) 由 DispatcherServlet 控制器查询一个或多个 HandlerMapping,找到处理请求的Controller–(寻找处理器)
(3)DispatcherServlet 将请求提交到Controller–(调用处理器)
(4)Controller 调用业务逻辑处理后,返回 ModelAndView。
(5) DispatcherServlet 查询一个或多个 ViewResolver视图解析器, 找到 ModelAndView 指定的视图。
(6)视图负责将结果显示到客户端。
SpringMVC有哪些组件
前端控制器(DispatcherServlet)
处理器映射器(HandlerMapping)
处理器适配器(HandlerAdapter)
拦截器(HandlerInterceptor)
语言环境处理器(LocaleResolver)
主题解析器(ThemeResolver)
视图解析器(ViewResolver)
文件上传处理器(MultipartResolver)
异常处理器(HandlerExceptionResolver)
数据转换(DataBinder)
消息转换器(HttpMessageConverter)
请求转视图翻译器(RequestToViewNameTranslator)
页面跳转参数管理器(FlashMapManager)
处理程序执行链(HandlerExecutionChain)
参数绑定
https://www.cnblogs.com/ysocean/p/7425861.html
Mybatis
核心组件
1)SqlSessionFactoryBuilder(构造器):它会根据配置或者代码来生成 SqlSessionFactory,采用的是分步构建的 Builder 模式。
2)SqlSessionFactory(工厂接口):依靠它来生成 SqlSession,使用的是工厂模式。
3)SqlSession(会话):一个既可以发送 SQL 执行返回结果,也可以获取 Mapper 的接口。在现有的技术中,一般我们会让其在业务逻辑代码中“消失”,而使用的是 MyBatis 提供的 SQL Mapper 接口编程技术,它能提高代码的可读性和可维护性。
4)SQL Mapper(映射器):MyBatis 新设计存在的组件,它由一个 Java 接口和 XML 文件(或注解)构成,需要给出对应的 SQL 和映射规则。它负责发送 SQL 去执行,并返回结果。
初始化机制
- 基于XML配置文件:基于XML配置文件的方式是将MyBatis的所有配置信息放在XML文件中,MyBatis通过加载并XML配置文件,将配置文信息组装成内部的Configuration对象
- 基于Java API:这种方式不使用XML配置文件,需要MyBatis使用者在Java代码中,手动创建Configuration对象,然后将配置参数set 进入Configuration对象中
根据配置文件mybatis-config.xml 配置文件事务管理器,数据源,数据库连接信息,全局属性,mapper等,创建SqlSessionFactory对象,然后产生SqlSession,执行SQL语句。而mybatis的初始化就发生在第三句:SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); 现在就让我们看看第三句到底发生了什么。
Mybatis缓存
一级缓存(sqlsession)
第一次发出一个查询 sql,sql 查询结果写入 sqlsession 的一级缓存中,缓存使用的数据结构是一个 map。
key:MapperID+offset+limit+Sql+所有的入参
value:用户信息
同一个 sqlsession 再次发出相同的 sql,就从缓存中取出数据。如果两次中间出现 commit 操作(修改、添加、删除),本 sqlsession 中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
注:一级缓存最多缓存1024条信息
二级缓存(mapper)
二级缓存的范围是mapper 级别(mapper 同一个命名空间),mapper 以命名空间为单位创建缓存数据结构,结构是map。mybatis 的二级缓存是通过 CacheExecutor 实现的。CacheExecutor
其实是 Executor 的代理对象。所有的查询操作,在 CacheExecutor 中都会先匹配缓存中是否存在,不存在则查询数据库。
key:MapperID+offset+limit+Sql+所有的入参
具体使用需要配置:
\1. Mybatis 全局配置中启用二级缓存配置
<settingname = "cacheEnabled" value = "true"></setting>
\2. 在对应的 Mapper.xml 中配置 cache 节点
\3. 在对应的select 查询节点中添加 useCache=true
select,insert,update,delete
select
元素常用属性
| 属性名称 | 描 述 |
|---|---|
| id | 它和 Mapper 的命名空间组合起来使用,是唯一标识符,供 MyBatis 调用 |
| parameterType | 表示传入 SQL 语句的参数类型的全限定名或别名。它是一个可选属性,MyBatis 能推断出具体传入语句的参数 |
| resultType | SQL 语句执行后返回的类型(全限定名或者别名)。如果是集合类型,返回的是集合元素的类型,返回时可以使用 resultType 或 resultMap 之一 |
| resultMap | 它是映射集的引用,与 元素一起使用,返回时可以使用 resultType 或 resultMap 之一 |
| flushCache | 用于设置在调用 SQL 语句后是否要求 MyBatis 清空之前查询的本地缓存和二级缓存,默认值为 false,如果设置为 true,则任何时候只要 SQL 语句被调用都将清空本地缓存和二级缓存 |
| useCache | 启动二级缓存的开关,默认值为 true,表示将査询结果存入二级缓存中 |
| timeout | 用于设置超时参数,单位是秒(s),超时将抛出异常 |
| fetchSize | 获取记录的总条数设定 |
| statementType | 告诉 MyBatis 使用哪个 JDBC 的 Statement 工作,取值为 STATEMENT(Statement)、 PREPARED(PreparedStatement)、CALLABLE(CallableStatement) |
| resultSetType | 这是针对 JDBC 的 ResultSet 接口而言,其值可设置为 FORWARD_ONLY(只允许向前访问)、SCROLL_SENSITIVE(双向滚动,但不及时更新)、SCROLLJNSENSITIVE(双向滚动,及时更新) |
使用 Map 接口传递多个参数
Dao:
public List<MyUser> selectAllUser(Map<String,Object> param);
--------------------------------------------
Mapper:
<!-- 查询陈姓男性用户信息 -->
<select id="selectAllUser" resultType="com.mybatis.po.MyUser">
select * from user
where uname like concat('%',#{u_name},'%')
and usex = #{u_sex}
</select>
//参数名 u_name 和 u_sex 是 Map 的 key
----------------------------------------------
Controller:
@Controller("UserController")
public class UserController {
private UserDao userDao;
public void test(){
...
//查询多个用户
Map<String,Object> map = new HashMap<>();
map.put("u_name","陈");
map.put("u_sex","男");
List<MyUser> list = userDao.seleceAllUser(map);
for(MyUser myUser : list) {
System.out.println(myUser);
}
...
}
}
使用 Java Bean 传递多个参数
pojo:
public class SeletUserParam {
private String u_name;
private String u_sex;
// 此处省略setter和getter方法
}
--------------------------------------------
Dao:
public List<MyUser> selectAllUser(SelectUserParam param);
-------------------------------------------------
Mapper:
<select id="selectAllUser" resultType="com.po.MyUser" parameterType="com.pojo.SeletUserParam">
select * from user
where uname like concat('%',#{u_name},'%')
and usex=#{u_sex}
</select>
--------------------------------------------------
Controller:
SeletUserParam su = new SelectUserParam();
su.setU_name("陈");
su.setU_sex("男");
List<MyUser> list = userDao.selectAllUser(su);
for (MyUser myUser : list) {
System.out.println(myUser);
}
注意:如果参数较少,建议选择 Map;如果参数较多,建议选择 Java Bean。
insert
属性
- keyProperty:该属性的作用是将插入或更新操作时的返回值赋给 PO 类的某个属性,通常会设置为主键对应的属性。如果是联合主键,可以将多个值用逗号隔开。
- keyColumn:该属性用于设置第几列是主键,当主键列不是表中的第 1 列时需要设置。如果是联合主键,可以将多个值用逗号隔开。
- useGeneratedKeys:该属性将使 MyBatis 使用 JDBC 的 getGeneratedKeys()方法获取由数据库内部产生的主键,例如 MySQL、SQL Server 等自动递增的字段,其默认值为 false。
//主键(自动递增)回填
Mapper:
<!--添加一个用户,成功后将主键值返回填给uid(po的属性)-->
<insert id="addUser" parameterType="com.po.MyUser" keyProperty="uid" useGeneratedKeys="true">
insert into user (uname,usex) values(#{uname},#{usex})
</insert>
-------------------------------------------------
Controller:
// 添加一个用户
MyUser addmu = new MyUser();
addmu.setUname("陈恒");
addmu.setUsex("男");
int add = userDao.addUser(addmu);
System.out.println("添加了" + add + "条记录");
System.out.println("添加记录的主键是" + addmu.getUid());
//自定义主键(例如oracle不支持主键自动递增)
<!-- 添加一个用户,#{uname}为 com.mybatis.po.MyUser 的属性值 -->
<insert id="insertUser" parameterType="com.po.MyUser">
<!-- 先使用selectKey元素定义主键,然后再定义SQL语句 -->
<selectKey keyProperty="uid" resultType="Integer" order="BEFORE">
select if(max(uid) is null,1,max(uid)+1) as newUid from user)
</selectKey>
insert into user (uid,uname,usex) values(#{uid},#{uname},#{usex})
</insert>
update
<!-- 修改一个用户 -->
<update id="updateUser" parameterType="com.po.MyUser">
update user set uname = #{uname},usex = #{usex} where uid = #{uid}
</update>
delete
<!-- 删除一个用户 -->
<delete id="deleteUser" parameterType="Integer">
delete from user where uid = #{uid}
</delete>
sql标签
元素的作用在于可以定义 SQL 语句的一部分(代码片段),以方便后面的 SQL 语句引用它,例如反复使用的列名。
<sql id="comColumns">id,uname,usex</sql>
<select id="selectUser" resultType="com.po.MyUser">
select <include refid="comColumns"> from user
</select>
resultMap和resultType区别
resultMap:是一个复杂结果集,可以返回一对多或多对多的数据
resultType:是可以找的到的一个参数类型(),数据类型引用类型,实体类都可
<resultMap id="" type="">
<constructor><!-- 类再实例化时用来注入结果到构造方法 -->
<idArg/><!-- ID参数,结果为ID -->
<arg/><!-- 注入到构造方法的一个普通结果 -->
</constructor>
<id/><!-- 用于表示哪个列是主键 -->
<result/><!-- 注入到字段或JavaBean属性的普通结果 -->
<association property=""/><!-- 用于一对一关联 -->
<collection property=""/><!-- 用于一对多、多对多关联 -->
<discriminator javaType=""><!-- 使用结果值来决定使用哪个结果映射 -->
<case value=""/><!-- 基于某些值的结果映射 -->
</discriminator>
</resultMap>
一对一关联查询
元素中通常使用以下属性。
- property:指定映射到实体类的对象属性。
- column:指定表中对应的字段(即查询返回的列名)。
- javaType:指定映射到实体对象属性的类型。
- select:指定引入嵌套查询的子 SQL 语句,该属性用于关联映射中的嵌套查询。
实体类:
public class Idcard {
private Integer id;
private String code;
// 省略setter和getter方法
}
public class Person {
private Integer id;
private String name;
private Integer age;
// 个人身份证关联
private Idcard card;
}
-------------------------------------------
mapper:
<mapper namespace="com.dao.PersonDao">
<!-- 一对一根据id查询个人信息:级联查询的第一种方法(嵌套查询,执行两个SQL语句)-->
<resultMap type="com.po.Person" id="cardAndPerson1">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<!-- 一对一级联查询-->
<association property="card" column="idcard_id" javaType="com.po.Idcard"
select="com.dao.IdCardDao.selectCodeByld"/>
</resultMap>
<select id="selectPersonById1" parameterType="Integer" resultMap=
"cardAndPerson1">
select * from person where id=#{id}
</select>
<!--对一根据id查询个人信息:级联查询的第二种方法(嵌套结果,执行一个SQL语句)-->
<resultMap type="com.po.Person" id="cardAndPerson2">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<!-- 一对一级联查询-->
<association property="card" javaType="com.po.Idcard">
<id property="id" column="idcard_id"/>
<result property="code" column="code"/>
</association>
</resultMap>
<select id="selectPersonById2" parameterType="Integer" resultMap= "cardAndPerson2">
select p.*,ic.code
from person p, idcard ic
where p.idcard_id=ic.id and p.id=#{id}
</select>
</mapper>
一对多关联查询
实体类:
需在用户类中添加订单list属性与mapper中rensultMap映射
// 一对多级联查询,用户关联的订单
private List<Orders> ordersList;
-------------------------------------------------
<mapper namespace="com.mybatis.mapper.UserMapper">
<!-- 一对多 根据uid查询用户及其关联的订单信息:级联查询的第一种方法(嵌套查询) -->
<resultMap type="com.po.MyUser" id="userAndOrders1">
<id property="uid" column="uid" />
<result property="uname" column="uname" />
<result property="usex" column="usex" />
<!-- 一对多级联查询,ofType表示集合中的元素类型,将uid传递给selectOrdersByld -->
<collection property="ordersList" ofType="com.po.Orders"
column="uid" select="com.dao.OrdersDao.selectOrdersByld" />
</resultMap>
<select id="selectUserOrdersById1" parameterType="Integer"
resultMap="userAndOrders1">
select * from user where uid = #{id}
</select>
<!--对多根据uid查询用户及其关联的订单信息:级联查询的第二种方法(嵌套结果) -->
<resultMap type="com.po.MyUser" id="userAndOrders2">
<id property="uid" column="uid" />
<result property="uname" column="uname" />
<result property="usex" column="usex" />
<!-- 对多级联查询,ofType表示集合中的元素类型 -->
<collection property="ordersList" ofType="com.po.Orders">
<id property="id" column="id" />
<result property="ordersn" column="ordersn" />
</collection>
</resultMap>
<select id="selectUserOrdersById2" parameterType="Integer"
resultMap="userAndOrders2">
select u.*,o.id, o.ordersn from user u, orders o where u.uid
= o.user_id and
u.uid=#{id}
</select>
</mapper>
多对多关联查询
与一对多类似,区别在于多了一张两表的关联关系表
public class Product {
private Integer id;
private String name;
private Double price;
// 多对多中的一个一对多
private List<Orders> orders;
// 省略setter和getter方法
}
public class Orders {
private Integer id;
private String ordersn;
// 多对多中的另一个一对多
private List<Product> products;
// 省略setter和getter方法
}
懒加载及原理
顾名思义,懒加载就是因为偷懒了,懒得加载了,只有使用的时候才进行加载。我们在用Mybatis进行一对多的时候,先查询出一方,当程序需要多方数据时,mybatis会再次发出sql语句进行查询,减轻了对我们数据库的压力。Mybatis的延迟加载,只对关联对象有延迟设置。
只对association和collection关联对象开放延迟加载。
加载时机
- 直接加载:执行完对主加载对象的 select 语句,马上执行对关联对象的 select 查询。
- 侵入式延迟: 执行对主加载对象的查询时,不会执行对关联对象的查询。但当要访问主加载对象的详情属性时,就会马上执行关联对象的select查询。
<!--全局参数设置-->
<settings>
<!--延迟加载总开关-->
<setting name="lazyLoadingEnabled" value="true"/>
<!--侵入式延迟加载开关-->
<!--3.4.1版本之前默认是true,之后默认是false-->
<setting name="aggressiveLazyLoading" value="true"/>
</settings>
- 深度延迟: 执行对主加载对象的查询时,不会执行对关联对象的查询。访问主加载对象的详情时也不会执行关联对象的select查询。只有当真正访问关联对象的详情时,才会执行对关联对象的 select 查询。
上面都是通过在mybatis.xml文件中统一配置的深度延迟加载,倘若只希望某些查询支持深度延迟加载的话可以在resultMap中的collection或association添加fetchType属性,配置为lazy之后是开启深度延迟,配置eager是不开启深度延迟。fetchType属性将取代全局配置参数lazyLoadingEnabled的设置
原理:
使用CGLIB为目标对象建立代理对象,当调用目标对象的方法时进入拦截器方法。比如调用a.getb().getName(),拦截器方法invoke()发现a.getb()为null值,会单独发送事先保存好的查询关联b对象的sql语句,把b查询上来然后调用a.setB(b),于是a的对象的属性b就有值了,然后接着调用a.getb().getName(),这就是延迟加载的原理。
#{}和${}的区别
#{}是预编译处理,${}是字符串替换。
(1)mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
(2)mybatis在处理 时 , 就 是 把 {}时,就是把 时,就是把{}替换成变量的值。
(3)使用#{}可以有效的防止SQL注入,提高系统安全性。预编译是提前对SQL语句进行预编译,而其后注入的参数将不会再进行SQL编译。我们知道,SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作。而预编译机制则可以很好的防止SQL注入。
分页
1.数组分页
2.sql分页
3.拦截器分页最为典型的PageHelper分页插件
properties配置文件
#分页插件
pagehelper.helper-dialect=mysql
pagehelper.params=count=countSql
pagehelper.reasonable=true
pagehelper.support-methods-arguments=true
---------------------------------------------
Controller
@Controller
public class PersonController {
@Autowired
private PersonService personService;
@GetMapping("/getAllPerson")
public String getAllPerson(Model model,@RequestParam(defaultValue = "1",value = "pageNum") Integer pageNum){
PageHelper.startPage(pageNum,5);
List<Person> list = personService.getAllPerson();
PageInfo<Person> pageInfo = new PageInfo<Person>(list);
model.addAttribute("pageInfo",pageInfo);
return "list";
}
---------------------------------------------------------
Json格式
@RequestMapping("/getGatewayList")
@ResponseBody
public List<PageInfo> getGatewayList(Model model,GatewayInfo gatewayInfo, @RequestParam(defaultValue = "1", value = "pageNum") Integer pageNum,
@RequestParam(defaultValue = "5") int pageSize) {
try {
PageHelper.startPage(pageNum, pageSize);
PageInfo pageInfo=new PageInfo(gmpGatewayService.selectGatewayAll());
logger.info("列表信息 |数据| "+JSON.toJSONString(pageInfo.getList()));
logger.info("分页数量: "+pageInfo.getNextPage());
logger.info("分页总数: "+pageInfo.getPageNum());
logger.info("分页总数: "+pageInfo.getPageSize());
//直接返回json字符串
return pageInfo.getList();
} catch (Exception e) {
logger.error("信息 | 查询 | error ");
return null;
前端
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div align="center">
<table border="1">
<tr>
<th>id</th>
<th>name</th>
<th>sex</th>
<th>age</th>
</tr>
<tr th:each="person:${pageInfo.list}">
<td th:text="${person.id}"></td>
<td th:text="${person.name}"></td>
<td th:text="${person.sex}"></td>
<td th:text="${person.age}"></td>
</tr>
</table>
<p>当前 <span th:text="${pageInfo.pageNum}"></span> 页,总 <span th:text="${pageInfo.pages}"></span> 页,共 <span th:text="${pageInfo.total}"></span> 条记录</p>
<a th:href="@{/getAllPerson}">首页</a>
<a th:href="@{/getAllPerson(pageNum=${pageInfo.hasPreviousPage}?${pageInfo.prePage}:1)}">上一页</a>
<a th:href="@{/getAllPerson(pageNum=${pageInfo.hasNextPage}?${pageInfo.nextPage}:${pageInfo.pages})}">下一页</a>
<a th:href="@{/getAllPerson(pageNum=${pageInfo.pages})}">尾页</a>
</div>
</body>
4.RowBounds分页
Mybatis主键id回显
使用<insert 中的useGeneratedKeys 和 keyProperty 两个属性
1.在Mybatis Mapper文件中添加属性 “useGeneratedKeys”和“keyProperty”,其中 keyProperty 是 Java 对象的属性名,而不是表格的字段名。
<insert id="insert" parameterType="Spares"
useGeneratedKeys="true" keyProperty="id">
insert into system(name) values(#{name})
</insert>
2.Mybatis 执行完插入语句后,自动将自增长值赋值给对象 systemBean 的属性id。因此,可通过 systemBean 对应的 getter 方法获取!
int count = systemService.insert(systemBean);
int id = systemBean.getId(); //获取到的即为新插入记录的ID
【注意事项】
1.Mybatis Mapper 文件中,“useGeneratedKeys” 和 “keyProperty” 必须添加,而且 keyProperty 一定得和 java 对象的属性名称一直,而不是表格的字段名。
2.java Dao中的 Insert 方法,传递的参数必须为 java 对象,也就是 Bean,而不能是某个参数。
批量插入
- 反复执行单条插入语句
- xml拼接sql
- 批处理执行
@Service
public class ItemService {
@Autowired
private ItemMapper itemMapper;
@Autowired
private SqlSessionFactory sqlSessionFactory;
//批处理
@Transactional
public void add(List<Item> itemList) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH,false);
ItemMapper mapper = session.getMapper(ItemMapper.class);
for (int i = 0; i < itemList.size(); i++) {
mapper.insertSelective(itemList.get(i));
if(i%1000==999){//每1000条提交一次防止内存溢出
session.commit();
session.clearCache();
}
}
session.commit();
session.clearCache();
}
//拼接sql
@Transactional
public void add1(List<Item> itemList) {
itemList.insertByBatch(itemMapper::insertSelective);
}
//循环插入
@Transactional
public void add2(List<Item> itemList) {
itemList.forEach(itemMapper::insertSelective);
}
}
循环插入单条数据虽然效率极低,但是代码量极少,在使用tk.Mapper的插件情况下,在需求插入数据数量不多的情况下肯定用它了。
批处理执行是有大数据量插入时推荐的做法,使用起来也比较方便。
SpringBoot
核心功能特点
1)独立运行的 Spring 项目
Spring Boot 可以以 jar 包的形式独立运行,运行一个 Spring Boot 项目只需通过 java–jar xx.jar 来运行。
2)内嵌 Servlet 容器
Spring Boot 可选择内嵌 Tomcat、Jetty 或者 Undertow,这样我们无须以 war 包形式部署项目。
3)提供 starter 简化 Maven 配置
Spring 提供了一系列的 starter pom 来简化 Maven 的依赖加载,例如,当你使用了spring-boot-starter-web 时,会自动加入依赖包。
4)自动配置 Spring
Spring Boot 会根据在类路径中的 jar 包、类,为 jar 包里的类自动配置 Bean,这样会极大地减少我们要使用的配置。当然,Spring Boot 只是考虑了大多数的开发场景,并不是所有的场景,若在实际开发中我们需要自动配置 Bean,而 Spring Boot 没有提供支持,则可以自定义自动配置。
5)准生产的应用监控
Spring Boot 提供基于 http、ssh、telnet 对运行时的项目进行监控。
6)无代码生成和 xml 配置
Spring Boot 的神奇的不是借助于代码生成来实现的,而是通过条件注解来实现的,这是 Spring 4.x 提供的新特性。Spring 4.x 提倡使用 Java 配置和注解配置组合,而 Spring Boot 不需要任何 xml 配置即可实现 Spring 的所有配置。
属性注入(配置文件属性)
1.@Autowired注入
@Autowired
private JdbcProperties jdbcProperties;
2.构造方法注入
private JdbcProperties jdbcProperties;
public JdbcConfiguration(JdbcProperties jdbcProperties){
this.jdbcProperties = jdbcProperties;
}
3.@Bean方法形参注入
@Bean
pulbic DataSource dataSource(JdbcProperties jdbcProperties){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(jdbcProperties.getDriverClassName);
.....
return dataSource;
}
4.@直接在@Bean方法@ConfigurationProperties(prefix = “jdbc”)
@Bean
@ConfigurationProperties(prefix = "jdbc")
pulbic DataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
return dataSource;
}
启动依赖
1.实例化SpringApplication对象,然后调用其run方法。在这之前
根据 classpath判断web类型(带REACTIVE是反应式web应用,无阻塞应用:后端将改变数据不断的推送到客户端,而不是传统的WEB应用将后端数据获得后发送给客户端显示)创建相应的ApplicationContext
SpringFactoriesLoader 在应用的 classpath 中查找并加载所有可用的 ApplicationContextInitializer。
SpringFactoriesLoader 在应用的 classpath 中查找并加载所有可用的 ApplicationListener。
推断并设置main方法定义类
2.实例初始化后,开始执行run方法逻辑启动SpringApplicationRunListeners监听,通知应用要开始执行了
3.创建并配置当前 SpringBoot 应用将要使用的 Environment(PropertySource 以及 Profile)调用SpringApplicationRunListeners监听器environmentPrepared()的方法,通知应用环境准备就绪
4.初始化Banner打印实例
5.根据webApplicationType类型进行反射实例化ApplicationContext上下文实例,决定是否使用自定义的 BeanNameGenerator,决定是否使用自定义的 ResourceLoader,将之前准备好的 Environment 设置给创建好的 ApplicationContext 使用
6.遍历调用这些 ApplicationContextInitializer 的 initialize(applicationContext)方法来对已经创建好的 ApplicationContext 进行进一步的处理。
7.SpringApplicationRunListener 的 contextPrepared()方法通知应用context准备就绪
8.将之前通过 @EnableAutoConfiguration 获取的所有配置以及其他形式的 IoC 容器配置加载到已经准备完毕的 ApplicationContext。
9.SpringApplicationRunListener 的 contextLoaded() 方法,通知ApplicationContext 装填完成。
10.调用 ApplicationContext 的 refresh() 方法并决定是否注册关闭任务
自动配置
@SpringbootAppliation注解通过@AlisaFor(用于为注解属性声明别名注解)将@EnableAutoConfiguration(自配置注解),@ComponentScan(扫描主类所在的同级包以及下级包里的Bean注解)组合起来形复合注解。自动配置主要体现在@EnableAutoConfiguration这个注解它借助了EnableAutoConfigurationImportSelector将所有符合条件的@Configuration配置都加载到当前SpringBoot创建并使用的IoC容器,其中getCandidateConfigurations方法得到所需待自动配置的class的类名集合,配置信息就存在于META-INF/spring.factories文件中。

mybatis-spring-boot-starter、spring-boot-starter-web等组件的META-INF文件下均含有spring.factories文件,自动配置模块中,SpringFactoriesLoader收集到文件中的类全名并返回一个类全名的数组,返回的类全名通过反射被实例化,就形成了具体的工厂实例,工厂实例来生成组件具体需要的bean。
https://blog.csdn.net/zjcjava/article/details/84028222
静态资源
WebProperties(定义了资源存放路径)
"classpath:/META-INF/resources/",
"classpath:/resources/",
"classpath:/static/",
"classpath:/public/"
部署方式(jar,war)
jar:
1.pom.xmljar
2.切到项目目录cmd运行 mvn install打出jar包
3.java -jar target/springboot-0.0.1-SNAPSHOT.jar即可运行项目
war:
1.Application新加@ServletComponentScan注解,并且继承SpringBootServletInitializer
2.pom.xml文件war;spring-boot-starter-tomcat修改为 provided方式,以避免和独立 tomcat 容器的冲突. mvn clean package表示provided 只在编译和测试的时候使用
3.切到项目目录cmd运行 mvn clean package打出war包
4.springboot-0.0.1-SNAPSHOT.war 这个文件名部署,那么访问的时候就要在路径上加上springboot-0.0.1-SNAPSHOT。 所以把这个文件重命名为 ROOT.war,然后把它放进tomcat 的webapps目录下,访问直接用/hello,root表示根路径
热部署
1.添加spring-loaded依赖
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional> <!-- 这个需要为 true 热部署才有效 -->
</dependency>
插件:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
端口和上下文路径
修改application.properties
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp
server.port=8888
server.context-path=/test
核心配置文件
- bootstrap (.yml 或者 .properties)
- application (.yml 或者 .properties)
*.properties 文件是 key=value 的形式
*.yml 是 key: value 的形式
*.yml 加载的属性是有顺序的,但不支持 @PropertySource 注解来导入配置
bootstrap/ application 的应用场景
application 配置文件这个容易理解,主要用于 Spring Boot 项目的自动化配置。
bootstrap 配置文件有以下几个应用场景。
- 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性
- 一些加密/解密的场景;
多配置文件
3个配置文件:
核心配置文件:application.properties
开发环境用的配置文件:application-dev.properties
生产环境用的配置文件:application-pro.properties
这样就可以通过application.properties里的spring.profiles.active 灵活地来切换使用哪个环境了
application.properties
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp
spring.profiles.active=pro
application-dev.properties
server.port=8080
server.context-path=/test
application-pro.properties
server.port=80
server.context-path=/
部署的话
java -jar target/springboot-0.0.1-SNAPSHOT.jar --spring.profiles.active=pro
或者
java -jar target/springboot-0.0.1-SNAPSHOT.jar --spring.profiles.active=dev
yml与properties
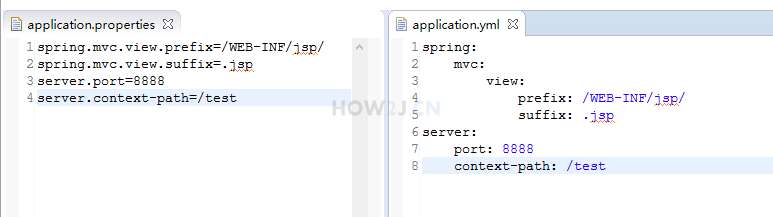
SpringCloud
Spring Cloud是一个微服务框架的规范,注意,只是规范,他不是任何具体的框架。
架构转变
1.集中式架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是影响项目开发的关键。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8AoURIm6-1620630936778)(https://i.loli.net/2021/03/12/pBWwdSOtoV3AqiQ.png)]
存在的问题:
- 代码耦合,开发维护困难
- 无法针对不同模块进行针对性优化
- 无法水平扩展
- 单点容错率低,并发能力差
2.垂直拆分
当访问量逐渐增大,单一应用无法满足需求,此时为了应对更高的并发和业务需求,我们根据业务功能对系统进行拆分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qJaxGE6W-1620630936779)(https://i.loli.net/2021/03/12/khQbtPYFwpKjEmL.png)]
优点:
- 系统拆分实现了流量分担,解决了并发问题
- 可以针对不同模块进行优化
- 方便水平扩展,负载均衡,容错率提高
缺点:
- 系统间相互独立,会有很多重复开发工作,影响开发效率
3.分布式服务
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式调用是关键。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hAABccqp-1620630936780)(https://i.loli.net/2021/03/12/zphjZcV8a2I5GwF.png)]
优点:
- 将基础服务进行了抽取,系统间相互调用,提高了代码复用和开发效率
缺点:
- 系统间耦合度变高,调用关系错综复杂,难以维护
4.流动计算架构(SOA面向服务)
SOA :面向服务的架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-faH2rRI2-1620630936781)(https://i.loli.net/2021/03/12/VyjDRSIAQgWptK5.png)]
以前出现了什么问题?
- 服务越来越多,需要管理每个服务的地址
- 调用关系错综复杂,难以理清依赖关系
- 服务过多,服务状态难以管理,无法根据服务情况动态管理
服务治理要做什么?
- 服务注册中心,实现服务自动注册和发现,无需人为记录服务地址
- 服务自动订阅,服务列表自动推送,服务调用透明化,无需关心依赖关系
- 动态监控服务状态监控报告,人为控制服务状态
缺点:
- 服务间会有依赖关系,一旦某个环节出错会影响较大
- 服务关系复杂,运维、测试部署困难,不符合DevOps思想
5.微服务
微服务是一种架构模式,叫微服务架构更合理,就是把一个系统中的各个功能点都拆开为一个个的小应用然后单独部署,同时因为这些小应用多,所以需要一些办法来管理这些小应用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GqTFt3dc-1620630936781)(https://i.loli.net/2021/03/12/eluryS9LsnmxOVf.png)]
特点:
1.单一职责:
微服务中每一个服务都对应唯一的业务能力,做到单一职责
2.微:
微服务的服务拆分粒度很小,例如一个用户管理就可为一个服务
3.面向服务:
每个服务都要对外暴露Rest风格服务接口API,不关心服务技术的实现,做到平台和语言无关,也不限定用什么技术实现,只提供Rest接口即可
4.自治:
服务间互相独立,互不干扰
- 团队独立:每个服务都是一个独立的开发团队,人数不能过多
- 技术独立:面向服务提供Rest接口,使用什么技术没人干涉
- 前后端分离:采用前后端分离开发,提供统一Rest接口,后端不再为PC、移动端开发不同接口
- 数据库分离:每个服务都有自己的数据源
- 部署独立,服务间虽有调用,但做到服务重启不影响其他服务。有利于持续集成和持续交付。每个服务都是独立的组件,可复用,可替换,降低耦合,易维护
RPC和HTTP
无论是微服务还是SOA,都面临着服务间的远程调用。那么服务间的远程调用方式有哪些呢?
常见的远程调用方式有以下2种:
-
RPC:Remote Produce Call远程过程调用,类似的还有RMI。自定义数据格式,基于原生TCP通信,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型代表
-
Http:http其实是一种网络传输协议,基于TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议,也可以用来进行远程服务调用。缺点是消息封装臃肿,优势是对服务的提供和调用方没有任何技术限定,自由灵活,更符合微服务理念。
现在热门的Rest风格,就可以通过http协议来实现。
RestTemplate
Spring提供了一个RestTemplate模板工具类,对基于Http的客户端进行了封装,并且实现了对象与json的序列化和反序列化,非常方便。RestTemplate并没有限定Http的客户端类型,而是进行了抽象,目前常用的3种都有支持:
- HttpClient
- OkHttp
- JDK原生的URLConnection(默认的)
首先在项目中注册一个RestTemplate对象,可以在启动类位置注册:
@SpringBootApplication
public class HttpDemoApplication {
public static void main(String[] args) {
SpringApplication.run(HttpDemoApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
在测试类中直接@Autowired注入:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = HttpDemoApplication.class)
public class HttpDemoApplicationTests {
@Autowired
private RestTemplate restTemplate;
@Test
public void httpGet() {
// 调用springboot案例中的rest接口
User user = this.restTemplate.getForObject("http://localhost/user/1", User.class);
System.out.println(user);
}
}
- 通过RestTemplate的getForObject()方法,传递url地址及实体类的字节码,RestTemplate会自动发起请求,接收响应,并且帮我们对响应结果进行反序列化。
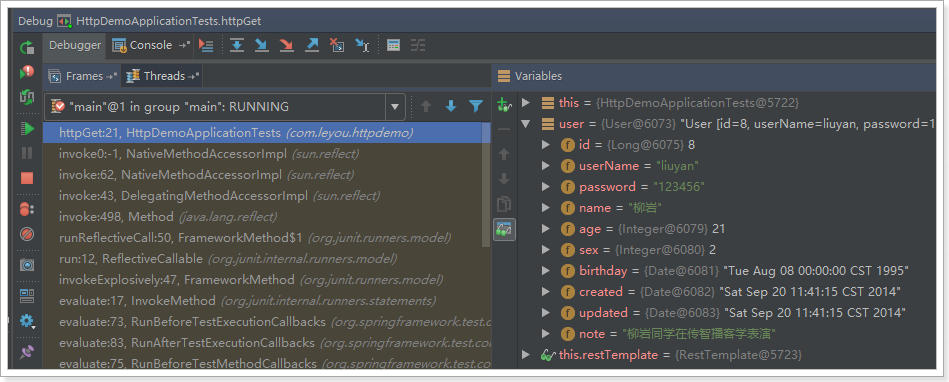
Spring Cloud Netflix组件
1.eureka (提供服务注册与发现功能)
2.ribbon(提供负载均衡功能)
3.Feign(整合了ribbon和Hystrix,具有负载均衡和熔断限流等功能)
4.Hystrix (提供了熔断限流,合并请求等功能)
5.Zuul (提供了智能路由的功能)
6.Hystrix Dashboard (提供了服务监控的功能,提供了数据监控和友好的图形化界面)
7.Hystrix Turbine (Hystrix Turbine将每个服务Hystrix Dashboard数据进行了整合。也是监控系统的功能)
8.spring cloud config (提供了统一配置的功能)
9.Spring Cloud Bus (提供了配置实时更新的功能)
Eureka(服务注册与发现)
1.高可用
eureka;互相注册;@EnableEurekaServer(开启eureka服务启动类添加)
server:
port: 10087
eureka:
client:
service-url: # EurekaServer的地址,现在是自己的地址,如果是集群,需要加上其它Server的地址。
defaultZone: http://127.0.0.1:10086/eureka
2.心跳过期 (服务提供方)
@EnableDiscoveryClient(发现服务同下)
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka,http://127.0.0.1:10087/eureka
register-with-eureka: true #注册eureka服务
instance:
lease-expiration-duration-in-seconds: 90 #服务失效时间90s,失效
lease-renewal-interval-in-seconds: 30 #服务续约间隔30s
3.拉取服务的间隔时间 (服务消费方)
@EnableDiscoveryClient
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka,http://127.0.0.1:10087/eureka
registry-fetch-interval-seconds: 5 #没隔5秒重新获取并更新数据
fetch-registry: true #获取注册列表
4.关闭自我保护,定期清除无效连接
eureka:
server:
eviction-interval-timer-in-ms: 5000
enable-self-preservation: false
Ribbon(负载均衡组件)
1.eureka集成了
2.@LoadBalanced:开启负载均衡(默认轮询)
3.this.restTemplate.getForObject(“http://service-provider/user/” + id, User.class);
通过服务id查找
Hystrix(容错组件)
线程隔离,服务降级
为预防负荷过载响应慢情况,内部舍弃非核心接口和数据请求,直接返回准备好的fallback错误处理信息。
检查每次请求,是否请求超时,或者连接池已满
1.引入hystrix启动器
2.熔断时间,默认1s
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000 # 设置hystrix的超时时间为6000ms
3.在引导类上添加了一个注解:@EnableCircuitBreaker @SpringCloudApplication(集合注解)
4.定义熔断方法:
局部(要和被熔断的方法返回值和参数列表一致)
全局(返回值类型要被熔断的方法一致,参数列表必须为空)
5.@HystrixCommand(fallbackMethod=“局部熔断方法名”):声明被熔断的方法
6.@DefaultProperties(defaultFallback=“全局熔断方法名”)
服务熔断
类似于保险丝,当到达了一定状态就会停止服务调用。
不再发送请求
1.close:闭合状态,所有请求正常方法
2.open:打开状态,所有请求都无法访问。如果在一定时间内容,失败的比例不小于50%或者次数不少于20次
3.half open:半开状态,打开状态默认5s休眠期,在休眠期所有请求无法正常访问。过了休眠期会进入半开状态,放部分请求通过
Feign(远程调用)
嵌入了Ribbon和Hystrix功能
1.引入openFeign启动器
2.feign.hystrix.enable=true,开启feign的熔断功能
3.在引导类上 @EnableFeignClients
4.创建一个接口,在接口添加@FeignClient(value=“服务id”, fallback=实现类.class)
5.在接口中定义一些方法,这些方法的书写方式跟之前controller类似
6.创建了一个熔断类,实现feign接口,实现对应的方法,这些实现方法就是熔断方法
Zuul(服务路由)
服务路由、均衡负载、权限控制
1.引入zuul的启动器
2.配置:
zuul.routes.<路由名称>.path=/service-provider/**
zuul.routes.<路由名称>.url=http://localhost:8082
zuul.routes.<路由名称>.path=/service-provider/**
zuul.routes.<路由名称>.serviceId=service-provider
zuul.routes.服务名=/service-provider/** 最常使用
不用配置,默认就是服务id开头路径
3.@EnableZuulProxy
过滤器
创建一个类继承ZuulFilter基类
重写四个方法
filterType:pre route post error
filterOrder:返回值越小优先级越高
shouldFilter:是否执行run方法。true执行
run:具体的拦截逻辑
消息中间件
本质就是接受数据,接受请求,存储数据,发送数据等功能的技术服务。
1.利用可靠的消息传递机制进行系统和系统直接的通讯。
2.通过提供消息传递和消息的排队机制,它可以再分布式系统环境下扩展进程间的通讯。
场景
1.跨系统数据传递
2.高并发的流量削峰
3.数据的分发和异步处理
4.大数据分析与传递
5.分布式事务
组成
1.消息的协议
2.消息的持久化机制
3.消息的分发策略
4.消息的高可用,高可靠
5.消息的容错机制
消息中间件为什么不使用http协议?
1.http请求报文头和响应报文头比较复杂。
2.大部分为短连接,消息中断不会进行持久化造成请求丢失。
AMQP协议
高级消息队列协议
1.分布式事务支持2.消息持久化支持3.高性能和高可靠的消息处理优势。
MQTT协议
即时通许协议(物联网系统架构重要组成部分)
1.轻量2.架构简单3.传输快,不支持事务4.没有持久化设计
场景1.适用计算能力有限2.低带宽3.网络不稳定的场景
Kafka协议
基于tcp/ip二进制协议
RabbitMQ
spring同一家,对其支持完善
消息队列持久化
数据存入磁盘,而不是存在内存中服务器重启断开而消息,使数据能够永久保存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-plqwbEhn-1620630936782)(https://i.loli.net/2021/04/12/QWEx4PlCVdop6q8.png)]
消息分发策略
1:生产者 2:存储消息 3:消费者
生产者生成消息以后,MQ进行存储,消费者如何获取消息呢》
一般获取的方式无外乎推(push)或者拉(pull)两种方式,典型的git有推拉机制,我们发送的http请求就是一种典型的拉取数据库数据返回的过程,而消息队列MQ是一种推送的过程,而这些推机制会适用到很多的业务场景也有很多对应推机制策略。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gWWGldSj-1620630936783)(https://i.loli.net/2021/04/10/eZRI3WE9CaSLjhz.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EF58SnKs-1620630936784)(https://i.loli.net/2021/04/10/xtPCI5s3AfNiTwd.png)]
消息分发策略的机制和对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QylPb03W-1620630936785)(https://i.loli.net/2021/04/10/wbEfp1XgMrdWuiK.png)]
轮询分发:假设你有3台机器,100个消息,不关乎服务器性能都会给你分发33个消息,最后一个随便给另外一台
公平分发:是依据你服务器性能分配多少消息50 30 20这种
重发:例如上图当有三个订单系统,当消息中间件发送消息得不到响应出现故障他会重发给其他订单系统
消息队列的高可用和高可靠
**高可用:**产品在规定的条件和规定的时刻或时间内处于可执行规定功能状态的能力。
当业务量增加时,请求也过大,一台消息中间件服务器的会触及硬件(CPU,内存,磁盘)的极限,一台消息服务器你已经无法满足业务需求,所以消息中间件必须支持集群部署。
**高可靠:**是指系统可以无故障低持续运行,一个系统突然崩溃,报错,异常等等并不影响线上业务的正常运行,出错的几率极低。
保证中间件消息的可靠性,两方面考虑
1.消息的传输:通过协议来保证系统间数据解析的正确性
2.消息的存储可靠:通过持久化来保证消息的可靠性
集群模式1 Master-salve主从数据共享
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xt0QEOqu-1620630936785)(https://i.loli.net/2021/04/10/g658qDH3yQXIrLS.png)]
主节点负责写,从节点负责读
集群模式2 Master-slave主从同步部署方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WXuX9EuB-1620630936786)(https://i.loli.net/2021/04/10/w3Y8Xd9sctOebBr.png)]
主节点同样用来写入,但主节点会同步数据到slave节点形成副本,和redis主从机制有点类似。这样可达到负载均衡效果,若消费者有多个这样就可以去不同的节点进行消费,消息的拷贝和同步会占用很大的宽带和网络资源,尽量部署在同一个机房同一个局域网内
集群模式3 多主集群同步部署模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rWDrVeGa-1620630936787)(https://i.loli.net/2021/04/10/6JcUsvgd3FNq1nR.png)]
和上面区别不大,但是消费者可以从任意节点写入
集群模式4 多主集群转发部署模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o4ERbVY1-1620630936787)(https://i.loli.net/2021/04/10/Q8uL2sTyV9hHntU.png)]
元数据信息会存储数据的相关描述和记录存放的位置(队列)。
它会对元数据信息进行同步,如果消费者在slave消费,发现没有对应消息,可从对应的元数据信息中查询,然后返回对应消息信息,场景。例如买门票这个黄牛没票他会询问别的黄牛有门票吗,如果有就返回。
集群模式5 Master-slave与Breoker-cluster方案
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dc6vfiQS-1620630936788)(https://i.loli.net/2021/04/10/XaOTYsAuvIwiFz6.png)]
实现多主多从的热备机制来完成消息的高可用以及数据的热备机制,在生产规模达到一定的阶段的时候,这种使用的频率比较高。
总结:
1.要么消息共享
2.要么消息同步
3.要么元数据共享
角色分类
none
不能访问 management plugin
management
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
policymaker
management可以做的任何事外加:
查看、创建和删除自己的virtual hosts所属的policies和parameters
monitoring
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual hosts的全局的统计信息
administrator
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections
持久化队列会存盘;非持久化队列会存盘但会从服务器重启丢失。
AMQP
高级消息队列协议。
Broker即为rabbitmq一个节点。
生产者流转过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ffg7uhA6-1620630936788)(https://i.loli.net/2021/04/10/mpV4zh7stIQPEke.png)]
消费者流转过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-slwd6cr8-1620630936790)(https://i.loli.net/2021/04/10/4tAXea9JyqWjhz2.png)]
组成部分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uuTDCnyC-1620630936790)(https://i.loli.net/2021/04/10/vokEaBNF37C2mpg.png)]
**Server:**又称Broker,接受客户端连接,实现AMQP实体服务,安装rabbitmq-server
**Connection:**连接,应用程序与Broker的网络连接TCP/IP三次握手和四次挥手
**Channel:**网络通信,几乎所有操作都在Chanel中进行,Channel是进行消息读写的通道,客户端可以建立对各Channel
**Message:**消息,服务与应用程序之间传送的数据,由properties和body组成,Properties可是对消息进行修饰,比如消息的优先级,延迟等高级特性,Body则是消息体的内容
**Virtual Host:**虚拟地址,用于进行逻辑隔离,最上层的消息路由,一个虚拟主机理由可以有若干个Exchange和Quenue,同一个虚拟主机里面不能有相同名字的Exchange(可在管理端页面添加)
**Exchange:**交换机,接收消息,根据路由键发送消息到绑定的队列。(不具备消息存储的能力)
**Bindings:**Exchange和Queue之间的虚拟连接,bingding中可以保护多个routing key。
Routing key:是一个路由规则,虚拟机可以用它来确定如何路由一个特定信息。
**Queue:**队列,也称Message Queue,消息队列,保存消息并将他们转发给消费者。
RabbitMQ运行流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xFkr2cx7-1620630936790)(https://i.loli.net/2021/04/10/g2jbxBav5QtMedq.png)]
工作模式
Publish/Subscribe(发布订阅模式)
Exchange类型为fanout
只要有人订阅了我们的队列,都会收到消息(例如听直播讲课,大家都关注,我发消息通知,大家都会收到消息)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j7QYr44o-1620630936791)(https://i.loli.net/2021/04/10/cXFmJv3fVk8RKZC.png)]
Routing(路由模式)同时也是默认Exchage的模式
Exchange类型为direct(fanout的话还是会全收到)
相比上一层增加了路由key,只有队列绑定的路由key与交换机发送消息时携带的路由key相同才会接受到消息
Topic(主题模式)
相比上层更加了一层,增加了模糊key
Exchange类型为topic
#代表0个,1个或多个
*有且仅有一个
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iZoA3Gmb-1620630936792)(https://i.loli.net/2021/04/10/hRzdKBJVaA1LQy2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBVZO3Fl-1620630936793)(https://i.loli.net/2021/04/10/hRzdKBJVaA1LQy2.png)]
Headers模式
根据队列参数进行过滤
RabbitMQ使用场景
微服务系统拆分中,系统的一个模块与另一个模块要进行一个沟通和协同,这个时候公司采用了消息队列,在选择的时候就选择了RabbitMQ,我用起来最大的感触就是它是一个多线程异步的是一个分发的机制,可以使网站的性能成倍的提升,因为异步就可以使我们处理数据变得更加高效
\1. 异步
\2. 高内聚、低耦合
\3. 流量的削峰
\4. 分布式事务的可靠消费和可靠生产
\5. 索引、缓存、静态化处理的数据同步
\6. 流量监控
\7. 日志监控(ELK)
\8. 下单、订单分发、抢票
SpringBoot整合
生产者
\1. 导入依赖
\2. 配置rabbitmq服务
\3. 新建配置类定义交换机例如DirectExchange类和队列Queue以及与其绑定关系
\4. Service里边注入RabbitTemlate
消费者
\1. 导入依赖
\2. 配置rabbitmq服务
\3. @RabbitListener(queues={“queue_name”})
\4. @RabbitHandler接受消息方法注解
@RabbitListener(bindings = @QueueBinding(value = @Queue(value = “queuename”,durable = “true”,autoDelete = “false”),exchange = @Exchange(value = “exchange_name”,type = ExchangeTypes.TOPIC),key = “#.sms.#”)))
Rabbit配置最好定义在消费者队列,毕竟消费者直接跟队列打交道。
过期时间
可对消息设置预期的时间,在这个时间内都可以被消费者接收获取;过了之后消息将自动删除。RabbitMQ可对消息和队列设置TTL。
\1. 通过队列属性设置,队列中所有消息都有相同的过期时间
\2. 对消息进行单独设置,每条消息TTL可以不同
若两种方式同时使用,则以TTL较小的那个数值为准。
两者不同在于
队列属性设置过期之后会写入到死性队列中去可进行消息转移,单独消息设置会被移除
场景:订单下了20分钟还没有支付,就会将这个消息进行转移
给消息设置过期时间
MessagePostProcessor messagePostProcessor = new MessagePostProcessor(){
public Message postProcessMessage(Message message) throws AmqpException{
message.getMessageProperties().setExpiration(“5000”);
message.getMessageProperties().setContentEncoding(“UTF-8”);
return message;
}
};
死信队列
DLX,全程Dead-Letter-Exchange,可称之为死信交换机。当消息在一个队列中变成死信(dead message)之后,它能被重新发送到另一个交换机中,这个交换机就是DLX,绑定的队列就称之为死信队列。
死信的产生原因
l 消息被拒绝
l 消息过期
l 队列达到最大长度
队列参数更新的话启动会报错
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dSSGvqXe-1620630936794)(https://i.loli.net/2021/04/12/J3QqWc59rsAhleO.png)]
内存磁盘监控
内存极限大小例8g * 0.4 = 3.2
Rabbit为什么给予channel去处理而不是链接?
可以存在没有交换机的队列吗?
不可能,即使没有指定交换机,一定会存在一个默认的交换机
Kafka
基于tcp/ip协议二进制传输,高性能;不支持事务,支持持久化分发机制
Dubbo
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
排序算法
冒泡排序
int[] arr = new int arr[]{1,3,5,6,2};
for(int i=0;i<arr.length-1;i++){
for(int j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
for(int i=0;i<arr.length;i++){
System.out.print(arr[i]);
}
设计模式
创建型模式:工厂方法模式,抽象工厂模式,单例模式,建造者模式,原型模式
结构型模式:适配器模式,装饰器模式,代理模式,外观模式,桥接模式,组合模式,享元模式
行为型模式:策略模式,模板方法模式,观察者模式,迭代子模式,责任链模式,命令模式,备忘录模式,状态模式,访问者模式,中介者模式,解释器模式
代理模式
工厂模式
实现了创建者与调用者的分离,即将创建对象的具体过程屏蔽隔离起来,达到提高灵活性的目的。
1.无工厂模式
2.简单工厂模式
用来生产同一等级结构中的任意产品(对于增加新的产品,需要修改以偶的代码;违反开闭原则
interface Car{
public void run();
}
Class Audi implements Car{
public void run(){
System.out.print("Audi在跑");
}
}
Class Hongqi implements Car{
public void run(){
System.out.print("Hongqi在跑");
}
}
class CarFactory{
public static Car getCarType(String type){
//方式一
if("奥迪".equals(type)){
new Audi();
}else if("红旗".equals(type)){
new Hongqi();
}else{
return null;
}
}
//方式二
/*
public static Car getAudi(){
return new Audi();
}
public static Car getHongqi(){
return new Hongqi();
}
*/
public static void main(String[] args){
Car A = CarFactory.getCarType("Audi");
//Car A = CarFactory.getAudi();
audi.run();
}
}
3.工厂方法模式
用来生产同一等级结构中的固定产品。(支持增加任意产品—)
interface Factory{
Car getCar();
}
class AudiFactory implements Factory{
public Car getCar(){
return new Audi();
}
}
class HongqiFactory implements Factory{
public Car getCar(){
return new Hongqi();
}
}
public static void main(String[] args){
Car A = new AudiFactory.getCar();
A.run();
}
4.抽象工厂模式
用来生产不同产品族的全部产品(对于增加新的产品,无能为力,支持增加产品族)(比如讲车细分跑车,轿车,suv)
单例模式
饿汉式
public static void main(String[] args){
Blank blank1 = Blank.getInstance();
Blank blank2 = Blank.getInstance();
//blank1 == blank2
}
Class Blank{
//1.私有化类的构造器
private Blank(){
}
//2.内部创建类的对象
//4.要求此对象也必须声明为静态
private static Blank instance = new Blank();
//3.提供公共的静态的方法,返回类的对象
public static Blank getInstance(){
return instance;
}
}
懒汉式
public static void main(String[] args){
Order oreder1 = Order.getInstance();
}
Class Order{
//1.私有化类的构造器
private Order(){
}
//2.声明当前类对象,没有初始化
//4.要求此对象也必须声明为静态
public static Order instance = null;
//3.提供公共的静态的方法,返回类的对象
public static synchronized getInstance(){
if(instance == null){
instance = new Order();
}
return instance;
}
}
饿汉式:坏处:每次调用不用在创建,直接返回实例
好处:线程安全
懒汉式:好处:用if做了判断,延迟对象的创建
坏处:线程不安全
前端杂项
CSS选择器
类选择器 .class
ID选择器 #id
标签选择器 p
div,p //选择所有
元素。
div p //选择
元素。
属性选择器 [attribute = value]
JS中Dom操作
getElementById、getElementsByName、getElementsByTagName、getElementsByClassName、getAttribute、setAttribute、
Jquery
所有 jQuery 函数位于一个 document ready 函数中:
$(document).ready(function(){
// 开始写 jQuery 代码...
});
简洁写法(与以上写法效果相同):
$(function(){
// 开始写 jQuery 代码...
});
$.ajax({
type:"get",
url:"search",
data:{"key":$(this).val()},
dataType:"json",
success:function (data) {
$("#msg").show();
$("#msg").html(data);
$("#msg").click(function () {
$("#hname").val(data);
$autocomplete.empty().hide();
})
}})
JSON
json是一种轻量级数据交换格式,是一种特殊的字符串,是一种名值对集合,可在跨平台场景下传递数据用。一般在ajax时候用的多
{
"ming":"value",
...
}
Ajax跨域问题
1、响应头添加Header允许访问
2、jsonp 只支持get请求不支持post请求
3、httpClient内部转发
4、使用接口网关——nginx、springcloud zuul (互联网公司常规解决方案)
(1条消息) 解决ajax跨域问题【5种解决方案】_itcats_cn的博客-CSDN博客_ajax跨域的解决方案
Redis
redis是一个开源的,内存中的数据结构存储系统,可用作数据库、缓存和消息中间件。支持多种类型数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
常用命令
redis -server kconfig/redis.conf #开启进程
redis-cli -h host -p port -a password #连接redis
redis-cli --raw #防止中文乱码
keys * #查看所有key值
flushdb #清空点前库的值
flushall #清空所有
SET key value #设置key值
EXPIRE key 30 #设置过期时间
TTL key #查看key剩余生存时间
watch key #监视一个或多个(开启乐观锁)
UNWATCH #取消监视
MULTI #开启事务
DISCARD #清空事务队列
EXEC #执行事务
Jedis
java连接Jedis的中间组件
采用的直连。多个线程操作,不安全,若想要避免不安全,使用jedis pool连接池!BIO
Lettuce
SpringBoot2.X之后,原使用的jedis被替换为lettuce.
采用netty,实例可再多个线程中进行共享,不存在线程不安全的情况。可减少线程数量!NIO
注入RedisTemplate,完成redis相关操作与jedis相同
redisTemplate.opsForValue(); //操作字符串
Redis持久化
RDB(redis database)
在指定的时间间隔内将内存中的数据集快照写入磁盘,恢复时将快照文件直接读到内存里
原理:
redis单独创建fork子进程来进行持久化,先将数据写入到临时文件中,待持久化过程都结束了,再用临时文件替换上次持久化好的文件。
rdb保存的文件是dump.rdb
redis.conf 中 save 60 5 //60秒中修改了5次会更新dump.rdb;默认开启
恢复:
将rdb文件放在redis启动目录就可以,redis启动时候会自动恢复
位置 config get dir
优点:
1.适合大规模数据恢复
2.对数据的完整性要不高
缺点:
1.需要一定的时间间隔进程操作!若redis意外宕机了,最后一次数据修改就没了
2.fork进程时,会占用一定的内存空间
AOF(Append Only File)
将我们所有命令都记录下来,恢复的时候就把这个文件命令都执行一遍
原理:
以日志形式记录每个写操作,将redis执行过得所有指令记录下来,只许追加文件但不可以改写文件redis启动之初会读取该文件重新构造数据。
保存在appendonly.aof文件;
redis.conf默认不开启,需手动 即: appendonly yes
如果aof文件有错位,redis启动不起来,需要修复;通过redis -check -aof --fix修复
优点:
1.每一次修改都同步,文件的完整会更加好
2.每秒同步一次,可能会丢失一秒的数据
3.从不同步,效率最高的
缺点:
1.相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
2.aof运行效率也要比rdb慢,所以我们redis默认配置就是rdb持久化
乐观锁解决并发秒杀问题
场景:
秒杀时用户非常多,所以会有这样一种情况:用户A和用户B同时抢到一件商品,同时下单,同时减库存,库存只会减一次。这就是典型的并发问题。
解决:
Watch会监视指定的key,并会发觉这些键是否被改动过了。
如果在一个事务中开始执行之前,其他的客户端对已经监视的key进行了修改,那么当前事务就丢弃它的修改。
redis发布订阅
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3v08j3gj-1620630936797)(https://i.loli.net/2021/03/31/5KNVuXAroWa7gqe.png)]
SUBSCRIBE 频道名 #订阅频道名
PUBLISH 频道名 “message” #发布者发布消息到频道
原理:
通过SUBSCRIBE命令订阅某频道后,redis-server维护了一个字典,字典就是一个个频道,字典值则是一个链表,链表保存了所有订阅这个channel客户端。而SUBSCRIBE命令就是将客户端添加到channel订阅链表中
通过PUBLISH命令想订阅者发送消息,redis-server会使用给定的频道作为键,在它所维护的channel字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发布给所有订阅者。
场景:
1.实时消息系统
2.实时聊天(频道作为聊天室,将信息回显给所有人即可)
3.订阅,关注系统
复杂的会使用消息中间件MQ,kafka,rabbitmq
主从复制,读写分离
电商的商品,一般都是一次上传,无数次浏览;即多读少写符合情况
作用
1.数据冗余:主从复制实现数据的热备份,是持久化之外的一种冗余方式
2.故障恢复:主节点出现问题是,可以由节点提供服务,实现快速的故障恢复
3.负载均衡:主节点提供写服务,由从节点提供读服务(写用主,读用从)分担服务器负载;尤其是写少读多场景下,通过多从节点分担读负载,可大大提高redis服务器的并发量。
4.高可用(集群):
- 从结构上,单redis服务器会发生单点故障,一台服务器需处理的请求负载压力较大
- 从容量上,单redis最大使用内存不应超过20g
info replication #查看当前库的信息,可查看主从
#默认情况下,每一台都是主节点
搭建(一主二从)
cp redis.conf redis80.condf #拷贝配置文件
...
#修改配置文件中的port-端口,pidfile文件名,dump.rdb文件名,logfile文件名
SLAVEOF host port #找谁当主子;如果从机宕机,变回主机;变回从机即可获取
#真实情况下都是从配置文件中修改,这样是永久的
replicaof ip port #主机
masterauth password #主机密码
主机只能写,从机只能读
主机断链接,从机也可用;主机再连上,依旧可以获得最新的数据
复制原理
slave启动成功连接到master会发送一个sync同步命令
master接到命令,启动后台存盘进程,同事手机所有接受到用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到slave,并完成一次完全同步
**全量复制:**slave服务在接受到数据库文件数据后,将其存盘并加载到内存中
**增量复制:**master将新的所有收集到的修改命令依次传给slave,完成同步
只要重连master,一次完全同步(全量复制)将被自动执行
层层链路
master-slave-slave
如果主机断开连接,可使用SLAVEOF no one变为主机
哨兵模式
主从切换,带来的手动配置,需人工干预
能够后台监控主机是否故障,若故障根据投票数自动将从库转换为主库。
哨兵是一个独立的进程,哨兵通过发送命令,等待redis服务器响应,从而监控运行多个redis实例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wATjfymH-1620630936798)(https://i.loli.net/2021/03/29/sO6Zcl8otu7JheP.png)]
原理
假设主服务器宕机,哨兵1检测到这个结果,不会马上进行failover过程,仅仅哨兵1主观认为主服务器不可用,这个现象为主观下线,当后面哨兵检测到主服务器不可用,且数量达到一定值,那么哨兵就会进行一次投票,投票结果由一个哨兵发起,进行failover(故障转移)操作。切换成功,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程为客观下线。
如果主机回来,只能归并到新的主机当从机
使用
port 26379 #若有哨兵模式,需要挨个配置端口
sentinel monitor 被监控的名称 host port 1 #配置哨兵监控
redis -sentinel kconfig/sentinel.conf #开启哨兵模式
sentinel notification-script mymaster /var/redis/notify.sh #配置当某一时间发生是所需执行的脚本,可通过脚本来通知管理员
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh #客户端重新配置主节点参数脚本
优点
1.基于主从复制,有着其优点
2.主从可切换,故障可转移,系统可用性好
3.哨兵是主从的一个升级,手动到自动,更加健壮
缺点
1.redis不好在线扩容,集群容量一旦到达上限,在线扩容就十分麻烦
2.实现哨兵模式配置其实很麻烦
如何防止缓存穿透、缓存击穿、缓存雪崩和缓存刷新。
**【**1】**缓存穿透:缓存穿透是说收到一个请求,但是该请求缓存中不存在,只能去数据库中查询,然后放进缓存。但当有好多请求同时访问同一个数据时,业务系统把这些请求全发到了数据库;或者恶意构造一个逻辑上不存在的数据,然后大量发送这个请求,这样每次都会被发送到数据库,最终导致数据库挂掉。
【解决的办法】:**对于恶意访问,一种思路是先做校验,对恶意数据直接过滤掉,不要发送至数据库层;第二种思路是缓存空结果,就是对查询不存在的数据也记录在缓存中,这样就可以有效的减少查询数据库的次数。非恶意访问,结合缓存击穿说明。
解决方案
布隆过滤器:是一种数据结构, 对所有可能查询的参数以hash形式存储,在控制层先进性校验,不符则丢弃,从而避免对底层存储系统的查询压力。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hDh9KSSc-1620630936798)(https://i.loli.net/2021/03/31/TrHnZbLRqYmBtIO.png)]
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CvfRQbQu-1620630936799)(https://i.loli.net/2021/03/31/FnsbKxvyuCRXma7.png)]
存在问题
1.空值被缓存起来,这意味着缓存需更多的控件存储更多的键,因为这当中可能会有很多
2.即使空值设置过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口不一致,对于需要保持一致性的业务会有影响。
【2】缓存击穿:上面提到的某个数据没有,然后好多请求查询数据库,可以归为缓存击穿的范畴:对于热点数据,当缓存失效过期的一瞬间,所有的请求都被下放到数据库去请求更新缓存,数据库被压垮。
【解决的办法】**:**防范此类问题,一种思路是加全局锁,就是所有访问某个数据的请求都共享一个锁,获得锁的那个才有资格去访问数据库,其他线程必须等待。但现在大部分系统都是分布式的,本地锁无法控制其他服务器也等待,所以要用到全局锁,比如 Redis的 setnx实现全局锁。另一种思想是对即将过期的数据进行主动刷新,比如新起一个线程轮询数据,或者比如把所有的数据划分为不同的缓存区间,定期分区间刷新数据。第二个思路与缓存雪崩有点关系。
【3】缓存雪崩:缓存雪崩是指当我们给所有的缓存设置了同样的过期时间,当某一时刻,整个缓存的数据全部过期了,然后瞬间所有的请求都被抛向了数据库,数据库就崩掉了。(例如双十一:停掉一些服务,保证主要服务可用)
【解决的办法】:
redis高可用:多搞几台redis,挂掉后还可继续工作,即搭建集群
限流降级:缓存失效后通过枷锁或队列控制读数据库写缓存的线程数量,对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热:在正式部署前,把先可能的数据先预先访问一遍,这样部分可能的大量访问的数据就会加载到缓存中,即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的事件尽量均匀。
对于 Redis 挂掉了,请求全部走数据库,也属于缓存雪崩,我们可以有以下思路进行解决:
事发前:实现 Redis 的高可用(主从架构+Sentinel 或者 Redis Cluster),尽可能避免 Redis 挂掉这种情况。
事发中:万一 Redis 真的挂了,我们可以设置本地缓存(ehcache)+ 限流(hystrix),尽量避免我们的数据库被干掉。
事发后:Redis 持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
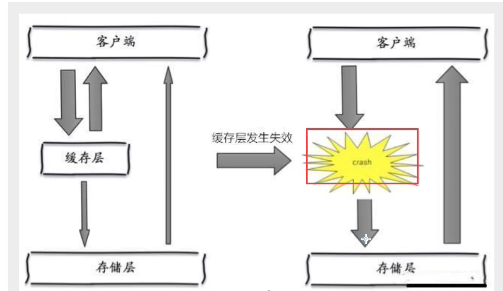
【4】**缓存刷新:**既清空缓存 ,一般在 Insert、Update、Delete 操作后就需要刷新缓存,如果不执行就会出现脏数据。但当缓存请求的系统蹦掉后,返回给缓存的值为null。
Nginx
Nginx ,是一个高性能的 Web 服务器和反向代理服务器用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。
配置简单,非阻塞、高并发连接、内存消耗小、CPU使用效率高、成本低廉。
主要功能
1、正向、反向代理
2、负载均衡、分流
3、虚拟主机(绑定host)
Nginx解决端口问题(反向代理)
注意
windows环境下,如果nginx指令不存在,添加环境变量path添加nginx路径;
如果start nginx.exe启动不了,查看端口80是否被占用
nginx是在启动过程中;更改了nginx.conf;执行命令nginx -s reload(重新加载)
解决:
更改conf下的nginx.conf文件;
localhost改为你要拦截的域名
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R4UeijvC-1620630936800)(https://i.loli.net/2021/03/25/dut317NbeQhLSHP.png)]
正向代理和反向代理区别

正向代理是一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定原始服务器,然后代理向原始服务器转交请求并将获得的内容返回给客户端。代理服务器和客户端处于同一个局域网内。
比如说fanqiang。我知道我要访问谷歌,于是我就告诉代理服务器让它帮我转发。
反向代理实际运行方式是代理服务器接受网络上的连接请求。它将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给网络上请求连接的客户端 。代理服务器和原始服务器处于同一个局域网内。
比如说我要访问taobao,对我来说不知道图片、json、css 是不是同一个服务器返回回来的,但是我不关心,是反向代理 处理的,我不知道原始服务器。
Nginx如何处理HTTP请求
它结合多进程机制(单线程)和异步非阻塞方式。
1、多进程机制(单线程)
服务器每当收到一个客户端时,就有 服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
2、异步非阻塞机制
每个工作进程 使用 异步非阻塞方式 ,可以处理 多个客户端请求 。运用了epoll模型,提供了一个队列,排队解决。
当某个 工作进程 接收到客户端的请求以后,调用 IO 进行处理,如果不能立即得到结果,就去 处理其他请求 (即为 非阻塞 );而 客户端 在此期间也 无需等待响应 ,可以去处理其他事情(即为 异步 )。
当 IO 返回时,就会通知此 工作进程 ;该进程得到通知,暂时 挂起 当前处理的事务去 响应客户端请求 。
Nginx的master和worker是如何工作的
这跟Nginx的多进程、单线程有关。(一个进程只有一个主线程)。
为什么要用单线程?
采用单线程来异步非阻塞处理请求(管理员可以配置Nginx主进程的工作进程的数量),不会为每个请求分配cpu和内存资源,节省了大量资源,同时也减少了大量的CPU的上下文切换,所以才使得Nginx支持更高的并发。
简单过程:
主程序 Master process 启动后,通过一个 for 循环来 接收 和 处理外部信号 ;
主进程通过 fork() 函数产生 worker 子进程 ,每个子进程执行一个 for循环来实现Nginx服务器对事件的接收和处理 。
详细过程:
1、Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程。
2、master 接收来自外界的信号,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程,然后向各worker进程发送信号,每个进程都有可能来处理这个连接。
3、所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接。
4、当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。
Nginx常用命令
- 启动
nginx。 - 停止
nginx -s stop或nginx -s quit。 - 重启
nginx -s reload或service nginx reload。 - 重载指定配置文件
.nginx -c /usr/local/nginx/conf/nginx.conf。 - 查看 nginx 版本
nginx -v。 - 测试配置文件 nginx -t
Nginx状态码
500:
Internal Server Error 内部服务错误,比如脚本错误,编程语言语法错误。
502:
Bad Gateway错误,网关错误。比如服务器当前连接太多,响应太慢,页面素材太多、带宽慢。
503:
Service Temporarily Unavailable,服务不可用,web服务器不能处理HTTP请求,可能是临时超载或者是服务器进行停机维护。
504:
Gateway timeout 网关超时,程序执行时间过长导致响应超时,例如程序需要执行20秒,而nginx最大响应等待时间为10秒,这样就会出现超时。
Nginx和Apache、Tomcat之间的不同点
1、Nginx/Apache 是Web Server,而Apache Tomact是一个servlet container
2、tomcat(web应用服务器)可以对jsp进行解析,nginx和apache只是web服务器,可以简单理解为只能提供html静态文件服务。
区分:web服务器不能解析jsp等页面,只能处理js、css、html等静态资源。
并发:web服务器的并发能力远高于web应用服务器。
Nginx和Apache区别:
1)Nginx轻量级,同样起web 服务,比apache占用更少的内存及资源 。
2)Nginx 抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能 。
3)Nginx提供负载均衡,可以做做反向代理,前端服务器
4)Nginx多进程单线程,异步非阻塞;Apache多进程同步,阻塞。
Nginx负载均衡策略
1.轮询(默认)round_robin
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
2.IP哈希ip_hash
每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 session 共享的问题。
当然,实际场景下,一般不考虑使用 ip_hash 解决 session 共享。
3.最少连接least_conn
下一个请求将被分派到活动连接数量最少的服务器
4.权重weight
weight的值越大分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下,达到合理的资源利用率。
还可以通过插件支持其他策略
如何限流
Nginx 提供两种限流方式,一是控制速率,二是控制并发连接数。
1、控制速率
ngx_http_limit_req_module 模块提供了漏桶算法(leaky bucket),可以限制单个IP的请求处理频率。
如:
1.1 正常限流:
http {
limit_req_zone 192.168.1.1 zone=myLimit:10m rate=5r/s;
}
server {
location / {
limit_req zone=myLimit;
rewrite / http://www.hac.cn permanent;
}
}
参数解释:
key: 定义需要限流的对象。
zone: 定义共享内存区来存储访问信息。
rate: 用于设置最大访问速率。
表示基于客户端192.168.1.1进行限流,定义了一个大小为10M,名称为myLimit的内存区,用于存储IP地址访问信息。
rate设置IP访问频率,rate=5r/s表示每秒只能处理每个IP地址的5个请求。
Nginx限流是按照毫秒级为单位的,也就是说1秒处理5个请求会变成每200ms只处理一个请求。如果200ms内已经处理完1个请求,但是还是有有新的请求到达,这时候Nginx就会拒绝处理该请求。
1.2 突发流量限制访问频率
上面rate设置了 5r/s,如果有时候流量突然变大,超出的请求就被拒绝返回503了,突发的流量影响业务就不好了。
这时候可以加上burst 参数,一般再结合 nodelay 一起使用。
server {
location / {
limit_req zone=myLimit burst=20 nodelay;
rewrite / http://www.hac.cn permanent;
}
}
burst=20 nodelay 表示这20个请求立马处理,不能延迟,相当于特事特办。不过,即使这20个突发请求立马处理结束,后续来了请求也不会立马处理。
burst=20 相当于缓存队列中占了20个坑,即使请求被处理了,这20个位置也只能按100ms一个来释放。
2、控制并发连接数
ngx_http_limit_conn_module 提供了限制连接数功能。
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}
limit_conn perip 10 作用的key 是 $binary_remote_addr,表示限制单个IP同时最多能持有10个连接。
limit_conn perserver 100 作用的key是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。
注:limit_conn perserver 100 作用的key是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。
拓展:
如果不想做限流,还可以设置白名单:
利用 Nginx ngx_http_geo_module 和 ngx_http_map_module 两个工具模块提供的功能。
##定义白名单ip列表变量
geo $limit {
default 1;
10.0.0.0/8 0;
192.168.0.0/10 0;
81.56.0.35 0;
}
map $limit $limit_key {
0 "";
1 $binary_remote_addr;
}
# 正常限流设置
limit_req_zone $limit_key zone=myRateLimit:10m rate=10r/s;
geo 对于白名单 将返回0,不限流;其他IP将返回1,进行限流。
具体参考:http://nginx.org/en/docs/http/ngx_http_geo_module.html
除此之外:
ngx_http_core_module 还提供了限制数据传输速度的能力(即常说的下载速度)
location /flv/ {
flv;
limit_rate_after 500m;
limit_rate 50k;
}
针对每个请求,表示客户端下载前500m的大小时不限速,下载超过了500m后就限速50k/s。
Git
工作流程
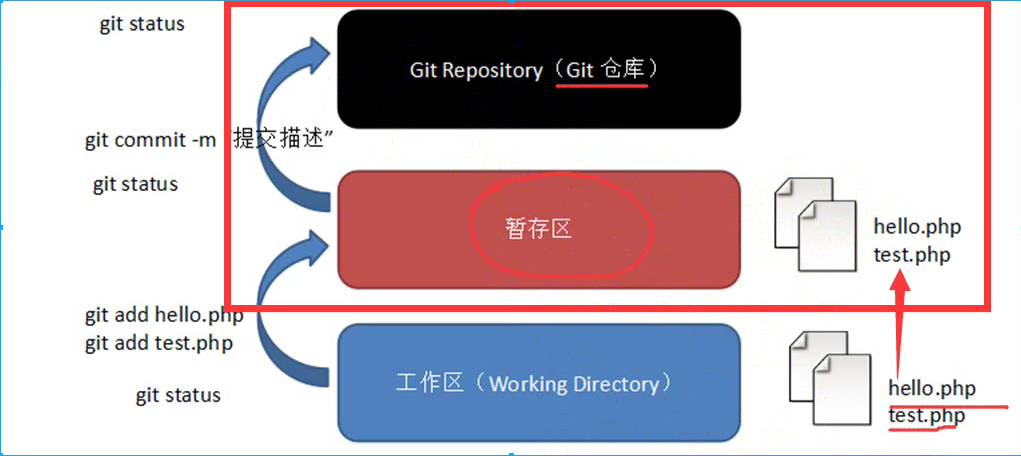
常用命令
git fetch //拉取代码
git status //查看状态
git rebase origin/master //合并
git stash pop //(保存已修改的代码;apply还原工作区)
git add . //添加当前目录修改的文件
git commit -m “提交注释” //提交
git push //上传
统一换行符
Windows操作系统采用两个字符来进行换行,即CRLF;Unix/Linux/Mac OS X操作系统采用单个字符LF来进行换行;另外,MacIntosh操作系统(即早期的Mac操作系统)采用单个字符CR来进行换行。
仓库中的换行符是LF,但是在更新的时候被改为自动CRLF了。
解决
用指令将其关闭
git config --global core.autocrlf false
Merge和Rebase区别
merge 是一个合并操作,会将两个分支的修改合并在一起,默认操作的情况下会提交合并中修改的内容
merge 的提交历史忠实地记录了实际发生过什么,关注点在真实的提交历史上面
rebase 并没有进行合并操作,只是提取了当前分支的修改,将其复制在了目标分支的最新提交后面
rebase 的提交历史反映了项目过程中发生了什么,关注点在开发过程上面
Git回滚撤销
(8条消息) Git撤销&回滚操作_李刚的学习专栏-CSDN博客_git回滚命令
Linux
ls | grep abs //显示含有abs的文件
pwd //显示当前目录
stat abs //显示abs文件详细信息
rm //删除文件
-r //递归删除,可删除子目录及文件
-f //强制删除
ping 127.0.0.1 //测试网路连通
netstat -pan | grep 50002 //查看50002端口占用情况
ps -aux | grep 14398 //通过进程id查找程序
kill -9 pid //杀死pid进程
gzip file1 //压缩名为file1的文件
vim使用
vim三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
?apache 从上往下查找apache
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









