







问题现象
某项目打来急电,说pre服务跑着跑着就挂了,几乎隔两个小时就挂,挂了重启依然如此。经过初步排查,只知道是内存溢出的原因,于是项目开发人员将jvm堆内存由512M 调大至1G,1G不够到2G,调大以后,虽然没有那么快死掉,但是最终的宿命还是一样。搞不定了~
排查过程
接到了这个问题,我也很兴奋,正好利用前端时间培训课所学伎俩,来排查此问题。因为是堆内存溢出嘛,很容易想到把系统堆内存倒出来看下。结果一开始导出来,根本看不出啥问题,一切都是那么正常,大约过了一会儿,就不正常了,看到有我们自己写某2个对象的实例数明显异常。
jmap -histo 14006 > pre_jamap.log
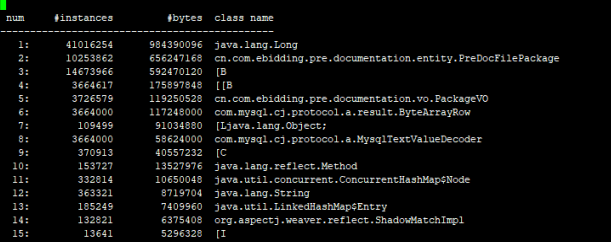
但是问题来了,这两个对象在系统里面多处都用到了,不太好排查具体是哪块逻辑导致的。此时想到了会不会是定时任务执行的逻辑?执行很频繁,或者产生了死循环之类的。好,那既然这样,先看下定时任务。
定时任务经过排查很快就被排除,因为这个服务的定时任务没有和业务相关的。然后进一步证明,如果系统启动后,没有测试的同事上去操作,放多久没事,一旦大家上去操作几个功能后,可能内存一下就上来了。所以肯定还是出发了某个机关,然后就会出现此问题。
然后既然可能是死循环,那就看看有没有死锁,或者CPU高的情况嘛。
top -H -p 14006
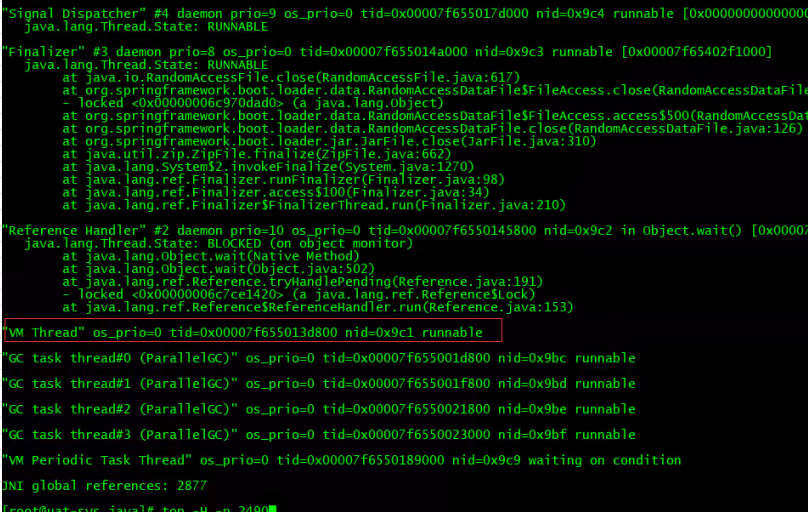
一开始并没有发现CPU很高,不过过一会儿就碰到了,然后启动的时间越久,CPU就一直处于高位,停不下来,好,继续敲命令。一共有4个线程id CPU几乎100%,随便拿一个就行。
jstack 14006 | grep -A 10 4cd0
结果一看,是FGC的线程,仔细想想也是,系统里应该有对象在疯狂创建,堆内存会自动扩容,同时也会频繁发生FGC。
然后就拿之前所学的一个命令,看下
jstat -gc 15387 1000 100
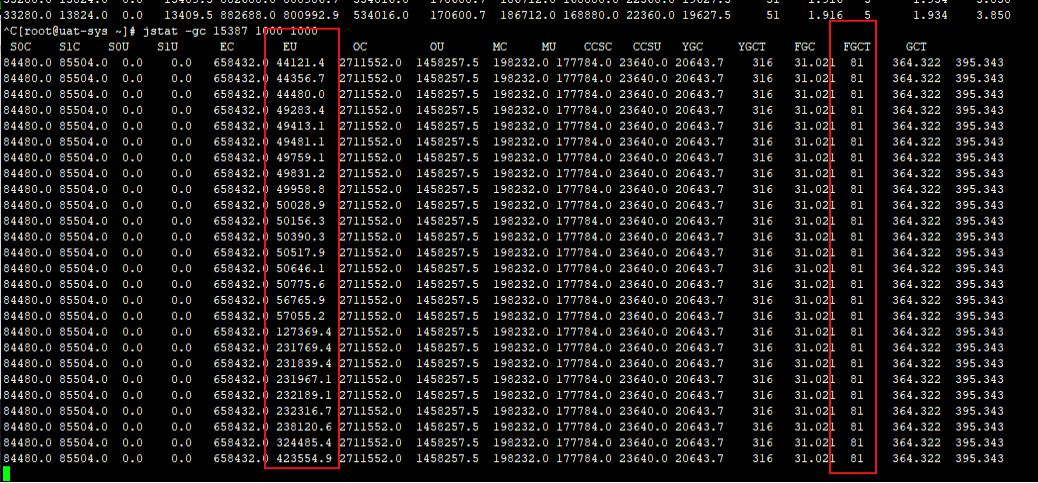
结果到最后看到这个现象,伊甸园区疯狂增长,不断增长,到了个值后,马上发生full GC,然而Full GC貌似根本回收不了太多空间,而且从结果来看,FGC的平均时间越来越长,几乎每隔1~2秒就发生一次。
此时,想到了之前学的“老年代空间担保机制”与“大对象直接进入老年代”等机制,但是关键在于断不了准确的问题。于是还是想着从看CPU线程栈入手。
理论上讲,如果有对象疯狂创建,那么那个线程的CPU一定不会太低,但事实是除了那几个GC的线程,其他线程貌似占用CPU资源都算正常,也就偶尔高一下。这让我犯难了~
然后经过多次找CPU略高的线程,看看对应哪个代码。结果看了好多次,怀疑了好几个地方,结果把那个接口发给开发看,开发说我这个逻辑很简单,就是根据id查一个数据而已,能有啥问题?
搞了一晚+一上午,觉得之前上的课白上了,这个问题,貌似用这些命令能看出来问题类型,但却很难定位到具体代码,怎么办?这个问题很严重,客户在做系统测试呢……后来,我想了一个办法,在这两个对象的构造函数里,打印下一个东西,就是创建他的线程名字及对应的方法调用栈。发布上去一看,哇,果然疯狂的刷这个sout,很疯狂,当然,其方法调用栈也找到了,可以说至少找到了一部分了。
没办法,还得自己亲自来审视我找到的关键代码。这个问题让我一晚上没睡好,功夫不负有心人,总算抓到了非常可疑的点,其CPU略高一点点,但是里面的逻辑正好会涉及到上面查出来的那两个对象。于是仔细再看他里面的各种条件、循环等,看看是否出现了死循环等,然而好像都不大可能,因为都是for,for的list都是从数据库里根据复杂条件查出来的,他能有多大?不可能让循环一直跑吧。
StackTraceElement stack[] = Thread.currentThread().getStackTrace();
for(int i=0;i<stack.length;i++){
System.out.print(stack[i].getClassName()+" ---"+stack[i].getMethodName()+"---");
}
突然,我回头再看了下那个堆内存信息,发现除了自己代码的两个对象外,还有两个mysql包里的对象也很大,,还有个LinkedHashMap也很大,咦,会不会真的和数据库有关系?然后就把整个逻辑里涉及到呗循环的list对应的查询语句都拿了出来,仔细看看!看到了这个SQL,我把前面的字段去掉了,换成count看看,来来来,你也来看下:
SELECT
count(*)
FROM
pre_doc_file_package p,
pre_prj_package b,
pre_doc_bulletin_relate re,
pre_doc_bulletin_main dum
WHERE
p.is_deleted = '0'
AND p.doc_file_id = (
SELECT
b.doc_file_id
FROM
pre_doc_file a
LEFT JOIN pre_doc_file_package b ON a.id = b.doc_file_id
LEFT JOIN pre_prj_package p ON p.id = b.package_id
WHERE
a.is_deleted = '0'
AND b.is_deleted = '0'
AND p.is_deleted = '0'
AND a.file_type_code = '20'
AND b.PACKAGE_ID = 1336238002837393410
)
AND b.is_deleted = '0'
AND b.id = p.package_id
ORDER BY
b.package_seq ASC;
结果结果让我大吃一惊,执行了24秒左右,出来的结果数是30W+,我滴乖乖,仔细看看这个SQL,发现:
pre_doc_bulletin_relate re,
pre_doc_bulletin_main dum
这两个表是干嘛用的?嗯哼!!!嚓,没用到不说,写在这里没加任何条件,产生了笛卡尔积的效应啊!哎,这个鬼终于抓到了……
思考 一条SQL下去查出30W的记录,然后放到jvm里是什么概念?这是一个用户触到了,如果是2个用户,3个用户对这个接口发起了请求呢?不炸才怪,好吧,原因知道了~,这个坑~,这位朋友应该为此问题好好反思下了。请敬畏自己提交的每一行代码~
解决方案
没啥好说了,把SQL改下,去掉那两张表,再启动,万事大吉了~
好了,本期内容就是这么多,希望能够帮助到您,感谢您能读到最后,如果觉得内容不错,请您点赞转发给予鼓励,咱们下期再见!















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









