







你在训练机器学习模型的时候,有哪些关于 training dynamics 的经验?
training dynamics 指的是训练过程中,损失函数(或者其他反应模型性能的指标)随训练时间/迭代轮数变化的情况。(不知道中文怎么翻译?训练动力学?感觉怪怪的 = =)
了解不同网络结构/损失函数的 training dynamics 有助于判断模型在训练过程中到底发生了什么问题,为下一步超参数的调整方向提供指导。
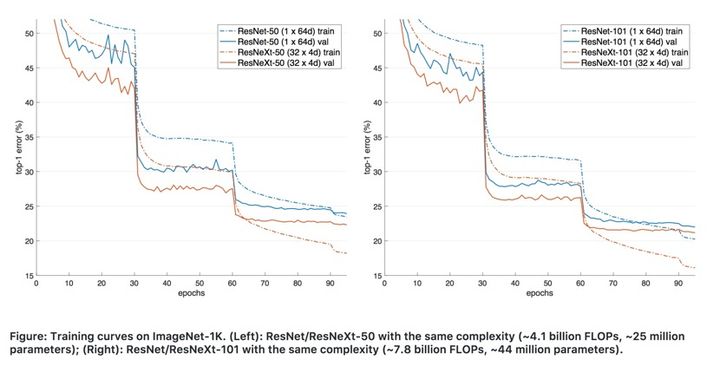
一个例子是用 batch norm 的时候,在训练初期,可能会出现训练集 accuracy 增长较快但是验证集 accuracy 几乎不动的情况。这时候不一定是代码有问题,也有可能是 estimated population mean/variance 还不够准确,需要耐心等一段时间才会看到验证集上的精度提升,就像这个手写汉字识别项目(soloice/Chinese-Character-Recognition)的配图里所展示的情况(橙色:训练集;青色:验证集)。这时可以通过减小 exponential moving average 的 decay 之类的手段缩短验证集上预热的时间(当然这会造成 population mean/variance 估计变得不太稳定)。
另一个例子是 10686 一次 CTC-RNN 调参经历,其中记录了训练 LSTM network with CTC loss 时发生的错误率先降后升再降的现象。
https://www.zhihu.com/question/63152097
作者:星衡科技
链接:https://www.zhihu.com/question/63152097/answer/759214147
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
常见的是初始固定学习率(learning rate),然后每隔一定轮(epoch)之后降低学习率,损失(loss)和准确率(accuracy)此时一般会进行突变,如下图:

实用策略:warm up+余弦退火
warm up:训练初期由于离目标较远,一般需要选择大的学习率,但是使用过大的学习率容易导致不稳定性。所以可以做一个学习率热身阶段,在开始的时候先使用一个较小的学习率,然后当训练过程稳定的时候再把学习率调回去。比如说在热身阶段,将学习率从0调到初始学习率。
余弦退火:按照余弦函数将学习速率从初始值降低到0。假设批次总数为T(忽略预热阶段),然后在批次t,学习率η_t 计算如下:
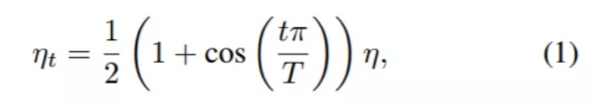
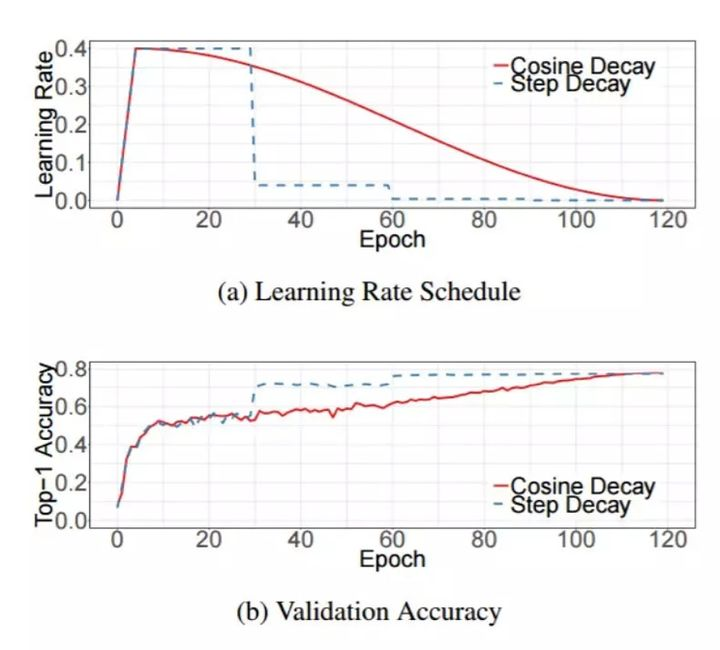
上图为warm up+余弦退火策略示意图。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









