







 本文介绍了LRU(最近最少使用)、LFU(最不经常使用)和FIFO(先进先出)缓存算法的区别,重点讲解了LRU在浏览器缓存和Memcached中的应用。通过自定义双向链表和哈希表实现LRU算法,包括节点操作、容量限制及get和put方法,最后展示了使用Java LinkedHashMap的简化实现。
本文介绍了LRU(最近最少使用)、LFU(最不经常使用)和FIFO(先进先出)缓存算法的区别,重点讲解了LRU在浏览器缓存和Memcached中的应用。通过自定义双向链表和哈希表实现LRU算法,包括节点操作、容量限制及get和put方法,最后展示了使用Java LinkedHashMap的简化实现。
常见的缓存算法
- LRU (Least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。
- LFU (Least frequently used) 最不经常使用,如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
- FIFO (Fist in first out) 先进先出, 如果一个数据最先进入缓存中,则应该最早淘汰掉。
LRU 算法介绍
题目链接:⼒扣第 146 题「LRU缓存机制」
题目分析:⾸先要接收⼀个 capacity 参数作为缓存的最⼤容量,然后实现两个 API,⼀个是 put(key, val) ⽅法存⼊键值对,另⼀个是 get(key) ⽅法获取 key 对应的 val,如果 key 不存在则返回 -1。注意这里的 get 和 put ⽅法必须都是 O(1) 的时间复杂度。
像浏览器的缓存策略、memcached的缓存策略都是使用LRU这个算法,LRU算法会将近期最不会访问的数据淘汰掉。LRU如此流行的原因是实现比较简单,而且对于实际问题也很实用,良好的运行时性能,命中率较高。下面谈谈如何实现LRU缓存:
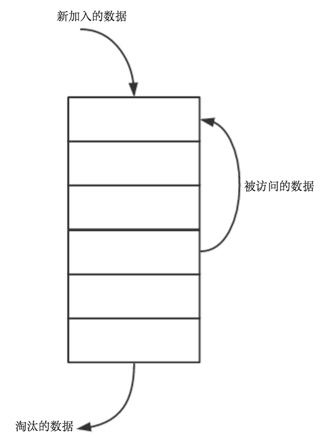
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
LRU Cache具备的操作:
set(key,value):- 如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;
- 若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
get(key):- 如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;
- 如果不存在,则返回-1。
LRU的Java实现
LRU 缓存算法的核⼼数据结构就是 双向链表 和 哈希表 的结合体。我们先⾃⼰造轮⼦实现⼀遍 LRU 算法,然后再使⽤ Java 内置的 LinkedHashMap 来实现⼀遍。
完全自己造轮子
前置准备
⾸先,我们把双链表的节点类写出来,为了简化,key 和 val 都认为是 int 类型:
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
然后依靠我们的 Node 类型构建⼀个双链表,实现⼏个 LRU 算法必须的 API:
class DoubleList {
// 头尾虚节点
private Node head, tail;
// 链表元素数
private int size;
public DoubleList() {
// 初始化双向链表的数据
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
// 在链表尾部添加节点 x,时间 O(1)
public void addLast(Node x) {
x.prev = tail.prev;
x.next = tail;
tail.prev.next = x;
tail.prev = x;
size++;
}
// 删除链表中的 x 节点(x ⼀定存在)
// 由于是双链表且给的是⽬标 Node 节点,时间 O(1)
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--;
}
// 删除链表中第⼀个节点,并返回该节点,时间 O(1)
public Node removeFirst() {
if (head.next == tail)
return null;
Node first = head.next;
remove(first);
return first;
}
// 返回链表⻓度,时间 O(1)
public int size() { return size; }
}
到这⾥就能回答刚才「为什么必须要⽤双向链表」的问题了,因为我们需要删除操作。删除⼀个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,⽽双向链表才能⽀持直接查找前驱,保证操作的时间复杂度 O(1)。
注意我们实现的双链表 API 只能从尾部插⼊,也就是说靠尾部的数据是最近使⽤的,靠头部的数据是最久为使⽤的。
有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可,先搭出代码框架:
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最⼤容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
}
再实现几个基本方法:
/* 将某个 key 提升为最近使⽤的 */
private void makeRecently(int key) {
Node x = map.get(key);
// 先从链表中删除这个节点
cache.remove(x);
// 重新插到队尾
cache.addLast(x);
}
/* 添加最近使⽤的元素 */
private void addRecently(int key, int val) {
Node x = new Node(key, val);
// 链表尾部就是最近使⽤的元素
cache.addLast(x);
// 别忘了在 map 中添加 key 的映射
map.put(key, x);
}
/* 删除某⼀个 key */
private void deleteKey(int key) {
Node x = map.get(key);
// 从链表中删除
cache.remove(x);
// 从 map 中删除
map.remove(key);
}
/* 删除最久未使⽤的元素 */
private void removeLeastRecently() {
// 链表头部的第⼀个元素就是最久未使⽤的
Node deletedNode = cache.removeFirst();
// 同时别忘了从 map 中删除它的 key
int deletedKey = deletedNode.key;
map.remove(deletedKey);
}
这⾥就能回答之前的问答题「为什么要在链表中同时存储 key 和 val,⽽不是只存储 val」,注意removeLeastRecently 函数中,我们需要⽤ deletedNode 得到 deletedKey。
也就是说,当缓存容量已满,我们不仅仅要删除最后⼀个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,⽽这个 key 只能由 Node 得到。如果 Node 结构中只存储 val,那么我们就⽆法得知 key 是什么,就⽆法删除 map 中的键,造成错误。
get() 方法
上述⽅法就是简单的操作封装,调⽤这些函数可以避免直接操作 cache 链表和 map 哈希表,下⾯我先来实现 LRU 算法的 get ⽅法:
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
// 将该数据提升为最近使⽤的
makeRecently(key);
return map.get(key).val;
}
put()方法
put ⽅法稍微复杂⼀些,我们先来画个图搞清楚它的逻辑:
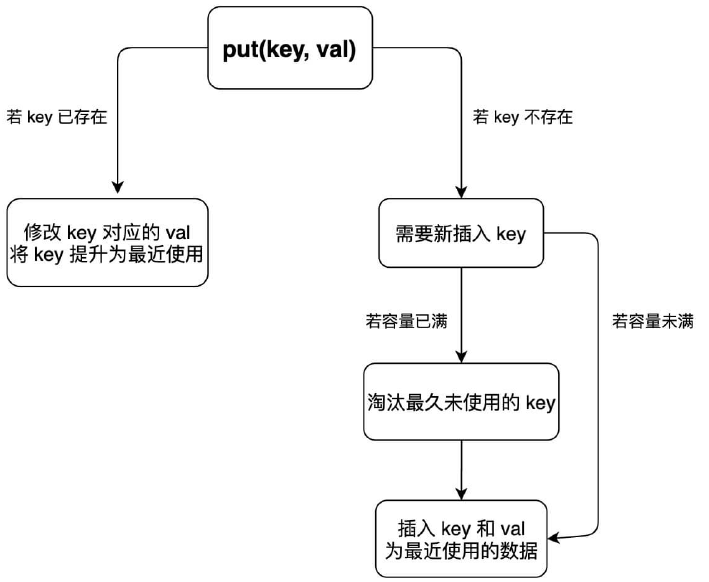
public void put(int key, int val) {
if (map.containsKey(key)) {
// 删除旧的数据
deleteKey(key);
// 新插⼊的数据为最近使⽤的数据
addRecently(key, val);
return;
}
if (cap == cache.size()) {
// 删除最久未使⽤的元素
removeLeastRecently();
}
// 添加为最近使⽤的元素
addRecently(key, val);
}
LinkedHashMap简化实现
⽤ Java 的内置类型 LinkedHashMap 来实现 LRU 算法,逻辑和之前完全⼀致:
class LRUCache {
int cap;
LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
// 将 key 变为最近使⽤
makeRecently(key);
return cache.get(key);
}
public void put(int key, int val) {
if (cache.containsKey(key)) {
// 修改 key 的值
cache.put(key, val);
// 将 key 变为最近使⽤
makeRecently(key);
return;
}
if (cache.size() >= this.cap) {
// 链表头部就是最久未使⽤的 key
int oldestKey = cache.keySet().iterator().next();
cache.remove(oldestKey);
}
// 将新的 key 添加链表尾部
cache.put(key, val);
}
private void makeRecently(int key) {
int val = cache.get(key);
// 删除 key,重新插⼊到队尾
cache.remove(key);
cache.put(key, val);
}
}


















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











