







Python爬虫实战笔记
文章目录
完整源码
# codeing = utf-8
# 引入模块
import urllib.request, urllib.error # 制定URL,获取网页数据
from bs4 import BeautifulSoup # 网页解析
import sqlite3 # 进行SQLite数据库操作
import xlwt # 进行excel操作
import re # 正则表达式
def main():
baseurl = 'https://movie.douban.com/top250?start=' # 设置基础网页链接
savepath = '.\\豆瓣电影Top250.xls' # 保存解析后数据的文件
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据
savaData(datalist,savepath)
# 全局变量
# 创建正则表达式对象(字符串模式),规则
# 影片详情链接规则
findLink = re.compile(r'<a href="(.*?)">')
# 影片图片链接规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S 让换行符包含在字符中
# 影片片名规则
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片评分规则
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 影片评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 影片概况规则
findInq = re.compile(r'<span class="inq">(.*)</span>')
# 影片相关内容规则
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
#print(html)
# 2.解析数据
soup = BeautifulSoup(html,"html.parser") # 设置解释器
for item in soup.find_all('div', class_='item'): # 查找符合要求的字符串,形成列表
#print(item)
data = []; # 保存一部电影的所有信息
item = str(item)
# 获取影片详情链接
link = re.findall(findLink, item)[0] # re库通过正则表达式查找指定字符串
data.append(link) # 添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) # 添加图片
titles = re.findall(findTitle,item) # 片名可能只有一个
if(len(titles) == 2): # 若存在其他名字
ctitle = titles[0]
data.append(ctitle) # 添加中文名
otitle = titles[1].replace("/","") # 去掉无关的符号
data.append(otitle) # 添加别名(外国名)
else: # 只有一个片名
data.append(titles[0]) # 添加中文名
data.append(" ") # 留空
rating = re.findall(findRating,item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge,item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","") # 去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") # 留空
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd) # 去掉<br/>
bd = re.sub('/'," ",bd) # 替换/
data.append(bd.strip()) # 添加相关信息 | .strip() 去掉前后空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器(这个是我们模拟的,伪装用)
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/94.0.4606.81 Safari/537.36'
}
# 合成请求报头
request = urllib.request.Request(url, headers=head)
html = ''
try:
# 发送请求
response = urllib.request.urlopen(request)
# 保存获取的网页源码
html = response.read().decode('utf-8')
except urllib.error.URLError as e: # 异常处理
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return html
# 保存数据
def savaData(datalist, savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True) # 创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概述","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) # 列名
for i in range(0,250):
print("第%d条"%(i+1))
data = datalist[i] # 第i 条电影
for j in range(0,8):
sheet.write(i+1, j, data[j])
book.save(savepath) # 保存
if __name__ == '__main__':
main()
准备工作
我们的目标是把豆瓣Top250 的影片信息爬取到到Excel 中。
目标网站
URL分析
我们可以看到它的链接是:https://movie.douban.com/top250
划到最下面,选择后页,再选择前页,我们就可以看到网页的参数列表:https://movie.douban.com/top250?start=0&filter=
参数有:start 和 filter(过滤器,这里没有值,所以其实是可以忽略的)
现在再点击后页,看到链接:https://movie.douban.com/top250?start=25&filter=
可以看到变化的是 start,从0 变成了25,现在我们就能明白,start参数是让榜单从 start+1 开始往后呈现,动动手把start 传入的值改为任意一个在0~249 内的数试试看效果吧。
最后,我们简化链接,明确只需要改变start 的值就可以了:https://movie.douban.com/top250?start=0
页面分析
- 访问我们分析后的URL,然后 右键查看页面源代码,按以下三步找到我们页面元素的位置

- 之后找到Network(网络),打开以下页面。
Headers
这个是我们给服务器发送的请求。
Response

这个是服务器响应我们请求的数据。
引入模块
# 引入模块
from bs4 import BeautifulSoup #网页解析
import re #正则表达式
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
如果写完出现红色波浪线说明这个模块你是没有安装的,可以按以下步骤安装。
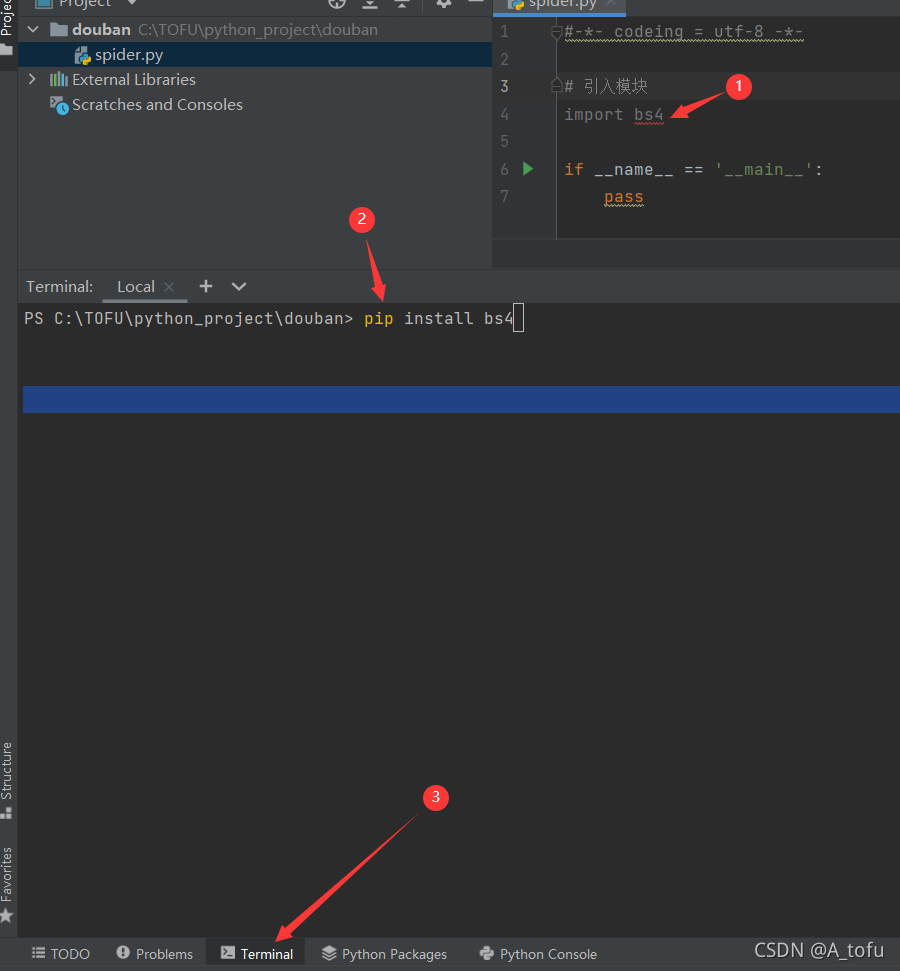
- 更新pip:
pip install --upgrade pip - 下载 bs4:
pip install bs4 - 下载xlwt:
pip install xlwt
获取数据
# codeing = utf-8
# 引入模块
import urllib.request, urllib.error # 制定URL,获取网页数据
from bs4 import BeautifulSoup # 网页解析
import sqlite3 # 进行SQLite数据库操作
import xlwt # 进行excel操作
import re # 正则表达式
def main():
baseurl = 'https://movie.douban.com/top250?start=' # 设置基础网页链接
savepath = '.\\豆瓣电影Top250.xls' # 保存解析后数据的文件
# 1.爬取网页
datalist = getData(baseurl)
# 3.保存数据
# savaData(datalist, savepath)
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
print(html)
# 2.解析数据
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器(这个是我们模拟的,伪装用)
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/94.0.4606.81 Safari/537.36'
}
# 合成请求报头
request = urllib.request.Request(url, headers=head)
html = ''
try:
# 发送请求
response = urllib.request.urlopen(request)
# 保存获取的网页源码
html = response.read().decode('utf-8')
except urllib.error.URLError as e: # 异常处理
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return html
# 保存数据
def savaData(datalist, savepath):
pass
if __name__ == '__main__':
main()
目前打印出来的就是所有 html数据,接下来我们来分析数据并解析。
解析内容
分析html
看看官方网页我们需要提取的 html标签:
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/>
</a>
</div>
<div class="info">
<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span content="10.0" property="v:best"></span>
<span>2472032人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
获取html
可以用:
# 2.解析数据
soup = BeautifulSoup(html,"html.parser") # 设置解释器
for item in soup.find_all('div', class_='item'): # 查找符合要求的字符串,形成列表
print(item)
来获取到它。
设置正则
接下来我们就可以循环拆解出来我们需要的内容,那么我们先把其他要获取的正则表达式规则都写出来:
# 全局变量
# 创建正则表达式对象(字符串模式),规则
# 影片详情链接规则
findLink = re.compile(r'<a href="(.*?)">')
# 影片图片链接规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S 让换行符包含在字符中
# 影片片名规则
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片评分规则
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 影片评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 影片概况规则
findInq = re.compile(r'<span class="inq">(.*)</span>')
# 影片相关内容规则
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
正则解析数据
然后将解析数据的代码完善好:
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
#print(html)
# 2.解析数据
soup = BeautifulSoup(html,"html.parser") # 设置解释器
for item in soup.find_all('div', class_='item'): # 查找符合要求的字符串,形成列表
#print(item)
data = []; # 保存一部电影的所有信息
item = str(item)
# 获取影片详情链接
link = re.findall(findLink, item)[0] # re库通过正则表达式查找指定字符串
data.append(link) # 添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) # 添加图片
titles = re.findall(findTitle,item) # 片名可能只有一个
if(len(titles) == 2): # 若存在其他名字
ctitle = titles[0]
data.append(ctitle) # 添加中文名
otitle = titles[1].replace("/","") # 去掉无关的符号
data.append(otitle) # 添加别名(外国名)
else: # 只有一个片名
data.append(titles[0]) # 添加中文名
data.append(" ") # 留空
rating = re.findall(findRating,item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge,item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","") # 去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") # 留空
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd) # 去掉<br/>
bd = re.sub('/'," ",bd) # 替换/
data.append(bd.strip()) # 添加相关信息 | .strip() 去掉前后空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
return datalist
数据演示
获取到的数据datalist 大致为:(列表内包含列表)
[['https://movie.douban.com/subject/1292052/', 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg', '肖申克的救赎', '\xa0\xa0The Shawshank Redemption', '9.7', '2475783', '希望让人自由', '导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins ... 1994\xa0 \xa0美国\xa0 \xa0犯罪 剧情'], ['https://movie.douban.com/subject/1291546/', 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg', '霸王别姬', ' ', '9.6', '1840336', '风华绝代', '导演: 陈凯歌 Kaige Chen\xa0\xa0\xa0主演: 张国荣 Leslie Cheung 张丰毅 Fengyi Zha... 1993\xa0 \xa0中国大陆 中国香港\xa0 \xa0剧情 爱情 同性']]
保存数据
下面我们来把我们爬取到的数据保存到Excel 中。
# 保存数据
def savaData(datalist, savepath):
print("save...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True) # 创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概述","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) # 列名
for i in range(0,250):
print("第%d条" %i)
data = datalist[i] # 第i 条电影
for j in range(0,8):
sheet.write(i+1, j, data[j])
book.save(savepath) # 保存
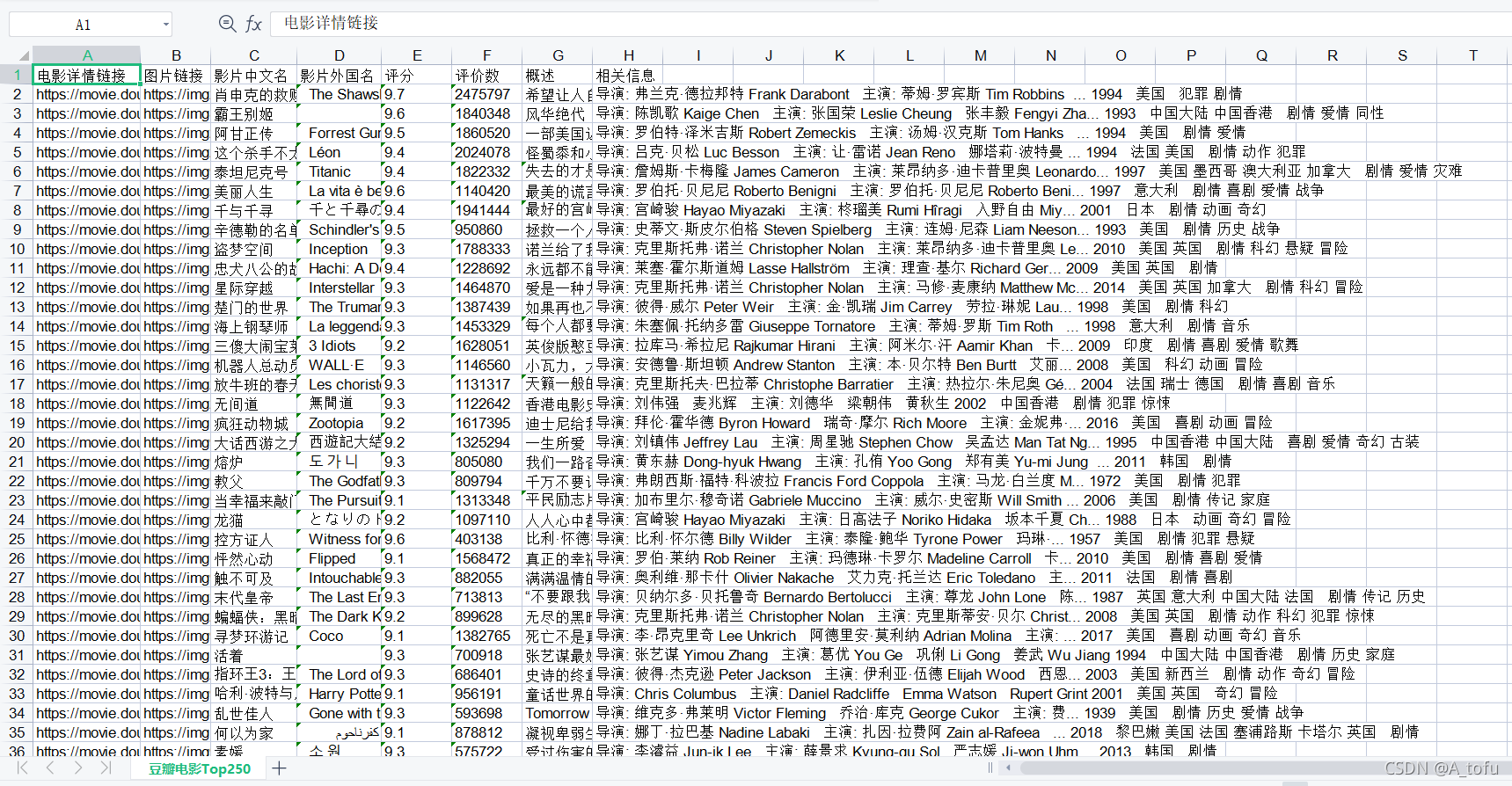
效果展示
最后程序运行后得到豆瓣电影Top250.xls,效果如下:















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









