







OpenAI刚刚发布了GPT-4.1,这是一系列专为开发者打造的新模型。我和大家一样,对GPT-4.5跳到GPT-4.1的命名变化感到困惑,但值得庆幸的是,基准测试并没有回退——相反,进展显著。
GPT-4.1分为三个版本:GPT-4.1、GPT-4.1 Mini和GPT-4.1 Nano。三者都支持最多100万的上下文标记,并在编码、指令执行和长上下文理解方面带来了显著提升。它们的速度更快、成本更低,优于之前的版本。
在这篇文章中,我将为您介绍每个模型的功能,它与GPT-4o和GPT-4.5的比较,以及在基准测试和实际应用中的表现。


🚀AIO通用智能(AGI)服务平台
GPT-4.1是什么?
GPT-4.1模型系列由三个模型组成:GPT-4.1、GPT-4.1 Mini和GPT-4.1 Nano。它们都是仅提供API的版本,旨在满足需要更好性能、更长上下文和更可预测指令执行的开发者需求。每个模型支持最多100万个上下文标记,这相比于之前版本(如GPT-4o)中的12万个标记是一个巨大的飞跃。
尽管架构相同,每个版本针对不同的使用场景进行了调优。下面是每个模型的特点。
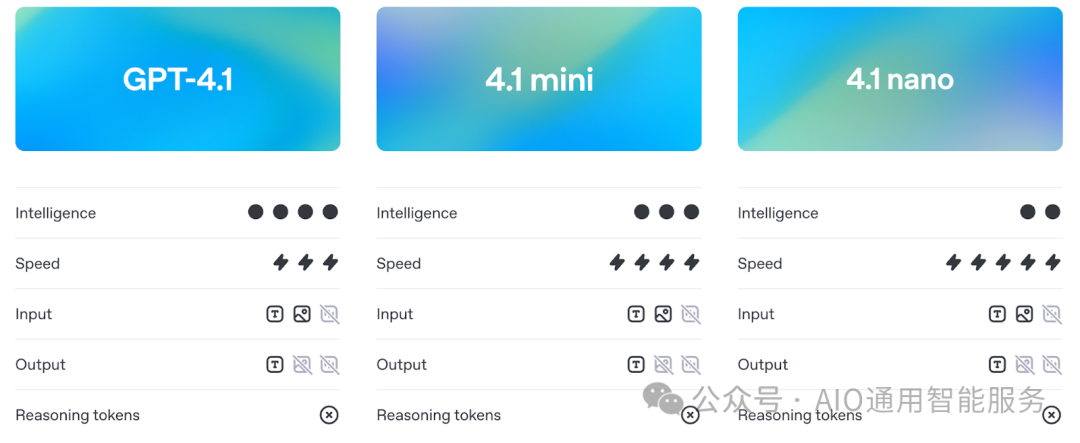
GPT-4.1
这是旗舰模型。如果您希望在编码、指令执行和长上下文任务中获得最佳整体性能,这个模型就是您的首选。它旨在处理复杂的编码工作流程或在单个提示中处理大型文档。
在基准测试中,它在实际软件工程(SWE-bench)、指令执行(MultiChallenge)和长上下文推理(MRCR、Graphwalks)方面超越了GPT-4o。同时,它在遵循结构和格式方面的表现也显著提升——例如处理XML响应、有序指令以及像“除非……否则不回答”的负约束。
自发布之日起,您也可以对GPT-4.1进行微调,这使其能够满足对语气、格式或领域知识有控制要求的更多生产用例。
GPT-4.1 Mini
GPT-4.1 Mini是中端选项,提供与完整模型几乎相同的功能,但延迟和成本更低。在许多基准测试中,它的表现与GPT-4o相当或更优,包括指令执行和基于图像的推理。
它很可能成为许多用例的默认选择:速度足够快以适应交互式工具,智慧足够以跟随详细指令,并且比完整模型显著便宜。
与完整版本一样,它支持100万个上下文标记,并已可进行微调。
GPT-4.1 Nano
Nano是这三者中最小、最快且最便宜的模型。它专为自动补全、分类和从大型文档中提取信息等任务而设计。尽管体积小巧,它仍支持完整100万个标记的上下文窗口。
它也是OpenAI迄今为止最小、最快、最便宜的模型,每百万个标记的费用仅约为10美分。虽然您无法获得更大模型的完整推理和计划能力,但对于某些任务来说,这并不是重点。微调支持很快就会推出。
GPT-4.1 与 GPT-4o 及 GPT-4.5 比较
在我们开始讨论基准测试(将在下一节详细介绍)之前,了解 GPT-4.1 在实际应用中如何与 GPT-4o 和 GPT-4.5 不同是很有必要的。
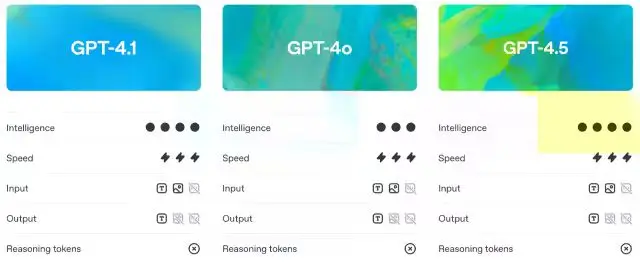
比 GPT-4o 更聪明,比 GPT-4.5 更实用
GPT-4.1 在保留大致相同延迟的情况下,提升了 GPT-4o 的能力。实际上,这意味着开发者可以在响应速度未受影响的情况下,获得更好的性能。
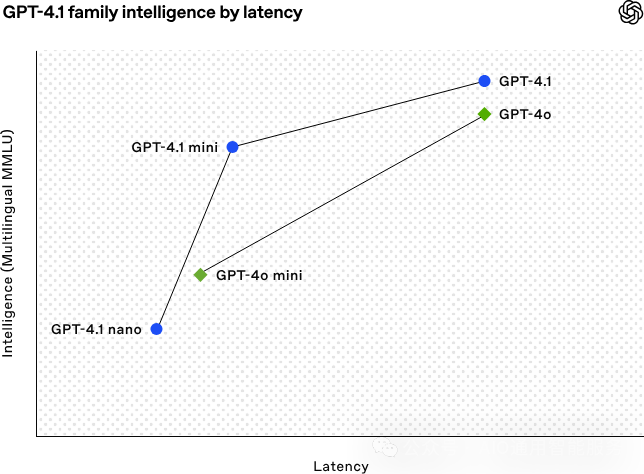
让我们来分析上面的图表:
-
GPT-4.1 和 GPT-4o 在延迟上大致处于同一水平,但 GPT-4.1 在智能上更为出色。因此,你将以类似的速度获得一个更聪明(且更便宜)的模型。
-
GPT-4.1 Mini 的能力也超过了 GPT-4o Mini,但这种提升伴随着轻微的折衷:延迟有了小幅增加。
-
GPT-4.1 Nano 在速度上明显领先,图表中位于最左侧。尽管在 MMLU 上表现不如其他模型,但这是可以预料的——它是为轻量级任务设计的,更注重速度而非复杂推理。
另一方面,GPT-4.5 一直被定位为研究预览。尽管它在推理和写作质量上表现强劲,但它的开销也更大。相比之下,GPT-4.1 在关键基准测试中提供类似或更好的结果,却更加便宜和响应迅速——因此 OpenAI 计划在 7 月中旬之前完全退役 GPT-4.5,以腾出更多 GPU。
100 万个 Token 的上下文
所有三种 GPT-4.1 模型——标准版、Mini 版和 Nano 版——都支持高达 100 万个 Token 的上下文。这比 GPT-4o 提供的上下文多出 8 倍以上。
这种长上下文容量使得实际应用场景如处理完整日志、索引代码库、处理多文档法律工作流程或分析长篇成绩单成为可能——这一切都无需事先将内容拆分或总结。
更好的指令遵循能力
GPT-4.1 也标志着模型遵循指令的可靠性发生了变化。它能够处理涉及有序步骤、格式约束和否定条件(如在格式错误时拒绝回答)的复杂提示。
在实践中,这意味着两点:减少了构思提示所花费的时间,以及减少了事后清理输出的时间。
GPT-4.1 基准测试
GPT-4.1 在四个核心领域取得了进展:编码、指令遵循、长上下文理解和多模态任务。
编码性能
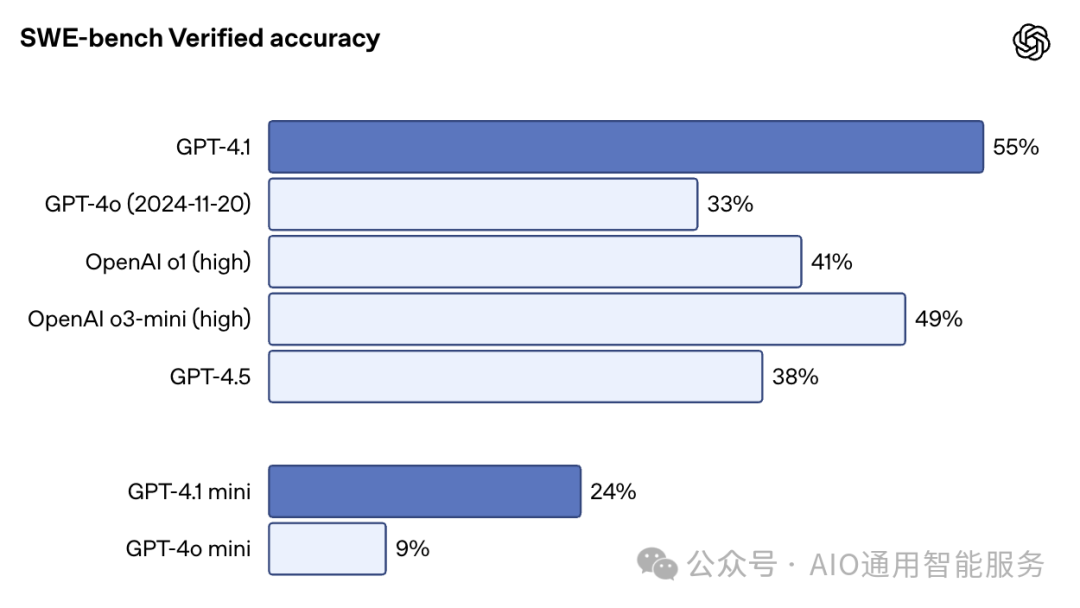
在 SWE-bench Verified 的基准测试中,该测试将模型置于真实代码库中,要求其完成从头到尾的问题,GPT-4.1 的得分为 54.6%。这一成绩较 GPT-4o 的 33.2% 和 GPT-4.5 的 38% 有了显著提升。值得一提的是,GPT-4.1 的得分甚至高于 o1 和 o3-mini。
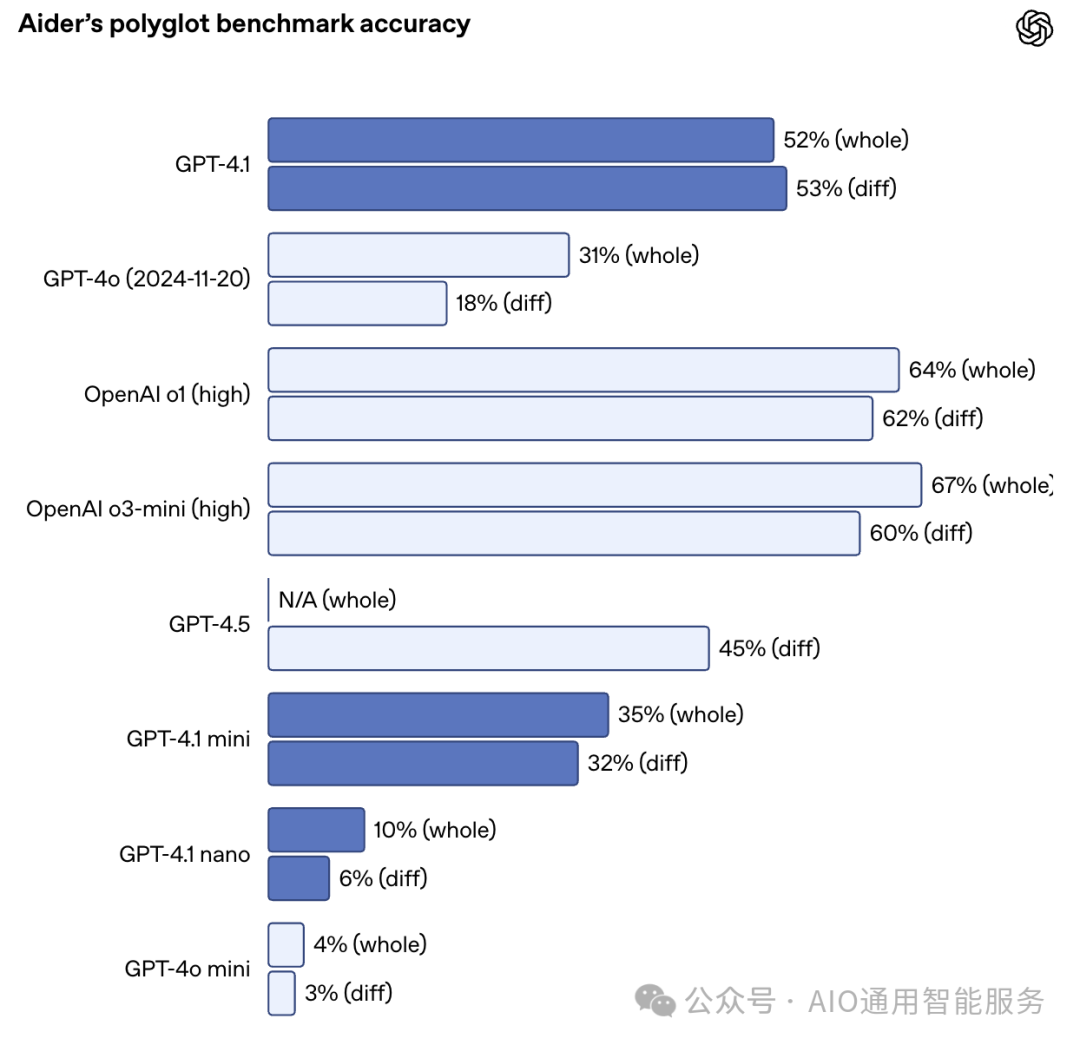
在 Aider 的多语言 diff 基准测试中,GPT-4.1 的表现也超过了 GPT-4o,达到了 52.9% 的准确率,超越了多种语言和格式的代码差异。相比之下,GPT-4.5 在同一任务上的得分为 44.9%。此外,GPT-4.1 的精确度更高:在内部评估中,冗余代码编辑的比例从 GPT-4o 的 9% 降至仅 2%。
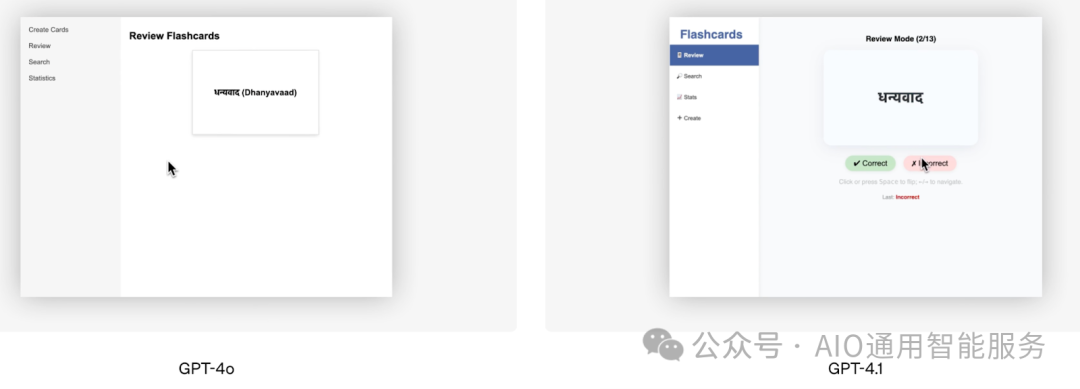
除了基准分数,OpenAI 提供的前端编码演示也很好地展示了 GPT-4.1 的出色性能。OpenAI 的团队要求这两个模型构建相同的抽认卡应用程序,人工评审者在 80% 的情况下更喜欢 GPT-4.1 的输出。
作为 alpha 测试者之一的 Windsurf 报告称,他们自己的内部编码基准测试性能提高了 60%。另一家公司 Qodo 在真实的 GitHub pull requests 上测试 GPT-4.1,发现其建议的改进率达 55%,并且冗余或过于冗长的编辑更少。
指令遵循
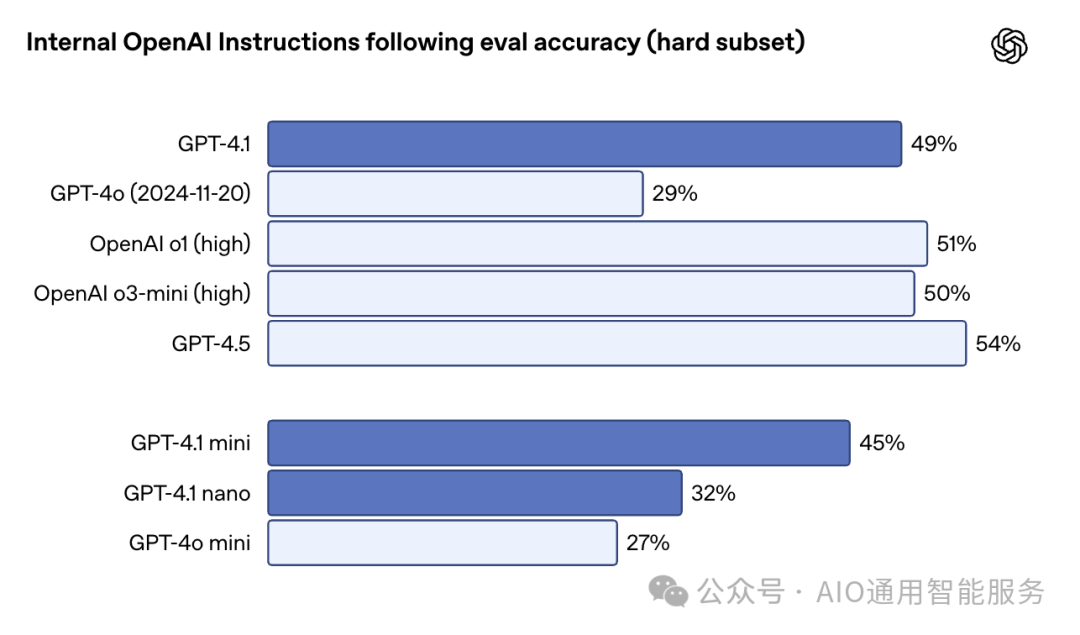
在遵循指令方面,GPT-4.1 更加字面化且更可靠,尤其是在涉及多个步骤、格式规则或条件的任务上。在 OpenAI 的内部指令遵循评估中(困难子集),GPT-4.1 的得分为 49.1%,相比之下,GPT-4o 仅为 29.2%。GPT-4.5 在这里稍微领先,得分为 54%,但 GPT-4.1 和 GPT-4o 之间的差距显著。
在 MultiChallenge 测试中,该测试评估模型是否能够遵循多轮指令,并记住在谈话中引入的约束,GPT-4.1 的得分为 38.3%,较 GPT-4o 的 27.8% 有所提升。而在 IFEval 测试中,该测试评估是否遵循明确规定的输出要求,GPT-4.1 的得分达到 87.4%,较 GPT-4o 的 81% 也有了稳步提升。
具体而言,这意味着 GPT-4.1 更擅长遵循有序步骤、拒绝错误格式的输入,并按照请求的格式作出反应——尤其是在 XML、YAML 或 Markdown 等结构化输出中。这也使得构建可靠的代理工作流程变得更容易,而无需多次尝试提示。
长上下文推理
所有三种 GPT-4.1 模型——标准版、Mini 版和 Nano 版——都支持高达 100 万个 Token 的上下文。这比 GPT-4o 多了 8 倍,后者的上限为 128K。同样重要的是,使用该上下文窗口并没有额外费用,其定价与其他提示相同。
但这些模型真的能利用所有这些上下文吗?在 OpenAI 的“针在干草堆”评估中,GPT-4.1 能够可靠地找到插入的内容,无论是位于输入的开始、中间还是结束,均能在完整的 1M Token 输入中进行识别。
Graphwalks 作为一个测试长上下文多跳推理的基准,GPT-4.1 的得分为 61.7%,较 GPT-4o 的 41.7% 有了显著提升,尽管仍低于 GPT-4.5 的 72.3%。
这些改进在现实世界测试中也得到了体现。汤森路透报告使用 GPT-4.1 进行多文档法律分析时提升了 17%,而卡莱尔则报告在从密集的财务报告中提取细粒度数据时提高了 50%。
多模态和视觉任务
在多模态任务上,GPT-4.1 同样取得了进展。在 Video-MME 基准测试中(该测试涉及回答关于 30-60 分钟无字幕视频的问题),GPT-4.1 的得分为 72.0%,而 GPT-4o 则为 65.3%。
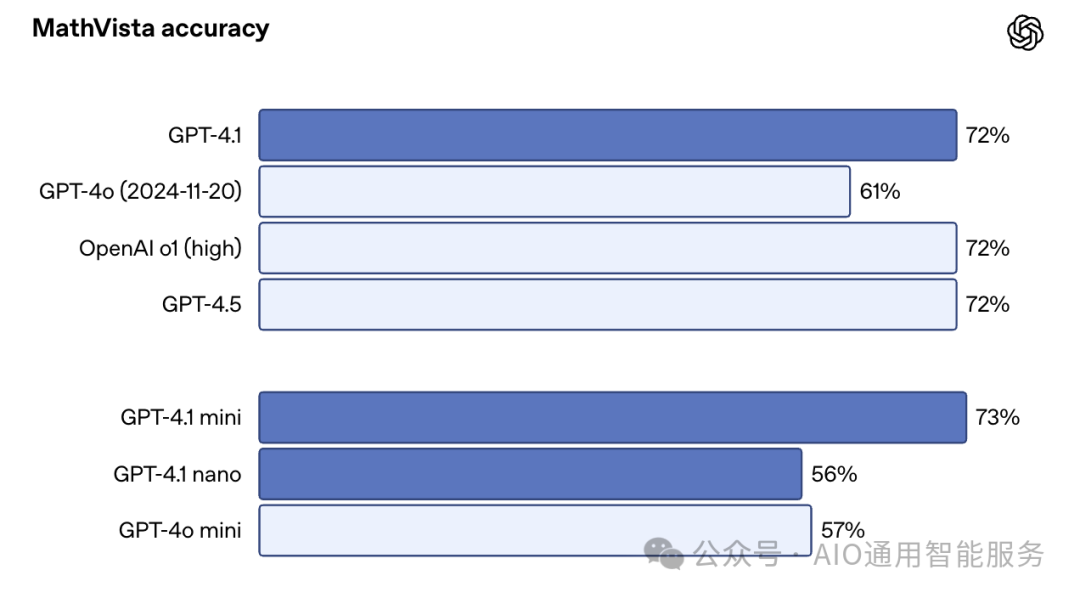
在像 MMMU 这样的图像重型基准中,GPT-4.1 达到了 74.8%,而 GPT-4o 为 68.7%。在 MathVista 测试中,包含图表、图形和数学视觉元素,GPT-4.1 的得分为 72.2%。
一个惊喜是:在一些基准测试中,GPT-4.1 Mini 的表现几乎与完整版相当。例如在 MathVista 测试中,它的得分为 73.1%,略高于 GPT-4.1。这使得它成为结合速度和图像重型提示的用例中的吸引人选择。
如何访问 GPT-4.1
您无法通过常规聊天应用程序访问 GPT-4.1、GPT-4.1 Mini 和 GPT-4.1 Nano。这些模型专为开发者设计,您只能通过 OpenAI API 进行访问。
探索这些模型的默认方式是通过 OpenAI Playground,现在已支持这三种变体。在此,您可以对系统提示进行迭代,测试多步骤输出,并查看每个模型如何处理长文档或结构化输入,然后再将其集成到生产环境中。
如果您正在处理长文档——比如日志、PDF、法律记录或学术文章——您可以在一次调用中发送多达 100 万个 Token,无需特殊参数。长上下文的定价也没有额外费用:无论输入大小,Token 成本都是统一的。
微调 GPT-4.1
您已经可以对 GPT-4.1 和 GPT-4.1 Mini 进行微调。这为自定义指令、特定领域词汇或特定语气的输出打开了大门。请注意,微调的价格略有增加(截至 2025 年 4 月 15 日):
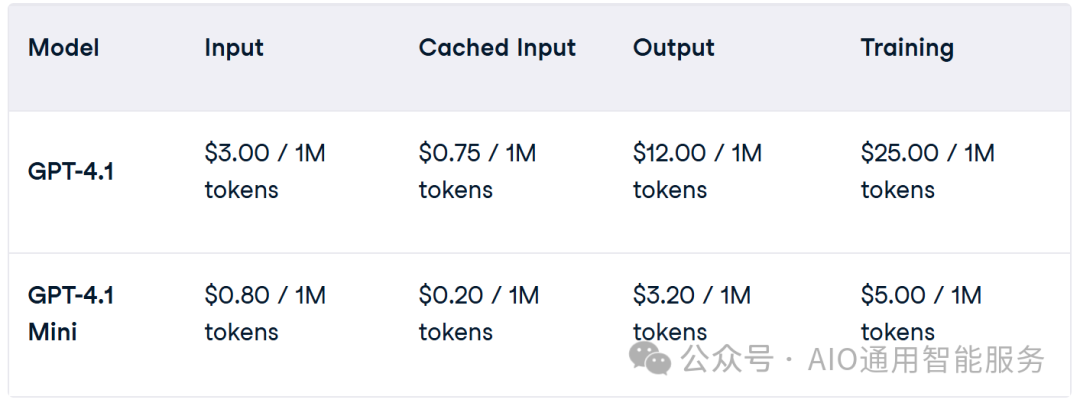
Nano 目前还不能进行微调,但 OpenAI 表示这项功能即将推出。如果您之前对 GPT-3.5 或 GPT-4 模型进行了微调,流程大致相同——只需选择更新的基础模型。如果想了解更多,我推荐您查看有关微调 GPT-4o Mini 的教程。
GPT-4.1 定价
GPT-4.1 的一项令人欢迎的更新是,它不仅更聪明,而且更便宜。OpenAI 表示,目标是使这些模型在更多实际工作流程中更具用户友好性,这在定价结构上得以体现。
以下是三种模型的推理定价(截至 2025 年 4 月 15 日):
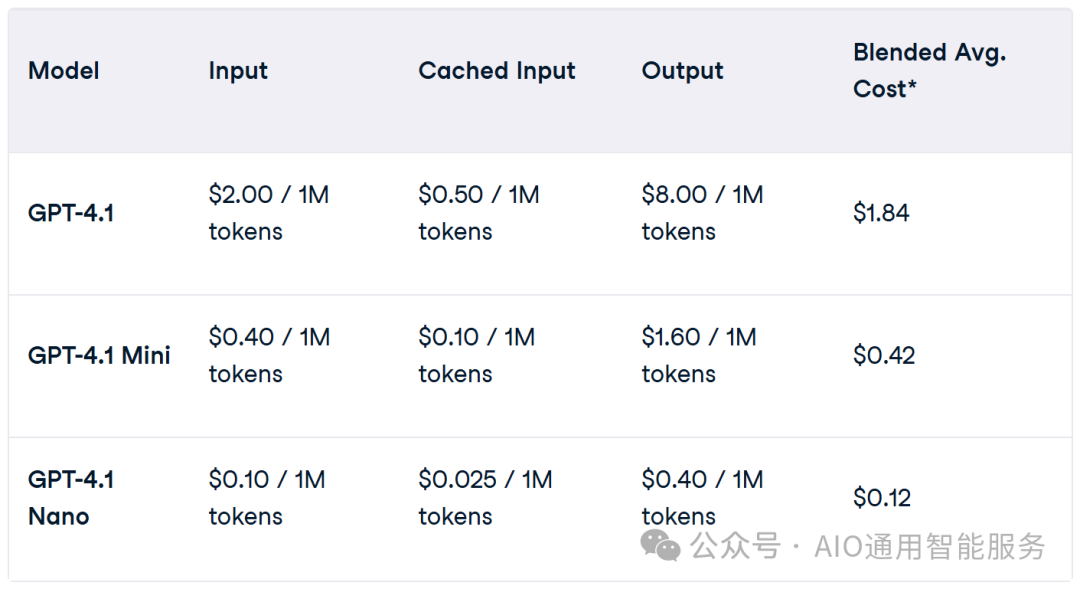
“blended”数值是基于 OpenAI 对典型输入/输出比率的假设。
总结
您无法通过常规聊天应用程序访问 GPT-4.1、GPT-4.1 Mini 和 GPT-4.1 Nano。这些模型专为开发者设计,您只能通过 OpenAI API 进行访问。
探索这些模型的默认方式是通过 OpenAI Playground,现在已支持这三种变体。在此,您可以对系统提示进行迭代,测试多步骤输出,并查看每个模型如何处理长文档或结构化输入,然后再将其集成到生产环境中。
如果您正在处理长文档——比如日志、PDF、法律记录或学术文章——您可以在一次调用中发送多达 100 万个 Token,无需特殊参数。长上下文的定价也没有额外费用:无论输入大小,Token 成本都是统一的。
微调 GPT-4.1
您已经可以对 GPT-4.1 和 GPT-4.1 Mini 进行微调。这为自定义指令、特定领域词汇或特定语气的输出打开了大门。请注意,微调的价格略有增加(截至 2025 年 4 月 15 日):
Nano 目前还不能进行微调,但 OpenAI 表示这项功能即将推出。如果您之前对 GPT-3.5 或 GPT-4 模型进行了微调,流程大致相同——只需选择更新的基础模型。如果想了解更多,我推荐您查看有关微调 GPT-4o Mini 的教程。
GPT-4.1 定价
GPT-4.1 的一项令人欢迎的更新是,它不仅更聪明,而且更便宜。OpenAI 表示,目标是使这些模型在更多实际工作流程中更具用户友好性,这在定价结构上得以体现。
以下是三种模型的推理定价(截至 2025 年 4 月 15 日):
“blended”数值是基于 OpenAI 对典型输入/输出比率的假设。
GPT-4.1 提供了更可靠的代码生成、更好的指令遵循能力、真正的长上下文处理和更快的迭代速度。
虽然命名可能会让人感到困惑,且发布时仅限于 API,这是故意设计的,但这些模型显然比之前的版本更强大。同时,它们的价格也更可负担,尤其是在对延迟、成本和可预测性有要求的生产环境中,更加实用。
探索智能边界,发现无限可能!(AIOAGI.TECH)


















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









