






今天的任务是线性神经网络,记得大学的时候还手写过,关键内容就是梯度下降和反向传播的概念。而对于线性神经网络没有复杂的结构,本质上还是pytorch 的学习和使用。
梯度下降的原理
梯度下降是一种常见的优化算法,用于在机器学习和深度学习中最小化成本函数或损失函数。其核心原理是通过不断迭代来调整模型参数,以使损失函数值最小化。
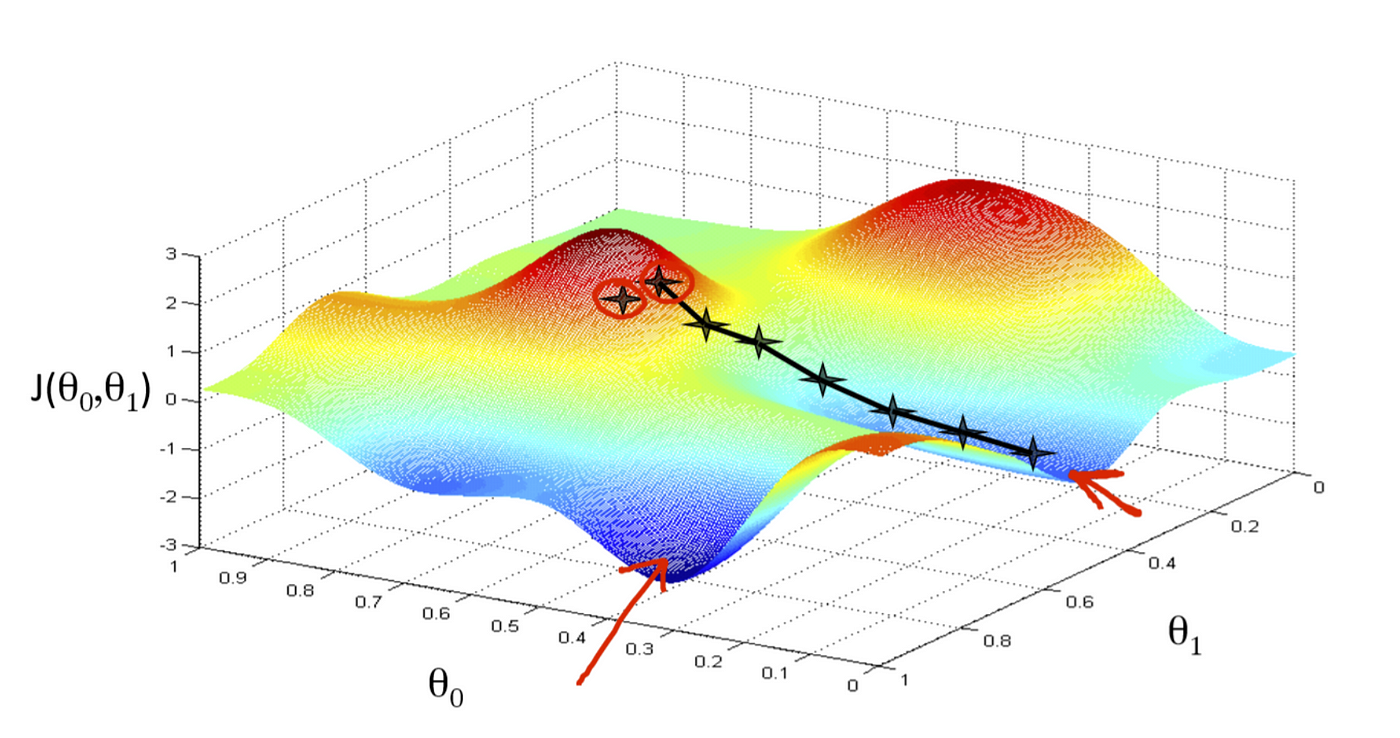
具体来说,梯度下降的过程是从一个随机的初始点开始,计算损失函数在该点的梯度(即函数在该点处的斜率),然后沿着梯度的反方向更新参数,以使函数值下降。通过不断重复上述步骤,直到损失函数值收敛或达到预定的停止条件为止,从而得到最优的参数值。要注意的是,学习率的选择非常重要,过大的学习率会导致每次更新步长过大,可能会导致算法不稳定,甚至不能收敛;而过小的学习率则会使算法收敛速度缓慢。
关于反向传播
反向传播(Backpropagation)是一种用于训练神经网络的优化算法,其核心原理是通过计算网络输出与真实值之间的误差,并将误差沿着网络反向传播,从而更新网络的权重和偏置。
反向传播算法可以分为两个阶段,前向传播和反向传播。
- 在前向传播阶段,输入数据经过网络的各个层进行加权求和和激活处理,最终得到网络的输出结果。
- 在反向传播阶段,首先需要计算输出结果与真实值之间的误差,常用的损失函数包括均方误差和交叉熵等。然后,误差沿着网络反向传播,通过链式法则计算每个权重和偏置对误差的贡献,最终更新网络的参数。
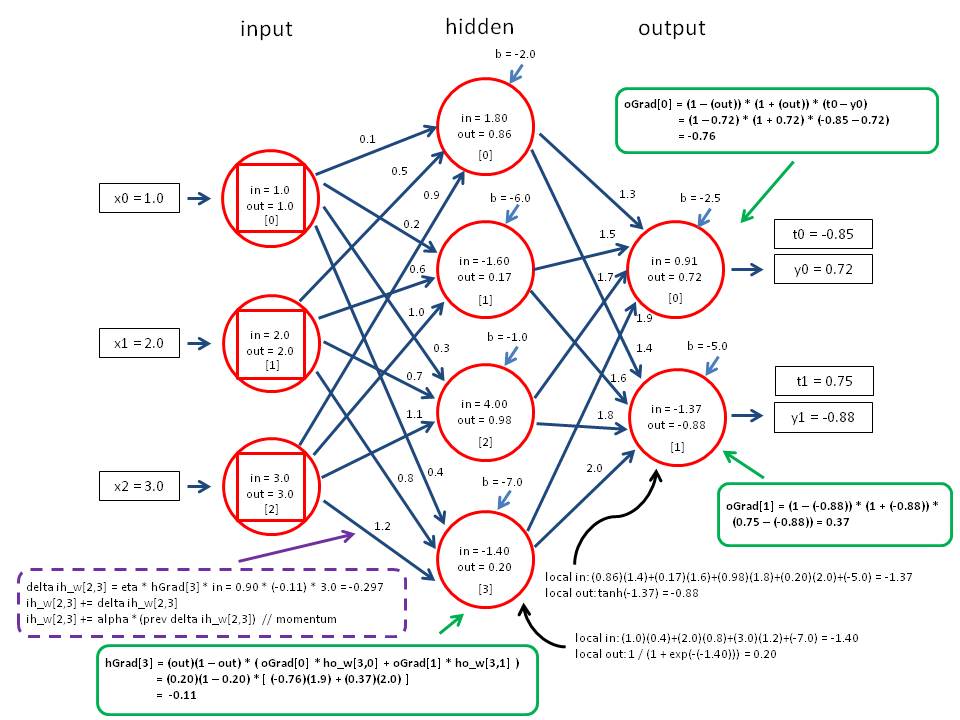
反向传播算法的优化方法有多种,例如随机梯度下降、批量梯度下降和小批量梯度下降等,它们的区别在于每次更新时使用的样本数量不同。
代码笔记
简单的线性神经网络
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=42)
X = torch.from_numpy(X).float() # 转为 tensor 类型
y = torch.from_numpy(y).float().view(-1, 1) # 转为 tensor 类型并将 y 的形状变为 (batch_size, 1)
# 定义神经网络模型
class LinearNet(nn.Module):
def __init__(self):
super(LinearNet, self).__init__()
self.fc1 = nn.Linear(4, 10) # 第一层全连接层,输入大小为 4,输出大小为 10
self.fc2 = nn.Linear(10, 1) # 第二层全连接层,输入大小为 10,输出大小为 1
self.sigmoid = nn.Sigmoid() # sigmoid 激活函数
def forward(self, x):
x = self.fc1(x)
x = self.sigmoid(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x
# 实例化模型、定义损失函数和优化器
model = LinearNet()
criterion = nn.BCELoss() # 二分类交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 随机梯度下降优化器
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X)
loss = criterion(outputs, y)
# 反向传播和优化
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印损失值
if (epoch+1) % 100 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# 可视化结果
with torch.no_grad():
outputs = model(X)
predicted = (outputs >= 0.5).float()
accuracy = (predicted == y).float().mean()
print('Accuracy: {:.2f}%'.format(accuracy * 100))
plt.scatter(X[:, 0], X[:, 1], c=predicted.squeeze().detach().numpy())
plt.title('Linear Classification')
plt.show()
最基础的softmax回归的实现
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=42)
X = torch.from_numpy(X).float() # 转为 tensor 类型
y = torch.from_numpy(y).long() # 转为 tensor 类型
# 定义神经网络模型
class SoftmaxNet(nn.Module):
def __init__(self):
super(SoftmaxNet, self).__init__()
self.fc = nn.Linear(4, 3) # 全连接层,输入大小为 4,输出大小为 3
def forward(self, x):
x = self.fc(x)
x = nn.functional.softmax(x, dim=1) # softmax 激活函数
return x
# 实例化模型、定义损失函数和优化器
model = SoftmaxNet()
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 随机梯度下降优化器
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X)
loss = criterion(outputs, y)
# 反向传播和优化
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印损失值
if (epoch+1) % 100 == 0:
_, predicted = torch.max(outputs.data, 1)
correct = (predicted == y).sum().item()
accuracy = correct / len(y)
print('Epoch [{}/{}], Loss: {:.4f}, Accuracy: {:.2f}%'.format(epoch+1, num_epochs, loss.item(), accuracy*100))
# 可视化结果
with torch.no_grad():
outputs = model(X)
_, predicted = torch.max(outputs.data, 1)
plt.scatter(X[:, 0], X[:, 1], c=predicted.numpy())
plt.title('Softmax Regression')
plt.show()


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









