









B-树
前面我们已经学习了二叉查找树、2-3树以及它的实现红黑树。2-3树中,一个结点做多能有两个key,它的实现红 黑树中使用对链接染色的方式去表达这两个key。接下来我们学习另外一种树型结构B树,这种数据结构中,一个结点允许多于两个key的存在。
B树是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(logn)的时间复杂度进行查找、顺序读取、插入和删除等操作。
1 定义
用阶定义B树
B树中允许一个结点中包含多个key,可以是3个、4个、5个甚至更多,并不确定,需要看具体的实现。现在我们选 择一个参数M,来构造一个B树,我们可以把它称作是M阶的B树,
- 根节点至少有两个孩子
- 每个非根节点至少有M/2(上取整)个孩子,至多有M个孩子。
- 每个非根节点至少有M/2-1(上取整)个key,至多有M-1个key。并以升序排列。
- key[i]和key[i+1]之间的孩子节点的值介于key[i]和key[i+1]之间。
- 所有的叶子节点都在同一层。
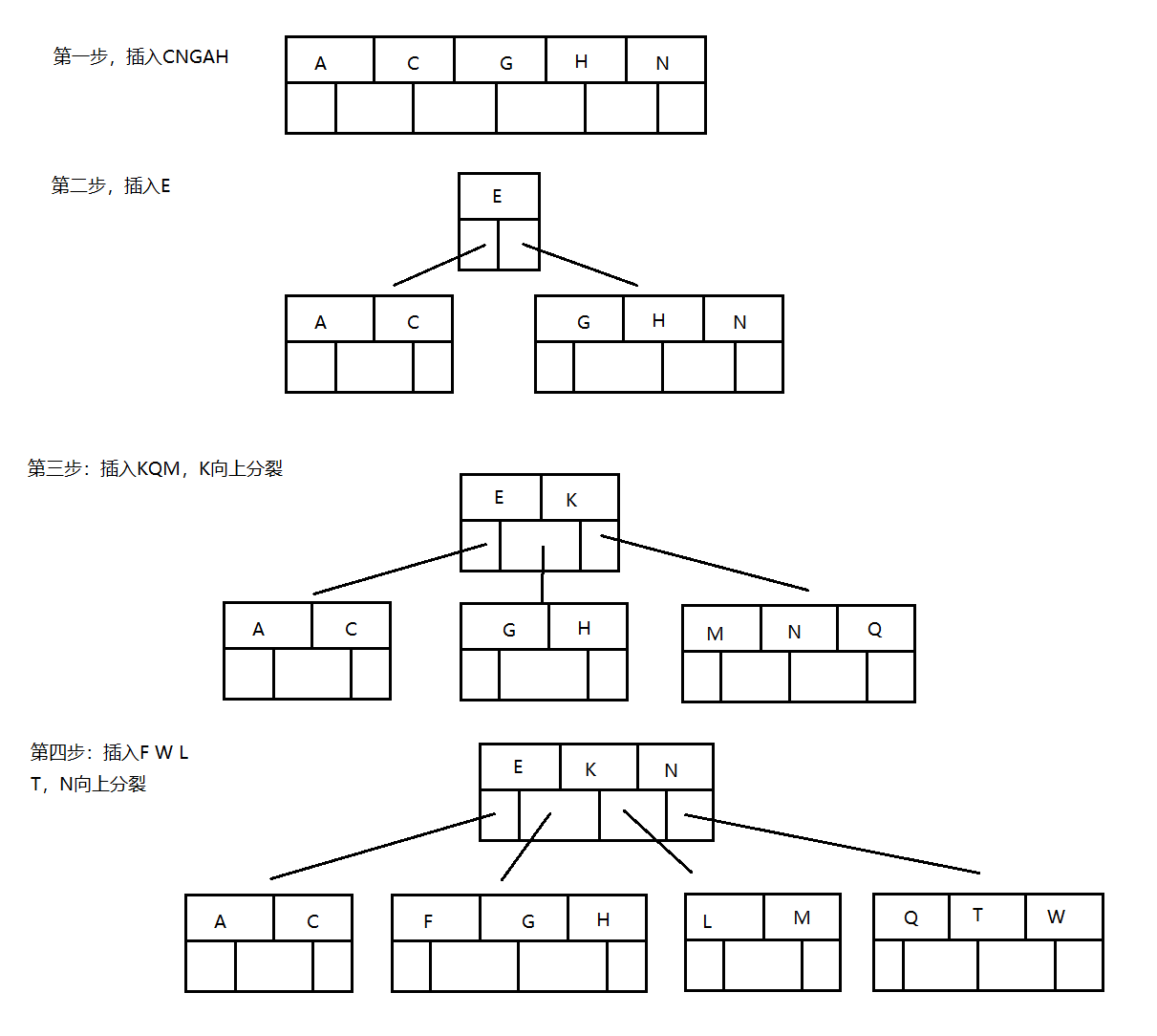
在实际应用中B树的阶数一般都比较大(通常大于100),所以,即使存储大量的数据,B树的高度仍然比较小,这样在某些应用场景下,就可以体现出它的优势。
用度定义B树
针对上面的5点,再阐述下:B树中每一个结点能包含的关键字(如之前上面的D H和Q T X)数有一个上界和下界。这个下界可以用一个称作B树的最小度数(算法导论中文版上译作度数,最小度数即内节点中节点最小孩子数目)t(t>=2)表示。
- 每个非根的内结点至少有t个子女,每个非根的结点必须至少含有t-1个关键字,如果树是非空的,则根结点至少包含一个关键字;
- 每个结点可包含至多2t-1个关键字。所以一个内结点至多可有2t个子女。如果一个结点恰好有2t-1个关键字,我们就说这个结点是满的
t度 的B树就是 2t阶 的B树 t=2m
因为t度的B树节点最多有2t个孩子,2t-1个关键字;m阶的B树最多有m个孩子,m-1个关键字
用度定义B树,分割会先提出了t−1处的结点
2 B树存储数据
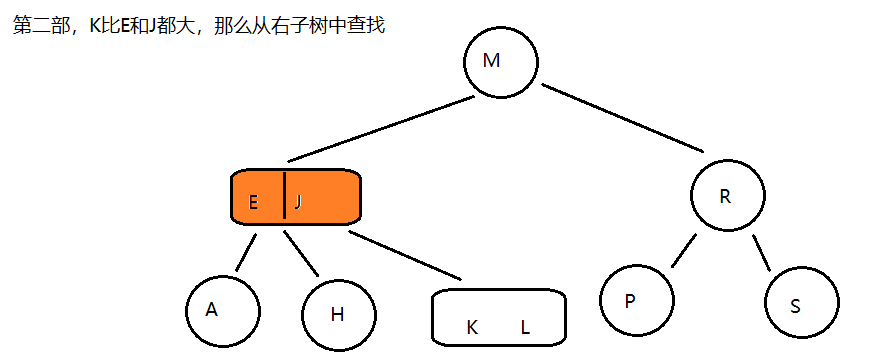
若参数M选择为5,那么每个结点最多包含4个键值对,我们以5阶B树为例,看看B树的数据存储
插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例
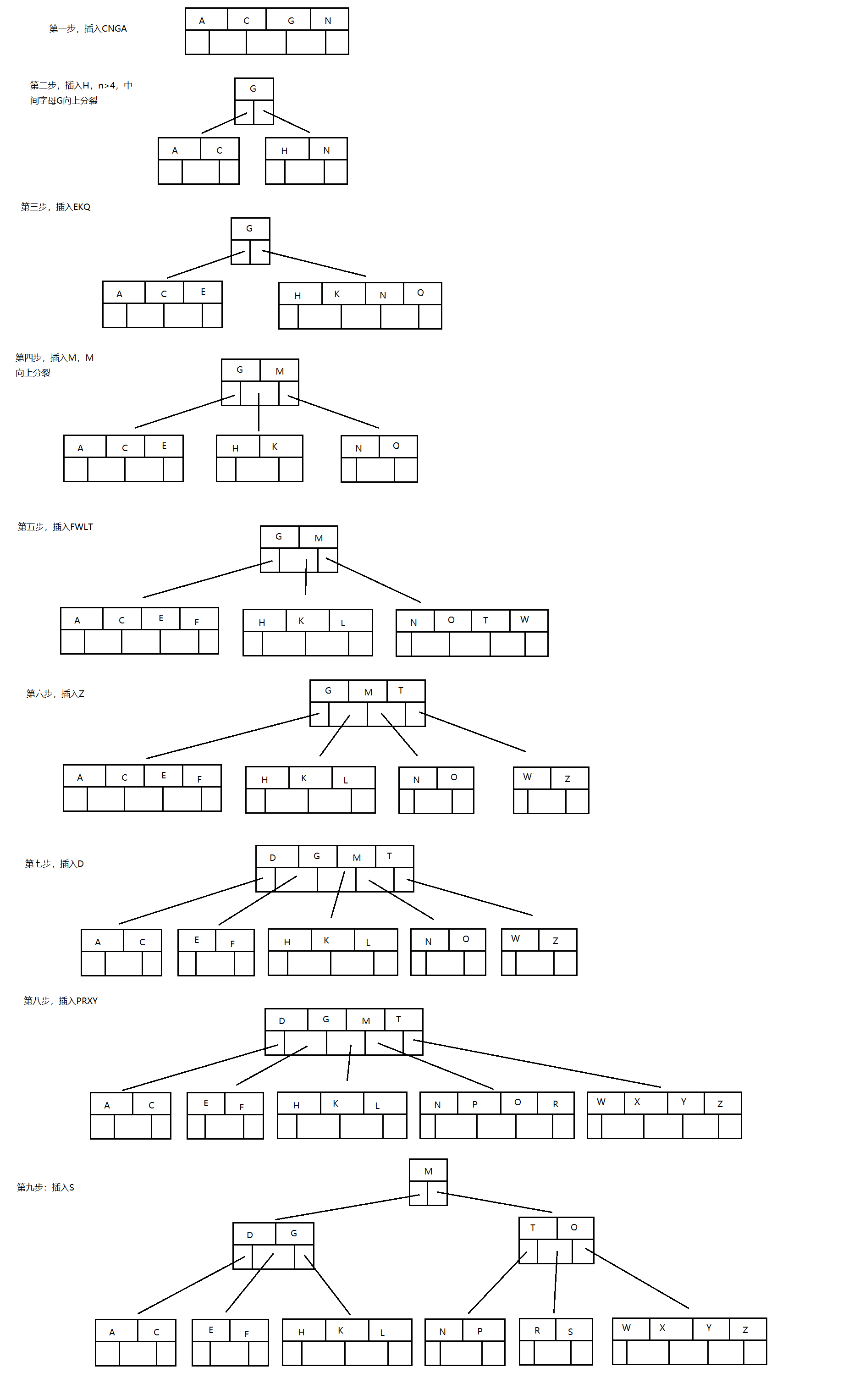
若参数T选择为3,那么每个结点最多包含3*2-1=5个键值对,看看B树的数据存储
3 B树在磁盘文件中的应用
在我们的程序中,不可避免的需要通过IO操作文件,而我们的文件是存储在磁盘上的。计算机操作磁盘上的文件是通过文件系统进行操作的,在文件系统中就使用到了B树这种数据结构。mysql的索引使用的是B+树
3.1 磁盘
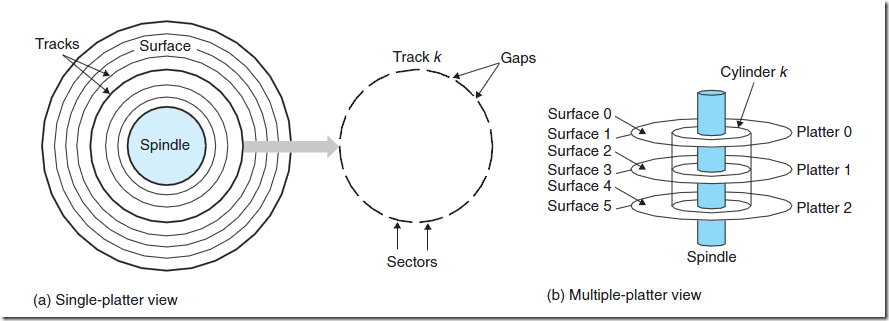
我们使用的更多的是使用磁盘,磁盘能够保存大量的数据,从GB一直到TB级,但是 他的读取速度比较慢,因为涉及到机器操作,读取速度为毫秒级,从DRAM读速度比从磁盘度快10万倍,从SRAM读速度比从磁盘读快100万倍。
磁盘由盘片构成,每个盘片有两面,又称为盘面 。盘片中央有一个可以旋转的主轴,他使得盘片以固定的旋转速率 旋转,通常是5400rpm或者是7200rpm,一个磁盘中包含了多个这样的盘片并封装在一个密封的容器内 。盘片的每 个表面是由一组称为磁道同心圆组成的 ,每个磁道被划分为了一组扇区 ,每个扇区包含相等数量的数据位,通常 是512个子节,扇区之间由一些间隙隔开,这些间隙中不存储数据 。
3.2 磁盘IO
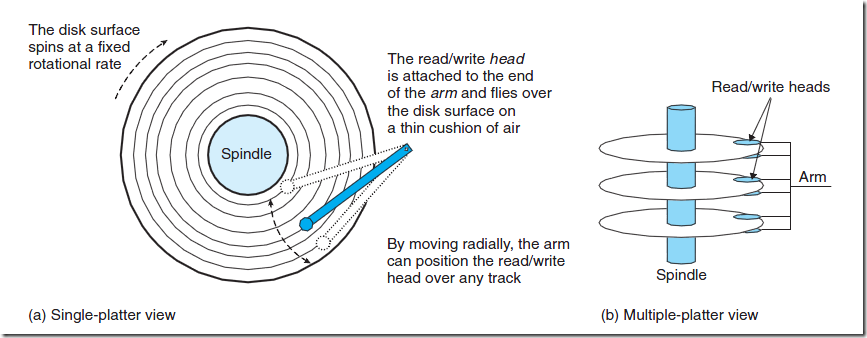
磁盘用磁头来读写存储在盘片表面的位,而磁头连接到一个移动臂上,移动臂沿着盘片半径前后移动,可以将磁头 定位到任何磁道上,这称之为寻道操作。一旦定位到磁道后,盘片转动,磁道上的每个位经过磁头时,读写磁头就 可以感知到该位的值,也可以修改值。对磁盘的访问时间分为 寻道时间,旋转时间,以及传送时间。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,因此为了提高效率,要尽量减少磁盘 I/O,减少读写操作。 为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字 节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的 局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。由于磁盘顺序读取的效率很高(不需要寻 道时间,只需很少的旋转时间),因此预读可以提高I/O效率。
页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储 块称为一页(1024个字节或其整数倍),预读的长度一般为页的整倍数。主存和磁盘以页为单位交换数据。当程 序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位 置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。 文件系统的设计者利用了磁盘预读原理,将一个结点的大小设为等于一个页(1024个字节或其整数倍),这样每 个结点只需要一次I/O就可以完全载入。那么3层的B树可以容纳102410241024差不多10亿个数据,如果换成二 叉查找树,则需要30层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在10亿个数据中查 找目标值,只需要小于3次硬盘读取就可以找到目标值,但红黑树需要小于30次,因此B树大大提高了IO的操作效 率
4 代码实现
键值对API设计
| 类名 | Entry<K, V> |
|---|---|
| 成员属性 | private K key; private V value; |
| 成员方法 | public String toString()// 输出 |
搜索结果API设计
| 类名 | SearchResult |
|---|---|
| 成员属性 | private boolean exist;查找是否成功 private int index;键值在B树节点中的位置 private V value; |
| 构造方法 | public SearchResult(boolean exist, int index) public SearchResult(boolean exist, int index, String value) |
结点类API设计
| 类名 | Node<K, V> |
|---|---|
| 构造方法 | private Node() public Node(Comparator kComparator) |
| 成员属性 | private List<Entry<K, V>> entrys;节点的项,按键非降序存放 private List<Node<K, V>> children; private boolean leaf;是否为叶子节点 private Comparator kComparator;键的比较函数对象 |
| 成员方法 | public int size()返回项的个数。 int comparYe(K key1, K key2)比较两个key的大小 public SearchResult searchKey(K key)在节点中查找给定的键 public void addEntry(Entry<K, V> entry)将给定的项追加到节点的末尾 public Entry<K, V> removeEntry(int index)删除给定索引的entry public Entry<K, V> entryAt(int index)得到节点中给定索引的项 public V putEntry(Entry<K, V> entry)如果节点中存在给定的键,则更新其关联的值 public boolean insertEntry(Entry<K, V> entry)在该节点中插入给定的项 public void insertEntry(Entry<K, V> entry, int index)在该节点中给定索引的位置插入给定的项 public Node<K, V> childAt(int index)返回节点中给定索引的子节点 public void addChild(Node<K, V> child)将给定的子节点追加到该节点的末尾 public void removeChild(int index)删除该节点中给定索引位置的子节点 public void insertChild(Node<K, V> child, int index)将给定的子节点插入到该节点中给定索引的位置 |
B树API设计
| 类名 | BTree<K, V> |
|---|---|
| 成员属性 | private static final int DEFAULT_T = 2;最小度 private BTreeNode<K, V> root;根节点 private int t = DEFAULT_T;默认度数 private int minKeySize = t - 1;非根节点最小键值数 private int maxKeySize = 2 * t - 1;非根节点最大键值数 private Comparator kComparator;比较对象 |
| 构造方法 | public BTree() public BTree(int t) public BTree(Comparator kComparator) public BTree(Comparator kComparator, int t) |
| 成员方法 | int compare(K key1, K key2)比较两个key大小 public V search(K key)搜索指定的key private V search(BTreeNode<K, V> node, K key)在以给定节点为根的子树中,递归搜索 private void splitNode(BTreeNode<K, V> parentNode, BTreeNode<K, V> childNode, int index)分裂一个满子节点 private boolean insertNotFull(BTreeNode<K, V> node, Entry<K, V> entry)在一个非满节点中插入给定的项 public boolean insert(K key, V value)在B树中插入给定的键值对 private V putNotFull(BTreeNode<K, V> node, Entry<K, V> entry)如果存在给定的键,则更新键关联的值,否则则插入 public V put(K key, V value)如果B树中存在给定的键,则更新值,否则插入 public Entry<K, V> delete(K key)从B树中删除一个与给定键关联的项。 private Entry<K, V> delete(BTreeNode<K, V> node, K key)从以给定node为根的子树中删除与给定键关联的项 public void output()层序遍历B树输出 |
代码实现
package com.jg.tree;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
/**
* B树代码实现
*
* @Author: 杨德石
* @Date: 2020/7/20 20:50
* @Version 1.0
*/
public class BTree<K extends Comparable<K>, V> {
/**
* 最小度
*/
private static final int DEFAULT_T = 2;
/**
* 根节点
*/
private Node<K, V> root;
/**
* 默认度数
*/
private int t = DEFAULT_T;
/**
* 非根节点最小键值数
*/
private int minKeySize = t - 1;
/**
* 非根节点最大键值数
*/
private int maxKeySize = 2 * t - 1;
/**
* 比较对象
*/
private Comparator<K> kComparator;
public BTree() {
root = new Node<>();
root.leaf = true;
}
public BTree(int t) {
this();
this.t = t;
minKeySize = t - 1;
maxKeySize = 2 * t - 1;
}
public BTree(Comparator<K> kComparator) {
root = new Node<>(kComparator);
root.leaf = true;
this.kComparator = kComparator;
}
public BTree(Comparator<K> kComparator, int t) {
this(kComparator);
this.t = t;
minKeySize = t - 1;
maxKeySize = 2 * t - 1;
}
/**
* 比较两个key大小
*
* @param key1
* @param key2
* @return
*/
private int compare(K key1, K key2) {
return key1.compareTo(key2);
}
/**
* 搜索指定的key
*
* @param key
* @return
*/
public V search(K key) {
return search(root, key);
}
/**
* 在以给定节点为根的子树中,递归搜索
*
* @param node
* @param key
* @return
*/
private V search(Node<K, V> node, K key) {
// 直接从当前节点查询数据
SearchResult<V> result = node.searchKey(key);
if (result.exist) {
// 如果查到了,直接返回
return result.value;
} else {
// 没有查到,递归查询
search(node.childAt(result.index), key);
}
return null;
}
/**
* 分裂一个满子节点
*
* @param parentNode
* @param childNode
* @param index
*/
private void splitNode(Node<K, V> parentNode, Node<K, V> childNode, int index) {
if (childNode.size() < maxKeySize) {
throw new RuntimeException("当前节点的子节点尚未达到最大key数,不允许分裂");
}
// 创建一个node
Node<K, V> siblingNode = new Node<>(kComparator);
siblingNode.leaf = childNode.leaf;
// 将满子节点中索引为t, 2t-2的(t-1)个项插入到新节点中
for (int i = 0; i <= minKeySize; i++) {
siblingNode.addEntry(childNode.entryAt(t + i));
}
// 提取出满子节点的中间相,索引是(t-1)
Entry<K, V> midEntry = childNode.entryAt(t - 1);
// 删除满子节点中t-1到2t-2处的值
for (int i = maxKeySize; i >= t - 1; i--) {
childNode.removeEntry(i);
}
// 判断如果满子节点不是叶子结点,则还需要处理叶子结点
if (!childNode.leaf) {
// 将满子节点中索引为t 2t-1的t个子节点插入到新的节点中
for (int i = 0; i < maxKeySize + 1; i++) {
siblingNode.addChild(childNode.childAt(t + 1));
}
// 删除满子节点中索引为t 2t-1除的t个子节点
for (int i = maxKeySize; i >= t; i--) {
childNode.removeChild(i);
}
}
// 将entry插入父节点
parentNode.insertEntry(midEntry, index);
// 将新结点插入父节点
parentNode.insertChild(siblingNode, index + 1);
}
/**
* 在一个非满节点中插入给定的项
*
* @param node 非满节点
* @param entry 给定的项
* @return
*/
private boolean insertNotFull(Node<K, V> node, Entry<K, V> entry) {
// 如果是叶子结点,直接插入
if (node.leaf) {
return node.insertEntry(entry);
} else {
// 不是叶子结点
// 找到entry在给定的节点应该插入的位置
SearchResult<V> result = node.searchKey(entry.key);
// 如果存在,则直接返回失败
if (result.exist) {
return false;
}
// 获取到子节点
Node<K, V> childNode = node.childAt(result.index);
// 判断子节点是否为满节点
boolean b = insertNotFull(childNode, entry);
if (childNode.size() == 2 * t) {
// 先分裂
splitNode(node, childNode, result.index);
// 如果给定的entry的键大于分裂之后新生成的键,则需要插入到该项的右边
if (compare(entry.key, node.entryAt(result.index).key) > 0) {
childNode = node.childAt(result.index + 1);
}
}
return b;
}
}
/**
* 在B树中插入给定的键值对
*
* @param key
* @param value
* @return
*/
public boolean insert(K key, V value) {
boolean b = insertNotFull(root, new Entry<>(key, value));
if (root.size() == maxKeySize + 1) {
// 根节点满了,则B树长高
Node<K, V> newRoot = new Node<>(kComparator);
newRoot.leaf = false;
newRoot.addChild(root);
splitNode(newRoot, root, 0);
root = newRoot;
}
return b;
}
/**
* 如果存在给定的键,则更新键关联的值,否则则插入
*
* @param node
* @param entry
* @return
*/
private V putNotFull(Node<K, V> node, Entry<K, V> entry) {
assert node.size() < maxKeySize;
// 如果是叶子结点,直接插入
if (node.leaf) {
return node.putEntry(entry);
} else {
// 找到entry在给定节点应该插入的位置
SearchResult<V> result = node.searchKey(entry.key);
// 如果存在,则更新
if (result.exist) {
return node.putEntry(entry);
}
// 获取到子节点
Node<K, V> childNode = node.childAt(result.index);
// 判断子节点是否为满节点
if (childNode.size() == 2 * t - 1) {
// 先分裂
splitNode(node, childNode, result.index);
// 如果给定的entry的键大于分裂之后新生成的键,则需要插入到该项的右边
if (compare(entry.key, node.entryAt(result.index).key) > 0) {
childNode = node.childAt(result.index + 1);
}
}
return putNotFull(childNode, entry);
}
}
/**
* 如果B树中存在给定的键,则更新值,否则插入
*
* @param key
* @param value
* @return
*/
public V put(K key, V value) {
if (root.size() == maxKeySize) {
// 根节点满了,则B树长高
Node<K, V> newRoot = new Node<>(kComparator);
newRoot.leaf = false;
newRoot.addChild(root);
splitNode(newRoot, root, 0);
root = newRoot;
}
return putNotFull(root, new Entry<>(key, value));
}
/**
* 从以给定<code>node</code>为根的子树中删除与给定键关联的项。
* <p/>
* 删除的实现思想请参考《算法导论》第二版的第18章。
*
* @param node - 给定的节点
* @param key - 给定的键
* @return 如果B树中存在给定键关联的项,则返回删除的项,否则null
*/
private Entry<K, V> delete(Node<K, V> node, K key) {
// 该过程需要保证,对非根节点执行删除操作时,其关键字个数至少为t。
assert node.size() >= t || node == root;
SearchResult<V> result = node.searchKey(key);
/*
* 因为这是查找成功的情况,0 <= result.index <= (node.size() - 1),
* 因此(result.index + 1)不会溢出。
*/
if (result.exist) {
// 1.如果关键字在节点node中,并且是叶节点,则直接删除。
if (node.leaf) {
return node.removeEntry(result.index);
} else {
// 2.a 如果节点node中前于key的子节点包含至少t个项
Node
<K, V> leftChildNode = node.childAt(result.index);
if (leftChildNode.size() >= t) {
// 使用leftChildNode中的最后一个项代替node中需要删除的项
node.removeEntry(result.index);
node.insertEntry(leftChildNode.entryAt(leftChildNode.size() - 1), result.index);
// 递归删除左子节点中的最后一个项
return delete(leftChildNode, leftChildNode.entryAt(leftChildNode.size() - 1).key);
} else {
// 2.b 如果节点node中后于key的子节点包含至少t个关键字
Node
<K, V> rightChildNode = node.childAt(result.index + 1);
if (rightChildNode.size() >= t) {
// 使用rightChildNode中的第一个项代替node中需要删除的项
node.removeEntry(result.index);
node.insertEntry(rightChildNode.entryAt(0), result.index);
// 递归删除右子节点中的第一个项
return delete(rightChildNode, rightChildNode.entryAt(0).key);
} else // 2.c 前于key和后于key的子节点都只包含t-1个项
{
Entry<K, V> deletedEntry = node.removeEntry(result.index);
node.removeChild(result.index + 1);
// 将node中与key关联的项和rightChildNode中的项合并进leftChildNode
leftChildNode.addEntry(deletedEntry);
for (int i = 0; i < rightChildNode.size(); ++i) {
leftChildNode.addEntry(rightChildNode.entryAt(i));
}
// 将rightChildNode中的子节点合并进leftChildNode,如果有的话
if (!rightChildNode.leaf) {
for (int i = 0; i <= rightChildNode.size(); ++i) {
leftChildNode.addChild(rightChildNode.childAt(i));
}
}
return delete(leftChildNode, key);
}
}
}
} else {
/*
* 因为这是查找失败的情况,0 <= result.index <= node.size(),
* 因此(result.index + 1)会溢出。
*/
if (node.leaf) // 如果关键字不在节点node中,并且是叶节点,则什么都不做,因为该关键字不在该B树中
{
return null;
}
Node
<K, V> childNode = node.childAt(result.index);
if (childNode.size() >= t) // // 如果子节点有不少于t个项,则递归删除
{
return delete(childNode, key);
} else // 3
{
// 先查找右边的兄弟节点
Node
<K, V> siblingNode = null;
int siblingIndex = -1;
if (result.index < node.size()) // 存在右兄弟节点
{
if (node.childAt(result.index + 1).size() >= t) {
siblingNode = node.childAt(result.index + 1);
siblingIndex = result.index + 1;
}
}
// 如果右边的兄弟节点不符合条件,则试试左边的兄弟节点
if (siblingNode == null) {
if (result.index > 0) // 存在左兄弟节点
{
if (node.childAt(result.index - 1).size() >= t) {
siblingNode = node.childAt(result.index - 1);
siblingIndex = result.index - 1;
}
}
}
// 3.a 有一个相邻兄弟节点至少包含t个项
if (siblingNode != null) {
if (siblingIndex < result.index) // 左兄弟节点满足条件
{
childNode.insertEntry(node.entryAt(siblingIndex), 0);
node.removeEntry(siblingIndex);
node.insertEntry(siblingNode.entryAt(siblingNode.size() - 1), siblingIndex);
siblingNode.removeEntry(siblingNode.size() - 1);
// 将左兄弟节点的最后一个孩子移到childNode
if (!siblingNode.leaf) {
childNode.insertChild(siblingNode.childAt(siblingNode.size()), 0);
siblingNode.removeChild(siblingNode.size());
}
} else // 右兄弟节点满足条件
{
childNode.insertEntry(node.entryAt(result.index), childNode.size() - 1);
node.removeEntry(result.index);
node.insertEntry(siblingNode.entryAt(0), result.index);
siblingNode.removeEntry(0);
// 将右兄弟节点的第一个孩子移到childNode
// childNode.insertChild(siblingNode.childAt(0), childNode.size() + 1);
if (!siblingNode.leaf) {
childNode.addChild(siblingNode.childAt(0));
siblingNode.removeChild(0);
}
}
return delete(childNode, key);
} else // 3.b 如果其相邻左右节点都包含t-1个项
{
if (result.index < node.size()) // 存在右兄弟,直接在后面追加
{
Node
<K, V> rightSiblingNode = node.childAt(result.index + 1);
childNode.addEntry(node.entryAt(result.index));
node.removeEntry(result.index);
node.removeChild(result.index + 1);
for (int i = 0; i < rightSiblingNode.size(); ++i) {
childNode.addEntry(rightSiblingNode.entryAt(i));
}
if (!rightSiblingNode.leaf) {
for (int i = 0; i <= rightSiblingNode.size(); ++i) {
childNode.addChild(rightSiblingNode.childAt(i));
}
}
} else // 存在左节点,在前面插入
{
Node
<K, V> leftSiblingNode = node.childAt(result.index - 1);
childNode.insertEntry(node.entryAt(result.index - 1), 0);
node.removeEntry(result.index - 1);
node.removeChild(result.index - 1);
for (int i = leftSiblingNode.size() - 1; i >= 0; --i) {
childNode.insertEntry(leftSiblingNode.entryAt(i), 0);
}
if (!leftSiblingNode.leaf) {
for (int i = leftSiblingNode.size(); i >= 0; --i) {
childNode.insertChild(leftSiblingNode.childAt(i), 0);
}
}
}
// 如果node是root并且node不包含任何项了
if (node == root && node.size() == 0) {
root = childNode;
}
return delete(childNode, key);
}
}
}
}
/**
* 层序遍历B树输出
*/
public void output() {
Queue<Node<K, V>> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
Node<K, V> node = queue.poll();
for (int i = 0; i < node.size(); i++) {
System.out.print(node.entryAt(i) + " ");
}
System.out.println();
if (!node.leaf) {
// 不是叶子结点,将叶子结点放入队列
for (int i = 0; i <= node.size(); i++) {
queue.offer(node.childAt(i));
}
}
}
}
/**
* 键值对类
*
* @param <K>
* @param <V>
*/
private static class Entry<K extends Comparable<K>, V> {
public K key;
public V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public String toString() {
return key + ":" + value;
}
}
/**
* 搜索结果类
* 在B树节点中搜索指定的键值返回的结果
* 该结果由两部分组成,第一部分表示是否查找成功
* 如果查找成功,第二部分表示给定键值对在B树节点中的位置
* 如果查找失败,第二部分表示给定键值应该插入的位置
*
* @param <V>
*/
private static class SearchResult<V> {
public boolean exist;
public int index;
public V value;
public SearchResult(boolean exist, int index) {
this.exist = exist;
this.index = index;
}
public SearchResult(boolean exist, int index, V value) {
this.exist = exist;
this.index = index;
this.value = value;
}
}
private static class Node<K extends Comparable<K>, V> {
/**
* 节点的项,按键非降序存放
*/
public List<Entry<K, V>> entries;
/**
* 子节点
*/
public List<Node<K, V>> children;
/**
* 是否是叶子结点
*/
public boolean leaf;
/**
* 键的比较函数对象
*/
public Comparator<K> kComparator;
public Node() {
entries = new ArrayList<>();
children = new ArrayList<>();
leaf = false;
}
public Node(Comparator<K> kComparator) {
this();
this.kComparator = kComparator;
}
/**
* 返回项的个数
*
* @return
*/
public int size() {
return entries.size();
}
/**
* 比较两个key的大小
*
* @param key1
* @param key2
* @return
*/
private int compare(K key1, K key2) {
return key1.compareTo(key2);
}
/**
* 在节点中查找给定的键
* 如果节点中存在给定的键,则返回一个SearchResult
* 标识此次查找成功。返回给定的键在节点中的索引和给定的键关联的值
* 如果不存在,则返回SearchResult
* 标识此次查找失败,返回给定的键应该插入的位置,关联的值是null
* 二分查找法
*
* @param key
* @return
*/
public SearchResult<V> searchKey(K key) {
int low = 0;
int high = entries.size() - 1;
int mid = 0;
while (low <= high) {
// 计算中间值
mid = (low + high) / 2;
// 调用get方法,取出来中间的值
Entry<K, V> entry = entries.get(mid);
// 比较
if (compare(entry.key, key) == 0) {
// 两个key相同,说明找到了需要的元素
} else if (compare(entry.key, key) > 0) {
// 中间值的key比传入的key大,从左边开始找
high = mid - 1;
} else {
// 中间值的key比传入的key大,从右边开始找
low = mid + 1;
}
}
// 循环完毕,说明找到了需要的值,此时mid就是我们要查询元素的index
boolean result = false;
int index = 0;
V value = null;
if (low <= high) {
// 说明查找成功
result = true;
index = mid;
value = entries.get(index).value;
} else {
result = false;
index = low;
}
return new SearchResult<>(result, index, value);
}
/**
* 将给定的项追加到节点的末尾
*
* @param entry
*/
public void addEntry(Entry<K, V> entry) {
entries.add(entry);
}
/**
* 删除给定索引的entry
*
* @param index
* @return
*/
public Entry<K, V> removeEntry(int index) {
return entries.remove(index);
}
/**
* 得到节点中给定索引的项
*
* @param index
* @return
*/
public Entry<K, V> entryAt(int index) {
return entries.get(index);
}
/**
* 如果节点中存在给定的键,则更新其关联的值
*
* @param entry
* @return
*/
public V putEntry(Entry<K, V> entry) {
// 查询给定的key是否存在
SearchResult<V> result = searchKey(entry.key);
if (result.exist) {
// 存在,替换值
// 获取旧值
V oldValue = entries.get(result.index).value;
// 设置新值
entries.get(result.index).value = entry.value;
return oldValue;
} else {
// 不存在,插入
insertEntry(entry, result.index);
return null;
}
}
/**
* 在该节点中插入给定的项
* 该方法保证插入之后,其键值还是以非降序存放
*
* @param entry
* @return
*/
public boolean insertEntry(Entry<K, V> entry) {
// 查找指定的key是否存在
SearchResult<V> result = searchKey(entry.key);
if (result.exist) {
return false;
} else {
insertEntry(entry, result.index);
return true;
}
}
/**
* 在该节点中给定索引的位置插入给定的项
*
* @param entry
* @param index
*/
public void insertEntry(Entry<K, V> entry, int index) {
List<Entry<K, V>> newEntries = new ArrayList<>();
int i = 0;
for (; i < index; i++) {
newEntries.add(entries.get(i));
}
newEntries.add(entry);
for (; i < entries.size(); i++) {
newEntries.add(entries.get(i));
}
entries.clear();
entries = newEntries;
}
/**
* 返回节点中给定索引的子节点
*
* @param index
* @return
*/
public Node<K, V> childAt(int index) {
if (leaf) {
// 如果当前节点是叶子结点,没有子节点,不予许操作
throw new IllegalArgumentException("当前节点是叶子结点,不存在子节点");
}
return children.get(index);
}
/**
* 将给定的子节点追加到该节点的末尾
*
* @param child
*/
public void addChild(Node<K, V> child) {
children.add(child);
}
/**
* 删除该节点中给定索引位置的子节点
*
* @param index
*/
public void removeChild(int index) {
children.remove(index);
}
/**
* 将给定的子节点插入到该节点中给定索引的位置
*
* @param child
* @param index
*/
public void insertChild(Node<K, V> child, int index) {
List<Node<K, V>> newChild = new ArrayList<>();
int i = 0;
for (; i < index; i++) {
newChild.add(children.get(i));
}
newChild.add(child);
for (; i < children.size(); i++) {
newChild.add(children.get(i));
}
children.clear();
children = newChild;
}
}
}
class Test16 {
public static void main(String[] args) {
BTree<String, String> tree = new BTree<>(3);
tree.insert("C", "C");
tree.insert("N", "N");
tree.insert("G", "G");
tree.insert("A", "A");
tree.insert("H", "H");
tree.insert("E", "E");
tree.insert("K", "K");
tree.insert("Q", "Q");
tree.insert("M", "M");
tree.insert("F", "F");
tree.insert("W", "W");
tree.insert("L", "L");
tree.insert("T", "T");
tree.output();
}
}















 1925
1925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









