







一、redis集群简介
1、集群
-
集群是一组相互独立的、通过高速网络互相联通的节点,构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群就是一个独立的服务器。
-
集群技术是一种通用的技术,其目的是为了解决单机运算能力的不足、IO能力的不足、提高服务的可靠性、获得规模可扩展能力,降低整体方案的运维成本(运行、升级、维护成本)。能在大流量访问下提供稳定的业务,集群化是存储的必然形态。
2、redis集群
-
Redis 集群是一个分布式(distributed)、容错(fault-tolerant)的 Redis 实现,
集群可以使用的功能是普通单机 -
Redis 所能使用的功能的一个子集(subset),提供在多个Redis节点之间共享数据的程序集。。
-
Redis 集群并不支持同时处理多个键的 Redis
命令,因为这需要在多个节点间移动数据,这样会降低redis集群的性能,在高负载的情况下可能会导致不可预料的错误。 -
Redis 集群通过分区来提供一定程度的可用性,即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
3、redis集群的优势
- 缓存永不宕机:启动集群,永远让集群的一部分起作用。主节点失效了子节点能迅速改变角色成为主节点,整个集群的部分节点失败或者不可达的情况下能够继续处理命令;
- 迅速恢复数据:持久化数据,能在宕机后迅速解决数据丢失的问题
- Redis可以使用所有机器的内存,变相扩展性能;
- 使Redis的计算能力通过简单地增加服务器得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长;
- Redis集群没有中心节点,不会因为某个节点成为整个集群的性能瓶颈;
- 异步处理数据,实现快速读写。
4、redis集群工作原理
所有的节点通过服务通道直接相连(PING-PONG机制),各个节点之间通过二进制协议优化传输的速度和带宽。
客户端与节点之间通过 ascii 协议进行通信
客户端与节点直连,不需要中间 Proxy 层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
5、哈希槽
Redis集群(Cluster)并没有选用一致性哈希,而是采用了哈希槽(SLOT)的这种概念。主要的原因就是一致性哈希算法对于数据分布、节点位置的控制并不是很友好(整个哈希空间是一个虚拟圆环,数据顺时针存储到最近结点)。
首先哈希槽其实是两个概念,第一个是哈希算法。Redis Cluster的hash算法不是简单的hash(),而是crc16算法,一种校验算法。
另外一个就是槽位的概念,空间分配的规则。其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布。而Redis Cluster的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定义大小,自定义位置的。
Redis Cluster包含了16384个哈希槽,每个Key通过计算后都会落在具体一个槽位上,而这个槽位是属于哪个存储节点的,则由用户自己定义分配。例如机器硬盘小的,可以分配少一点槽位,硬盘大的可以分配多一点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
另外在容错性和扩展性上,表象与一致性哈希一样,都是对受影响的数据进行转移。而哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位转移到新的节点上。
但一定要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的。所以Redis集群的高可用是依赖于节点的主从复制与主从间的自动故障转移。
Redis 集群内置了16384个哈希槽,每个key通过CRC16算法校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽
举例:
比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点.
比如如果我想新添加个节点D,我需要从节点 A, B, C中得部分槽到D上.
如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可.
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
6、容错
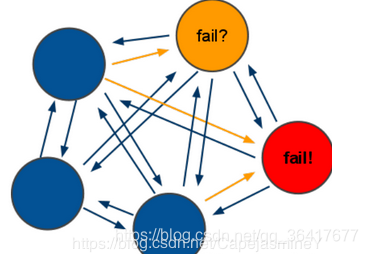
集群中的节点不断的 PING 其他的节点,当一个节点向另一个节点发送 PING 命令, 但是目标节点未能在给定的时限内回复, 那么发送命令的节点会将目标节点标记为 PFAIL(possible failure,可能已失效)。
当节点接收到其他节点发来的信息时, 它会记下那些被其他节点标记为失效的节点。 这被称为失效报告(failure report)。
如果节点已经将某个节点标记为 PFAIL , 并且根据节点所收到的失效报告显式, 集群中的大部分其他主节点也认为那个节点进入了失效状态, 那么节点会将那个失效节点的状态标记为 FAIL 。
一旦某个节点被标记为 FAIL , 关于这个节点已失效的信息就会被广播到整个集群, 所有接收到这条信息的节点都会将失效节点标记为 FAIL 。
简单来说, 一个节点要将另一个节点标记为失效, 必须先询问其他节点的意见, 并且得到大部分主节点的同意才行。
如果被标记为 FAIL 的是从节点, 那么当这个节点重新上线时, FAIL 标记就会被移除。 一个从节点是否处于 FAIL 状态, 决定了这个从节点在有需要时能否被提升为主节点。
如果一个主节点被打上 FAIL 标记之后, 经过了节点超时时限的四倍时间, 再加上十秒钟之后, 针对这个主节点的槽的故障转移操作仍未完成, 并且这个主节点已经重新上线的话, 那么移除对这个节点的 FAIL 标记。在不符合上面的条件后,一旦某个主节点进入 FAIL 状态, 如果这个主节点有一个或多个从节点存在, 那么其中一个从节点会被升级为新的主节点, 而其他从节点则会开始对这个新的主节点进行复制。
二、实验
实验环境:
server1虚拟机作Redis缓存数据库:
ip为:172.25.1.1
关闭防火墙及selinux
2. 搭建redis集群
在server1(master)上面:
因为server1之前是做过主从切换的,所以redis已经安装好。
步骤一:停掉redis服务
redis服务本身监听的端口是6379端口
停掉redis服务
redis服务本身监听的端口是6379端口
[root@server1 redis]# /etc/init.d/redis_6379 stop
步骤二:在server1上创建 6个Redis 节点
首先在 server1 机器上 /usr/local/目录下创建 redis_cluster 目录;
在 rediscluster 目录下,创建名为7001、7002、7003、7004、7005、7006的结点目录
```clike
[root@server1 redis]# mkdir /usr/local/rediscluster
[root@server1 redis]# cd /usr/local/rediscluster/
[root@server1 rediscluster]# mkdir 700{1..6}
[root@server1 rediscluster]# ls
7001 7002 7003 7004 7005 7006
步骤三:对六个结点进行配置
编辑配置文件,下面给出的是一个节点7001的配置文件(其余节点(7002-7006)的配置文件跟这个配置文件类似,只需要将redis.conf文件中的7001改为对应的节点即可)
[root@server1 rediscluster]# cd 7001/
[root@server1 7001]# vim redis.conf
port 7001 #端口
cluster-enabled yes #如果是yes,表示启用集群,否则以单例模式启动
cluster-config-file nodes.conf #请注意,尽管有此选项的名称,但这不是用户可编辑的配置文件,而是Redis群集节点每次发生更改时自动保留群集配置(基本上为状态)的文件,以便能够 在启动时重新读取它。 该文件列出了群集中其他节点,它们的状态,持久变量等等。 由于某些消息的接收,通常会将此文件重写并刷新到磁盘上。
cluster-node-timeout 5000 #Redis群集节点超过不可用的最长时间,而会将其视为失败。 如果主节点超过指定的时间不可达,它将由其从属设备进行故障切换。 此参数控制Redis群集中的其他重要事项。 值得注意的是,每个无法在指定时间内到达大多数主节点的节点将停止接受查询。
appendonly yes #是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。
pidfile "/usr/local/rediscluster/7001/redis.pid" #pid文件存放的位置
logfile "/usr/local/rediscluster/7001/redis.log" #日志文件存放的位置
daemonize yes #打入后台
dir "/usr/local/rediscluster/7001" #该节点所在目录
其余节点(7002-7006)的配置文件跟这个配置文件类似,只需要将redis.conf文件中的7001改为对应的节点即可
redis-server ./redis.conf #开启结点服务
(2)启动节点,下面给出的是7001节点的启动方法(其余节点(7002-7006)的启动方法,类似。只需要把7001改为对应的节点即可)
[root@server1 7001]# redis-server redis.conf
[root@server1 7001]# ps -aux | grep 7001

其余节点(7002-7006)的启动方法,类似。只需要把7001改为对应的节点即可
当6个节点都启动时用ps -aux命令查看

步骤四: 搭建集群
现在已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
(1)安装redis-trib所需的 ruby环境
[root@server1 ~]# yum install ruby -y
2)将redis-trib.rb对应的脚本文件放到/usr/local/bin目录下,以便直接敲击redis-trib.rb命令
[root@server1 ~]# cd redis-5.0.3/src/
[root@server1 src]# cp redis-trib.rb /usr/local/bin/
(3)使用redis-trib.rb创建集群
当时用redis-trib.rb创建集群会出现错误,提示使用redis-cli命令
过程如下:
root@server1 src]# redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 #输入yes
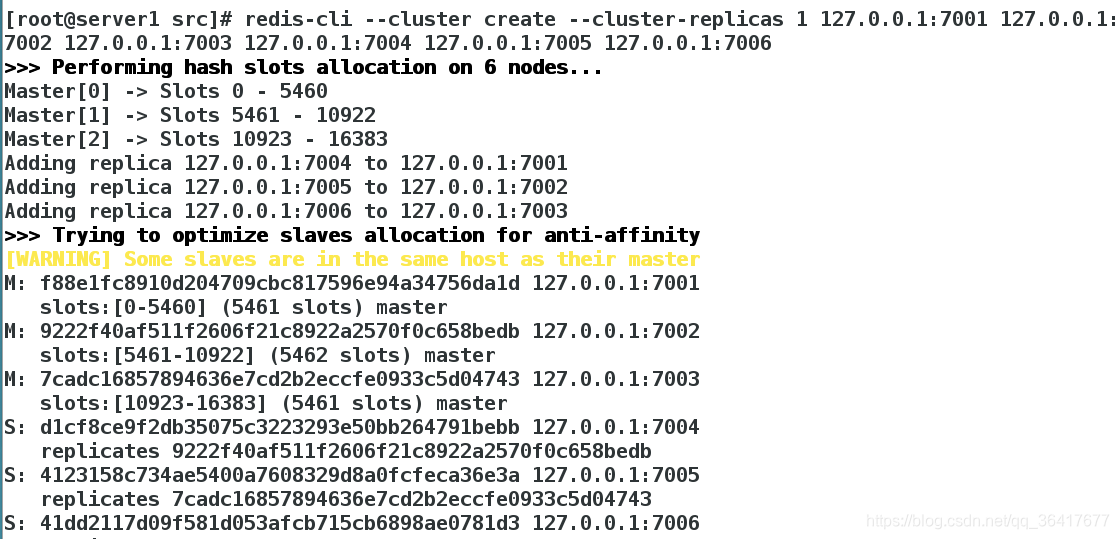
–cluster-replicas 1 #为集群中的每个主节点创建一个从节点
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯.
最终可以看到:(当然下面的信息,也可以登录每个节点(例如:redis-cli -p 7001),查看每个节点的info replication,来获取)
(1)主节点:7001;对应的从节点为:7006
(2)主节点:7002;对应的从节点为:7004
(3)主节点:7003;对应的从节点为:7005
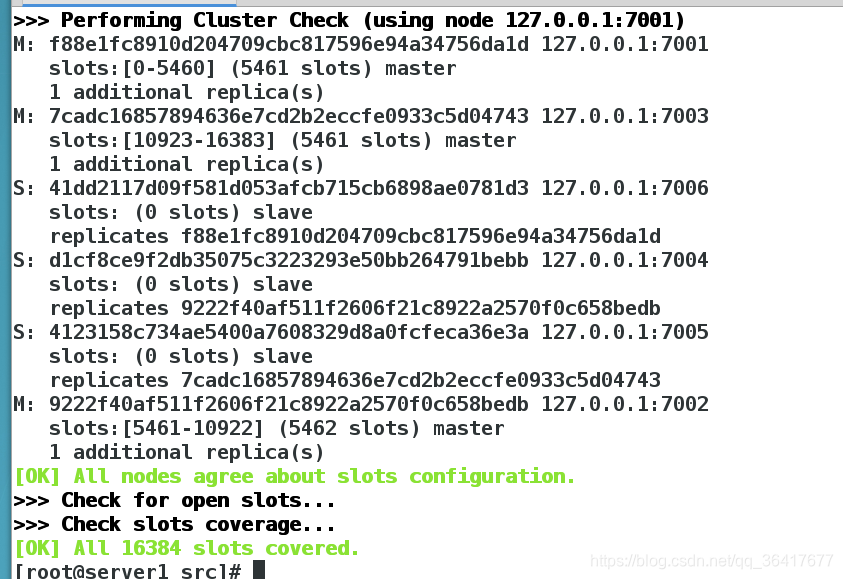
此时可以利用下面的命令来查看该集群的信息以查看该集群的主节点
[root@server1 src]# redis-cli --cluster info 127.0.0.1:7001 #节点7001,可以换为任何一个节点,看到的结果都是一样的
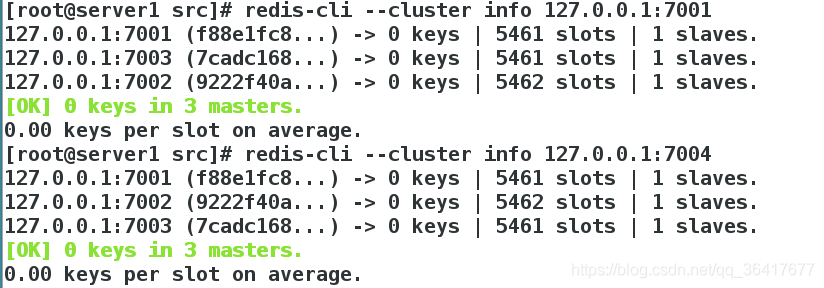
redis集群的测试:
测试存取值
客户端连接集群redis-cli需要带上 -c ,redis-cli -c -p 端口号
[root@server1 src]# redis-cli -c -p 7001
127.0.0.1:7001> set name westos
-> Redirected to slot [5798] located at 127.0.0.1:7002
OK
127.0.0.1:7002> get name
"westos"
根据redis-cluster的key值分配,name应该分配到节点7002[5461-10922]上,上面显示redis cluster自动从7001跳转到了7002节点。
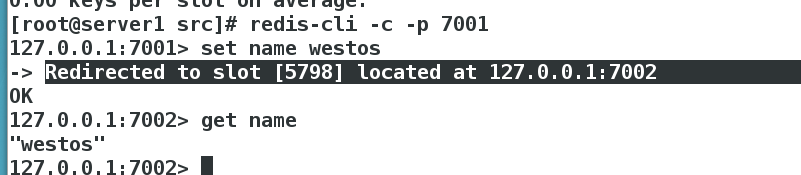
我们可以测试一下7005从节点获取name值

结论:
7005为7002的从节点,从上面也是自动跳转至7002获取值,这也是redis cluster的特点,它是去中心化,每个节点都是对等的,连接哪个节点都可以获取和设置数据。
三、 redis cluster集群的故障迁移
1)手动将7002节点挂掉
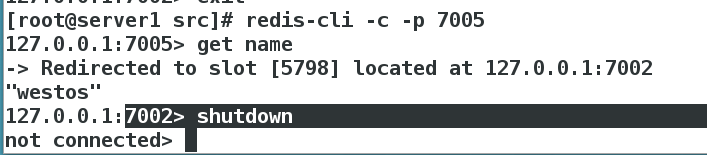
(2)再次查看集群的信息,可以看到7004节点(之前7002节点的从节点)已经成为主节点。查看7006节点的所有key,可以看出7006节点承担着7002节点的角色。对外提供的服务不受影响
[root@server1 src]# redis-cli --cluster info 127.0.0.1:7001

此时,访问name key将会转到7004
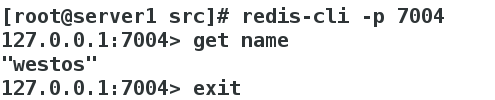
如果将7004节点也手动down掉,那么该集群里就只有两主两从:


此时再访问name key将会报错:

此时数据可以在7002配置目录下的appendonly.aof文件中找到,同样在7004配置目录中也可以找到:


之后打开7002和7004节点:
[root@server1 7002]# redis-server redis.conf
[root@server1 rediscluster]# cd 7004/
[root@server1 7004]# redis-server redis.conf
集群恢复正常,但是7004变成主master,7002变成slave,同时上线可以交换主备

四、redis cluster集群的扩容
配置过程
新增节点:127.0.0.1:7007,127.0.0.1:7008。配置文件与之前的基本一致
1.创建目录
[root@server1 7006]# cd ..
[root@server1 rediscluster]# mkdir 700{7,8}
[root@server1 rediscluster]# ls
7001 7002 7003 7004 7005 7006 7007 7008
[root@server1 rediscluster]# cp 7001/redis.conf 7007/
[root@server1 rediscluster]# cp 7001/redis.conf 7008/
2.编辑配置文件
[root@server1 7007]# vim redis.conf
port 7007
cluster-enabled yes
cluster-node-timeout 15000
cluster-config-file nodes.conf
appendonly yes
pidfile "/usr/local/rediscluster/7007/redis.pid"
logfile "/usr/local/rediscluster/7007/redis.log"
daemonize yes
dir "/usr/local/rediscluster/7007"
[root@server1 7008]# vim redis.conf
port 7008
cluster-enabled yes
cluster-node-timeout 15000
cluster-config-file nodes.conf
appendonly yes
pidfile "/usr/local/rediscluster/7008/redis.pid"
logfile "/usr/local/rediscluster/7008/redis.log"
daemonize yes
dir "/usr/local/rediscluster/7008"
3.启动7007和7008节点
[root@server1 7007]# redis-server redis.conf
[root@server1 7007]# cd ..
[root@server1 rediscluster]# cd 7008/
[root@server1 7008]# redis-server redis.conf
4.加入集群
(1)新增主节点
[root@server1 7008]# redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
#往集群中添加端口7007,
#存在的端口可以写7001-7006中的任意一个
可以使用以下命令查看新增主节点的状态:
[root@server1 7007]# redis-cli -c -p 7007
127.0.0.1:7007> cluster nodes
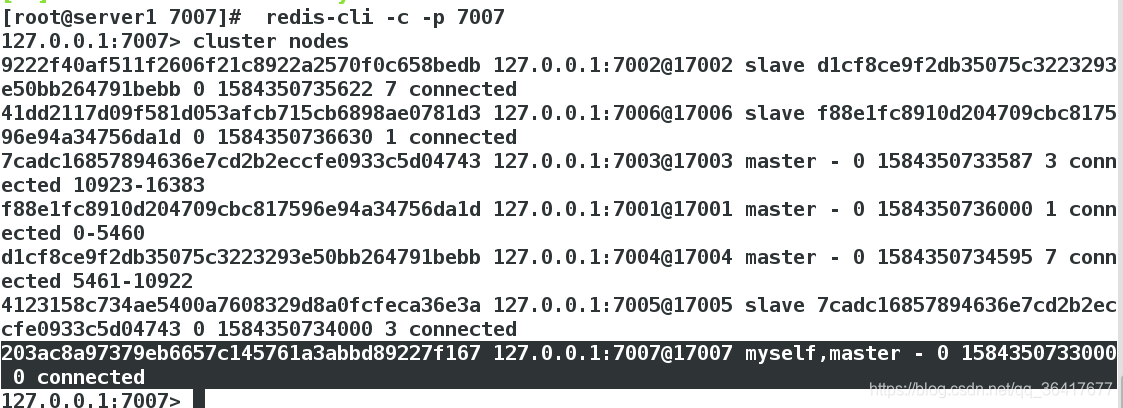
(2)新增slave从节点
[root@server4 7007]# redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7007 --cluster-slave --cluster-master-id "203ac8a97379eb6657c145761a3abbd89227f167"
注意:
将7008节点添加成7007的从节点
这里的203ac8a97379eb6657c145761a3abbd89227f167为节点7007的id号,可以在上图中查到
这里的第二个节点,必须写7007,不能写别的节点。因为这步是要将节点7008添加称为7007的节点
至此,集群的添加也就完成了,查看集群状态:
[root@server1 7007]# redis-cli --cluster info 127.0.0.1:7001
可以看出主节点与从节点添加成功,但新增加的节点没有哈希槽

5.迁移槽和数据
[root@server1 7007]# redis-cli --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters 127.0.0.1:7001
这里的节点7001可以写7001-7008中的任意一个节点任意的一个节点,因为帮助中没有表明是已经存在的节点,还是新节点,所以都可以。
这里 cluster-use-empty-masters表示将空余的槽平均分配给各个主节点
再次查看数据节点信息
[root@server1 7007]# redis-cli --cluster info 127.0.0.1:7001
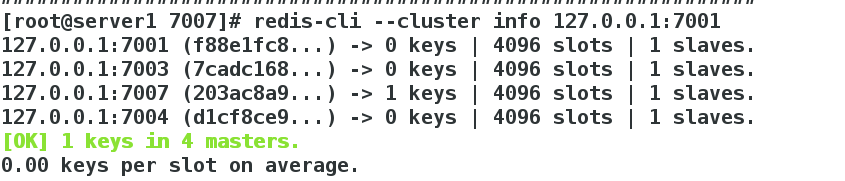
看到每个主节点的solt数量都是4096(solt的区间为:0-1364;5461-6826;10923-12287),表示solt数量平衡成功。
测试过程:
测试一下7007主节点和7008从节点获取name值
[root@server1 7007]# redis-cli -c -p 7008

结论:
节点7007和7008可以得到name的值,表示redis cluster集群的扩容配置成功。(值的注意的是:当7008节点获取name值时,自动跳转到了7007节点,而不是之前的7002节点。这是因为:之前redis cluster在扩容时。将存储name值的slot(5798)转移到7007主节点上了)














 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









