







Hive 大查询报警
背景
在知乎内部,Hive 主要被应用与两个场景:1. ETL 核心链路任务 2. Adhoc 即席查询。在 ETL 场景下,Hive SQL 任务都比较固定而且稳定,但是在 Adhoc 场景下,用户提交的 Hive SQL 比较随机多变。在用户对 SQL 没有做好优化的情况下,启动的 MapReduce 任务会扫描过多的数据,不仅使得任务运行较慢,还会对 HDFS 造成巨大压力,影响集群的稳定性,这种情况在季度末或者年底出现得极为频繁,有些用户会扫描一季度甚至一整年的数据,这样的查询一旦出现,便会导致集群资源紧张,进而影响 ETL 任务,导致报表延迟产出。
SQL 大查询实时报警系统简介
针对以上痛点,我们开发了大 SQL 查询实时报警系统,在用户提交 SQL 时,会做以下事情:
-
解析 SQL 的执行计划,转化成需要扫描的表路径以及分区路径;
-
汇总所有分区路径的大小,计算出扫描数据总量;
-
判断扫描分区总量是否超过阈值,如果超过阈值,在企业微信通知用户。
下面详解每一步的具体实现。
从执行计划拿到 Hive 扫描的 HDFS 路径
这一步我们利用 Hive Server 的 Hook 机制,在每条 SQL 被解析完成后,向 Kafka 输出一条审计日志,审计日志的格式如下:
{
"operation": "QUERY",
"user": "hdfs",
"time": "2021-07-12 15:43:16.022",
"ip": "127.0.0.1",
"hiveServerIp": "127.0.0.1",
"inputPartitionSize": 2,
"sql": "select count(*) from test_table where pdate in ('2021-07-01','2021-07-02')",
"hookType": "PRE_EXEC_HOOK",
"currentDatabase": "default",
"sessionId": "5e18ff6e-421d-4868-a522-fc3d342c3551",
"queryId": "hive_20210712154316_fb366800-2cc9-4ba3-83a7-815c97431063",
"inputTableList": [
"test_table"
],
"outputTableList": [],
"inputPaths": [
"/user/hdfs/tables/default.db/test_table/2021-07-01",
"/user/hdfs/tables/default.db/test_table/2021-07-02"
],
"app.owner": "humengyu"
}
这里我们主要关注以下几个字段:
| 字段 | 含义 |
|---|---|
| operation | SQL 的类型,如 QUERY, DROP 等 |
| user | 提交 SQL 的用户,在知乎内部是组账号 |
| sql | 提交的 SQL 内容 |
| inputPaths | 扫描的 HDFS 路径 |
| app.owner | 提交 SQL 的个人账号 |
汇总分区的大小
汇总分区大小需要知道 inputPaths 字段里每一个 HDFS 路径的目录大小,这里有以下几种解决方案:
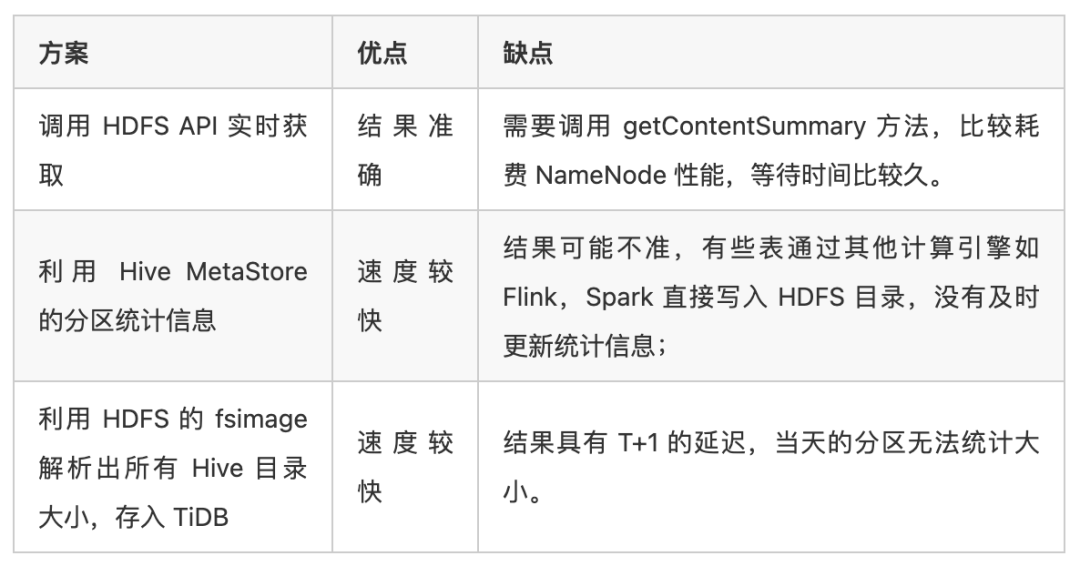
ps:
还可以通过修改元数据,具体:每次执行完sql,调用一个rpc接口,更新当前表在hive中的元数据,或者,每晚定时整理相关表(analyze),就可以实现从hive元数据获取文件大小(不在hdfs上存储的外表除外)

针对通过INSERT OVERWRITE生成的表和分区,统计会自动计算生成,可以通过配置控制是否生效,默认是开启状态
hive> set hive.stats.autogather;
hive.stats.autogather=true
考虑到使用场景,大 SQL 查询大部分情况下都是扫描了几个月甚至几年的数据,一两天的分区信息忽略可以接受,我们选择了第三种方案:每天将 HDFS 的 fsimage 解析,并且计算出每个 Hive 目录的大小,再将结果存入 TiDB。因为我们在其他场景也会用到 fsimage 的信息,所以这里我们不仅仅只存储了 Hive 目录,而是存储了整个 HDFS 的目录情况,近百亿条数据。很明显,在如此大的数据量下,还涉及到数据索引相关,TiDB 是一个很好的选择。
实时报警
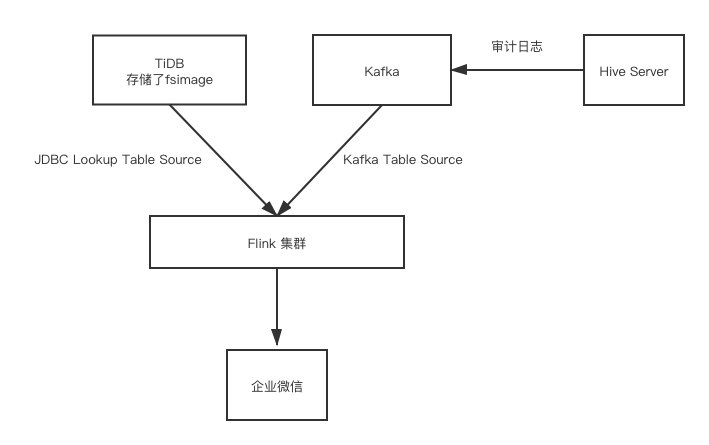
我们将审计日志实时发送至 Kafka,再用 Flink 实时去消费 Kafka 内的审计日志,利用 KafkaTableSource 和 Json Format 将 Kafka 作为流表,再利用 JdbcLookupTableSource 将 TiDB 作为维表,便可轻松计算出每条 SQL 扫描的数据量再进行报警判断。
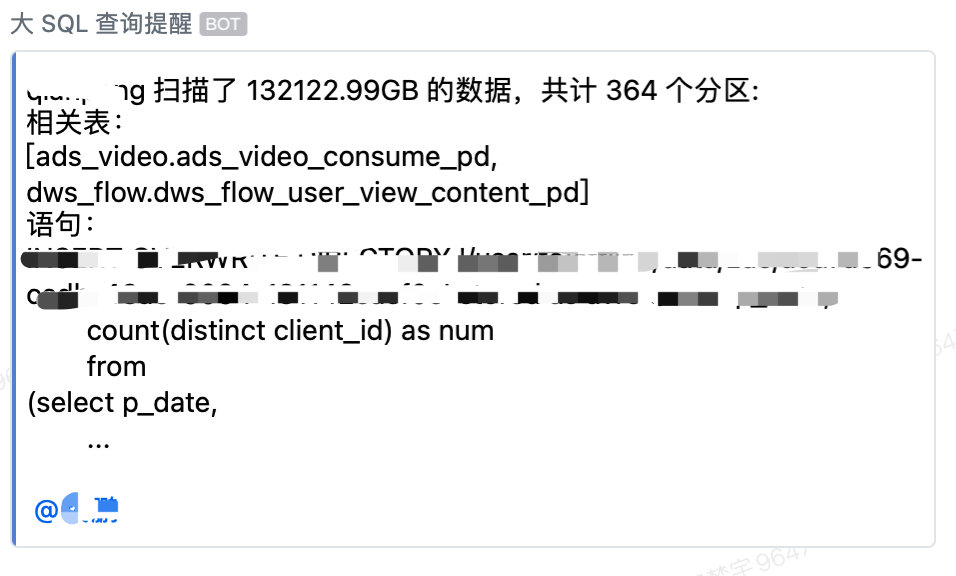
最后达成的效果如下:
hive hook
通常,Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,无需重新编译Hive。从这个意义上讲,提供了使用hive扩展和集成外部功能的能力。换句话说,Hive hadoop可用于在查询处理的各个步骤中运行/注入一些代码。根据钩子的类型,它可以在查询处理期间的不同点调用:
Pre-execution hooks-在执行引擎执行查询之前,将调用Pre-execution hooks。请注意,这个目的是此时已经为Hive准备了一个优化的查询计划。
Post-execution hooks -在查询执行完成之后以及将结果返回给用户之前,将调用Post-execution hooks 。
Failure-execution hooks -当查询执行失败时,将调用Failure-execution hooks 。
Pre-driver-run 和post-driver-run hooks-在driver执行查询之前和之后调用Pre-driver-run 和post-driver-run hooks。
Pre-semantic-analyzer 和 Post-semantic-analyzer hooks-在Hive在查询字符串上运行语义分析器之前和之后调用Pre-semantic-analyzer 和Post-semantic-analyzer hooks。
实现
public class getQueryHook implements ExecuteWithHookContext {
private static final HashSet<String> OPERATION_NAMES = new HashSet<>();
static {
OPERATION_NAMES.add(HiveOperation.CREATETABLE.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERDATABASE.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERDATABASE_OWNER.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_ADDCOLS.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_LOCATION.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_PROPERTIES.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAME.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAMECOL.getOperationName());
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_REPLACECOLS.getOperationName());
OPERATION_NAMES.add(HiveOperation.CREATEDATABASE.getOperationName());
OPERATION_NAMES.add(HiveOperation.DROPDATABASE.getOperationName());
OPERATION_NAMES.add(HiveOperation.DROPTABLE.getOperationName());
OPERATION_NAMES.add(HiveOperation.QUERY.getOperationName());
}
@Override
public void run(HookContext hookContext) throws Exception {
HashMap<String, Object> hiveSqlParseValue = new HashMap<>();
QueryPlan plan = hookContext.getQueryPlan();
ObjectMapper mapper = new ObjectMapper();
String operationName = plan.getOperationName();
//System.out.println("Query executed: " + plan.getQueryString());
hiveSqlParseValue.put("operation",operationName);//获取当前操作
hiveSqlParseValue.put("user",hookContext.getUserName());
Long timeStamp = System.currentTimeMillis(); //获取当前时间戳
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(Long.parseLong(String.valueOf(timeStamp))));
hiveSqlParseValue.put("time",sd);
hiveSqlParseValue.put("sql",plan.getQueryString());//当前查询sql
hiveSqlParseValue.put("hookType",hookContext.getHookType());
hiveSqlParseValue.put("queryId",plan.getQueryId());
ArrayList<String> tableList = new ArrayList<>();
ArrayList<String> inputPutList = new ArrayList<>();
ArrayList<String> inputPutPartitionList = new ArrayList<>();
HashSet<String> ownerSet = new HashSet<>();
int isPartition=0;
if (OPERATION_NAMES.contains(operationName)
&& !plan.isExplain()) {
Set<ReadEntity> inputs = hookContext.getInputs();
// Set<WriteEntity> outputs = hookContext.getOutputs();
for (Entity entity : inputs) {
switch (entity.getType()) {
//无分区
case TABLE:
tableList.add(entity.getTable().getTTable().getTableName());
inputPutList.add(mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"",""));
ownerSet.add(entity.getTable().getTTable().getOwner());
//有分区
case PARTITION:
if (null != entity.getP()){
isPartition=1;
String partitionName = getValueName(entity.getP().getSpec(), false);
String influxPath = mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"","");
inputPutPartitionList.add(influxPath+"/"+partitionName);
}
}
}
// for (Entity entity : outputs) {
// }
}
hiveSqlParseValue.put("inputTableList",tableList);
if (isPartition==0){
hiveSqlParseValue.put("inputPaths",inputPutList);
hiveSqlParseValue.put("totalSize",getListPathSize(inputPutList));
}else{
hiveSqlParseValue.put("inputPaths",inputPutPartitionList);
hiveSqlParseValue.put("totalSize",getListPathSize(inputPutPartitionList));
}
hiveSqlParseValue.put("app.owner",ownerSet);
String resultJson = mapper.writeValueAsString(hiveSqlParseValue);
System.out.println(resultJson);
}
}
public static long getTotalSize(String pathString) throws IOException {
FileSystem hdfs = FileSystem.get(HookUtils.getHdfsConfig(0));
//Path fpath = new Path(pathString.replace("JD","114.67.103.201"));
Path fpath = new Path(pathString);
FileStatus[] fileStatuses = hdfs.listStatus(fpath);
Path[] listPath = FileUtil.stat2Paths(fileStatuses);
long totalSize=0L;
for (Path eachpath:listPath) {
//totalSize = totalSize+hdfs.getContentSummary(new Path(eachpath.toString().replace("JD","114.67.103.201"))).getLength();
totalSize = totalSize+hdfs.getContentSummary(eachpath).getLength();
}
return totalSize;
}
打包上传
maven clean package
上传到hive lib目录,进入hive,用add jar的方式让其临时生效
hive> add jar /usr/local/service/hive/lib/original-hivehook-learn-1.0-SNAPSHOT.jar;
Added [/usr/local/service/hive/lib/original-hivehook-learn-1.0-SNAPSHOT.jar] to class path
Added resources: [/usr/local/service/hive/lib/original-hivehook-learn-1.0-SNAPSHOT.jar]
hive> set hive.exec.pre.hooks=com.hive.hook.learn.getQueryHook; #是在执行计划执行之前,所以指定hive.exec.pre.hooks
hive> select count(1) from bdm.bdm_tracker_flow_de where days>='2021-08-31';
{
"inputTableList": [
"bdm_tracker_flow_de"
],
"totalSize": 361986399,
"app.owner": [
"hadoop"
],
"time": "2021-08-31 18:22:01",
"operation": "QUERY",
"user": "hadoop",
"hookType": "PRE_EXEC_HOOK",
"sql": "select count(1) from bdm.bdm_tracker_flow_de where days>='2021-08-31'",
"queryId": "hadoop_20210831182159_5aa752d4-6f0c-4de7-9bfa-ac5ea7eb130d",
"inputPaths": [
"hdfs://HDFS43319/usr/hive/warehouse/bdm/bdm_tracker_flow_de/2021-08-31/07/10",
"hdfs://HDFS43319/usr/hive/warehouse/bdm/bdm_tracker_flow_de/2021-08-31/15/40",
"hdfs://HDFS43319/usr/hive/warehouse/bdm/bdm_tracker_flow_de/2021-08-31/17/10",
"hdfs://HDFS43319/usr/hive/warehouse/bdm/bdm_tracker_flow_de/2021-08-31/08/40"
......
]
}
问题
1.原文说,使用hdfs api获取时间比较久,实测查询96个分区文件的大小,只需要一秒左右,可能和集群本身的数据量有关
2.数仓有些hive表是hbase的外部表,在hdfs不存储数据,也就查不到大小
3.当分区过多的时候,会报oom,bdm_tracker_flow_de表按日、时、分进行分区,全部查的话,内存设置不够,会直接内存溢出
4.目前还有使用presto进行查询的,这个就捕捉不到了
5.使用analyze表即可更新最新的元数据,后面可随意查询,验证是否可行
还可以干什么?血缘分析,后面更新















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









