







第一种方法
创建虚拟环境
conda create -p E:\Python\envs\audiostu python=3.8
conda activate E:\Python\envs\audiostu
安装需要的包
pip uninstall protobuf
pip uninstall google
pip install protobuf==3.20.2
pip install typeguard==2.5.0
pip install attrdict==2.0.1
pip install text2digits==0.1.0
pip install configargparse==1.5.3
pip install webrtcvad==2.0.10
pip install PySoundFile==0.9.0
pip install -r requirements.txt
修改yaml文件
accum_grad: 16
cmvn_file: conf/global_cmvn
data_conf:
batch_conf:
batch_size: 1
batch_type: static
fbank_conf:
dither: 0.0
frame_length: 25
frame_shift: 10
num_mel_bins: 80
filter_conf:
max_length: 40960
min_length: 0
token_max_length: 200
token_min_length: 1
resample_conf:
resample_rate: 16000
shuffle: False
shuffle_conf:
shuffle_size: 1500
sort: False
sort_conf:
sort_size: 1000
spec_aug: true
spec_aug_conf:
max_f: 10
max_t: 50
num_f_mask: 2
num_t_mask: 2
speed_perturb: False
decoder: transformer
decoder_conf:
attention_heads: 8
dropout_rate: 0.1
linear_units: 2048
num_blocks: 6
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
encoder: conformer
encoder_conf:
activation_type: swish
attention_dropout_rate: 0.0
attention_heads: 8
cnn_module_kernel: 15
cnn_module_norm: layer_norm
dropout_rate: 0.1
input_layer: conv2d
linear_units: 2048
normalize_before: true
num_blocks: 12
output_size: 512
pos_enc_layer_type: rel_pos
positional_dropout_rate: 0.1
selfattention_layer_type: rel_selfattn
use_cnn_module: true
#use_dynamic_chunk: true
#use_dynamic_left_chunk: false
grad_clip: 5
input_dim: 80
is_json_cmvn: true
log_interval: 100
#max_epoch: 36
model_conf:
ctc_weight: 0.3
length_normalized_loss: false
lsm_weight: 0.1
optim: adam
optim_conf:
lr: 0.001
output_dim: 5537
scheduler: warmuplr
scheduler_conf:
warmup_steps: 5000
engine_sample_rate_hertz: 16000
engine_max_decoders: 1
engine_max_inactivity_secs: 3
model_path: conf/final.pt
dict_path: conf/words.txt
beam_size: 10
mode: ctc_greedy_search
decoding_chunk_size: 11
num_decoding_left_chunks: -1
#override_config:
#penalty:
gpu: 1
audio_save_path: G:\Python\ASR_python_deploy-main\audio_save
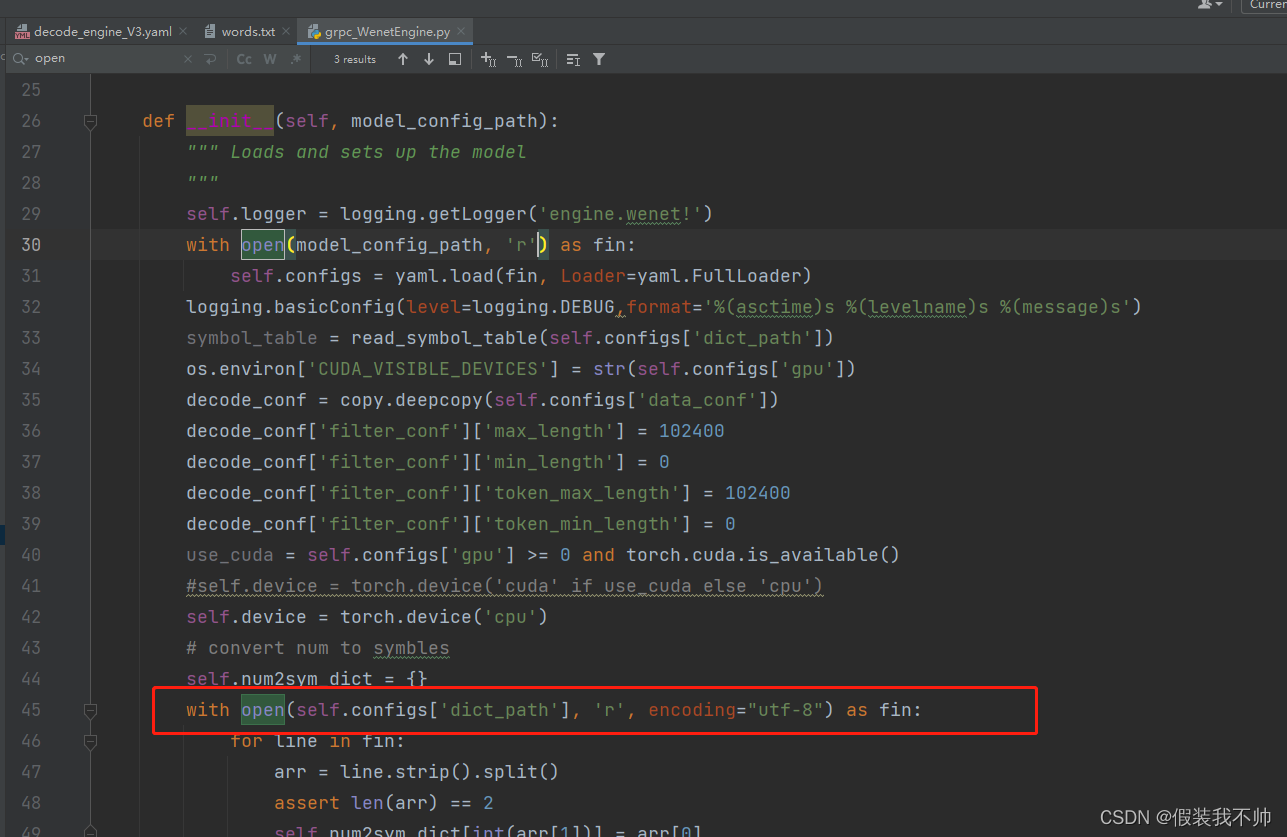
修改grpc_WenetEngine.py,将open打开修改为utf-8编码
运行即可
python server.py --model_config conf/decode_engine_V3.yaml --host 0.0.0.0 --port 9876 --vad_aggressiveness 3
参考
这个失败了
第二种 使用pyaudio+飞浆实现
安装步骤参考
安装gpu版本飞浆语音
这个方法监听的是系统声音
声音录制监听
import pyaudio
import wave
from enum import Enum
import numpy as np
import time
from threading import Thread
from paddlespeech.cli.tts.infer import TTSExecutor
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.text.infer import TextExecutor
def findInternalRecordingDevice(p):
"""获取内录设备序号,在windows操作系统上测试通过,hostAPI = 0 表明是MME设备"""
# 要找查的设备名称中的关键字
target = '立体声混音'
# 逐一查找声音设备
for i in range(p.get_device_count()):
devInfo = p.get_device_info_by_index(i)
# print(devInfo)
if devInfo['name'].find(target) >= 0: # and devInfo['hostApi'] == 0:
# print('已找到内录设备,序号是 ',i)
return i
print('无法找到内录设备!')
return -1
class AudioState(Enum):
'''标记音频操作当前的状态'''
LISTENING = 1 # 监听状态
RECORDING = 2 # 录制状态
PLAYING = 3 # 播放状态
p = pyaudio.PyAudio()
INTERNAL_RECORDING_DEVICE_ID = findInternalRecordingDevice(p);
frames = []
stopWatch_Record = None
audioState = AudioState.LISTENING
VOICE_STD_THRESHOLD = 150
RECORD_MAX_SECONDS = 5 # 最多录制5s
AUDIO_RATE = 16000 #44100
AUDIO_CHANNEL =1 #2
asr = ASRExecutor()
def getStdOfVoiceFrame(in_data):
'''获取一帧音频信号的标准差'''
return np.std(np.frombuffer(in_data, dtype=np.short))
def handleVoice(frames):
'''处理接收到的声音信息'''
# 保存文件
# 语音转文字
print("处理接收到的声音")
localTime = time.strftime("%Y%m%d%H%M%S", time.localtime())
audio_name = localTime+".wav"
wf = wave.open(audio_name, 'wb')
# 设置音频参数
wf.setnchannels(AUDIO_CHANNEL)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(AUDIO_RATE)
# 写入数据
wf.writeframes(b''.join(frames))
# 关闭文件
wf.close()
result = asr(audio_file=audio_name,force_yes=True)
print(result)
def callback(in_data, frame_count, time_info, status):
global audioState
global frames
global stopWatch_Record
global RECORD_MAX_SECONDS
# 如果当前帧的std大于阈值且处于监听状态,开始录音
if audioState == AudioState.LISTENING and getStdOfVoiceFrame(in_data) >= VOICE_STD_THRESHOLD:
# matrixLed.scrollingChar()
# print(getStdOfVoiceFrame(in_data))
stopWatch_Record = time.time()
print('录制中...')
frames.append(in_data)
audioState = AudioState.RECORDING # 当前处于RECORDING状态
return (bytes(len(in_data)), pyaudio.paContinue) # 如果不是播放状态,应该输入空的数据流
# 如果当前处于RECORDING状态
if audioState == AudioState.RECORDING:
t0 = time.time() - stopWatch_Record
frames.append(in_data)
# 如果录音时长已经超过限定,停止录音,保存音频文件
if t0 > RECORD_MAX_SECONDS:
# handleVoice(frames)
audioState = AudioState.PLAYING # PLAYING状态
t1 = Thread(target=handleVoice, args=(frames,))
t1.start()
frames = []
print('处理完成')
return (bytes(len(in_data)), pyaudio.paContinue)
# 如果当前处于播放状态
if audioState == AudioState.PLAYING:
print("音频播放")
# data = wf.readframes(frame_count)
# wf.close()
audioState = AudioState.LISTENING
# return (data, pyaudio.paComplete)
return (bytes(len(in_data)), pyaudio.paComplete)
return (bytes(len(in_data)), pyaudio.paContinue)
def start():
stream = p.open(
input_device_index=INTERNAL_RECORDING_DEVICE_ID,
format=pyaudio.paInt16,
channels=AUDIO_CHANNEL, # 声道 1单声道 2双声道
rate=AUDIO_RATE,
input=True,
frames_per_buffer=1024,
stream_callback=callback
)
stream.start_stream()
print("开始监听...")
try:
while True:
while stream.is_active():
pass
stream.stop_stream()
stream.close()
stream = p.open(
input_device_index=INTERNAL_RECORDING_DEVICE_ID,
format=pyaudio.paInt16,
channels=AUDIO_CHANNEL,
rate=AUDIO_RATE,
input=True,
frames_per_buffer=1024,
stream_callback=callback
)
stream.start_stream()
print('开始监听...')
except Exception as e:
stream.stop_stream()
stream.close()
p.terminate()
raise e
if __name__ == '__main__':
if INTERNAL_RECORDING_DEVICE_ID < 0:
print("没有找到内置录音设备")
else:
start()















 2952
2952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











