







SparkUI其实是伴随作业运行时候会启动一个网页,我们访问网页就可以打开,链接其实在启动的时候日志里面会打印出来,比如说我的地址:

一般端口是4040,地址是Driver所在的地址,实际在公司里面呢,也会在日志里面输出这个地址,因为历史的信息是存在history服务器上面的,地址其实是会变化,但是不管如何都会在你作业上面输出的,如果没有就找公司平台开发人员提需求要他们改成有即可不改好的话可以直接说他们技术不行,给他们精神压力。
概念对应
Spark作业构成回顾
我是比较鼓励大家去官网查看一些信息的,参考 Cluster Mode Overview
,官网给出了Spark运行:
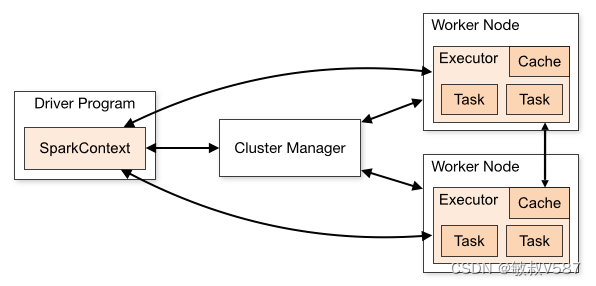
Spark中的关键术语,我整理过来,因为我们需要在Spark的UI上面一一进行对应起来:

这几个概念划分在我们的UI里面都有直接的体现 。
Application
app概念在一次提交提交的时候会生成一个appId,在Environment页面的Spark Properties上面。

上面记录了spark.app.id这个便是代表一个application了,从层级关系划分来说上来说,因为spark上面说app已经是在最顶层了,如果我们把Spark作业和Mapreduce的作业放在一起来看的话,我们就可以看到在Yarn模式下面,spark.app.id就是yarn生成的全局关系的applicationid。
另外的属性我们也解读一下,我的程序其实就是Spark自带的求圆周率的程序

Executors
Executors一进来一般是两种截然不同的反应
1、妈妈呀,都是啥呀,不想看啦,看不懂呀
2、妈妈呀,终于有信息啦~~
这个地方是有点像Spark的目录一样,类目比较细,其实里面就是对应Spark运行时候的各种元素,我们起码知道Spark总归是运行在JVM里面的嘛,我们在分布式环境中启动的一个个进程,这个时候就是在这个面板统计的,具体有哪些呢,Driver需要占用,还要我们实际的Worker也会申请,这部分资源Yarn 的分配环境则是来自nodemanager上面的,上面是汇总信息,表示整体的情况,具体其实就是执行过程中的信息,我们对这些信息说道说道:
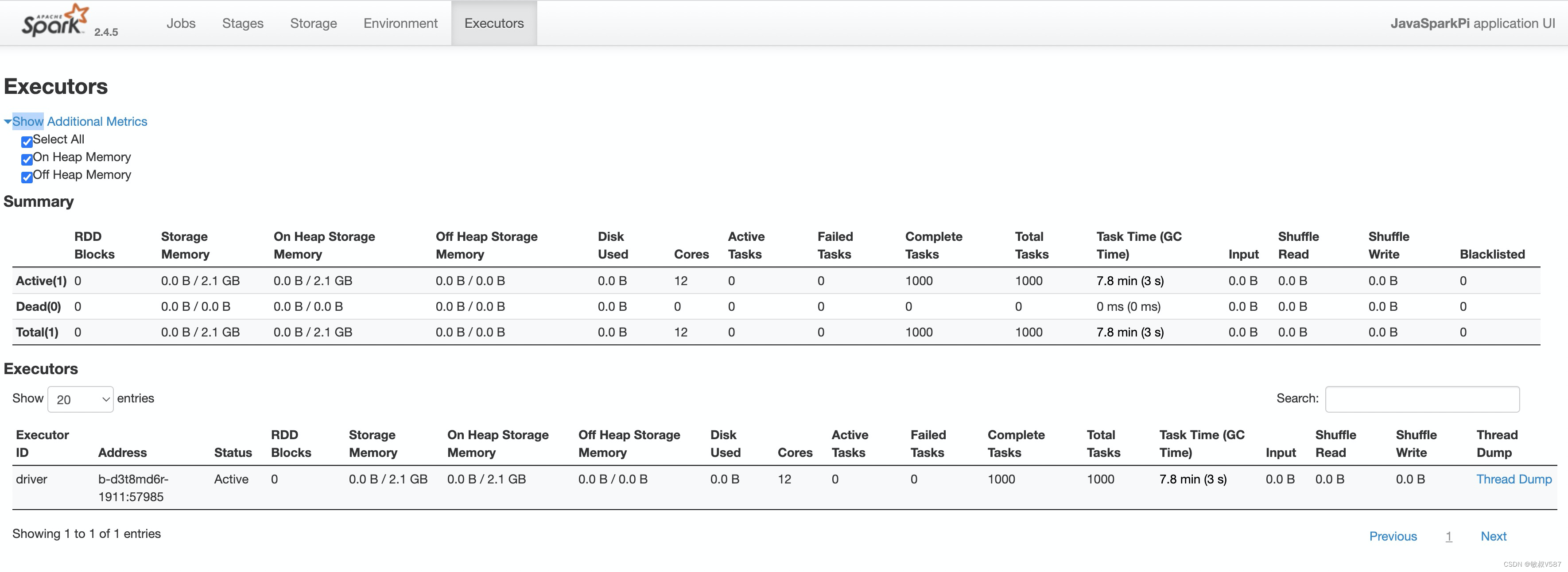
这些概念在学习Spark core的时候都有涉及的,我个人的建议是不断去尝试,去改变里面的数据信息,会有进一步的理解,光看解释没啥用,而且调优的过程本身就是使得整体优化,也是一个结果验证的过程。
Jobs
其实当我们需要看任务的时候,进入的首页是job页面,看到下面蓝色的进度没351/1000 (15 running),上面就是这个job有1000个stage啦,已经干到了351啦,这个地方大家肯定喜欢不断刷新,作业执行时候进度咔咔往后面走的感觉还是很爽,可是呢,往往出问题的时候就是前面很快执行完了,后面一步两步就搞很久甚至失败,这感觉跟迅雷下载一个大电影99%的进度卡在最后一下那种心情一样。
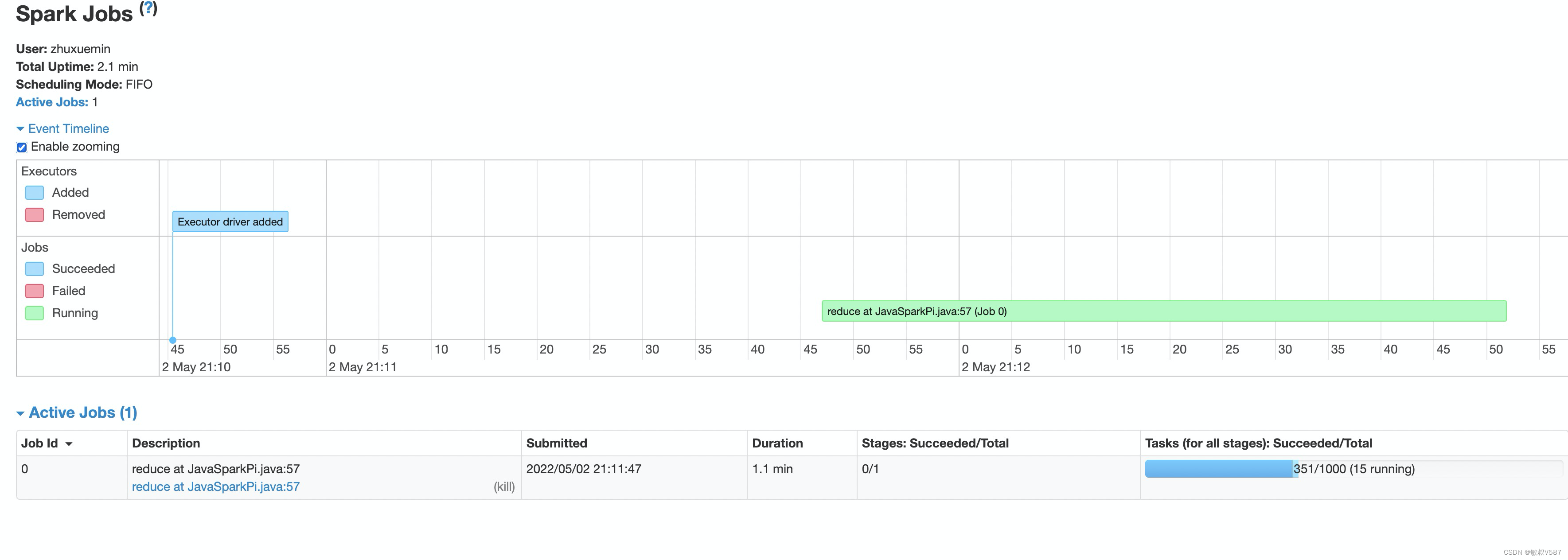
Spark页面设计一看就是程序员的画风特别强,那个zooming是指可以缩放的意思,然后缩放的是下面的时间甘特图,表示的是在什么时间点,执行到了哪个Stage,注意是Stage,因为job的下一层次划分就是Stage嘛。
下面执行是指正在活动的Job情况里面写着复数,说明是可以多个Job的,还记得前面写概念的时候Job的触发条件么,就是碰到Action就会触发。我们在PI程序中再加一次计算:
增加了Action操作,就出来两个了

stages
如果直接点页面上面的stage tab的话,进去看到的是所有Stage数据,因为我们job其实是很多个,里面展示的是所有job的stage,这个需要有区分,如果是对应job的stage,则从job的页面点击 description就可以,这个在作业比较复杂的时候是很容易迷路的。
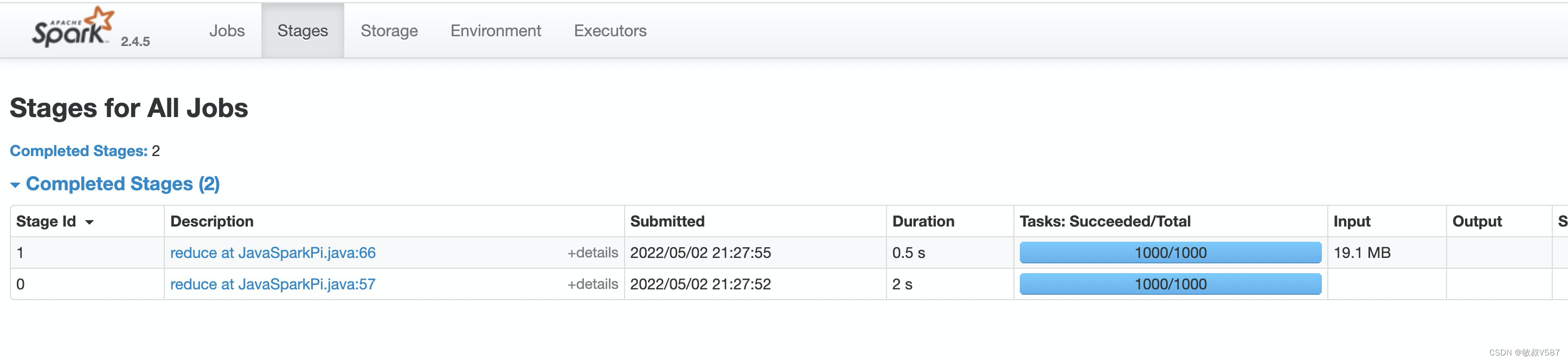
这里主要还是整体Stage的汇总信息,我们比较关注的是stage里面详细的信息,我们点击进去description信息,这个里面是一片豁然开朗的世界,很明显的就是信息丰富很多,没错我们想要优化,诊断,基本都是这个页面上面查询。有句话叫啥来着,浑身上下都是宝。然后我们来一波页面解读。
Details for Stage 1 (Attempt 0)
Stage在执行的其实有重试机制,这个标题Attempt 0表示第一次尝试,一般也就是第一次,需要在Yarn的层面,我们是可以看到对Attempt的生成关系的。
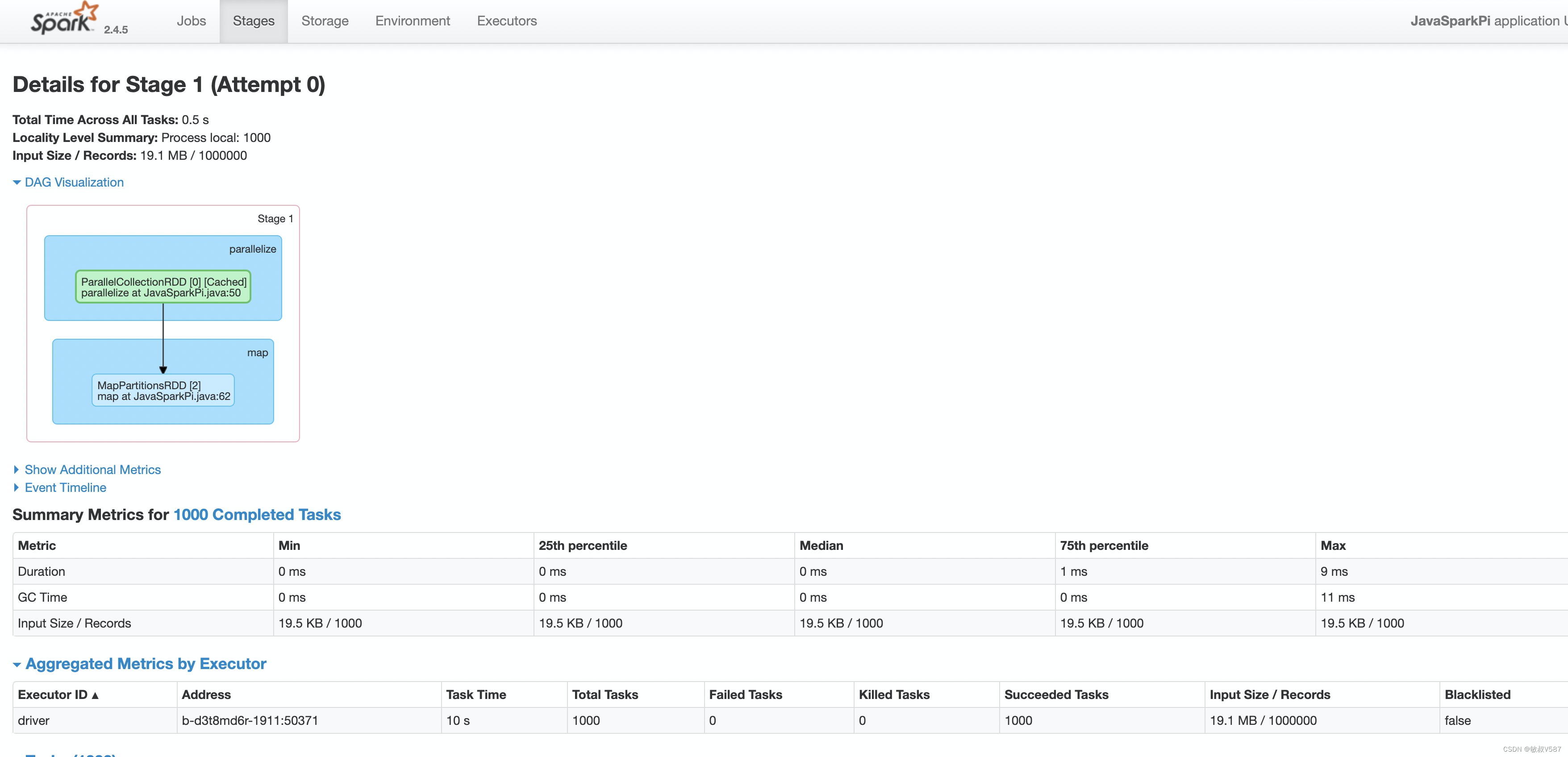

DAG Visualization
这个就是把Stage里面dDag展示出来,非常喜欢的地方。dag可以描述各个数据操作的拓扑关系,建议对各种算子都测试测试
Event Timeline
Stage里面时间线表示的是task执行的情况,通常我们在这里可以发现长尾,上面也有一些可选展示,我们可以自定义。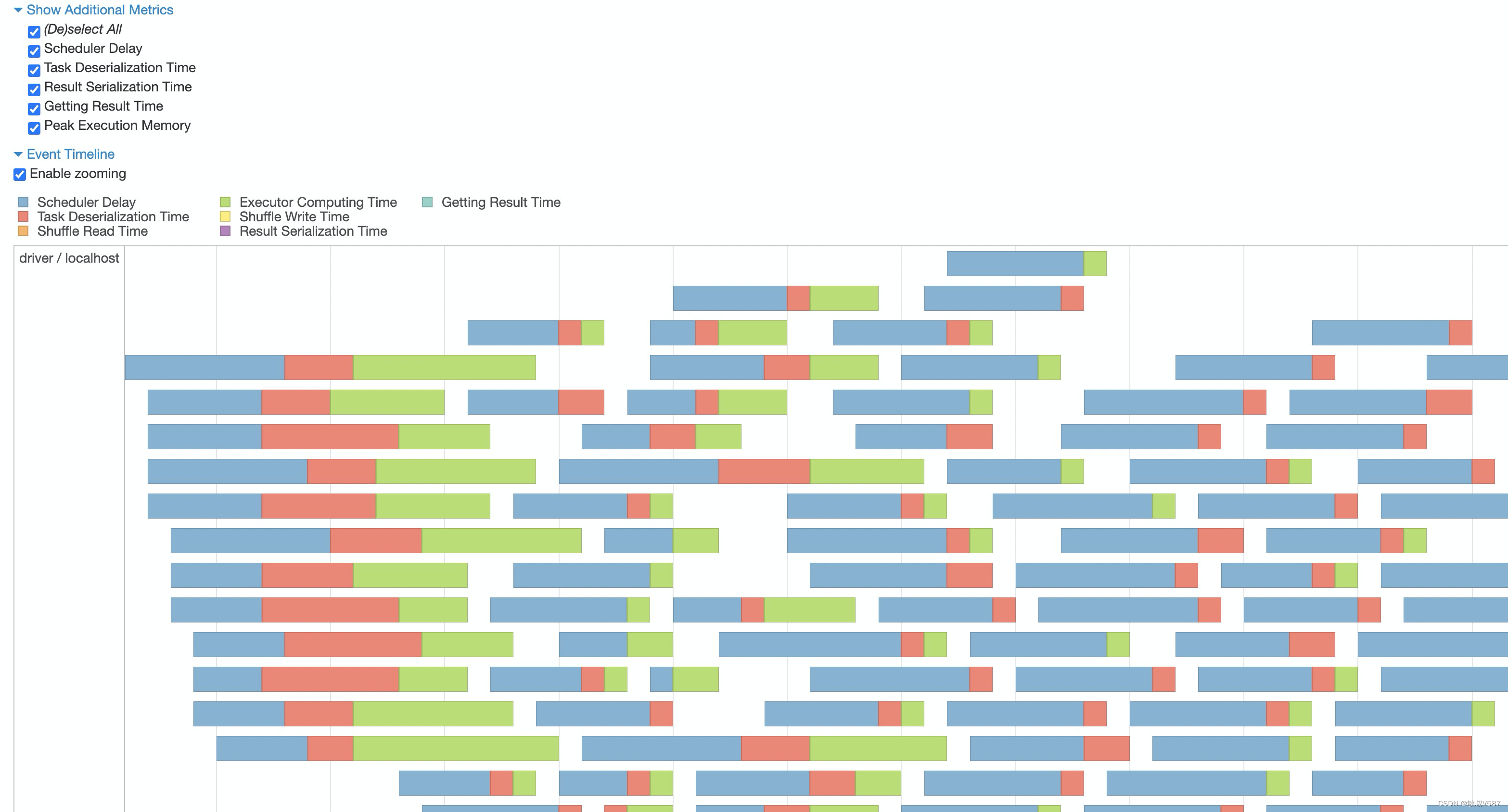
Summary Metrics
汇总信息统计的是所有task执行情况,因为task其实是会非常多的,所以各项指标还在最小、25%分位点、中位数、75%分位点、最大值进行展示,同时这些指标的分布我们可以进行一些有效的判断。

指标项说明:

这个面板上面在不同的Case下面其实可以判断出一些问题,我举几个例子,说明一些这些数据的场景。
实战技巧分析
Duration执行耗时,我们可以观察平均的耗时,如果平均的时间就很久,说明task内部处理比较久,那么实际task内部为什么久呢,又需要进一步判断,比如说数据量过大,那就配合一下inputSize分析,再比如说里面有性能很低的udf,再或者机器负荷很高,这种时候可以配合GCTime分析。再比如我们可以看到平均耗时不高,但是Max或者75%很高,这种就是典型的数据倾斜了,进一步去分析为什么出现倾斜情况。
Scheduler Delay 这个值很久的时候是经常的问题是执行很久,很容易被误会成别的问题,其实这个数据很大的时候表示调度上申请资源很久,进一步判断是否是集群资源不足,所以正确的方式是提高优先级或者增加资源,但是整体资源匮乏的时候,我们的做法反而是降低并行度。
Task Deserialization 这个是表示序列化时间,任务在提交worker之前,都是需要进行序列化,啥时候序列化会很久呢,伴随大量的复杂代码传输,或者有资源的加载,这种很可能传输很久,还有就是序列化方式啦,或者集群worker抖动都有情况发生。
Result Serialization Time
在计算的结果数据内容很大的时候,也会出现拉取结构慢的情况
Peak Execution Memory 执行时内存使用的峰值,这个内存是在一些内部的数据结构创建时候有关例如shuffles, aggregations and joins阶段,这个结果是在所有task执行结果中获取的一个大概的峰值,就表示计算过程中疯狂new对象的时候导致某次内存申请激增,这种情况会导致毛刺现象。
tasks
task则是具体某一个task都执行情况,用于更加细致的分析,需要注意的是task其实是会很多,找起来很困难,要借助面板的排序操作会比较好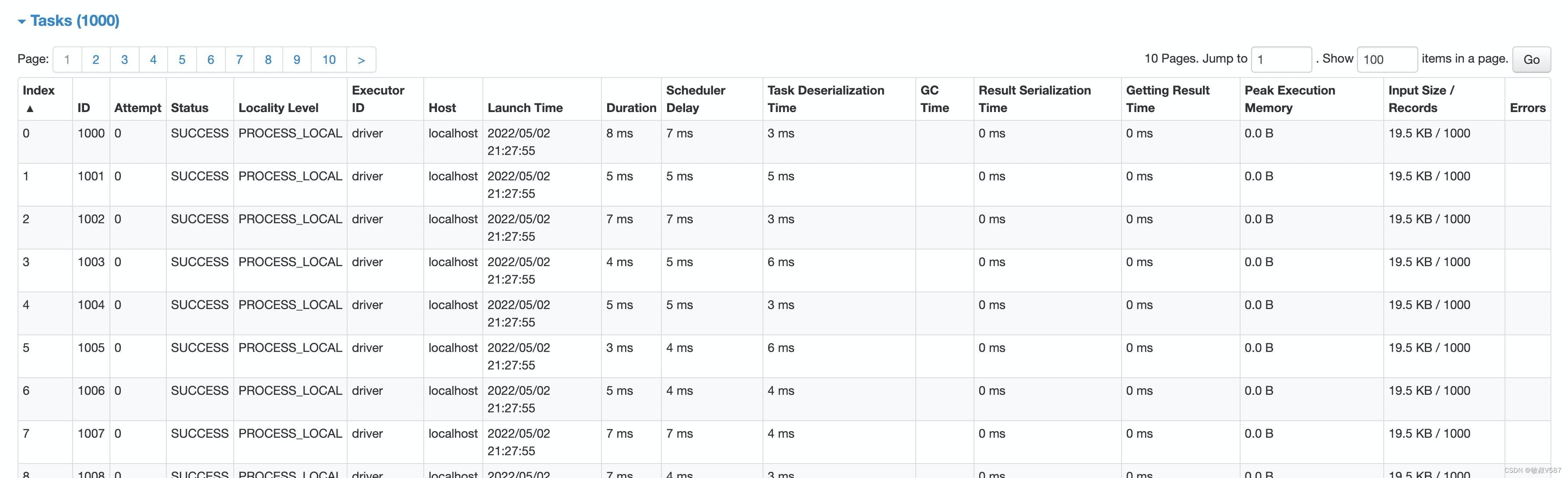














 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









