







集合有几种?
Java集合框架主要包括两种类型的容器,一种是集合(Collection),另一种是图(Map)。Collection接口又有3种子类型,List、Set和Queue,再下面是抽象类:ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap等,Map常用的有HashMap,LinkedHashMap等。
集合类可以分为两组:线程安全和非线程安全的。
JAVA中给集合赋值举例
Set<String>params=new HashSet<String>();
Params.add(“param one”);
Params.add(“param two”);也可以简写为
Set<String>params=new HashSet<String>(){
{
add(“param one”); add(“param two”);
}
}
Map map=new HashMap<String,String>(){
{
Put(“key1”,”value1”);
Put(“key2”,”value2”);
}
};小扩展:
List<? extends T>
List<? super T>
"Producer Extends,Consumer Super"(生产者用Extends,消费者用Super)
ArrayList和Vector的区别?
同步性:Vector是线程安全的,也就是说它的方法间是线程同步的,而ArrayList是线程不安全的,它的方法之间是线程不同步的,因此,当只有一个线程会访问到集合时,ArrayList的效率会更高;而当有多个线程访问集合时,使用Vector的好处是不需要自己编写线程安全的代码。数据增长:ArrayList和c++中的Vector都有一个初始的容量大小,当欲存储的元素个数超过了容量时,就需要增加ArrayList和Vector的存储空间,Vector增加原来的一倍,ArrayList增加原来的0.5倍。
**ArrayList和LinkedList区别?
ArrayList以数组的方式来实现List接口,特性是可以使用索引的方式来快速定位对象的位置,快速的随机取得对象的需求,使用ArrayList实现执行效率上会比较好。
而linkedlist在进行insert和remove动作时在效率上要比Arraylist好。
扩容原理:ArrayList容量能自动增长,不是线程安全的,所以限在单线程环境下使用。实现了Serializable接口,实现了RandomAccess接口,可通过下标序号进行快速访问。
在没指定initalCapacity时就会使用延迟分配对象数组空间,第一次插入元素时才分配10个对象空间。
若有20个数据需要添加,会分别在第一次,容量变为10,之后扩容1.5倍增长,及第11个数据添加时,变为15的容量。
HashMap
存储结构为数组+链表+红黑树(从JDK1.8开始增加红黑树)
由于Hash函数难免出现index冲突的情况,当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可。
插入数据Put方法,获取数据Get方法
HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
默认的初始长度:16
| 注:红黑树(R-B Tree)是一种特殊的二叉查找树。 特性之一:如果一个节点是红色的,则它的子节点必须是黑色的;从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。 关键性质:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。这一性质保证了树的大体是平衡的。查找、删除时间复杂度均为O(lgn);存储有序数据,采用红黑树的例子有Java中的TreeSet和TreeMap。 添加和删除基本操作都会用到旋转。 |
HashMap和HashTable区别
主要从线程安全性、同步以及速度比较。
HashMap是非同步的,为了避免死锁,要自己添加同步功能。
HashTable是同步的,意味着多个线程可以共享一个HashTable。而在Java5及以上,HashTable的替代方案是ConcurrentHashMap,他们两者都用于多线程环境,但当HashTable的大小增加到一定的时候,性能会急剧下降,因为HashTable锁定的整个map。而ConcurrentHashMap引入了分割,按需要锁定某个部分,不需要迭代完成才能访问map。
另外,HashTable不允许null值(Key和Value都不可以),而HashMap允许使用null值。
初始化和扩容方式不同:
HashTable默认的初始大小为11,每次扩充容量变为原来的2n+1;HashMap默认的初始大小为16,每次扩充容量变为原来的2倍。
遍历方法不同:HashTable使用Enumeration遍历,而HashMap使用Iterator(fail-fast迭代器)进行遍历。
HashMap的重要性能参数:初始容量和负载因子。
初始容量是创建哈希表时桶的数量;
负载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之越小。
比较:hash碰撞及hashCode一致时,才会调用equals方法。
HashMap什么时候重写hashcode和equals方法,为什么需要重写?
ConcurrentHashMap的Key和Value不允许为null,源码中对这两个属性都先做空值判断,因为HashMap自身解决了空值二义性问题,而ConcurrentHashMap是线程安全的,如果get到null,之后再做ContainssKey判断,不能保证期间有其他线程的干扰。
HashMap均允许为null,排除了二义性问题。
HashMap会带来死链问题和扩容数据丢失问题。
ConcurrentHashmap
是由一个Segment数组和多个HashEntry数组组成,支持16个线程的执行并发写操作及任意数量线程的读操作。
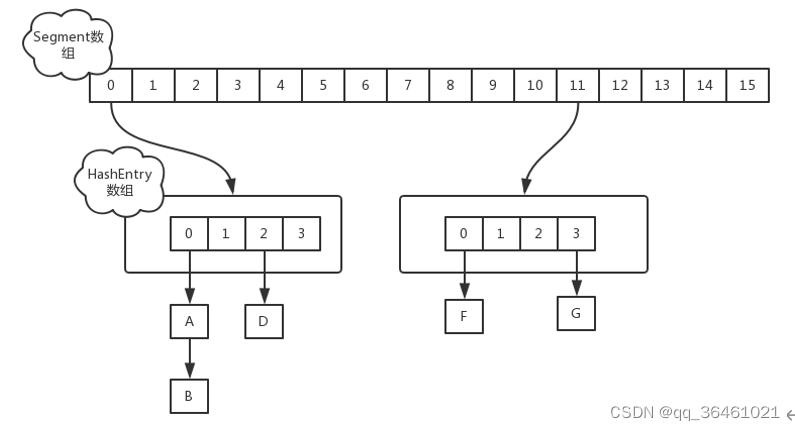
*ConcurrentHashMap为什么要做高低位的划分?
其源码中有这一句 (f = tabAt(tab, i = (n - 1) & hash)) == null ;通过(n-1) & hash来获得在table中的数组下标来获取节点数据。假设数组长16,转二进制【0001 0000】,减1后得【0000 1111】,假如某个key的hash值=9,对应的二进制是【0000 1001】,按照(n-1) & hash的算法 0000 1111 & 0000 1001 =0000 1001 , 运算结果是9 。
数组长16变成了32,那么(n-1)的二进制是 【0001 1111】 仍然以hash值=9的二进制计算为例 0001 1111 & 0000 1001 =0000 1001 ,运算结果仍然是9 。
所以对于高位,直接增加扩容的长度,当下次hash获取数组位置的时候,可以直接定位到对应的位置。
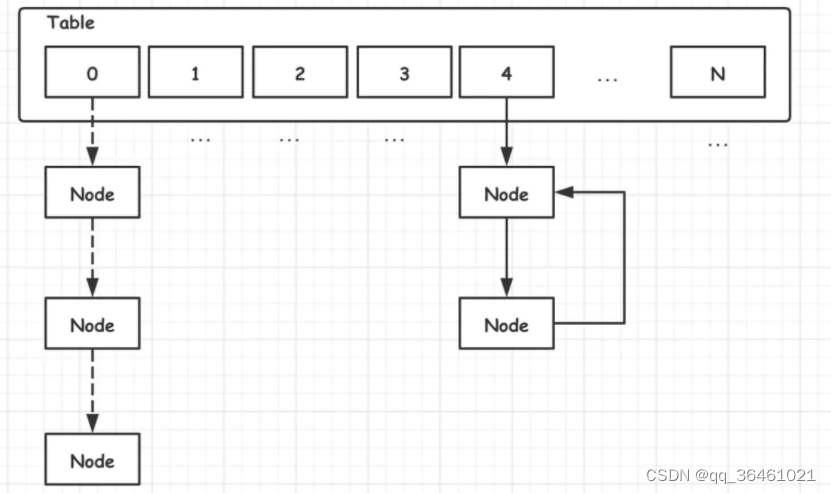
**造成死链问题的原因是因为有以下的实现:
//多线程并发扩容时,生成新数组采用头插入法,导致新链表元素的逆序排,会出现环形链表
void transfer(Entry[] newTable) {
Entry[] src = table; int newCapacity = newTable.length;
//从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j]; if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e; e = next;
} while (e != null);
}
}
}
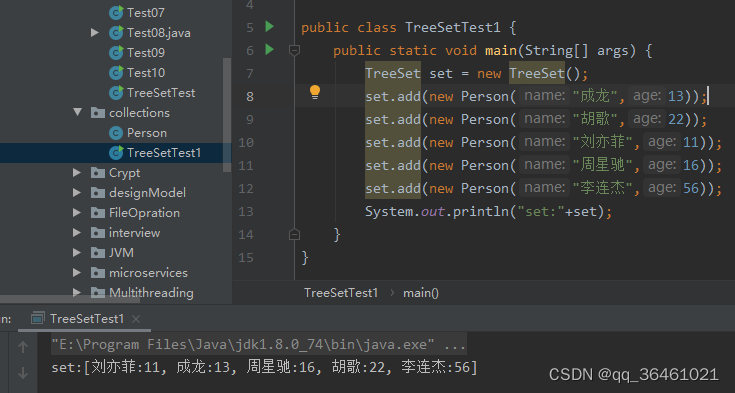
treeSet
存储有序,不重复,key不可以为空,value可以为null。
collection和collections区别
collection是一个集合接口,所有集合都是它的子类。
collections是一个包装类,包含了比如排序、搜索和线程安全等静态方法,不能被实例化。
Collections.sort(**);//当比较英文姓名时,例如Karl M、Steven Lee、John O、Tom M,按照英文先姓后名进行排序->Steven Lee、Karl M、Tom M、John O















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









