






ARPANET协议是如何工作的
本文译自:How the ARPANET Protocols Worked
ARPANET 证明可以使用标准化协议连接制造商截然不同的计算机,从而永远改变了计算。在我 关于 ARPANET 的历史意义的帖子中,我提到了其中的一些协议,但没有详细描述它们。所以我想仔细看看他们。我还想看看这些早期协议的设计有多少在我们今天使用的协议中得以保留。
ARPANET 协议,就像我们的现代互联网协议一样,被组织成层。1较高层的协议运行在较低层的协议之上。今天的 TCP/IP 套件有五层(物理层、链路层、网络层、传输层和应用层),但 ARPANET 只有三层——或者可能是四层,这取决于你如何计算它们。
我将解释这些层中的每一层是如何工作的,但首先要说明一下谁在 ARPANET 中构建了什么,你需要知道这一点才能理解为什么这些层被按原样划分。
一些快速的历史背景
ARPANET 由美国联邦政府资助,特别是国防部高级研究计划局(因此得名“ARPANET”)。美国政府没有直接建设网络;相反,它把这项工作外包给了一家名为 Bolt、Beranek 和 Newman(通常称为 BBN)的波士顿咨询公司。
反过来,BBN 处理了实施网络的许多责任,但不是全部。BBN 所做的是设计和维护一台称为接口消息处理器 (Interface Message Processor, IMP) 的机器。IMP 是一台定制的霍尼韦尔小型计算机,其中一台交付给全国每个要连接到 ARPANET 的站点。IMP 充当每个主机站点最多四台主机的 ARPANET 网关。它基本上是一个路由器。BBN 控制在 IMP 上运行的软件,将数据包从 IMP 转发到 IMP,但该公司无法直接控制将连接到 IMP 并成为 ARPANET 上的实际主机的机器。
主机由作为网络最终用户的计算机科学家控制。这些在全国各地的主机站点的计算机科学家负责编写允许主机相互交谈的软件。IMP 使主机能够相互发送消息,但除非主机就消息使用的格式达成一致,否则这并没有多大用处。为了解决这个问题,来自不同主机站点的大部分研究生组成的杂牌团队组成了网络工作组,该工作组试图指定主机使用的协议。
因此,如果您想象在 ARPANET 上进行一次成功的网络交互(例如发送电子邮件),则使交互成功的某些工程是一组人 (BBN) 的责任,而其他工程是负责另一组人员(网络工作组和每个主机站点的工程师)。这种组织和后勤方面的偶然事件可能在激发用于 ARPANET 协议的分层方法方面发挥了重要作用,这反过来又影响了用于 TCP/IP 的分层方法。
好的,回到协议
 阿帕网协议层次结构。
阿帕网协议层次结构。
协议层被组织成一个层次结构。最底层是“0 级”。2个从某种意义上说,这一层不算数,因为在 ARPANET 上,这一层完全由 BBN 控制,因此不需要标准协议。0 级管理数据如何在 IMP 之间传递。在 BBN 内部,有管理 IMP 如何执行此操作的规则;在 BBN 之外,IMP 子网络是一个黑盒子,它只传递您提供给它的任何数据。所以 0 级是一个没有真正协议的层,在一套众所周知和商定的规则的意义上,它的存在可以被运行在 ARPANET 主机上的软件忽略。粗略地说,它处理了当今 TCP/IP 套件的物理层、链路层和互联网层下的所有内容,甚至还有相当多的传输层,这是我将在本文末尾回过头来讨论的内容.
“1 级”层建立了 ARPANET 主机和它们所连接的 IMP 之间的接口。如果你愿意,它是一个 API,用于 BBN 构建的 0 级黑盒。它在当时也被称为 IMP 主机协议。必须编写和发布该协议,因为在首次建立 ARPANET 时,每个主机站点都必须编写自己的软件来与 IMP 接口。除非 BBN 给他们一些指导,否则他们不知道该怎么做。
IMP-Host Protocol 由 BBN 在一份名为BBN Report 1822的冗长文档中指定。随着 ARPANET 的发展,该文档被多次修订;我在这里要描述的是 IMP-Host 协议最初设计时的大致工作方式。根据 BBN 的规则,主机可以向其 IMP 传递不超过 8095 位的消息,并且每条消息都有一个领导**者,其中包括目标主机号和称为链接号的东西。3个 IMP 将检查指定主机号,然后尽职地将消息转发到网络中。当从远程主机接收到消息时,接收方 IMP 会将目标主机号替换为源主机号,然后再将其传递给本地主机。消息实际上并不是在 IMP 之间传递的——IMP 将消息分解成更小的数据包以便通过网络传输——但主机隐藏了这个细节。
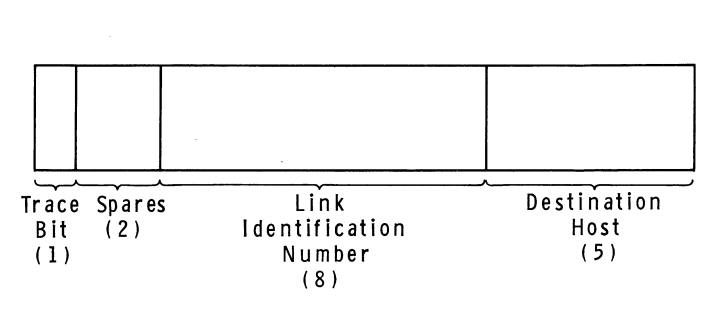 截至 1969 年的 Host-IMP 消息领导者格式。来自BBN Report 1763的图表。
截至 1969 年的 Host-IMP 消息领导者格式。来自BBN Report 1763的图表。
链接号可以是 0 到 255 之间的任何数字,有两个用途。它被更高级别的协议用于在网络上的任意两台主机之间建立多于一个的通信通道,因为可以想象在任何给定时间可能有不止一个本地用户与同一目标主机对话。(换句话说,链路号允许主机之间的通信多路复用。)但它也用于第 1 层以控制主机之间可以发送的流量,这是防止更快的计算机压倒更慢的计算机所必需的那些。按照最初的设计,IMP 主机协议限制每个主机在每个链接上一次只能发送一条消息。一旦给定主机通过链接将消息发送到远程主机,在沿同一链路发送下一条消息之前,它必须等待从远程 IMP 接收到一种称为 RFNM(请求下一条消息)的特殊消息。后来为了提高性能对该系统进行了修订,允许主机在给定时间将最多八条消息传输到另一台主机。4个
“2 级”层是事情真正开始变得有趣的地方,因为正是这一层和它上面的一层,BBN 和国防部完全留给学术界和网络工作组自己发明。第 2 层包括 Host-Host 协议,它首先在 RFC 9 中被勾画出来,并首先由 RFC 54 正式指定。ARPANET 协议手册中给出了对 Host-Host 协议更具可读性的解释。
主机-主机协议管理主机如何创建和管理 彼此之间的连接。连接是一台主机上的写套接字和**读套接字之间的单向数据管道在另一台主机上。“套接字”概念是在有限的 1 级链接设施之上引入的(请记住,链接号只能是 256 个值之一),以便为程序提供一种寻址远程主机上运行的特定进程的方法。读套接字为偶数,而写套接字为奇数;套接字是读套接字还是写套接字被称为套接字的性别。没有像 TCP 那样的“端口号”。连接可以通过在主机之间使用链路 0 发送的特殊格式的主机-主机控制消息来打开、操作和关闭,链路 0 是为此目的而保留的。一旦通过链路 0 交换控制消息以建立连接,就可以使用接收方选择的另一个链路号发送更多数据消息。
主机-主机控制消息由三个字母的助记符标识。当两个主机交换 STR(发送方到接收方)消息和匹配的 RTS(接收方到发送方)消息时建立连接——这些控制消息都称为连接请求消息。CLS(关闭)控制消息可以关闭连接。还有进一步的控制消息改变了数据消息从发送方发送到接收方的速率,需要再次确保更快的主机不会压倒较慢的主机。级别 1 协议已经提供的流量控制在级别 2 显然不够;我怀疑这是因为从远程 IMP 接收 RFNM 只是保证远程 IMP 已将消息传递到目标主机,而不是主机已完全处理该消息。
更高级别的协议都位于“级别 3”,即 ARPANET 的应用层。提供到另一台主机的虚拟电传打字连接的 Telnet 协议可能是这些协议中最重要的,但在这一级别还有许多其他协议,例如用于传输文件的 FTP 和用于发送电子邮件的协议的各种实验。
此级别中的一个协议与其他协议不同:初始连接协议 (ICP)。ICP 被认为是 3 级协议,但实际上它是一种 2.5 级协议,因为其他 3 级协议依赖于它。ICP 是必需的,因为主机-主机协议在第 2 层提供的连接只是单向的,但大多数应用程序需要双向(即全双工)连接来做任何有趣的事情。ICP 指定了一个两步过程,运行在一台主机上的客户端可以连接到另一台主机上长时间运行的服务器进程。第一步涉及使用服务器进程的众所周知的套接字号建立从服务器到客户端的单向连接。然后,服务器将通过已建立的连接向客户端发送一个新的套接字编号。在那时候,现有连接将被丢弃并打开两个新连接,一个基于传输的套接字号的读取连接和一个基于传输的套接字号加一的写连接。这种小舞蹈是大多数事情的必要前奏——例如,它是建立 Telnet 连接的第一步。
这完成了我们对 ARPANET 协议层次结构的提升。您可能一直希望我在某个时候提到“网络控制协议”。在我坐下来为这篇文章和我的最后一篇文章做研究之前,我肯定认为 ARPANET 运行在一个名为 NCP 的协议上。首字母缩略词偶尔用于指代整个 ARPANET 协议,这可能就是我有这个想法的原因。例如,RFC 801讨论了将 ARPANET 从“NCP”转换为“TCP”的方式,这听起来像是 NCP 是等同于 TCP 的 ARPANET 协议。但是阿帕网从来没有一个“网络控制协议”(即使大英百科全书这么认为),而且我怀疑人们错误地将“NCP”解包为“网络控制协议”,而实际上它代表的是“网络控制程序”。网络控制程序是运行在每个负责处理网络通信的主机中的内核级程序,相当于今天操作系统中的 TCP/IP 堆栈。RFC 801 中使用的“NCP”是一个转喻词,而不是协议。
与 TCP/IP 的比较
ARPANET 协议后来全部被 TCP/IP 协议取代(Telnet 和 FTP 除外,它们很容易适应在 TCP 之上运行)。鉴于 ARPANET 协议都是基于这样的假设,即网络是由单一实体 (BBN) 构建和管理的,而 TCP/IP 协议套件是为互联网设计的*,*一个网络的网络,在这个网络中,一切都将更加流畅,不可靠。这导致了我们的现代协议套件和 ARPANET 协议之间一些更直接明显的差异,例如我们现在如何区分网络层和传输层。ARPANET 中由 IMP 部分实现的类似传输层的功能现在由网络边缘的主机单独负责。
不过,我发现关于 ARPANET 协议最有趣的是,现在 TCP 中的这么多传输层功能如何在 ARPANET 上经历了一个不稳定的青春期。我不是网络专家,所以我拿出了我的大学网络教科书(Kurose 和 Ross,让我们开始吧),他们给出了传输层通常负责什么的非常好的概述。总结他们的解释,传输层协议必须至少做以下事情。这里的段基本上等同于ARPANET 上使用的术语消息:
- 提供进程之间的交付服务,而不仅仅是主机(传输层多路复用和多路分解)
- 在每个段的基础上提供完整性检查(即确保在传输过程中没有数据损坏)
传输层也可以像 TCP 一样提供可靠的数据传输,这意味着:
- 分段按顺序交付
- 没有片段丢失
- 段交付的速度不会太快,以至于它们会被接收方丢弃(流量控制)
似乎在 ARPANET 上对如何进行多路复用和多路分解以便进程可以通信存在一些困惑——BBN 在 IMP-Host 级别引入了链路号来执行此操作,但事实证明在 Host 上套接字号是必需的-无论如何,主机级别高于此。然后链路号只是用于 IMP-Host 级别的流量控制,但 BBN 似乎后来放弃了它,转而支持在唯一的主机对之间进行流量控制,这意味着链路号开始时只是为了这个超载的东西基本上成为退化。TCP 现在改用端口号,分别对每个 TCP 连接进行流量控制。进程到进程的多路复用和多路分解完全存在于 TCP 内部,不会像 ARPANET 那样泄漏到较低层。
同样有趣的是,根据 Kurose 和 Ross 如何发展 TCP 背后的思想,ARPANET 开始于 Kurose 和 Ross 所说的严格的“停止等待”方法,以便在 IMP 主机上进行可靠的数据传输等级。“停止等待”方法是传输一个段,然后拒绝传输任何更多段,直到收到对最近传输的段的确认。这是一种简单的方法,但它意味着只有一个网段在整个网络中运行,这使得协议非常慢——这就是为什么 Kurose 和 Ross 提出“停止并等待”只是通往一个功能齐全的传输层协议。在 ARPANET 上,“停止并等待”是一段时间内的工作方式,因为在 IMP 主机级别,在发送任何进一步的消息之前,必须收到对每个传出消息的响应的下一条消息请求。为了公平起见,BBN 起初认为这对于提供主机之间的流量控制是必要的,因此减速是有意的。正如我已经提到的,后来为了更好的性能放宽了 RFNM 要求,并且 IMP 开始将序列号附加到消息中并以大致相同的方式跟踪正在传输的消息的“窗口”今天的 TCP 实现。5个
因此,ARPANET 表明,如果让每个人都同意一些基线规则,异构计算系统之间的通信是可能的。也就是说,正如我之前所说,ARPANET 最重要的遗产。但我希望仔细研究这些基线规则可以揭示 ARPANET 协议对我们今天使用的协议的影响有多大。在主机和 IMP 之间分担传输层责任的方式肯定有很多尴尬,有时是多余的。回想起来,主机最初只能通过任何给定链接一次只向彼此发送一条消息,这真的很有趣。但是 ARPANET 实验是一个独特的机会,可以通过实际构建和运营网络来吸取这些教训。


















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









