







需要思考的问题:
- 前面我们已经完成了对ArrayBox、LinkedBox完成了封装,完成了对其功能的实现。
如果我们站着一个用户的角度去思考问题 提供两个工具类,他们的方法名称以及用法都是一样的, 能不能抽象一层出来,作为一个标准对外进行提供使用?或者以后用户看到了Box的类,就可以直接知道这个类所提供的功能,比如添加元素、删除元素、查询元素这几个主要的方法。 - 用户根据自己的需要使用不同的容器(比如:是要追求查询快,还是说追求删除、添加元素速度快)再比如后续我们有着更多的关于Box提供的方法是一样的,但是底层的使用存储的数据结构是不一样的,他们针对使用的场景也是不一样的。
- 我们就引出接口的一个概念,对Box使用标准做一个规范,直接定义标准。这样既可以用户使用起来方便,以后看到是关于Box就可以知道其提供的功能。后续如果有着更好的处理方法来满足容器的增删查的功能,也可以直接进行扩展。
- 我们在源码中看list的整个集合体系中,也是这样的设计思想,顶层的List接口规定这个类必须实现的能力
顶层设计:接口的的引入
将统统一标准的方法抽取出来
package com.hsc.box;
/**
* 思考的问题:
* 前面我们已经对ArrayBox和LinkedBox完成了封装 如果我们站着一个用户的角度去思考问题 提供两个工具类,他们的方法名称以及用法都是一样的,
* 能不能抽象一层出来,作为一个标准对外进行提供使用?或者以后用户看到了Box的类,就可以直接知道这个类所提供的功能,比如添加元素、删除元素、查询元素这几个主要的方法。用户根据自己的需要使用不同的容器(比如:是要追求查询快,还是说追求删除、添加元素速度快)
* 再比如后续我们有着更多的关于Box提供的方法是一样的,但是底层的使用存储的数据结构是不一样的,他们针对使用的场景也是不一样的。
* 我们就引出接口的一个概念,对Box使用标准做一个规范,直接定义标准。这样既可以用户使用起来方便,后续如果有着更好的处理方法来满足容器的增删查的功能,也可以直接进行扩展
*/
public interface Box<T> {
/**
* 【主要的方法】:规定一个标准,添加的一个元素的方法,如果子类或实现也属于Box的这个体系,就必须有添加元素的这个能力
* public abstract 权限修饰符和特征修饰符接口默认携带的,可以写也可以不写
*
* @param element
* @return
*/
public abstract boolean add(T element);
/**
* 【主要方法】:接口中定义了一个标准,查询的方法:根据索引的下标,获取到对应的元素
*
* @param index
* @return
*/
public abstract T get(int index);
/**
* 【主要方法】:接口中定义了一个标准,删除一个元素的方法:根据索引的下标,删除对应元素。如果子类或实现也属于Box的这个体系,就必须有添加元素的这个能力
*
* @param index
* @return
*/
public abstract T remove(int index);
/**
* 【非主要方法】:指定位置,添加指定元素的方法,如果这个方法不是整个Box体系中必须提供的能力,我们可以不一定在接口中强制规定,因为接口中规定了,实现类进行实现了,就必须实现该方法
*
* @param index
* @param element
* @return
*/
public abstract boolean add(int index, T element);
/**
* 【非主要方法】添加整个容器的方法:我们还可以定义一个添加所有元素的方法。但是这个方法也不是子类中必须要实现,或者说是后续规范要做的功能,我们可以不一定在接口中强制规定,我们放在抽象类,中间层中实现
* @param box
*
*/
// public abstract void addAll(Box<T> box);
/**
* 【非主要方法】在指定的位置,添加所有元素的方法,个方法也不是子类中必须要实现,或者说是后续规划要实现的功能,我们可以不一定在接口中强制规定,我们放在抽象类,中间层中实现
* @param index
* @param box
* @return
*/
// public abstract void addAll(int index,Box<T> box);
}
中间层:抽象类的引入
思考的问题:添加这个中间层抽象类的目的是什么呢?
- 我们在顶层接口中抽出了一层,关于整个Box体系需要提供的方法(能力),这样不但可以用户使用起来更加的方便,也给后续的如果产生新的工具类,有了一个良好的约束。
- 但是有一个不好的地方,如果子类直接进行实现最上层的接口,就必须要实现所有的抽象方法,这对于后续的子类(扩展类)并不是很友好。
- 这时我们使用抽象类能够很好解决这个问题,可以对接口的方法进行实现,自己本身也可以定义抽象方法,如果最终的实现类继承了该抽象方法,只需要实现最主要的功能即可,提供最主要的能力。
- 这里也很好体现了一个设计模式的思想:缺省适配器模式
- 也体现了面向对象的三大特性:封装、继承、多态
package com.hsc.box;
/**
* 思考的问题:添加这个中间层抽象类的目的?
* 我们在接口中抽出了一层,关于整个Box体系需要提供的方法(能力),这样不但可以用户使用起来更加的方便,也给后续的如果产生新的工具类,有了一个良好的约束。
* 但是有一个不好的地方,如果子类直接进行实现最上层的接口,就必须要实现所有的抽象方法,这对于后续的子类(扩展类)并不是很友好。
* 添加这个中间层抽象类的目的
* 这时我们使用抽象类能够很好解决这个问题,可以对接口的方法进行实现,自己本身也可以定义抽象方法,如果最终的实现类继承了该抽象方法,只需要实现最主要的功能即可,提供最主要的能力。
* 这里也很好体现了一个设计模式的思想:缺省适配器模式
* 也体现了面向对象的三大特性:封装、继承、多态
*/
public abstract class AbstractBox<T> implements Box<T> {
//声明一个子类共有的属性
private int size;
/**
* 【主要的方法】:规定一个标准,添加的一个元素的方法,如果子类或实现也属于Box的这个体系,就必须有添加元素的这个能力
* public abstract 权限修饰符和特征修饰符接口默认携带的,可以写也可以不写
*
* @param element
* @return
*/
public abstract boolean add(T element);
/**
* 【主要方法】:接口中定义了一个标准,查询的方法:根据索引的下标,获取到对应的元素
*
* @param index
* @return
*/
public abstract T get(int index); //抽象类这一层这个方法,可以写也可以不写,如果具体的类实现了AbstractBox<T>,就必须实现Box<T>接口的主要的方法
/**
* 【主要方法】:接口中定义了一个标准,删除一个元素的方法:根据索引的下标,删除对应元素。如果子类或实现也属于Box的这个体系,就必须有添加元素的这个能力
*
* @param index
* @return
*/
public abstract T remove(int index);//抽象类这一层这个方法,可以写也可以不写,如果具体的类实现了AbstractBox<T>,就必须实现Box<T>接口的主要的方法
/**
* 【子类中共有的方法】:如果我们顶层接口中,没有设计有这个size方法,但是我们的子类中都有这个方法,此时我们就可以将该方法抽到这里来,可以避免代码的冗余
*
* @return
*/
public int size(){
return size;
};
/**
* 【非主要方法】:指定位置,添加指定元素的方法,如果这个方法不是整个Box体系中必须提供的能力,我们可以不一定在接口中强制规定,因为接口中规定了,实现类进行实现了,就必须实现该方法
*
* @param index
* @param element
* @return
*/
public abstract boolean add(int index, T element);//抽象类这一层这个方法,可以写也可以不写,如果具体的类实现了AbstractBox<T>,就必须实现Box<T>接口的主要的方法
/**
* 【非主要方法】添加整个容器的方法:我们将接口中非主要实现功能或者说是后续规划要实现的功能,放在抽象类这一层做实现,
* 这样我们的具体继承我们的抽象类的时候,只需要实现接口中定义的主要方法就可以了
*
* @param box
* @return
*/
public boolean addAll(Box<T> box) {
throw new NuSupportedOperationException();
}
/**
* 【非主要方法】在指定的位置,添加所有元素的方法,个方法也不是子类中必须要实现,或者说是后续规划要实现的功能,放在抽象类这一层做实现,
* 这样我们的具体继承我们的抽象类的时候,只需要实现接口中定义的主要方法就可以了
*
* @param index
* @param box
* @return
*/
public boolean addAll(int index, Box<T> box) {
throw new NuSupportedOperationException();
}
/**
* 再且,我们这里还可以添加一些子类共有的方法,但是父类接口中没有进行规定的
*/
}
异常引入:自定义异常引入
这里我们定义异常类,作为对未实现的方法一个异常反馈,如果用户调用用到我们未做具体实现,但是规划要做的方法,我们可以直接进行异常的反馈
package com.hsc.box;
/**
* 这里我们定义异常类,作为对未实现的方法一个异常反馈,如果用户调用用到我们未做具体实现,但是规划要做的方法,我们可以直接进行异常的反馈
*/
public class NuSupportedOperationException extends RuntimeException{
}
另外自定义异常的演示
package com.hsc.box;
public class BoxIndexOutOfBoundsException extends RuntimeException {
public BoxIndexOutOfBoundsException() {
}
public BoxIndexOutOfBoundsException(String msg) {
super(msg);
}
}
ArrayBox实现
package com.hsc.box;
/**
* 从一个用户的需求去思考:
* 数组作为一个小的容器去存储数据的话,他的长度是固定的,而且用起来也麻烦
* 能否设计一个容器,能做一些类似数组存取的事情呢?更加方便我们的使用呢?
* 1、数组的长度不可变,
* 2、而且删除添加数据也麻烦,能否简化这个事情呢?
* 3、总结起来就是,我只管用,其他底层的细节不管
* 4、从而可以推导出来ArrayList的产生,
* <p>
* 做完我们发现(ArrayList推导):
* ArrayBox特点:
* 适合存储数据长度是可变的
* 适合遍历,底层其实就是一个动态的数组,数组底层的内存地址是连续的
* 不适合添加和删除元素,因为需要将原来的数组的中的数据挨个循环移动元素,性能会很慢
* 上面的封装ArrayBox做的事情是不是就是我们经常使用到的集合ArrayList呢,
* ArrayList的底层的实现也是类似的,包括其功能特性
* <p>
* 思考(LinkedList推导):
* 由于底层使用的是数组这个数据结构从而决定了这个性能的特性,或者说性能的瓶颈所在,能否有新的容器能够很好的解决这个问题呢?
* 如果我们寻求新的容器进行存储,不再使用数组来进行存在,我们能否用对象来进行存储元素呢?而且对象的创建是存放在堆内存空间的,对象中声明的属性是否也就可以进程元素的存储
* 将每次要存储的元素创建对象来存储,用面向对象的思想进行管理,这样删除和添加数据的时候,只要操作内存的地址是不是就可以了呢,从而提升效率,每个对象作为一个节点对象来进行存储,
* 这样的结构是不是就很像我们经常使用的LinkedList,LinkedList底层就是使用的链表进行存储的。
*
* 思考:可扩展性(面向对象思想)思考:代码的可扩展性,健壮性
* 实现类中继承了一个抽象类,并且实现了接口中定义的主要方法,做了一个良好的规范
*/
public class ArrayBox<T> extends AbstractBox<T>{
//默认大小的容量的数值
private static final int DEFAULT_CAPACITY = 10;
//这里我们使用的数组来装数据,数组的特点是长度一旦确定就不能再次发生改变
private Object[] elementData;
//创建一个计数器。来记录容器的有效元素个数
private int size = 0;
/**
* 创建一个构造方法,当我们的ArrayBox对象创建时,就准备好一个数组,用来装数据
*/
public ArrayBox() {
//创建对象默认长度大小的数组,默认创建的长度为10的数组
//在这里我们可以思考一下,我们为何不直接写数字10呢?从代码的可读性去思考,如果我们代码是给别人使用的一个工具,是否有一个见明知意的效果呢?
elementData = new Object[DEFAULT_CAPACITY];
}
/**
* 重载构造方法,提供一个方法给使用者自己去设置容器的大小,初始化容量
*
* @param initialCapacity 初始化容量大小
*/
public ArrayBox(int initialCapacity) {
elementData = new Object[initialCapacity];
}
/**
* 设计一个方法,我们需要提供个什么样的返回值来进行结果的确认?
* 在面向对象的思想角度去,或者从执行的效率上,我们可以返回一个整型的类型也可以返回一个布尔类型的返回值,
* 对于用户来说,我知需要得到一个添加成功的返回值就可以了,所以我们这里选择返回的是一个布尔值
*
* @param element 泛型的支持:返回值直接使用用户传入的数据类型,
*/
public boolean add(T element) {
//1、当用户添加一个数据进来的时候,
// 第一:首先先对元素进行一个存储,第二:需要判断,确保我们的容器能否保存得下来
//所以此时我们需要设计一个方法确认当前的内部的数组容量能否装得下
//我们添加一个元素就说明实际的元素的个数就会加1,说明我们的容器至少需要的最小的容量是size+1才能存入数据
this.ensureCapacityInternal(size + 1);
//插入元素,我们从数组的后进行元素的添加,因为数组的索引是从0开始的,所以我们添加元素的下标刚好是当前实际元素数量+1,
// 比如:当前数组的实际个数size为5,我们插入的第6个元素的时候,第六个元素的数组的索引下标就是5了,所以可以直接拿size当做数组索引下标
//这里解释一下size++的含义:
// 当size++放在组合的计算时,先对size先赋值,后自增
//所以elementData[size++]
// 实际分为了两步的计算:1、elementData[size[size]= element:先根据数组的下标插入元素 2、size++ :赋值完后再对size本身加1,实际的数量加1
elementData[size++] = element;
//添加成功,返回
return true;
}
/**
* 设计一个方法的重载,指定位置添加指定的元素
*
* @param index
* @param element
*/
public boolean add(int index, T element) {
//确保当前的数组的容量够用
this.ensureCapacityInternal(size + 1);
//上面代码没有报异常,说明当前的数组的容量够用
//添加元素思路:将添加元素的index位置空出来,然后从size---index,挨个往后移动覆盖
for (int i = size - 1; i >= index; i--) {
elementData[i + 1] = elementData[i]; // i=7 i+1=8 elementData[8]= elementData[7]
// i=6 i+1=7 elementData[7]= elementData[6]
}
//将element元素存入index位置中
elementData[index] = element;
//添加完元素,size加1
size++;
return true;
}
/**
* 确认当前数组容量是否满足的方法
*
* @param minCapacity
*/
private void ensureCapacityInternal(int minCapacity) {
//判断当前我们操作的数组是否有空间装下以上的元素
if (minCapacity - elementData.length > 0) {
//证明当前的数组的容量比我们需要的容量要小,需要进扩容
//扩容的逻辑,直接设计一个新的方法去做,将我们需要最小的容量告诉方法,进行扩容创建
this.grow(minCapacity);
}
}
/**
* 扩容的方法
*
* @param minCapacity 最小需要的容量大小
*/
private void grow(int minCapacity) {
//获取旧数组的容量
int oldCapacity = elementData.length;
//根据一个算法进行扩容,这里使用的是旧数组的容量1.5倍进行扩容,作为新数组的长度
//扩容:原来的数组容量的1.5倍
//(oldCapacity >> 1) :这里为什么不直接用oldCapacity*1.5呢? 计算机底层是用二进制表示数字,直接进行右移动1位就是1.5的意思了
// oldCapacity >> 1 :计算过程:
//10的二进制表示:
//0000000 0000000 0000000 0001010
//右移两位:
//10 >> 1 =4+1=5
//00000000 0000000 0000000 000101
//0000000 0000000 0000000 0000101
int newCapacity = oldCapacity + (oldCapacity >> 1);
//判断扩容之后,能否满足需要的最小的容量,如果计算出来的容量仍然不满足最小的容量,直接使用提供过来的最小容量
if (newCapacity - oldCapacity <= 0) {
newCapacity = oldCapacity;
}
//创建完新的数组后,将旧的元素复制新数组上,旧数组没有引用了,就会变成垃圾,垃圾回收会进行回收旧的数组
//将旧数组的元素和新计算需要的容量大小传入,将创建新的数组进行接收,引用传递
elementData = this.copyOf(elementData, newCapacity);
}
/**
* 扩容复制容器元素的方法
*
* @param oldElementData 旧数组的元素
* @param newCapacity 新的容量大小
* @return 新的数组
*/
private Object[] copyOf(Object[] oldElementData, int newCapacity) {
//根据新的容量大小创建一个新的数组容器
Object[] newElementData = new Object[newCapacity];
//将旧数组的元素放入到新的数组
for (int i = 0; i < elementData.length; i++) {
newElementData[i] = elementData[i];
}
return newElementData;
}
/**
* 查询的元素的方法
* 从用户的角度,用户提供了一个下标后,返回一个数组的元素
*
* @param index
* @return
*/
public T get(int index) {
//从当前的容器中,也就是当前的数组根据提供的下标获取元素
//1、判断当前的下标是否符合规则,检查index的范围是否合法
this.rangeCheck(index);
//2、index的范围合法,根据数组的下标进行元素的获取
return (T) elementData[index];
}
/**
* 判断传入的数组下标位置是否合法
*
* @param index
*/
private void rangeCheck(int index) {
//判断当前传入的下标是否符合范围内
if (index < 0 || index > size) {
//如果当前的下标小于0或者大于当前的数组的存储的元素数量,直接抛出异常,告诉不合理的范围数组下标
//自己定义一个异常(自己创建的类)来说明这个问题
new BoxIndexOutOfBoundsException("Index:" + index + ",Size:" + size);
}
}
public T remove(int index) {
//判断传入的索引是否合理
this.rangeCheck(index);
//如果代码不抛出异常,说明传入的索引在合理的范围内
//获取要删除元素的值,使用泛型
T oldValue = (T) elementData[index];
//从index开始 至size-1为止 将后面位置元素依次前移覆盖
//index:要删除元素的索引的位置
//size-1:实际元素个数最后一个元素索引位置,比如实际元素是8个,最后一个元素的索引下标就是size -1=7了
for (int i = index; i < size - 1; i++) {
//删除元素,其实就是对当前的索引位置往后的元素挨个往前挪,并不是真正的删除掉
elementData[i] = elementData[i + 1];
}
//删除掉一个元素,最后size的索引位置的默认置空,并且计算容量减少size实际的元素-1
//这里说明一下小知识点: elementData[size--] 这里可以拆分为两步的计算
//size--:先自减,后赋值
//1、size-- :先对size本身先自减1,得到的是数组最后一个元素的下标
//2、elementData[size]=null,对组最后一个元素的置null
elementData[size--] = null;
//将删除掉的元素返回
return oldValue;
}
/**
* 由于我们的属性size是私有的,所以我们提供对爱暴露的方法给用户进行获取实际的因素
*
* @return 数组存入的个数
*/
public int size() {
//返回数组的实际存储的数量
return this.size;
}
/**
* 提供一个方法,提供给用户获取一个容器的容量大小
*
* @return 容器的容量大小
*/
public int length() {
//返回数组容量大小
return elementData.length;
}
}
LinkedBox实现
package com.hsc.box;
/**
* 创建一个类模拟LinkedList的实现原理:
* 可扩展性(面向对象思想)思考:代码的可扩展性,健壮性
* 实现类中继承了一个抽象类,并且实现了接口中定义的主要方法,做了一个良好的规范
*/
public class LinkedBox<T> extends AbstractBox<T> {
//记录链表首节对象
private Node<T> first;
//记录链表尾节点对象
private Node<T> last;
//记录有效元素个数
private int size;
/**
* 添加一个元素到链表中
*
* @param element
* @return
*/
public boolean add(T element) {
//将element存入一个新的Node对象中,添加至链表的尾端
this.linkLast(element);
return true;
}
/**
* 设计一个方法,将指定的元素,添加到指定的位置
*
* @param index
* @param element
* @return
*/
public boolean add(int index, T element) {
return true;
}
/**
* 将元素添加在新的node对象中,并且添加至链表的尾端
*
* @param element
*/
private void linkLast(T element) {
//获取当前链表的尾节点对象
//创建一个局部变量
Node<T> l = last;
//创建一个新的node对象,将数据包装起来
//新添加的Node节点对象,记录着上一个节点,也就是当前链表的尾节点,就是当前节点的前节点,因为当前的尾节点是往链表的尾部添加,所以下一个节点是为空的
Node<T> newNode = new Node(l, element, null);
//从链表的整个结构去看,将添加的元素节点设置为链表的尾节点
last = newNode;
//上面保证了新创建的Node节点跟上下节点建立联系关系
//需要判断当前的node是否是当前链表的第一个元素
if (l == null) {
//如果当前链表的尾节点是null的,说明当前链表是空的,我们添加的元素是链表的第一个元素
//将当前链表的整体结构进行设置
//当前的节点是头节点
first = newNode;
} else {
//如果当前的链表的尾节点不是null的,说明链表是存在元素的
// 需要做两个操作:
// 1、将当前的节点与前节点进行关联(在上面已经做了)new Node(l, element, null); 2、将前节点跟当前节点进行关联,也就是前节点设置后节点的关联
l.next = newNode;
}
//添加完节点后 链表中的元素+1
size++;
}
/**
* 根据索引获取对应的元素
*
* @param index
* @return
*/
public T get(int index) {
this.rangeCheck(index);
//调用查找元素的方法
Node<T> targetNode = this.node(index);
return targetNode.item;
}
/**
* 根据下标查询的方法
*
* @param index
* @return
*/
private Node<T> node(int index) {
//声明一个局部变量获取要寻找的目标元素
Node<T> targetNode;
//因为这用的是数据结构的类型的,并不是数组,无法通过下标直接获取到元素
//判断index的所处的位置范围
if (index < size >> 1) { //从前往后栈
//size 右移动一位相当于 size /2,这样执行效率更快
//如果小于,说明当前的索引的位置处于链表的前半部分,遍历获取到index位置的节点信息
//获取到当前链表的头节点
targetNode = first;
//循环获取,引用传递
for (int i = 0; i < index; i++) {
targetNode = targetNode.next;
}
} else { //从后往前找
targetNode = last;
for (int i = size - 1; i > index; i--) {
targetNode = targetNode.prev;
}
}
return targetNode;
}
/**
* 设计一个方法,根据索引下标,删除元素
*
* @return
*/
public T remove(int index) {
//判断当前的索引是否合法
this.rangeCheck(index);
//根据index获取到对应元素
Node<T> targetNode = this.node(index);
T oldValue = unlink(targetNode);
return oldValue;
}
/**
* 删除元素的思路,有三种情况:
* 这里的删除不是将数组的元素直接覆盖,这里是将要删除的节点,前后引用关系全部断掉,也就是链表链接的线给断掉
* 1、当前元素的是当前的链表的首节点
* 如果当前是元素是首节点,设置下一个节点为链表的头节点
* 2、当前元素是尾节点
* 3、当前的元素是出于中间的节点
*
* @param targetNode 需要删除的元素
* @return
*/
private T unlink(Node<T> targetNode) {
//获取当前targetNode节点中的item数据
T oldValue = targetNode.item;
//获取当前元素节点记录的上一个节点元素
Node<T> prevNode = targetNode.prev;
//获取当前元素节点记录的的下一个节点元素
Node<T> nextNode = targetNode.next;
//如果当前元素的前节点为空,说明当前的元素节点是链表的头节点,当前的node是第一个
if (prevNode == null) {
//将当前元素节点的下节点设置为当前链表的头节点
first = nextNode;
} else {
//如果不为空,说明当前的元素节点不是头节点,可能是中间的节点
//1、需要将当前的节点前节点跟当前节点的后节点进行指向
prevNode.next = nextNode;
//当前的节点的前节点与当前节点的后节点建立连续后,当前节点与前节点联系断开(置空)
targetNode.prev = null;
}
//如果当前的节点后节点为空,说明当前节点是尾节点
if (nextNode == null) {
//直接当前节点前节点设置为链表中最后一个节点元素
last = prevNode;
} else {
//如果链表中不是尾节点元素,说明是中间的节点
//将当前节点的后节点跟当前节点的前节点进行关联
nextNode.prev = prevNode;
targetNode.next = null;
}
//当前的元素完成对上后节点之间联系,并且当前元素的前后指向也置空,断开链接
//链表元素减1
size--;
return oldValue;
}
public int size() {
return size;
}
private void rangeCheck(int index) {
//判断当前传入的下标是否符合范围内
if (index < 0 || index > size) {
//如果当前的下标小于0或者大于当前的数组的存储的元素数量,直接抛出异常,告诉不合理的范围数组下标
//自己定义一个异常(自己创建的类)来说明这个问题
new BoxIndexOutOfBoundsException("Index:" + index + ",Size:" + size);
}
}
//内部类,将一个类,放在另一类的内部
//Node是linkedBox的全局内部类
//只有当的linkedBox类使用,别人用不到
//隐藏了底层的机制
/**
* 创建一个对象用来存储元素,在链表的数据结构中:由一个个的节点链接而成
* 一个节点包含中包含着三个部分组成的元素:下一个元素的引用地址信息,当前节点的具体数据,上一个节点的地址引用
*/
private static class Node<T> {
//上一个节点的对象
Node prev;
//当前的节点的数据
T item;
//下一个节点对象
Node next;
//提供一个封装数据的构造方法
public Node(Node prev, T item, Node next) {
this.prev = prev;
this.item = item;
this.next = next;
}
}
}
HashBox扩展演示
package com.hsc.box;
/**
* 创建一个新的集合工具类,继承AbstractBox<T>必须实现的方法
* @param <T>
*/
public class HashBox<T> extends AbstractBox<T>{
@Override
public boolean add(Object element) {
return false;
}
@Override
public T get(int index) {
return null;
}
@Override
public T remove(int index) {
return null;
}
@Override
public int size() {
return 0;
}
@Override
public boolean add(int index, Object element) {
return false;
}
}
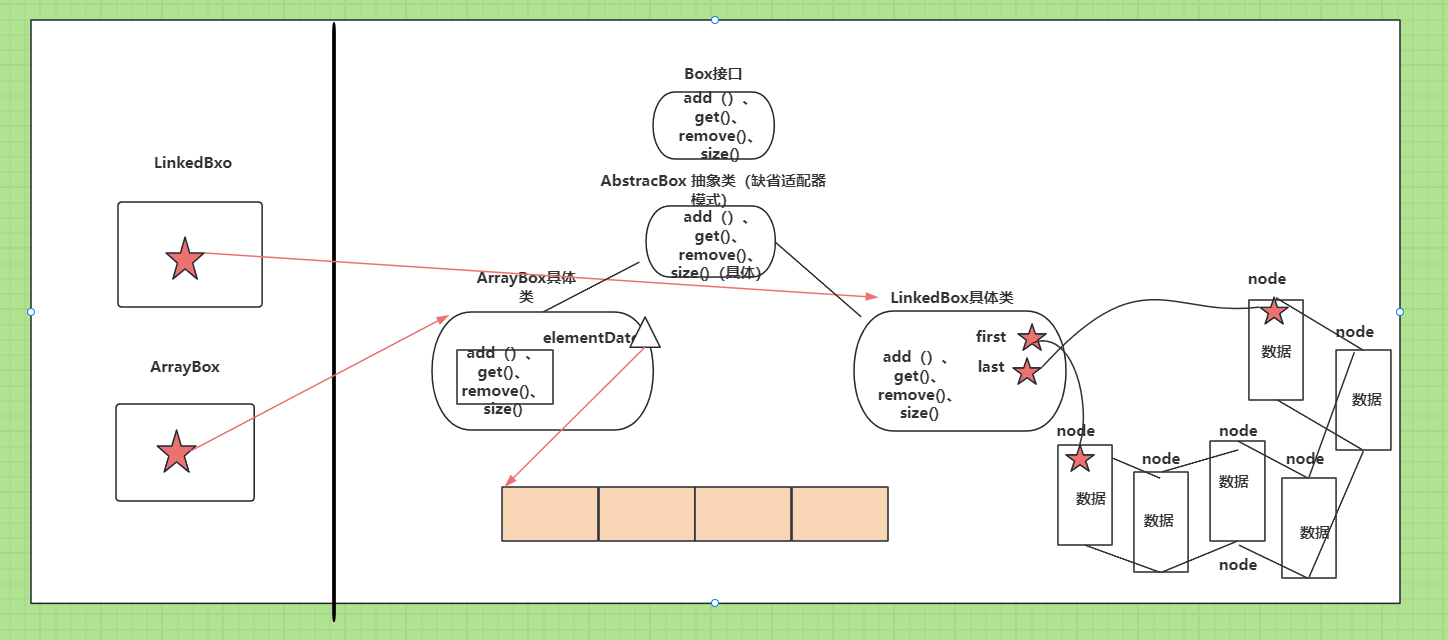
内存图解:
启动方法:
package com.hsc.test;
import com.hsc.box.LinkedBox;
public class LinkedMain {
public static void main(String[] args) {
LinkedBox<Integer> linkedBox=new LinkedBox();
//添加元素
for (int i = 0; i < 10; i++) {
linkedBox.add(i);
}
System.out.println("容器数量个数:"+linkedBox.size());
//获取第三个元素 index 索引下标
int i = linkedBox.get(2);
System.out.println(i);
//删除元素
int oldValue = linkedBox.remove(2);
System.out.println(oldValue);
System.out.println("删除一个元素:"+oldValue);
System.out.println(linkedBox.get(2));
System.out.println("容器数量个数:"+linkedBox.size());
}
}
思考、总结:
- 【底层原理】:经过手写ArrayList和LinkedList之后,对于两个集合有了更好的理解,而不单单只是在api的调用层面,如果知道其特点,我们能够更加的灵活和运用。
- 【可扩展性】:用过接口和抽象类中间层的引入,我们能够更好的理解关于面向对象的思想,封装、继承、多态,以及真正单一接口、抽象类单一知识点贯穿起来,有一个承上启下的作用。
- 【设计模式】:就在我们完成关于类和类之间的关联关系的时候,能够很好解决代码的之后冗余问题以及可扩展性性,其实这应用到了一个设计模式:装饰器(Decorator)模式。装饰者模式: 在不改变原有对象的情况下拓展其功能。装饰器模式通过组合替代继承来扩展原始类的功能,在一些继承关系比较复杂的场景(IO 这一场景各种类的继承关系就比较复杂)更加实用。在我们的java体系中,包括IO之间的类和类的关系和spring框架中都运用到了。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









