






目标
1、爬取糗事百科的所有热门段子
2、将发帖人、段子内容、好笑数爬取下来
3、将图片过滤掉

过程
1、传入user_agent,介绍如下图
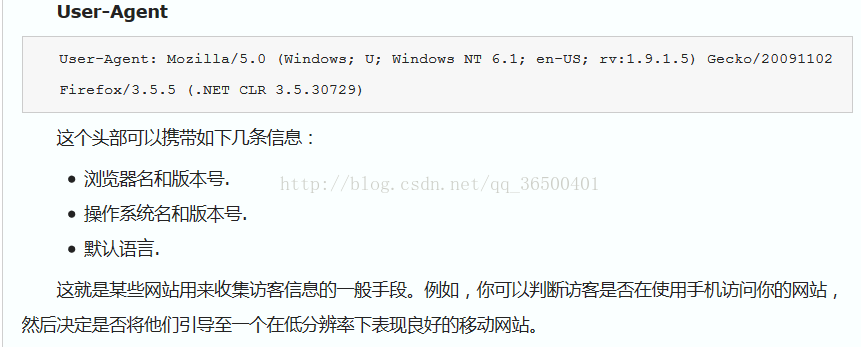
所以我们在写爬虫的时候可以加上去,可以解决一些禁止爬虫访问,返回不了源代码的问题
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent} # 有的网站加了保护,需要设置Headers伪装成浏览器访问2、在源代码中找到我们所需要爬取的信息,用正则爬取下来
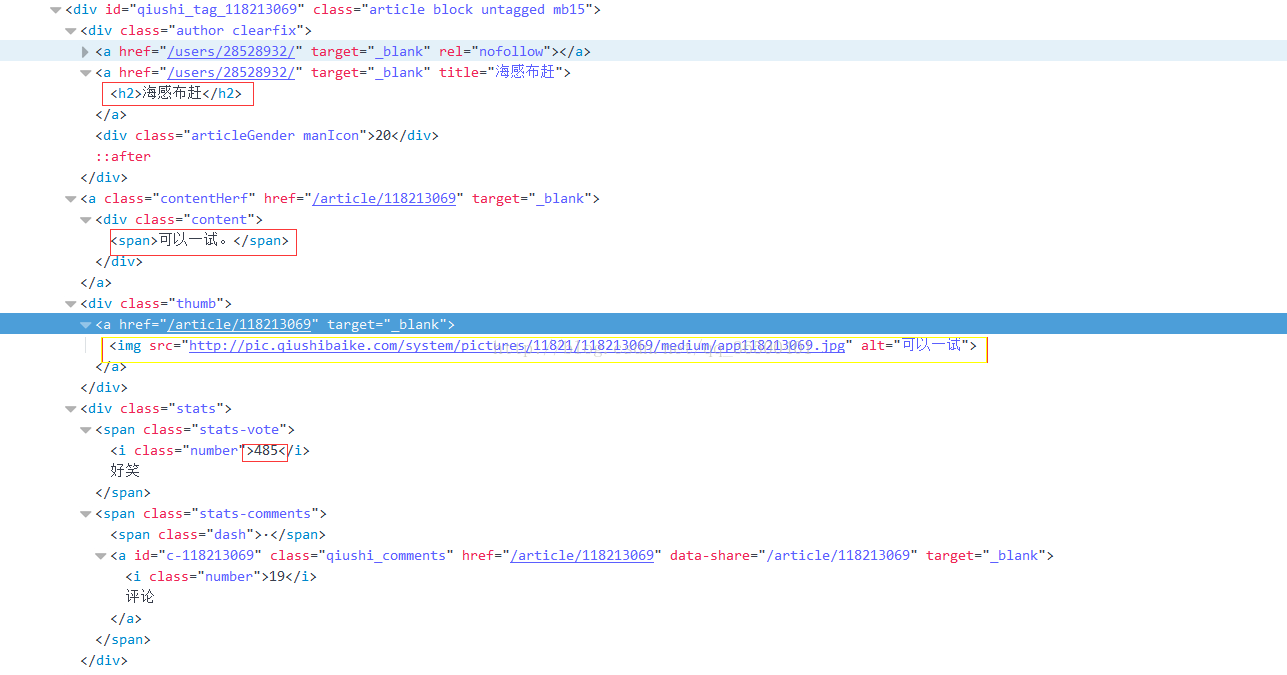

红色的部分是我们需要爬取的,黄色的则是底下的图片,开始写正则。。
pattern = re.compile('<div class="author clearfix">.*?href.*?<img src.*?'
'title=.*?<h2>(.*?)</h2>.*?<div class="content">'
'(.*?)</div>.*?<div class="stats">.*?class="number">(.*?)</i>', re.S)
3、剩下的就是查看爬下来的内容是不是自己想要的,空格或者不需要的东西就想办法去掉。下面是完整版的代码
# encoding=utf-8
import urllib
import urllib2
import re
url = 'http://www.qiushibaike.com/8hr/page/'
for page in range(1, 11): # 为了速度快点,只爬取了1——10页的段子
url1 = url + str(page) + '/?s=4929284'
# print url1 #检查网页是否正确
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent} # 有的网站加了保护,需要设置Headers伪装成浏览器访问
try: # 用这种方式写代码,如果出现错误URLError,会反馈回错误代号,更容易判断程序在哪出错
request = urllib2.Request(url1, headers=headers)
response = urllib2.urlopen(request) # 使代码更加规范,容易被理解,传入request
content = response.read().decode('utf_8')
pattern = re.compile('<div class="author clearfix">.*?href.*?<img src.*?'
'title=.*?<h2>(.*?)</h2>.*?<div class="content">'
'(.*?)</div>.*?<div class="stats">.*?class="number">(.*?)</i>', re.S)
items = re.findall(pattern, content)
for item in items:
replaceBR = re.compile('<br/>')
replaceSPAN = re.compile('<span>')
replaceSPAN1 = re.compile('</span>')
text = re.sub(replaceBR, "", item[1])
text1 = re.sub(replaceSPAN, "", text)
text2 = re.sub(replaceSPAN1, "", text1) # 去掉多余的字符
# print '-->',text2,'--<' #查看空格回车是在哪个分组里
text3 = text2.encode('utf-8').strip().replace('<span class="contentForAll">查看全文', '')
# 检查到了一行‘<span class="contentForAll">查看全文’,去掉它
item0 = item[0].encode('utf-8')
item2 = item[2].encode('utf-8') # 编码成utf-8格式,便于写入文件
# print text2
with open('qiubai3.txt', 'a+') as QB:
# 用读写追加的方式打开文件,使用w或w+ 因为for循环的遍历,只会出来最后一行数据,会覆盖掉
QB.write(item0 + '|' + text3 + '|' + item2 + '\n')
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason














 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









