







scrapy框架是python爬虫应用于系统性快捷处理和管理数据的一个框架,提取结构性数据而编写的应用框架,使用scrapy框架你可以更方便的对你所爬取的数据进行管理,
这是我对scrapy简单的理解。
这里就不介绍具体原理和图片展示了。(你应该对简单爬虫有一定得了解吧,不然怎么会直接学习scrapy)
如果你是刚准备学习scrapy,那么你应该仔细看看。如果你已经学习了一段时间scrapy了,那么这篇文章可能不适合你学习,这里先只讲入门
通过初学者的能力来实现
直接干货:(目的:爬取豆瓣250)
当然你可能还没有安装scrapy,这里我就不繁琐的讲解的,具体点就是 在你直接pip install scrapy之前你需要安装scrapy所依赖的环境
(pip install parsel,pip install Twisted,pip install lxml)还有的环境自己可以去网上查看。
找一个你以后存放scrapy文件的地方执行命令:scrapy startproject get_douban
会生成一个文件夹:
现在你需要在get_doubande 的
你可能需要了解一下xpath(http://www.w3school.com.cn/xpath/)这里你可以简单地了解一下。
import scrapy
from scrapy.http import Request
class DoubanSpider(scrapy.Spider):
name = "douban" #这个name是你必须给它一个唯一的名字 后面我们执行文件时的名字
start_urls = ["https://movie.douban.com/top250"]
#这个列表中的url可以有多个,它会依次都执行,我们这里简单爬取一个
url = "https://movie.douban.com/top250"
#因为豆瓣250有翻页操作,我们设置这个url用来翻页
def parse(self,response):#默认函数parse
sites = response.xpath('//ol[@class="grid_view"]') #('匹配你所需信息的路径')
#xpath是scrapy里面的一种匹配方式,类似于正则表达式,还有其他几种匹配方式
#这里我们首先获得的是我们需要的信息的那一大块sites。
print("!!!!!返回信息是:")
info = sites.xpath('./li')
#从sites中我们再进一步获取到所有电影的所有信息
for i in info: #这里的i是每一部电影的信息
#排名
num = i.xpath('./div//em[@class=""]//text()').extract() #获取到的为列表类型
#extract()是提取器 将我们匹配到的东西取出来
print(num[0],end=";")
#标题
title = i.xpath('.//span[@class="title"]/text()').extract()
print(title[0],end=";")
#评论
remark = i.xpath('.//span[@class="inq"]//text()').extract()
#分数
score = i.xpath('./div//span[@class="rating_num"]//text()').extract()
print(score[0])
nextlink = response.xpath('//span[@class="next"]/link/@href').extract()
#还记得我们之前定义的url吗,由于电影太多网页有翻页显示,这里我们获取到翻页的那个按钮的连接nextlink
if nextlink: #翻到最后一页是没有连接的,所以这里我们要判断一下
nextlink = nextlink[0]
print(nextlink)
yield Request(self.url+nextlink,callback=self.parse)
#yield中断返回下一页的连接到parse让它重新从下一页开始爬取,callback返回函数定义返回到哪里以上便是spiders的douban.py里面的代码,现在应该怎么执行呢?
在get_douban文件里面打开cmd输入执行文件的命令:scrapy crawl douban 回车
你会得到下面的信息:
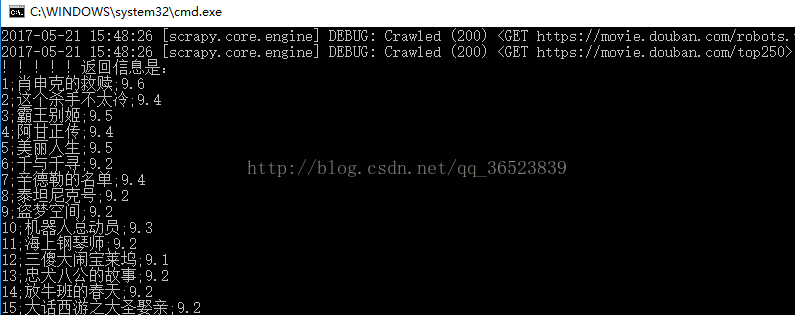
这样你就实现了使用scrapy简单的爬虫,爬取豆瓣250了,有什么意见都是可以提的。
我们暂时还没有讲解scrapy中的其他功能,例如items.py等等,先熟悉简单的吧!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









