









自然语言的处理是一个神奇的领域,它涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,由于复习相关知识,所以这里对该方向的部分知识做一个简单的介绍和记录。
该文主要记录的是一个很简单却很经典有效的算法——TF-IDF。从它的概念到运算可能花不了10分钟就能了解,并且用到的运算知识都不涉及高等数学,但往往能返回我们一个满意的答案。
当我们输入一段检索信息时,可以利用TF-IDF算法,给我们返回一篇与我们搜索比较符合的文章,下面对它做详细介绍:
TF(词频):
TF-IDF的第一个知识点,TF(Term Frequency,缩写为TF)表示词频,简单点说就是某个单词出现的频率,这是很容易理解的,如果我们要知道某个词是否是重要关键字,那么很容易想到的就是计算该词出现的数量。借由阮老师使用的例子来说明:《中国蜜蜂养殖》一文中,出现最多的一些词语可能是中国、蜜蜂、养殖,那么统计这些单词的个数(或者再做一些处理)就是该词的频率。
停用词:
停用词一个很简单的常识概念。我们知道绝大多数文章中(的、了、是、在)等词是最为常见的字词,由此若我们直接统计关键词的数量,那么获得的答案可能是无意义的,对于这些相当普通的词语我们称之为停用词,在我们处理文章时极有可能需要先将这些词语排除掉,预处理后再对文章做一个运算。停用词表有很多,很多公司企业研究机构都制作有停用词表,可以选择使用。
IDF(逆文档频率):
第二个知识点IDF,IDF(Inverse Document Frequency,缩写为IDF)表示逆文档频率。接着上面的例子来说,如果一文中中国、蜜蜂、养殖出现的次数一样多,那是不是它们同等重要呢?很有可能不是,仔细想想,一篇文章出现(中国)的概率和出现(蜜蜂)的概率哪个大,可能很多文章中都会出现中国一词,所以如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。于此我们需要一个数值(权重)来表示这些词语的一个重要性,最常见的(的、了、是、在)等词将给予最小的权重,较常见的(中国)等给予较小的权重,而(蜜蜂、养殖)这样的词语给予较大的权重,这个权重就叫做逆文档频率,值大小与常见程度成反比。
有了上面的概念,下面说说具体的运算:
一、TF(词频)的几种运算方式:
1:

2:

3:

以上的计算有多种(截图来自阮老师的文章),可以考虑到实际的情况来采用,比如考虑到文章有长短之分,便于不同文章之间的比较,可以进行词频的”标准化“,即采用2来表示。
二、IDF(逆文档频率):
由于前面对IDF的介绍,所以我们知道需要有一个包含很多文档的语料库(如:corpus),来模拟语言的使用环境。
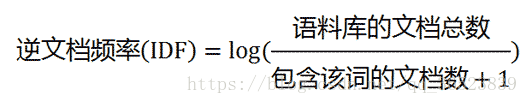
从该公式中可以很清楚的了解到如果一个词越常见(包含该词的文档数越多)则分母越大越接近0,对应的IDF越小。+1是为了避免分母为0。
三、TF-IDF:
最后结合两者做一个运算,得到TF-IDF值。TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。最后对结果排序,选出最大的k个值,对应的关键词就是运算的结果。
优缺点:
TF-IDF算法的优点是运算简单快速,比较符合实际情况。缺点是单纯以一个“词频”衡量一个词的重要性,不够全面,比如:重要的词可能出现的次数不多;可能位置信息更重要,在第一段或每段第一句更为重要,不能视为同等重要(一种解决方法是对这些重要的位置赋予更高的权重)
余弦相似性:
前面介绍了TF-IDF,下面介绍一种可以对文章之间相似性做运算的计算方式——余弦相似性,通过该计算方式,我们可以对不同文章之间的相似性做一个定量的分析表示。
余弦相似度的计算可以看成为两个向量之间的运算,计算两个向量之间的夹角,比较夹角时一般指两者方向上的差别。当夹角为0,则两者方向相同,向量重合;当夹角为90,则两者垂直,方向完全无关;当夹角为180,则两者方向相反。
样例示图(来自):
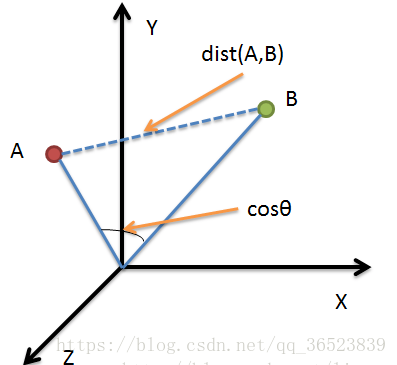
图中A、B两点,若要计算两点之间的距离则可以使用欧氏距离等方法计算,若计算A、B向量之间的相似度,则可以使用余弦相似度来计算(欧氏距离表示点之间的距离,余弦相似度表示变化趋势相似度)。
余弦定理:
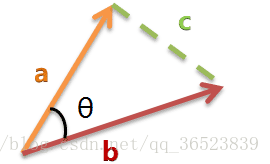
若a向量为[x1,y1],b向量为[x2,y2],所以上面的余弦公式可以转换为:
余弦公式同样适用于n维向量,如a为[x1,x2,x3,x4....x100],所以可以得出下面的公式:
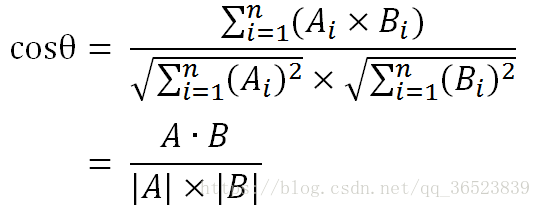
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
通过上面TF-IDF于余弦相似度的学习后(TF-IDF计算一篇文章,余弦相似度比较多篇),可以得出一种“寻找相似文章”的算法:
- 使用TF-IDF算法,找出两篇文章各自的关键词;
- 每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
- 生成两篇文章各自的词频向量;
- 计算两个向量的余弦相似度,值越大就表示越相似。
参考文章:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html 推荐可以看看(本文主要参考该文)
参考文章:https://blog.csdn.net/u013749540/article/details/51813922















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









