







Titan是一个分布式的图数据库,支持横向扩展,可容纳数千亿个节点和边。 Titan支持事务,并且可以支撑上千用户并发进行复杂图遍历操作。在这里使用Hbase存储数据,elasticsearch做索引。
Titan包含下面这些特性:
弹性与线性扩展
分布式架构,可容错
支持多数据中心的高可用和热备
支持ACID和最终一致性
支持多种存储后端
Apache Cassandra
Apache HBase
Oracle BerkeleyDB
Akiban Persistit
支持位置、数字和全文检索
ElasticSearch
Apache Lucene
原生支持TinkerPop软件栈
Gremlin graph query language
Frames object-to-graph mapper
Rexster graph server
Blueprints standard graph API
开源协议 Apache 2 license
一丶依赖环境
JDK1.8(jdk1.8.0_11这个版本有坑)下载地址
Ubuntu 下载地址
titan-1.0.0-hadoop2 下载地址
hadoop-2.7.1 下载地址
hbase-0.98.12-hadoop2 下载地址
elasticsearch-1.5.1(请在titan-1.0.0-hadoop2/lib下寻找es对应版本进行下载)下载地址
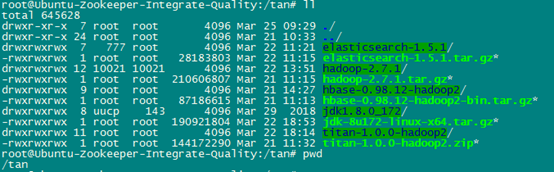
二丶Hadoop安装(伪分布式)
- tar –xzvf hadoop-2.7.1.tar.gz,解压到当前目录
- cd hadoop-2.7.1/etc/hadoop/目录下
- 配置core-site.xml
<configuration> <!-- Hadoop 伪分布式配置 --> <!-- 使用 hadoop-2.5.2/tmp 做为 hdfs 的存储目录,默认为 /tmp <property> <name>hadoop.tmp.dir</name> <value>file:/tan/hadoop-2.7.1/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9009</value> </property> </configuration>
4. 配置hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/tan/hadoop-2.7.1/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/tan/hadoop-2.7.1/tmp/dfs/name</value> </property> </configuration>
5. 配置hadoop-env.sh,将JAVA_HOME改为JDK安装目录
export JAVA_HOME=/tan/jdk1.8.0_172
6. 启动hadoop服务。sbin/start-dfs.sh。启动成功后,执行jps,可以看到三个服务 NameNode、DataNode和SecondaryNameNode。成功启动后,可以访问 Web 界面 http://192.168.1.96:50070 来查看 Hadoop 的信息(在win系统上访问记得配置hosts)

三丶Hbase(单机模式)
- tar –xzvf hbase-0.98.12-hadoop2-bin.tar.gz,解压到当前目录
- cd hbase-0.98.12-hadoop2/conf目录下
- 配置hbase-env.sh。如要使用外接zookeeper搭建伪分布式请参考:https://www.cnblogs.com/abc-begin/p/8206835.html
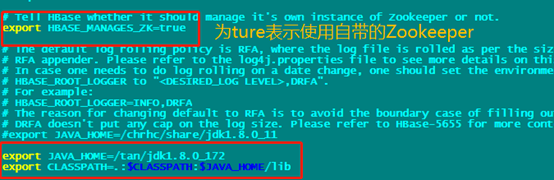
4. 配置hbase-site.sh
<configuration> <property> <name>hbase.tmp.dir</name> <value>/var/hbase</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://192.168.1.96:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>Ubuntu-Zookeeper-Integrate-Quality</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/zkdata</value> </property> <property> <name>hbase.master.info.port</name> <value>60010</value> </property> </configuration>5. 启动Hbase。bin/start-hbase.sh完成
四丶elasticsearch安装
- tar –xzvf elasticsearch-1.5.1.tar.gz,解压到当前目录
- 启动elasticsearch。./bin/elasticsearch #看到如下输出,安装成功。服务最好使用nouhp在后台运行
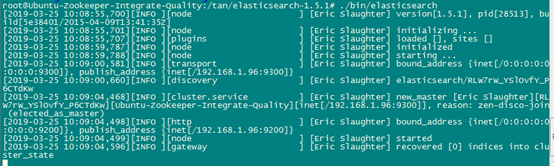
五丶Titan安装
- 解压
unzip titan-1.0.0-hadoop2.zip- 删除并添加相关jar包 。官方提供的hadoop2的安装包有一些问题,如果想要顺利的使用titan,必须删除相关的jar包,并添加一些缺失的jar包
(a) 删除异常jar包
hadoop-core-1.2.1.jar(b)添加所需要的jar包,这些jar包
titan-hadoop-1.0.0.jar titan-hadoop-core-1.0.0.jar3.使用Gremlin客户端测试服务是否启动成功。./bin/gremlin.sh #启动gremlin控制台,出来如下图表示成功
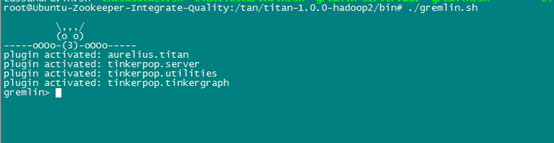
六丶环境变量
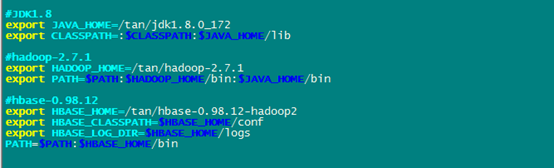
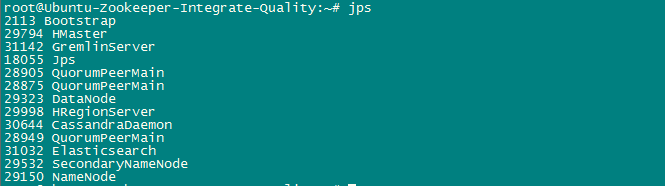
查看jps:
















 3071
3071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











