







目录
SQLContext
SQLContext是一个类,用于初始化Spark SQL的功能。Spark SQL提供对读取和写入自动捕获原始数据模式的镶木地板文件的支持。
1.初始化SparkContext命令
进入spark bin目录中,输入:spark-shell,SparkContext对象在spark-shell启动时用namesc初始化(默认)。
D:\spark-2.4.3-bin-hadoop2.7\bin> spark-shell显示:
如上所示,出现scala,表示成功进入scala。
2.创建SQLContext命令:
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)显示:

(1)Spark中使用toDF函数创建DataFrame
//命令生成SQLContext,scmeans是SparkContext对象.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
//用于将RDD隐式转换为DataFrame的所有SQL函数
scala> import sqlcontext.implicits._
scala> val df = Seq(
(1, "First datetime", java.sql.Date.valueOf("2019-08-01")),
(2, "Last datatime", java.sql.Date.valueOf("2019-08-30"))
).toDF("index", "string_column", "date_column")
//查看数据
scala> df.show
//查看DataFrame的Structure(Schema)
scala> df.printSchema()显示:
![]()


Spark读取本地TXT文件创建DataFrame
通过使用以下命令从名为ceshi.txt的文本文件读取数据来创建RDD DataFrame。
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
scala> import sqlcontext.implicits._
scala> val people = sc.textFile("E:\\ceshi.txt").map(_.split(",")).toDF()
scala> people.show注:.map(_.split(“,”)):将文本记录分割成字段。
toDF()方法:用于将具有模式的案例类对象转换为DataFrame。
显示:

(2)创建Case Class
必须使用案例类定义记录数据的模式。 以下命令用于根据给定数据(id,name,num)声明Case Class。
scala> case class Csl(id:Int,name:String,num:Int)显示:
![]()
以下命令生成RDD namedemplby,从ceshi.txt中读取数据并使用Map函数将其转换为DataFrame。
scala> val empl=sc.textFile("E:\\ceshi.txt").map(_.split(",")).map(c => Csl(c(0).trim.toInt,c(1),c(2).trim.toInt)).toDF()注:.map(_.split(“,”)):将文本记录分割成字段;
.map(_.split(",")).map(c => Csl(c(0).trim.toInt,c(1),c(2).trim.toInt)):将单个字段(id,name,num)转换为一个case类对象;
toDF():将具有模式的案例类对象转换为DataFrame。
显示:
![]()

(3)使用选择(select)方法
查看date_column列的值
scala> df.select("date_column").show显示:
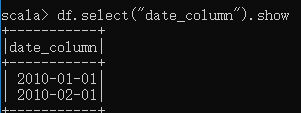
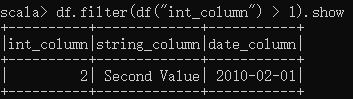
(4)过滤器(filter)方法
过滤int_column列大于1的数据
scala> df.filter(df("int_column") > 1).show显示:
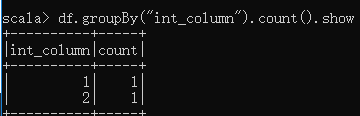
(5)分组(groupby)方法
scala> df.groupBy("int_column").count().show显示:
(6)将DataFrame数据存储在表中
将DataFrame数据存储到名为ceshi的表中。
scala> empl.registerTempTable("ceshi")
warning: there was one deprecation warning; re-run with -deprecation for details
(7)表上传递sql查询
显示记录
使用SQLContext.sql()方法在表上传递一些sql查询,选择DataFrame上的查询,使用命令从theemployableable中选择所有记录。 这里,我们使用变量allrecords来捕获所有记录数据。 显示记录,调用show()。
scala> val allrecords = sqlContext.sql("SELECT * FROM ceshi")
allrecords: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> allrecords.show()
+---+----------+---+
| id| name|num|
+---+----------+---+
| 1|water game| 12|
| 2| swim| 16|
| 3| wind| 64|
| 1| game| 38|
+---+----------+---+子句SQL查询数据帧
where语句,条件查询
scala> val numfilter = sqlContext.sql("SELECT * FROM ceshi WHERE num>20")
numfilter: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> numfilter.show
+---+----+---+
| id|name|num|
+---+----+---+
| 3|wind| 64|
| 1|game| 38|
+---+----+---+ 对其应用Transform来从结果DataFrame获取数据。
使用列索引从numfilter 数据帧获取id值
scala> numfilter.map(t=>"id: "+t(0)).collect().foreach(println)
id: 3
id: 13.创建RDD、拷贝、修改
Spark最主要的抽象是叫Resilient Distributed Dataset(RDD)的弹性分布式集合。RDDs可以使用Hadoop InputFormats(例如HDFS文件)创建,也可以从其他的RDDs转换。在Spark源代码目录里从README.md文本文件中创建一个新的RDD。
scala> val textFile = sc.textFile("file:///home/hadoop/hadoop/spark/README.md")
注:1)file代表本地目录;
2)file后三个斜杠(/);
3)“/home/hadoop/hadoop/spark/README.md”是spark安装目录,可替换。
显示:

在spark目录/conf文件夹下,此时有一个名为log4j.properties.template的文件
scala> cp log4j.properties.template log4j.properties
scala> vim log4j.properties 
4.阅读JSON文档
scala> spark-shell
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
scala> val df = sqlContext.read.json("E:\\ceshi.json")
scala> df.show
scala> df.dfs.printSchema()显示:
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@3531509c
scala> val dfs = sqlContext.read.json("E:\\ceshi.json")
dfs: org.apache.spark.sql.DataFrame = [_corrupt_record: string, gender : string ... 2 more fields]
scala> dfs.show
+---------------+-------+----+-----+
|_corrupt_record|gender | id| name|
+---------------+-------+----+-----+
| {| null|null| null|
| null| male| 1| Jim|
| null| female| 2| Tina|
| null| female| 3| Ella|
| null| male| 4|Jerry|
| null| male| 5|Smith|
| }| null|null| null|
+---------------+-------+----+-----+
scala> val dfs = sqlContext.read.json("E:\\ceshi.json")
dfs: org.apache.spark.sql.DataFrame = [gender : string, id: string ... 1 more field]
scala> dfs.show
+-------+---+-----+
|gender | id| name|
+-------+---+-----+
| male| 1| Jim|
| female| 2| Tina|
| female| 3| Ella|
| male| 4|Jerry|
| male| 5|Smith|
+-------+---+-----+
scala> dfs.printSchema()
root
|-- gender : string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)
5.HiveContext
Hive与Spark库捆绑为HiveContext,它继承自SQLContext。 使用HiveContext在HiveMetaStore中创建和查找表,并使用HiveQL在其上写入查询。 没有现有Hive部署的用户仍然可以创建HiveContext。 当未有hive-site.xml配置时,上下文会自动在当前目录中创建名为metastore_db的元数据库和名为warehouse的文件夹。
启动Spark Shell
scala> spark-shellHiveContext初始化到Spark Shell中,创建SQLContext对象
scala> val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) 在路径D:\spark-2.4.3-bin-hadoop2.7\bin 下产生metastore_db的元数据库和名为warehouse的文件夹
HiveQL创建表
使用HiveQL语法的Create语句,创建表ceshi。
sacal> sqlContext.sql("CREATE TABLE IF NOT EXISTS ceshi(id INT, name STRING,gender SING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")HiveQL将数据加载到表中
使用以下命令将记录数据加载到表中。如果成功执行,给定的ceshi.txt中的记录将按照模式存储在表ceshi中。
sacal> sqlContext.sql("LOAD DATA LOCAL INPATH 'E:\\ceshi.txt' INTO TABLE ceshi")从表中选择字段
使用HiveQL select查询获取所有记录。
scala> val df = sqlContext.sql(" SELECT id, name, gender, age FROM ceshi")
scala>df.showSpark SQL - Parquet文件
Parquet是一种柱状格式,许多数据处理系统支持。
柱状存储的优点 :
1、列存储限制IO操作。
2、列式存储可以获取您需要访问的特定列。
3、列式存储占用更少的空间。
4、列式存储提供更好的摘要数据,并遵循类型特定的编码
打开Spark Shell
scala> spark-shell创建SQLContext对象
sc表示SparkContext对象。
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)从文本文件读取输入
从名为ceshi.parquet的parquet文件读取数据来创建RDD DataFrame。
scala> val parqfile = sqlContext.read.parquet(“ceshi.parquet”)将DataFrame存储到表中
将DataFrame数据存储到名为employee的表中。
scala> parqfile.registerTempTable(“employee”)使用SQLContext.sql()方法在表上传递SQL查询。
选择DataFrame上的查询
从employee表中选择所有记录。
scala> val allrecords = sqlContext.sql("SELeCT * FROM employee")
scala> allrecords.show














 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









