






APIJSON使用文档:http://apijson.cn/
APIJSON介绍:APIJSON赋予了前端极大的灵活性和自主性。根据业务需求前端可以自己设计数据库表结构,不再受限于后台接口,要啥有啥,所求即所得,大大提升了开发效率。
APIJSON 是一种专为 API 而生的 JSON 网络传输协议 以及 基于这套协议实现的 ORM 库。为各种增删改查提供了完全自动化的万能 API,零代码实时满足千变万化的各种新增和变更需求。能大幅降低开发和沟通成本,简化开发流程,缩短开发周期。
APIJSON - 功能符、数组关键词、对象关键词、全局关键词简表速查
一 功能符号
数据库表中的字段用key代替
[]:查询数组
"key[]":{}
{}:匹配选项范围
"key{}":[1,2,3]
{}:匹配条件范围
"key{}":"<=10;length(key)>1..."
<>:包含选项范围
"key<>":38710
}{@:判断是否存在
"key}{@":{}
():远程调用函数
"key()":"function(arg0,arg1...)"
@key():存储过程
"@key()":"function(arg0,arg1...)"
key@:引用赋值
"key@":"key0/key1.../targetKey"
key@:子查询
"key@":{
"range":"ALL",
"from":"Table",
"Table":{ ... }
}
$:模糊搜索
"key$":"%abc%"
~:正则匹配
"key~":"^[0-9]+$"
%:连续范围
"key%":"2018-01-01,2018-10-01"
+:增加/扩展
"key+":[1]
-:减少/去除
"key-":888.88
>:比较运算
"key{}":"<=90000"
- “>” 大于
- “<” 小于
- “>=” 大于等于
- “<=” 小于等于
&:逻辑运算符
"key&{}":">80000,<=90000" // &, |, !
- “&” 与(并且)
- “|” 或(或者)
- “!” 非(不等于)
新建别名
"key:alias"
二 数组关键词
“key”:Object,key为 “[]”:{} 中{}内的关键词,Object的类型由key指定 可以理解为下面这种格式
"[]":{
"User":{},
"query":2,
"count":1,
......
},
查询数量
"count":1
查询页码
"page":1
查询内容
"query":Integer
- 0 对象
- 1 总数和分页详情
- 2 数据、总数和分页详情
关联
"join":"&/Table0,</Table1/key1@"
- “@” APP JOIN
- “<” LEFT JOIN
- “>” RIGHT JOIN
- “&” INNER JOIN
- “|” FULL JOIN
- “!” OUTER JOIN
- “*” CROSS JOIN
- “^” SIDE JOIN
- “(” ANTI JOIN
- “)” FOREIGN JOIN
自定义关键词
"otherKey":Object
三 对象关键词
“@key”:Object,@key为 Table:{} 中{}内的关键词,Object的类型由@key指定 下面这种格式
"Table": {
"@column":"key,key1",
}
条件组合
"@combine":"key0 | (key1 & (key2 | !key3))..."
返回字段
"@column":"column;function(arg)..."
排序方式
"@order":"column0+,column1-..."
分组方式
"@group":"column0,column1..."
聚合条件HAVING
"@having":"function0(...)?value0;function1(...)?value1;function2(...)?value2..."
集合空间
"@schema":"sys"
数据库类型
"@database":"POSTGRESQL"
跨数据源
"@datasource":"DRUID"
转为 JSON 格式返回
"@json":"key0,key1..."
来访角色
"@role":"OWNER"
性能分析
"@explain":true
自定义原始SQL片段
"@raw":"key0,key1..."
自定义关键词
"@otherKey":Object
四 全局关键词
为最外层对象 {} 内的关键词。
集合空间
"@schema":"sys"
跨数据源
"@datasource":"DRUID"
来访角色
"@role":"OWNER"
性能分析
"@explain":true
参数校验
"tag":String
接口版本
"version":Integer
格式化
"format":Boolean
APIJSON的简单查询
用user表作为示例
1、查询数组
查询列表,返回三条

“count”:查询数量

“page”:查询页码,从0开始
2、连续范围
查询2017-10-01到2018-10-01的数据
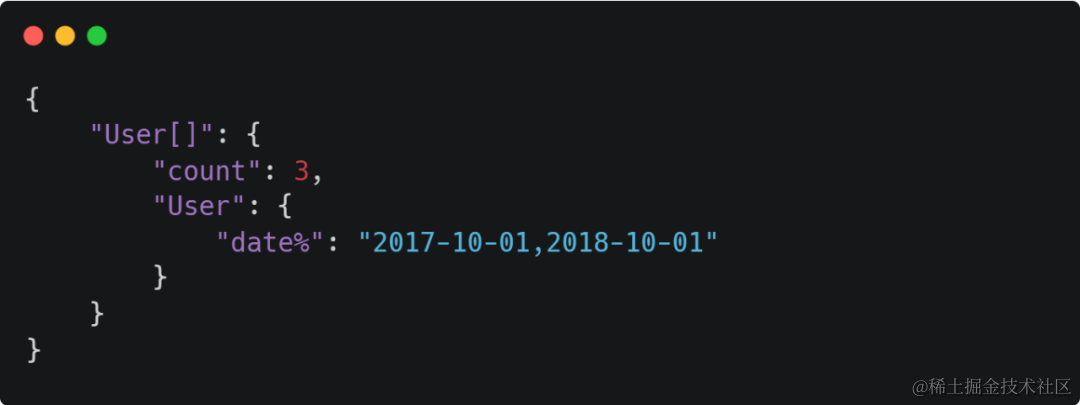
如果想查询<2017-10-01的数据,可以用下面的方式,同样的 <= , >=, > 也通用适用。

3、匹配条件范围
查询id<=80000|(或)id>90000的数据

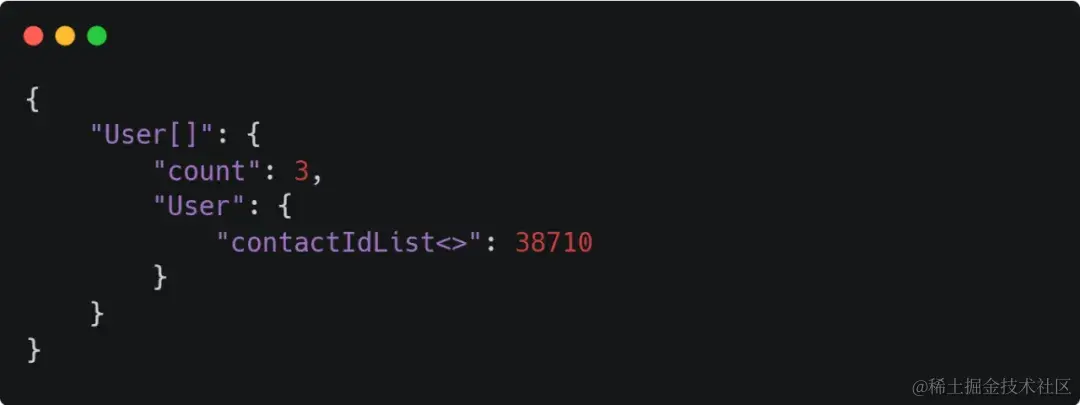
4、包含选项范围
查询contactIdList包含38710的一个User数组
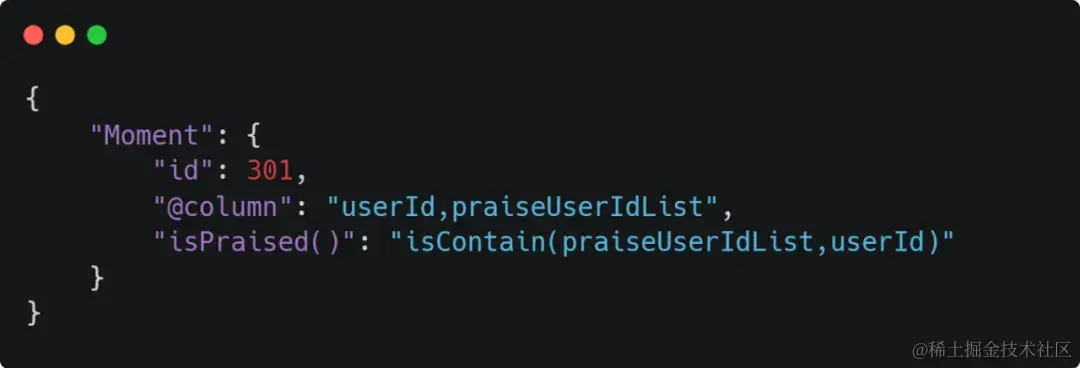
5、远程调用函数
这个在项目上有用到,还在深入研究中。可以理解为你把参数和方法名传递给后端,后端处理业务逻辑。
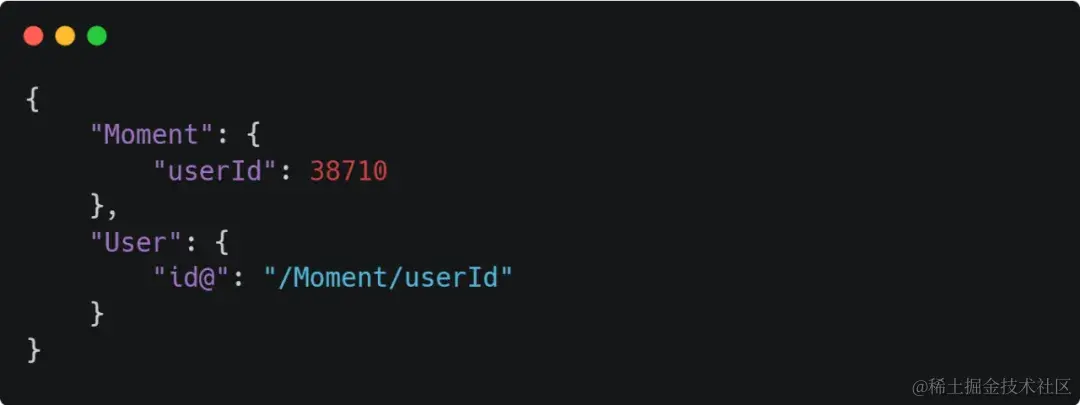
6、引用赋值
User内的id引用了与User同级的Moment内的userId, 即User.id = Moment.userId,请求完成后 “id@”:“/Moment/userId” 会变成 “id”:38710
7、模糊搜索
模糊搜索在项目上用到的很多,下面的列子对应 SQL name LIKE ‘%m%’
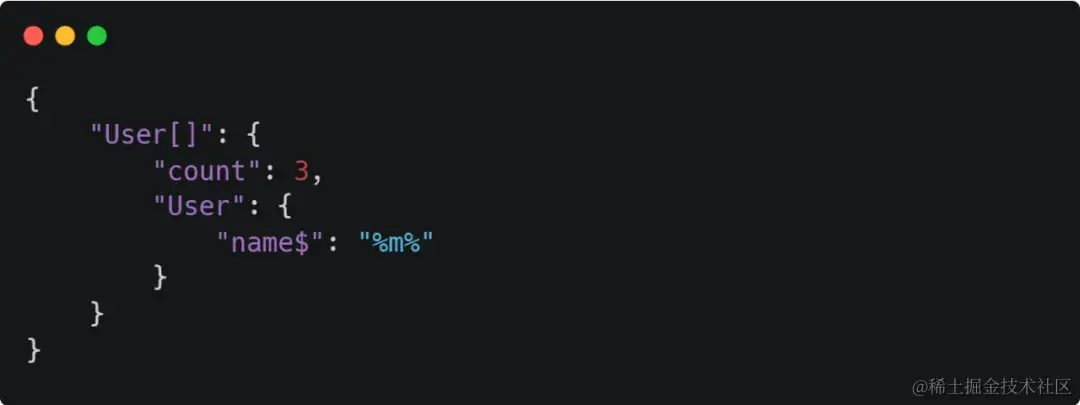
其他模糊查询方式:

8、正则匹配
如果其他查询不满足需求,可以自定义正则查询,下面例子对应SQL name REGEXP ‘1+$’
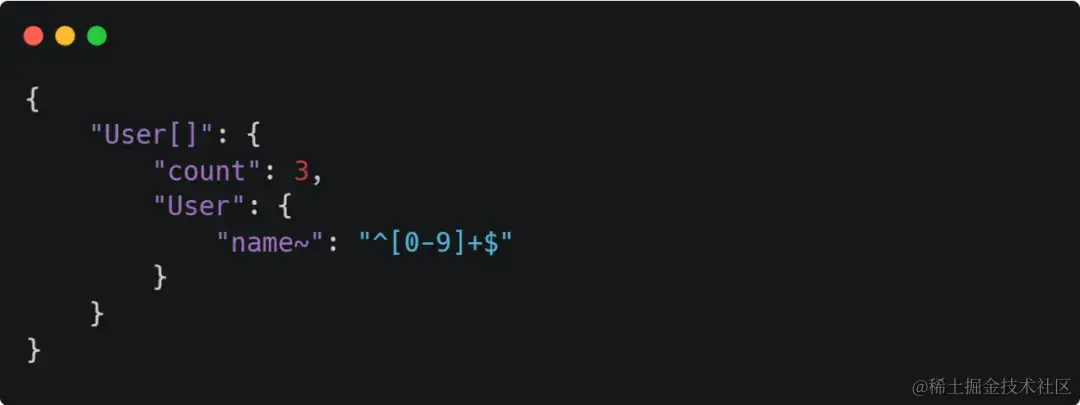
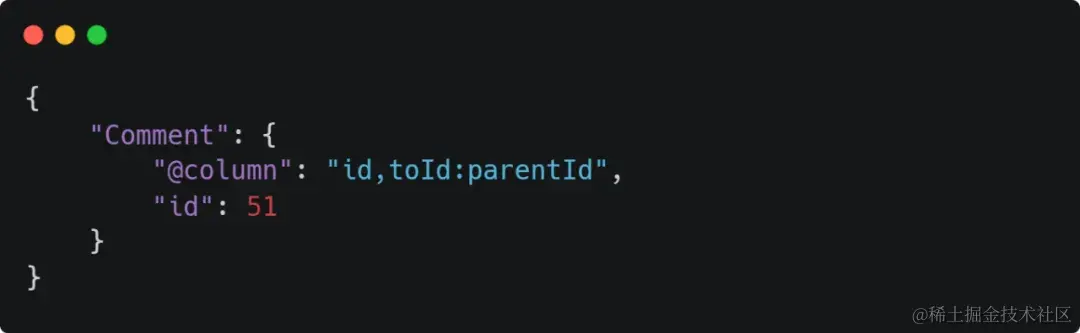
9、新建别名
很好理解,库字段 toId 返回前端时变为 parentId
10、逻辑运算 - &
查询id>80000 &(并且)id<=90000的数据

11、逻辑运算 - |
查询id>90000 | (或)id<=80000的数据

12、逻辑运算 - !
查询即 id满足 ! (id=82001 | id=38710)的数据

上面对查询操作做了示例,接下来就是增删改的使用
13、增加 - POST

14、修改 PUT

15、删除 - EDLETE

APIJSON 的复杂查询是如何实现的。
在演示查询之前我们先建几个表,Test_user、Test_user_moent_ref(关联表)、Test_moment,关联关系如图
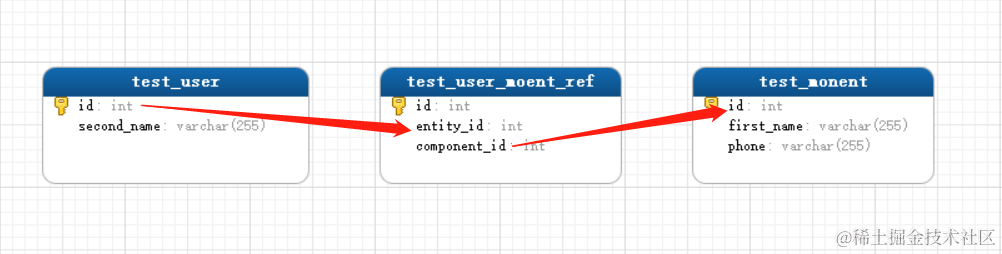
随便添加几条数据,必须保证关联关系是正确的。
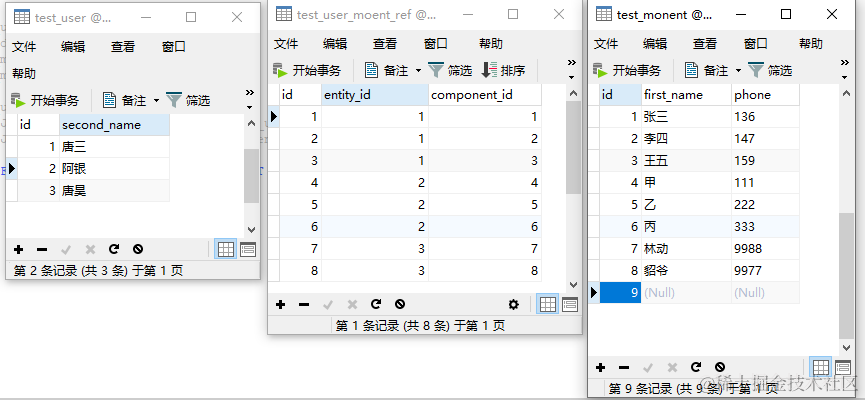
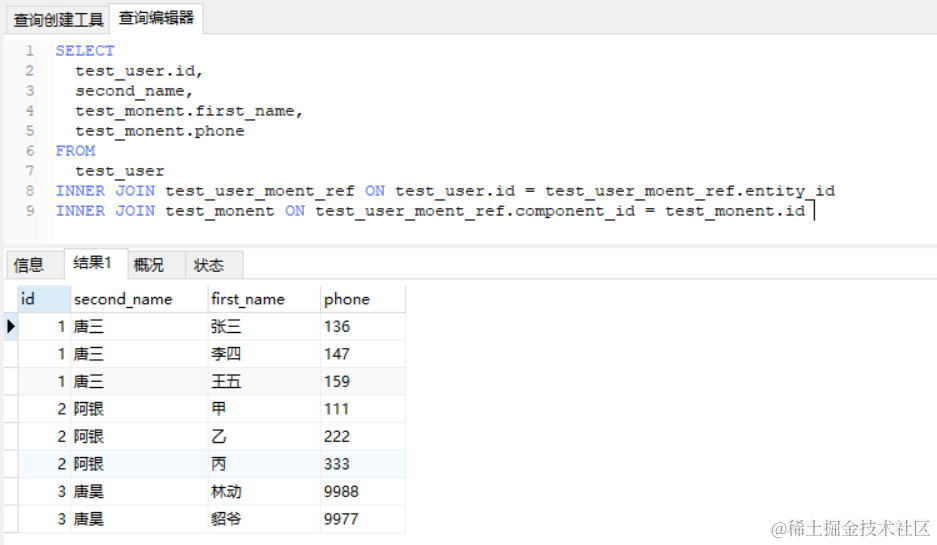
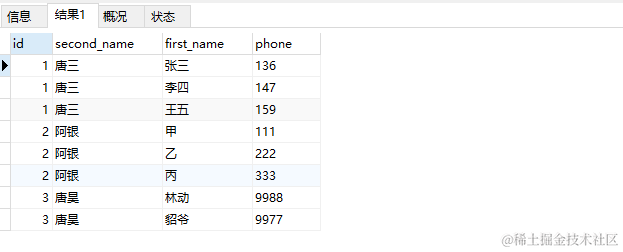
我们先用 SQL 查询,查询结果如下
一、单表查询 - 单条数据
1、单条数据
单表查询返回一条数据,用 Test_user 做示例,请求格式如下,
{
"Test_user": {}
}
APIJSON 会转换为
SELECT * FROM test_user LIMIT 1 OFFSET
返回格式如下
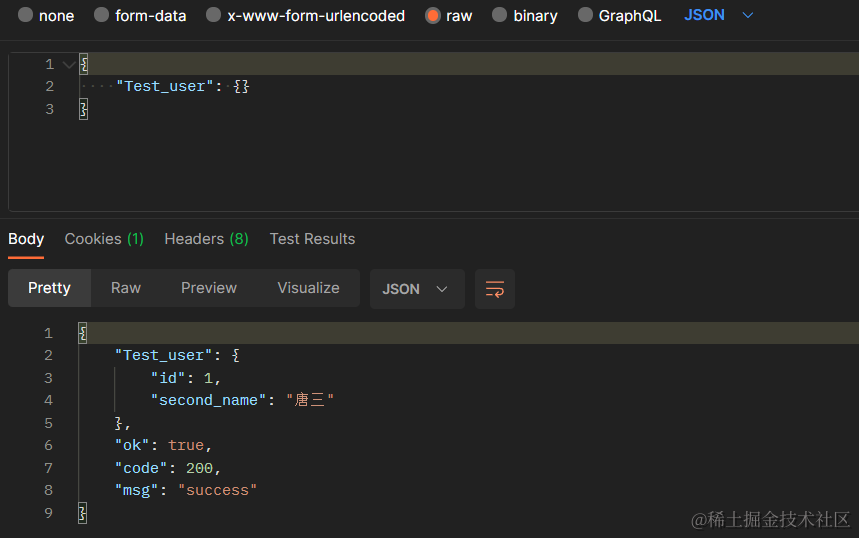
2、 过滤数据
也可以过滤,比如 id=2 的数据
{
"Test_user": {
"id":"2"
}
}
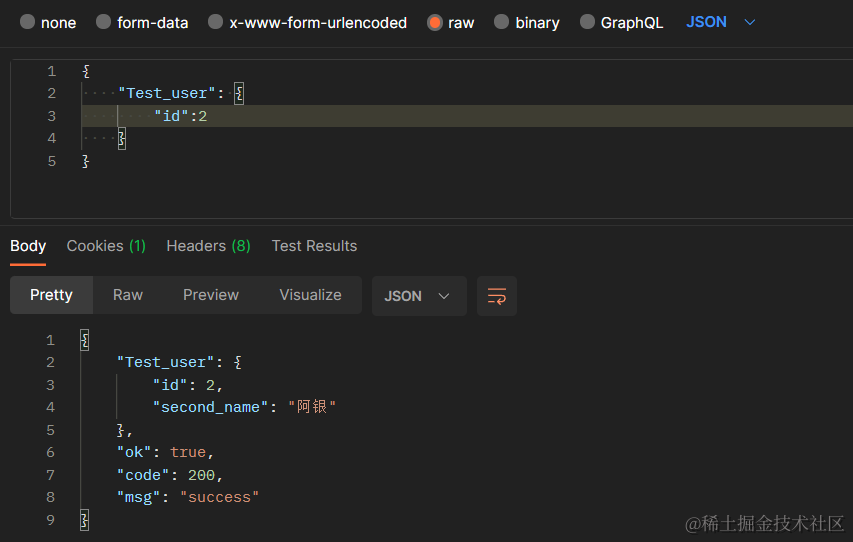
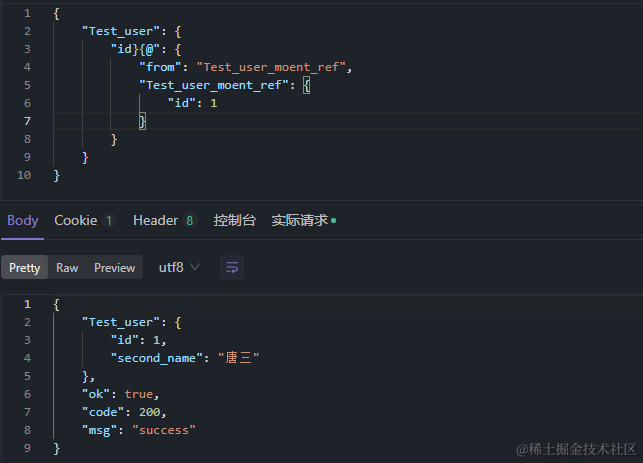
3、判断是否存在
{
"Test_user": {
"id}{@": {
"from": "Test_user_moent_ref",
"Test_user_moent_ref": {
"id": 1
}
}
}
}
}{ 表示 EXISTS,@ 后面是 子查询 对象,from 为目标表 Table 的名称;
二、单表查询 - 多条数据
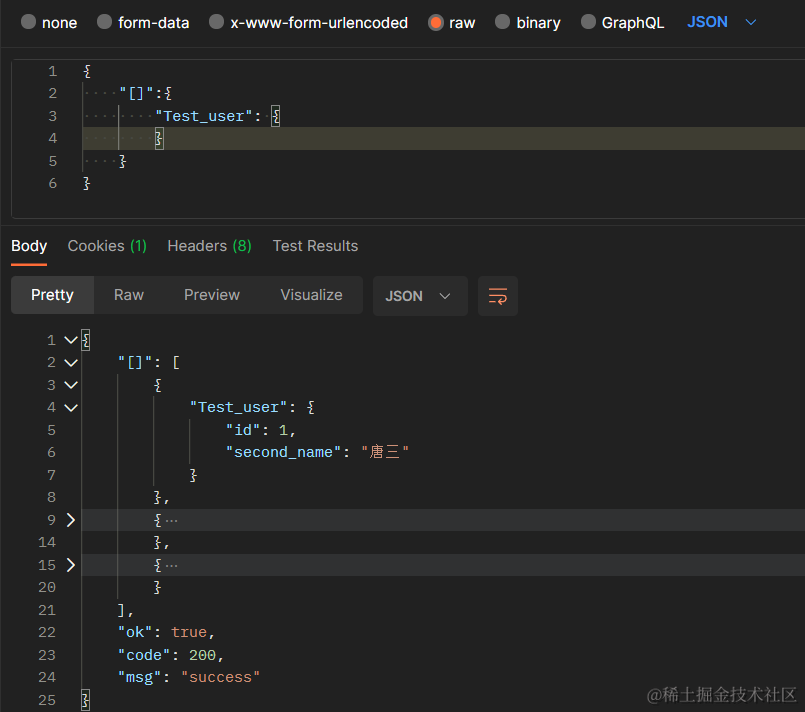
1、多条数据
单表查询返回多条数据,用 Test_user 做示例,请求格式如下,
{
"[]":{
"Test_user": {}
}
}
返回结果
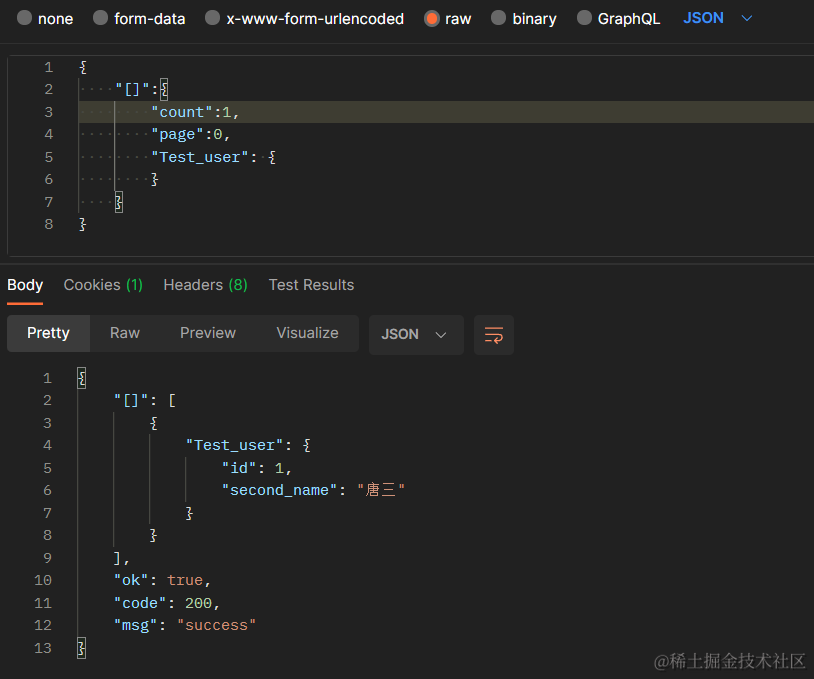
2、分页查询
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"second_name": "唐三"
}
}
}
查询结果
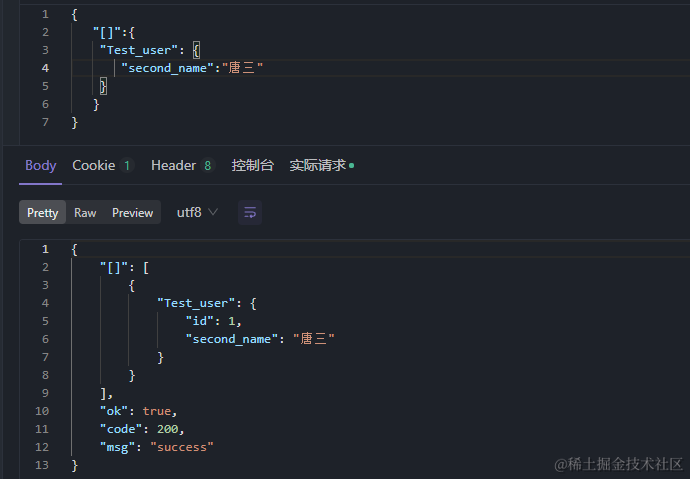
3、 过滤字段
{
"[]":{
"Test_user": {
"second_name":"唐三"
}
}
}
过滤second_name=唐三的数据
4、 模糊查询
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"second_name$": "唐%"
}
}
}
%表示任意字符,上面搜索是以唐开始,可以是任意SQL搜索表达式字符串,如 %key%(包含key), key%(以key开始), %k%e%y%(包含字母k,e,y) 等。
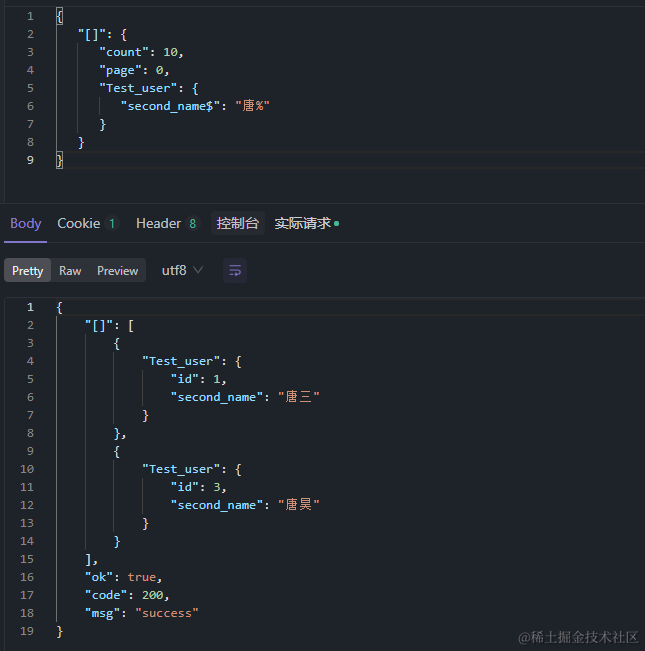
5、 正则表达式
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"second_name~": "\u5510"
}
}
}
正则也很简单,就是把汉字唐转化ASCII码,搜索包含唐的数据
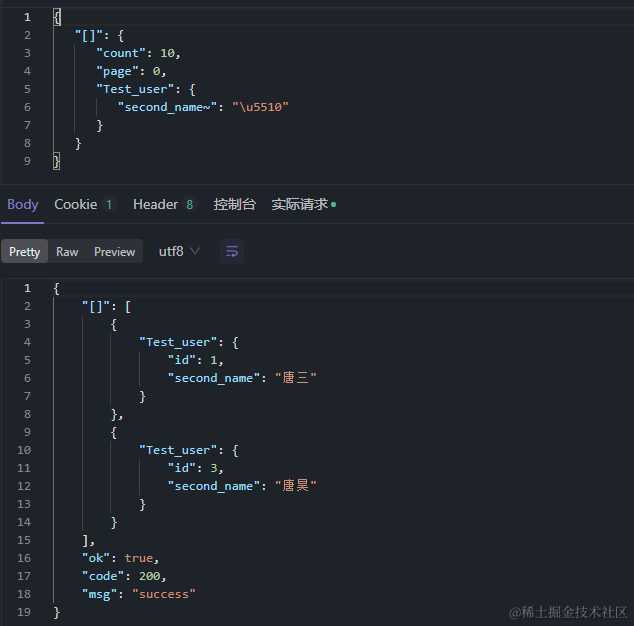
6、 连续范围
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"id%": "1,9"
}
}
}
可以查询范围内的,由于我这边数据比较少,所以用 id 查
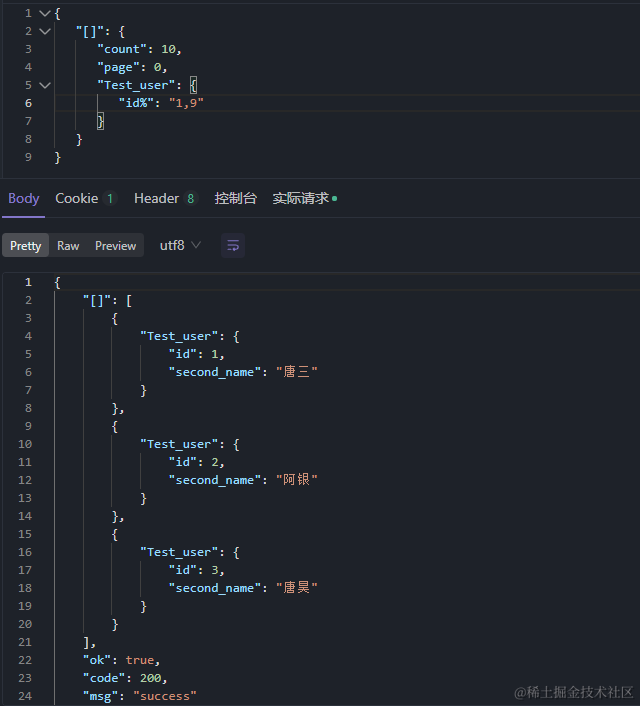
7、 控制返回字段
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"@column":"second_name",
"id%": "1,9"
}
}
}
只返回second_name字段
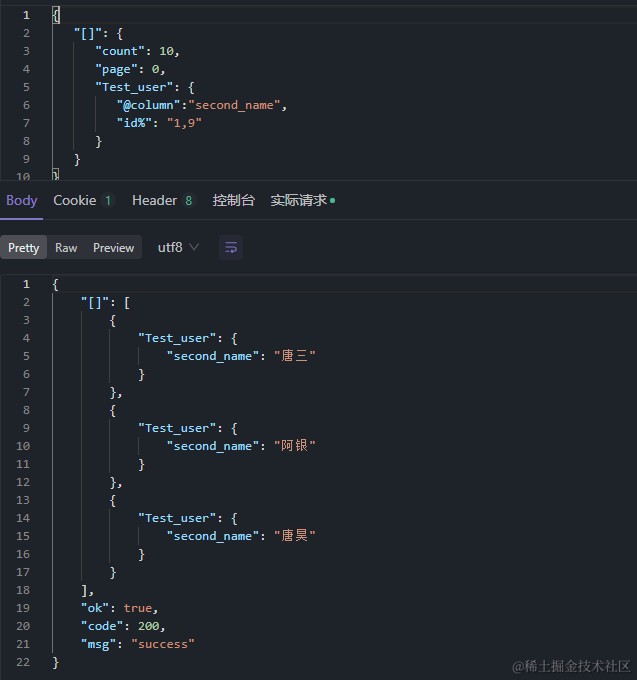
8、 给返回字段设置别名
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"@column":"second_name:s_name",
"id%": "1,9"
}
}
}
second_name设置别名为s_name
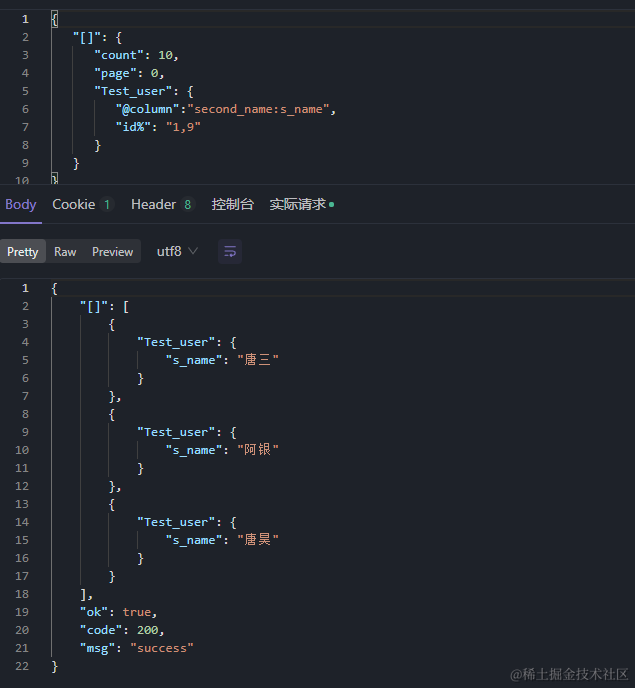
9、 比较运算
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"id>": "1"
}
}
}
比较运算符>, <, >=, <=都支持,不支持key=和key!=这两种,而是使用更为简单的 “key”:Object 和 “key!”:Object 替代。
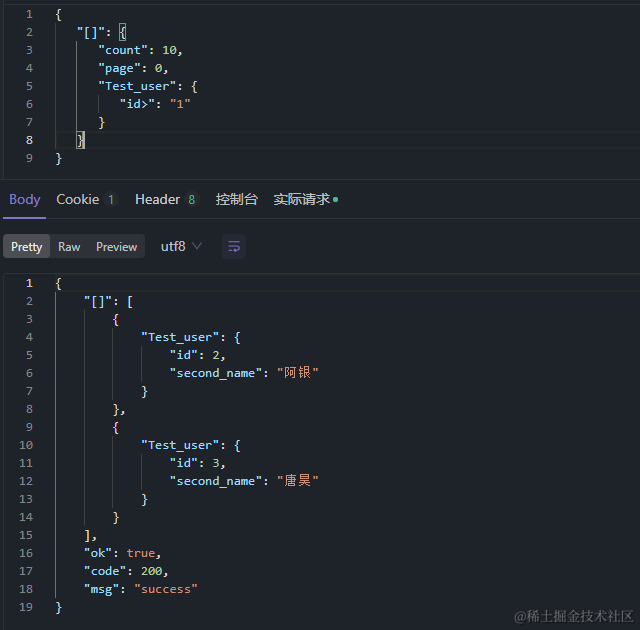
10、逻辑运算
{
"[]": {
"count": 10,
"page": 0,
"Test_user": {
"id&{}": ">1,<3"
}
}
}
逻辑运算符&, |, !都支持,但是使用场景不同
- & 可用于"key&{}":"条件"等
- | 可用于"key|{}":“条件”, “key|{}”:[]等,一般可省略
- ! 可单独使用,如"key!":Object,也可像&,|一样配合其他功能符使用
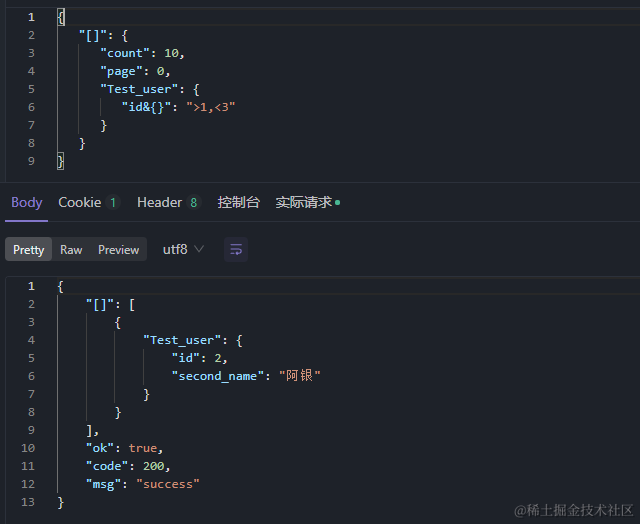
三、 两张表-一对一关联查询
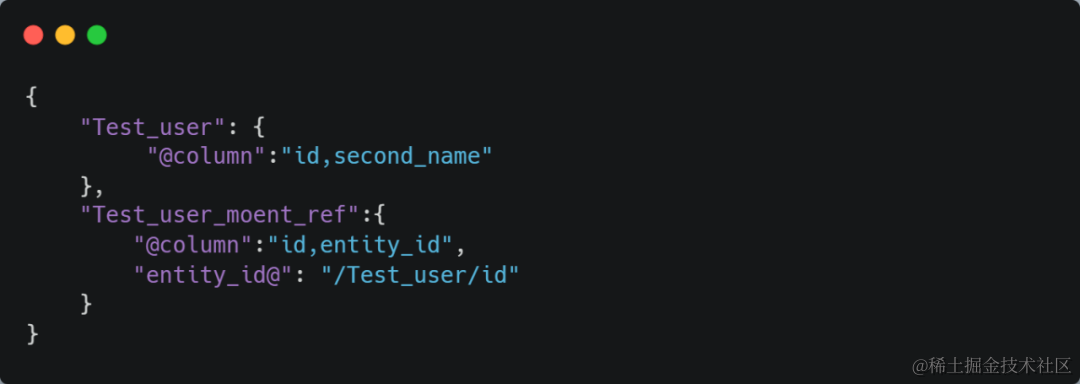
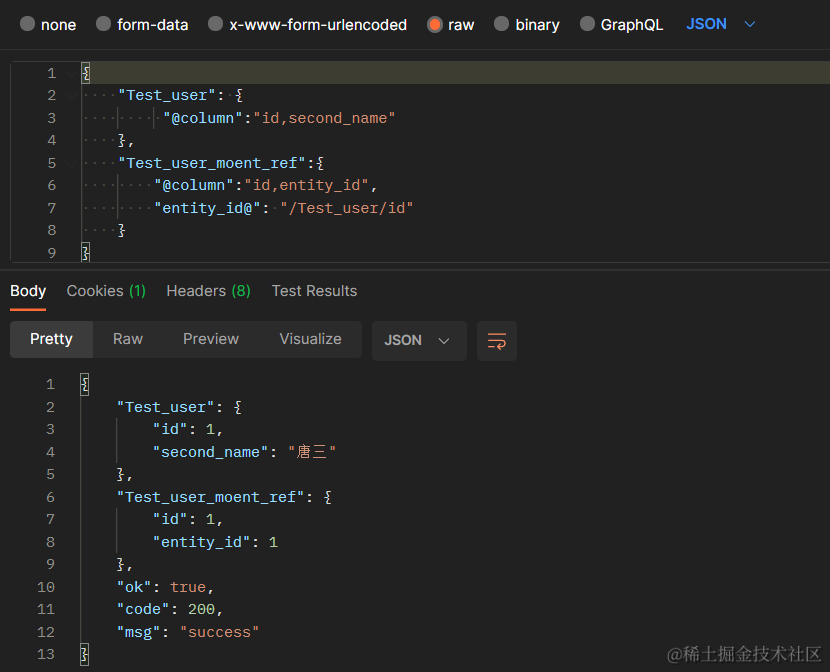
用Test_user和Test_user_moent_ref做示例,通过Test_user的id字段和Test_user_moent_ref的entity_id字段关联
{
"Test_user": {},
"Test_user_moent_ref":{
"entity_id@":"/Test_user/id"
}
}
返回两个表的所有字段
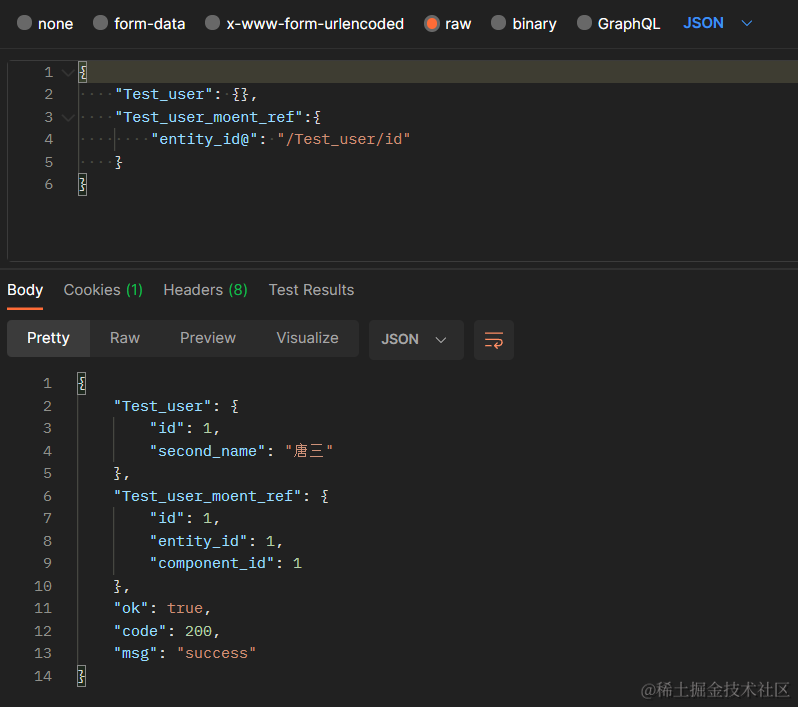
可以指定返回字段
四、 两张表-一对多关联查询
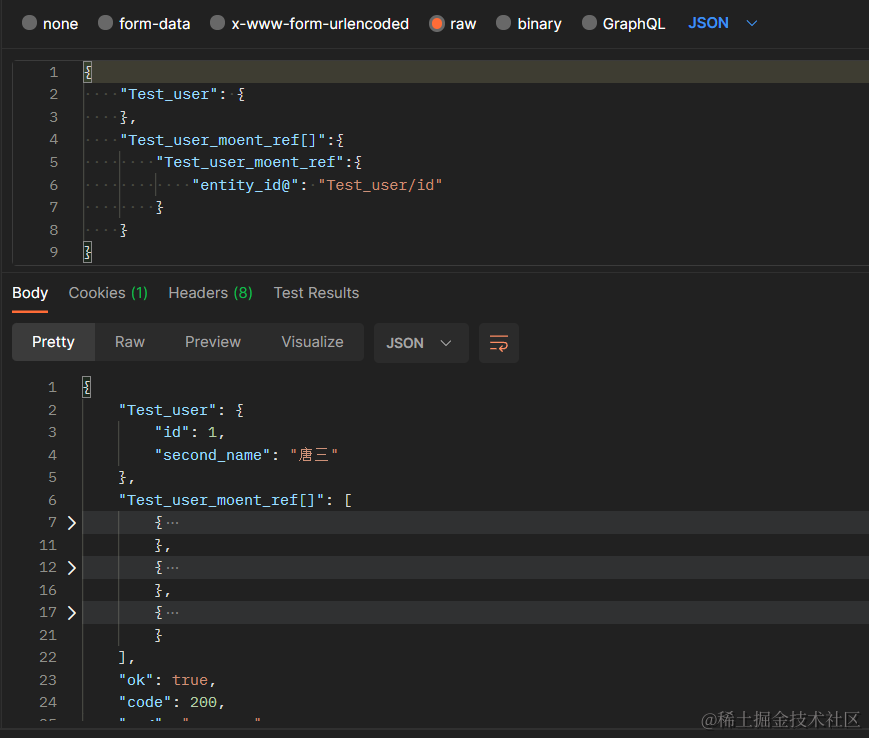
还是Test_user和Test_user_moent_ref做示例,通过Test_user的id字段和Test_user_moent_ref的entity_id字段关联
{
"Test_user": {},
"Test_user_moent_ref[]":{
"Test_user_moent_ref":{
"entity_id@":"Test_user/id"
}
}
}
返回数据如下
五、 两张表-数组内一对一关联查询
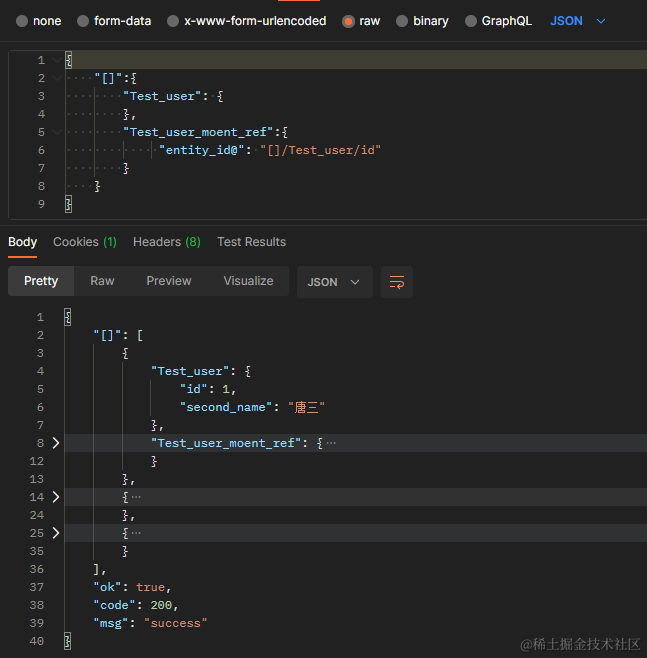
通过 Test_user 的 id 字段和 Test_user_moent_ref 的 entity_id 字段关联
{
"[]":{
"Test_user": {},
"Test_user_moent_ref":{
"entity_id@":"[]/Test_user/id"
}
}
}
其中
"entity_id@":"[]/Test_user/id
要根据 Test_user 在数组中的位置 index 来动态改变
请求返回格式
六、 两张表-数组内一对多关联查询
通过 Test_user 的 id 字段和 Test_user_moent_ref 的 entity_id 字段关联
{
"[]":{
"Test_user": {},
"Test_user_moent_ref[]":{
"Test_user_moent_ref":{
"entity_id@":"[]/Test_user/id"
}
}
}
}
注意事项和上面一样,返回格式如下
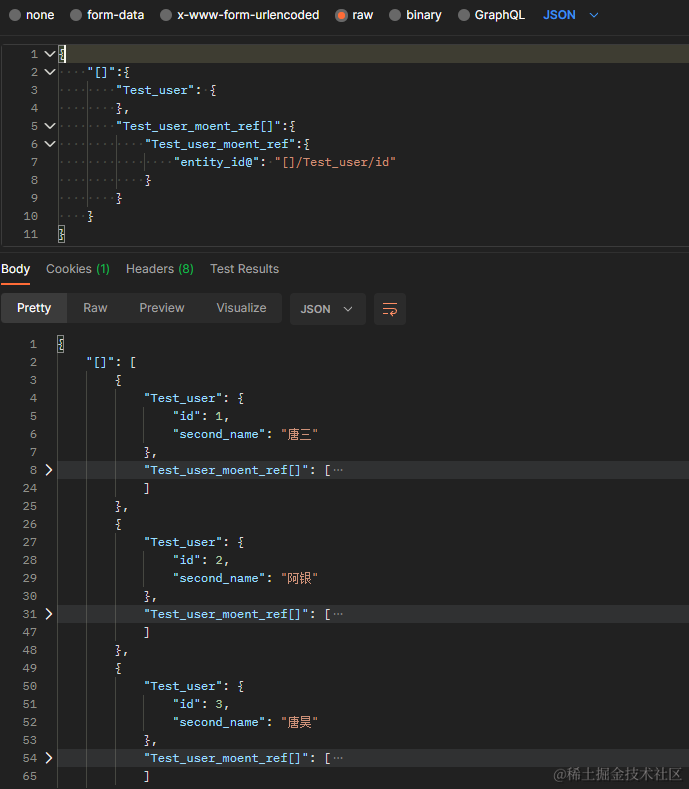
七、三张表及以上查询
通过 Test_user 的 id 字段和 Test_user_moent_ref 的 entity_id 字段关联,Test_user_moent_ref 的 component_id 字段和 Test_monent 的 id 字段关联,查询方式和上面大同小异。
{
"[]": {
"join": "</Test_user_moent_ref,</Test_monent",
"Test_user": {
"@column":"id,second_name"
},
"Test_user_moent_ref": {
"entity_id@": "/Test_user/id"
},
"Test_monent":{
"id@": "/Test_user_moent_ref/component_id"
}
}
}
数据是返回了,但是有点小问题
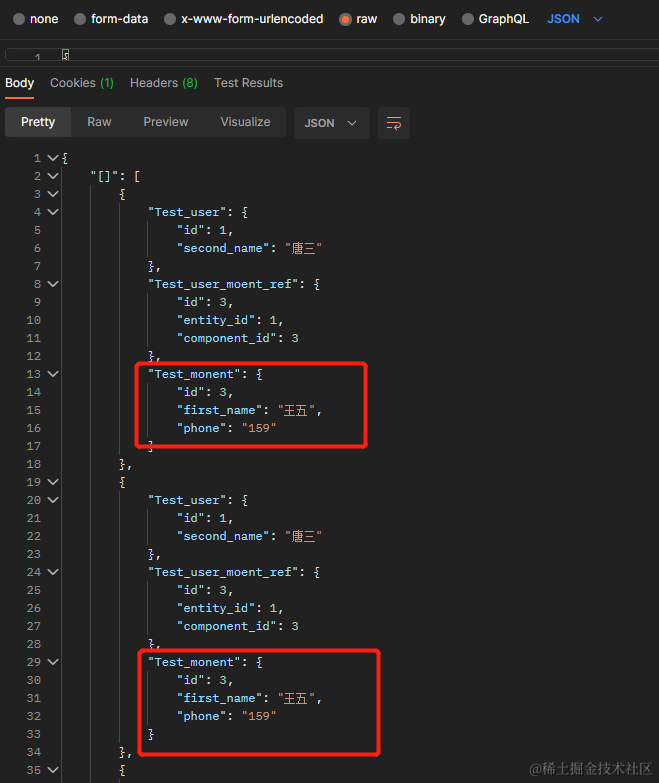
用 SQL 查询应该是这个样子的,但是返回的数据有点区别。
0-9 ↩︎


















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











