









前言
相信现在应该很多人都爱看网络小说吧,特别是那些还在连载的小说,有些作者一周都不更新几章,当更新特别精彩的时候,每天都要刷好几遍,看看有没有更新,这可苦了我们。要是有个脚本可以帮我检查小说是否有更新,然后把更新的内容发到我们邮箱上,那该有多好。下面我们就来编写这样的python脚本
思路
我们想获取每章小说的内容,只要得到每章小说的url,通过requests去请求url,就可以得到对应的网页源代码,我们需要的小说内容就在里面,如下:
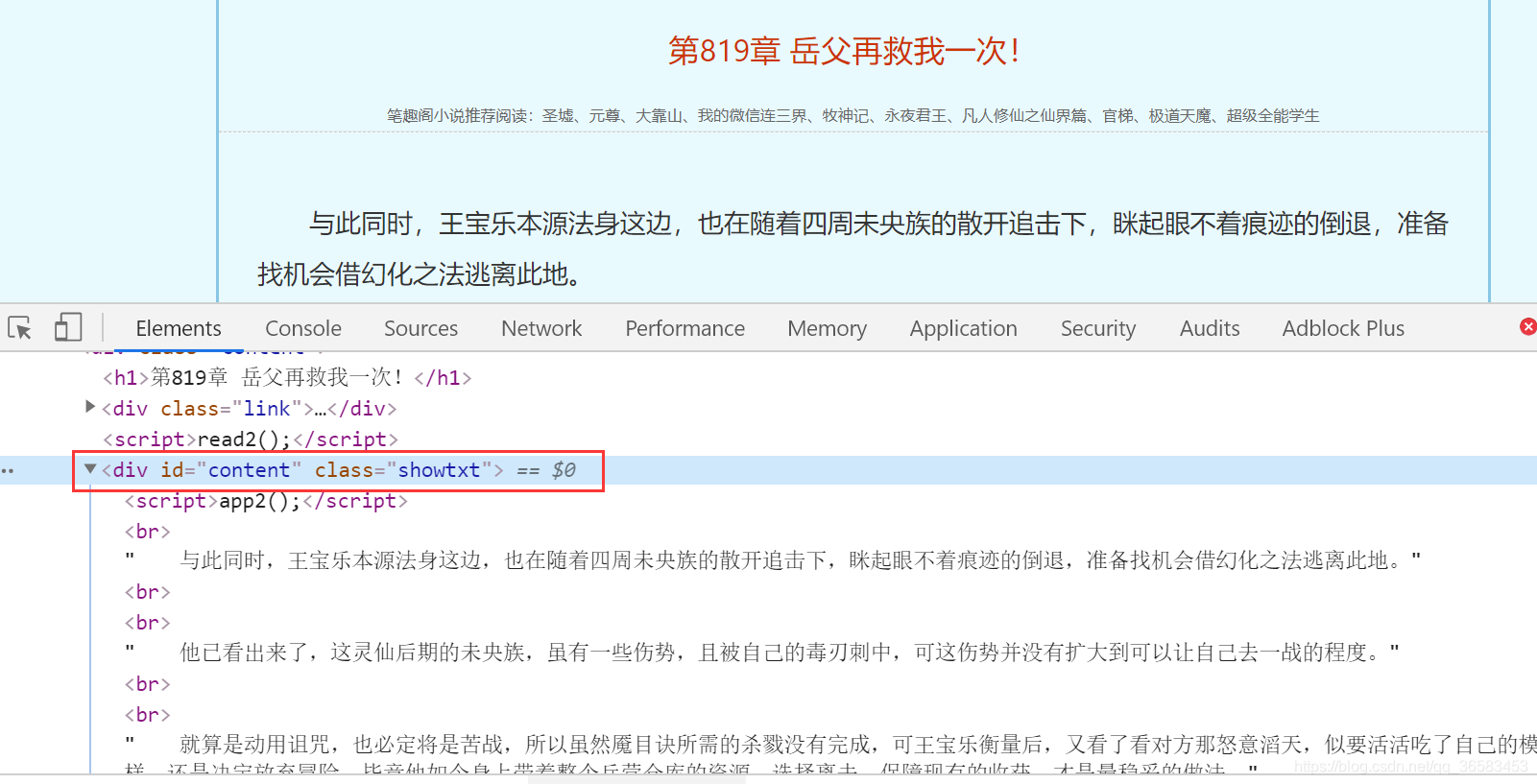
我们需要的小说内容就在id='content’的div标签中,我们通过解析库beautifulSoup或者lxml把我们需要的小说内容从源代码中分离出来.
所以我们只需要知道每个章节小说对应的url就可以获取到所以的小说内容了.
那我们怎么获取小说章节的url呢?一般的,这些url都是通过组合形成.
我们先到章节页面,找到刚才的那章小说的章节名,右键网页,选择检查,选中章节名
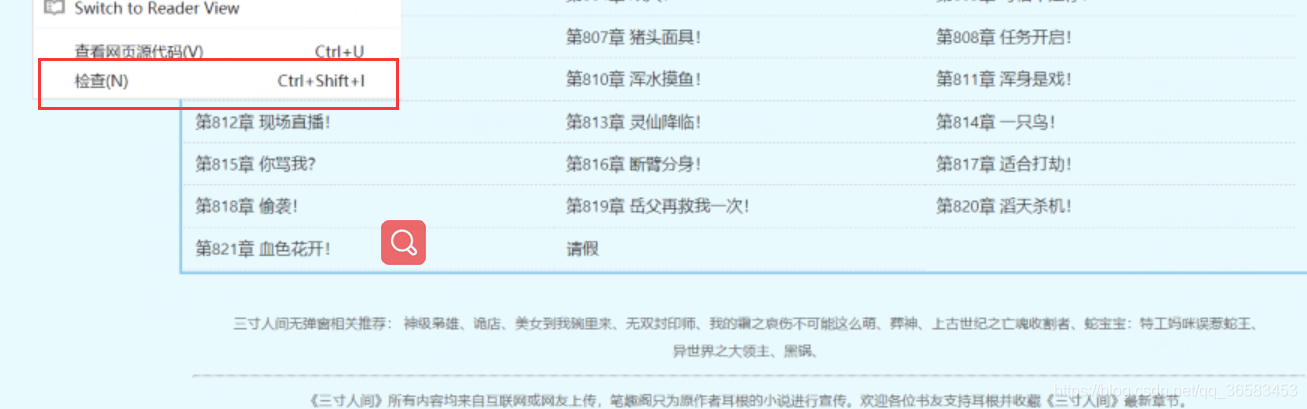
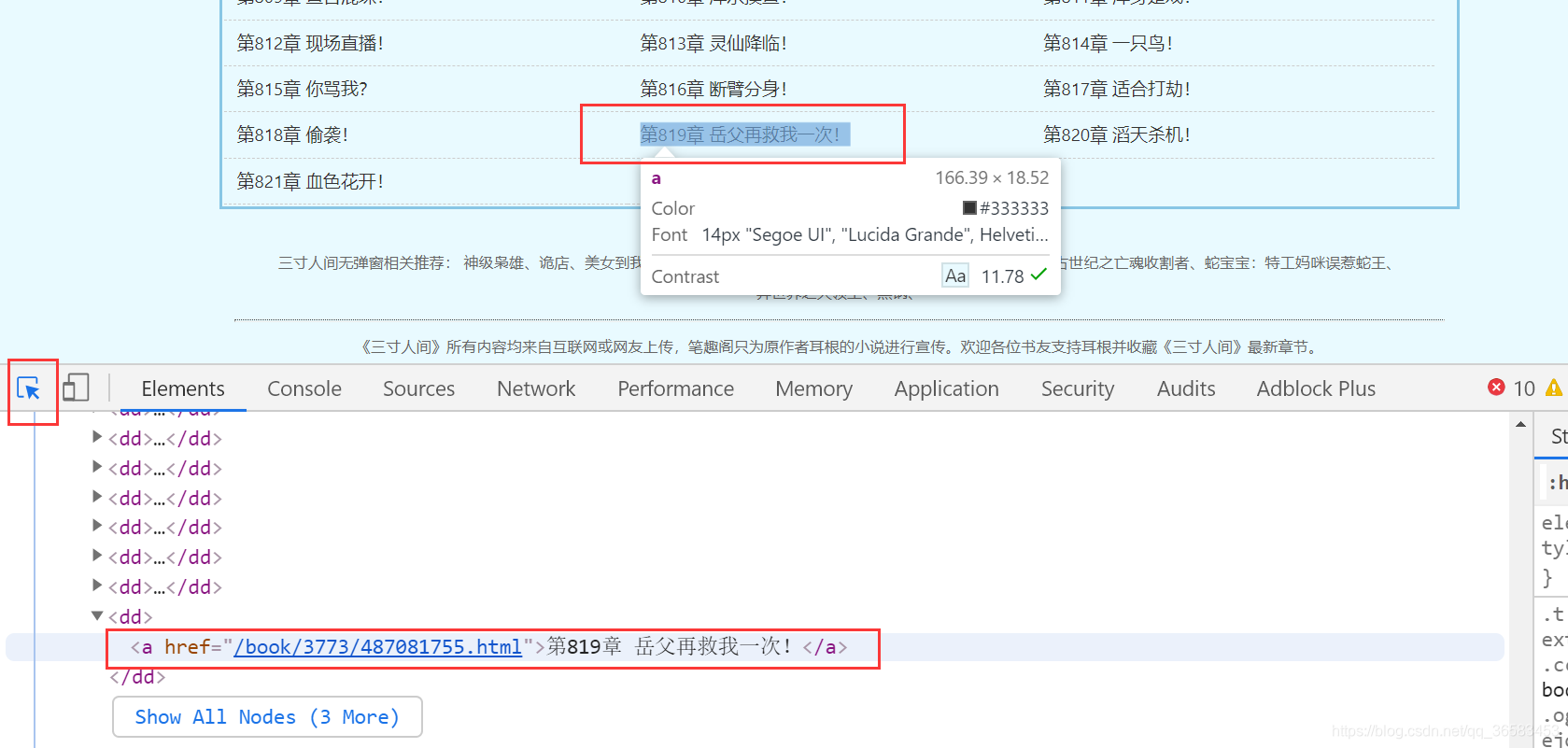
我们选中对应章节名之后,就可以到其有一个url
章节名url:
/book/3773/487081755.html
我们再到小说的主页(https://www.biqiuge.com/)去找到对应的小说

得到了小说名对应url:/book/3773
整理一下:
小说主页url:https://www.biqiuge.com/
小说名url:book/3773
小说章节界面的url:https://www.biqiuge.com/book/3773/
小说章节名的url: /book/3773/487081755.html
小说内容的url:
https://www.biqiuge.com/book/3773/487081755.html
从上可知,你看出了什么了吗?
小说章节界面url由小说注册url和小说名url构成
小说内容url由小说章节界面url和章节名url构成
了解其中的关系之后,我们就是通过requests去请求对应的url来获取不通的信息了.
步骤
获取小说章节界面所有章节的url和章节名
章节页面url:https://www.biqiuge.com/book/12426/
打开章节页面之后,右键检查,发现所有的章节信息都在class='listmain’的div标签里,如下图
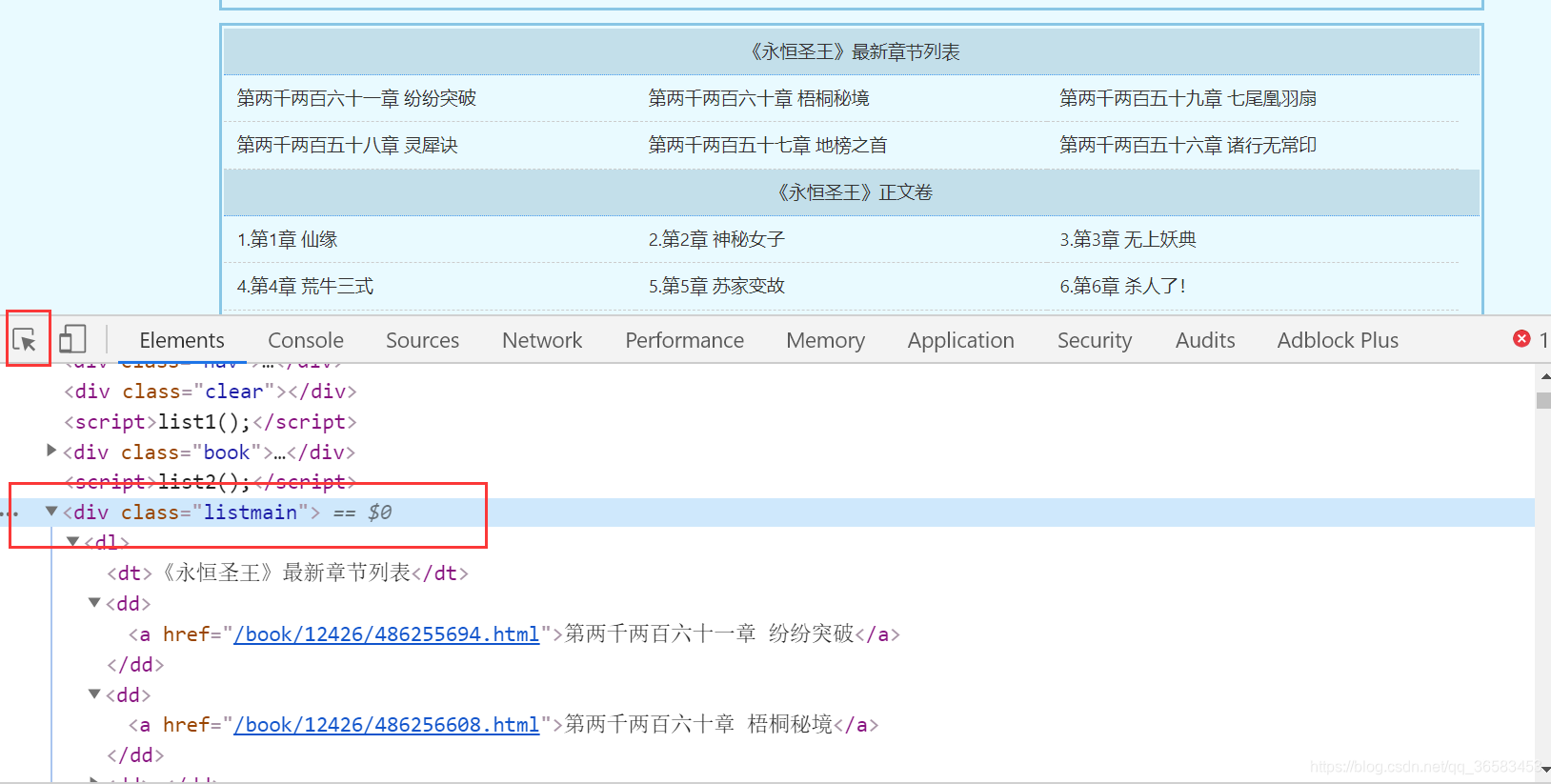
查看这个div标签,发现我们需要的信息是在这个div标签下的子孙标签dd中,如下图

dd标签中的子标签a的文本就是我们需要的章节名,href属性的值就是我们需要的url链接.
明白我们需要的信息在哪里之后就可以写代码了,如下
import requests
from lxml import etree
chapter_web_url='https://www.biqiuge.com/book/12426/' #小说章节页面的url
chapter_web_res=requests.get(chapter_web_url) #获取小说页面的源代码
chapter_web_res.encoding=chapter_web_res.apparent_encoding #正确解码小说章节页面的编码,不然中文会乱码
chapter_web_html=etree.HTML(chapter_web_res.text) #使用lxml模块解析源代码
# //div[@class='listmain']//dd/a 是定位到章节名和url所在的a标签
# //div[@class='listmain']//dd/a/text() 获取a标签的文本
# //div[@class='listmain']//dd/a/@href 获取a标签的href属性的值
all_chapter_name=chapter_web_html.xpath("//div[@class='listmain']//dd/a/text()")
all_chapter_url=chapter_web_html.xpath("//div[@class='listmain']//dd/a/@href")
#由于前面6条是最新更新的章节列表和下面的有冲突,需要剔除
print(all_chapter_name[6:])
print(all_chapter_url[6:])
执行结果如下

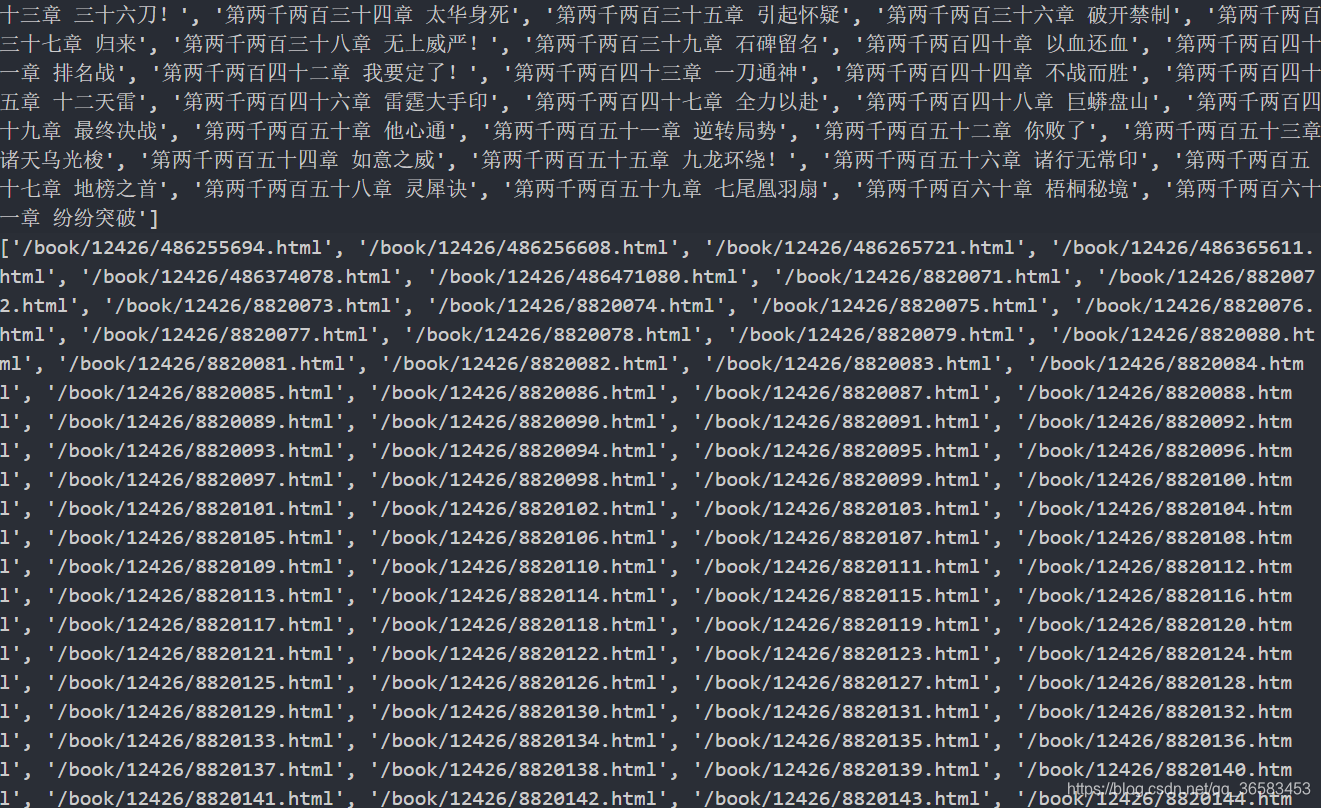 返回的结果为列表.
返回的结果为列表.
保存上次发送的小说信息
通过上面我们就可以获得的整本小说的章节名字和url,但这并不是我们的目标,我们的目标是获取最新更新的小说,所以需要记录下小说的更新章数,和下一次检查的章数作对比.
用一个字典来保存,并存入文件中,以便下一次使用.
import json
novel_info={
'永恒圣王':{'url':'https://www.biqiuge.com/book/12426/','chapter_num':'3504'}
}
novel_info=json.dumps(novel_info,ensure_ascii=False)
with open('novel_info','w',encoding='utf-8') as f:
f.write(novel_info)
获取小说章节的内容
随便打开一章小说,右键检查,定位到小说在哪个标签,如下
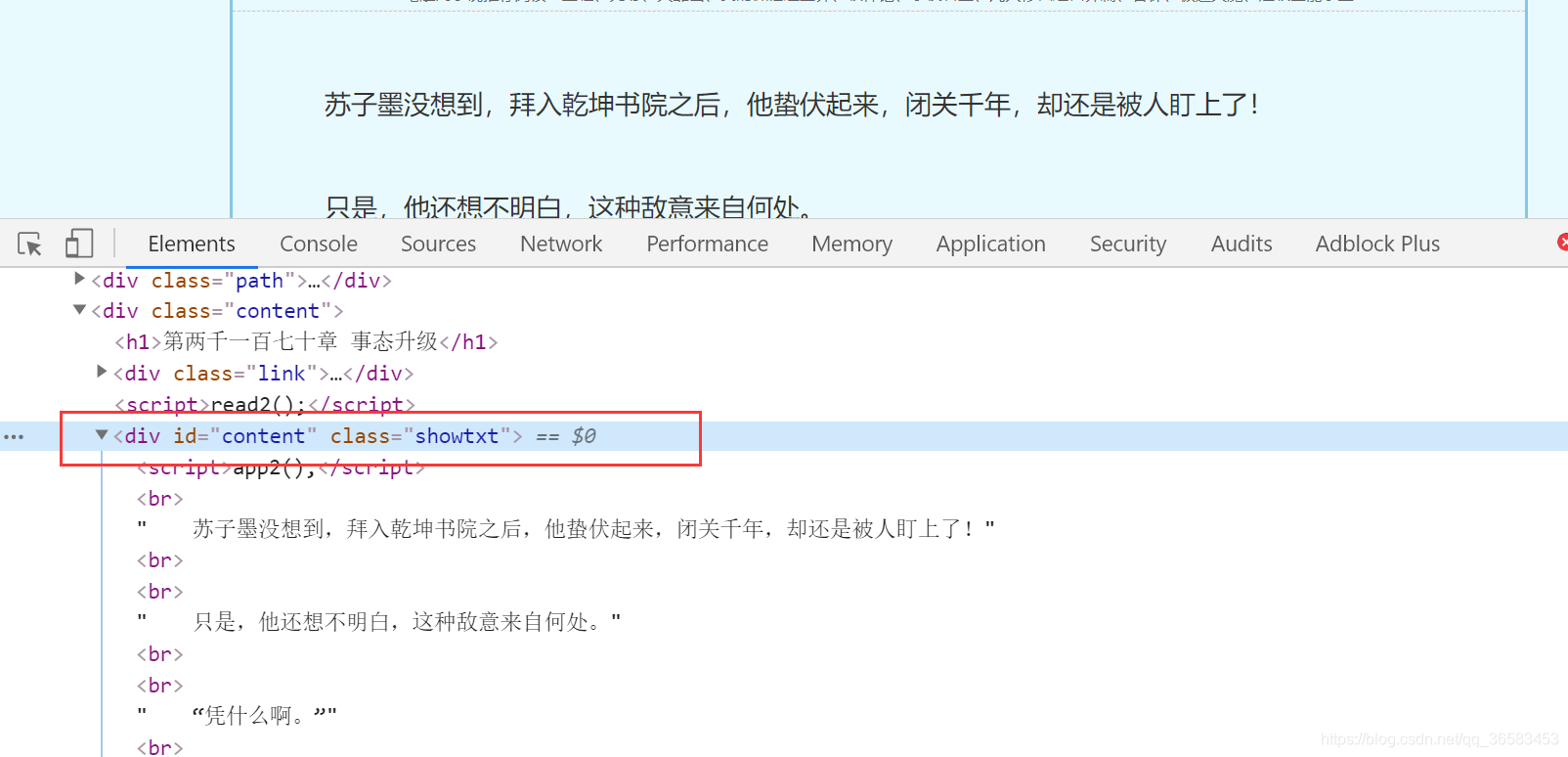
小说的内容在id='content’的div标签中,我们只要获取此div标签的内容,过滤之后就可以得到小说内容了.代码如下
import requests
from lxml import etree
url='https://www.biqiuge.com/book/12426/492365100.html'
novel_content_res=requests.get(url)
novel_content_res.encoding=novel_content_res.apparent_encoding
novel_content_html=etree.HTML(novel_content_res.text)
disordered_novel_content=novel_content_html.xpath("//div[@id='content']//text()")
print(disordered_novel_content)
运行结果如下:

从运行结果上已经看到小说内容,但是我们发现里面混杂了其他数据,这时候我们就还得过滤下其中\u3000代表的是空格,代码如下
import requests
from lxml import etree
url='https://www.biqiuge.com/book/12426/492365100.html'
novel_content_res=requests.get(url)
novel_content_res.encoding=novel_content_res.apparent_encoding
novel_content_html=etree.HTML(novel_content_res.text)
disordered_novel_content=novel_content_html.xpath("//div[@id='content']//text()")
#用于存储过滤后的小说内容
novel_content=''
for content in disordered_novel_content:
if 'app2();' in content or 'chaptererror();' in content:
continue
novel_content=novel_content+content+'\n'
print(novel_content)
过滤之后就可以观看了,更新的小说已经搞定了,接下来是发送邮件
发送邮件
邮件模块分为文本,附件和图片,我们只需要构造文本就行了.
代码如下:
class SEND_MAIL:
def __init__(self):
'''
# 初始化收件人,发件人,发送人的账号和授权密码
:param day:
'''
#QQ邮箱服务器
self.mail_server = 'smtp.qq.com'
self.mail_user = '发送者QQ邮箱'
self.mail_passwd = '发送者QQ邮箱授权码,不是QQ密码,不懂的话百度下'
self.sender = '发送者QQ邮箱'
self.receiver = '接受者QQ邮箱'
def email_heading(self,subject):
'''
构建主题,发件人,收件人,日期是显示在邮件页面上的。
:return:
'''
self.msg['From'] = Header(self.sender, 'utf-8').encode()
self.msg['To'] = Header(self.receiver, 'utf-8').encode()
#邮件的主题
self.msg['Subject'] = Header(subject, 'utf-8').encode()
def send_text(self,text):
'''
发送文本邮件,传入的参数为邮件内容
:return:
'''
mail_content = MIMEText(text, 'plain', 'utf-8')
self.msg.attach(mail_content)
def send_mail(self):
'''
发送邮件
:return:
'''
smtp = smtplib.SMTP()
smtp.connect(self.mail_server, 25)
smtp.login(self.mail_user, self.mail_passwd)
smtp.sendmail(self.sender, self.receiver, self.msg.as_string())
smtp.quit()
最终效果
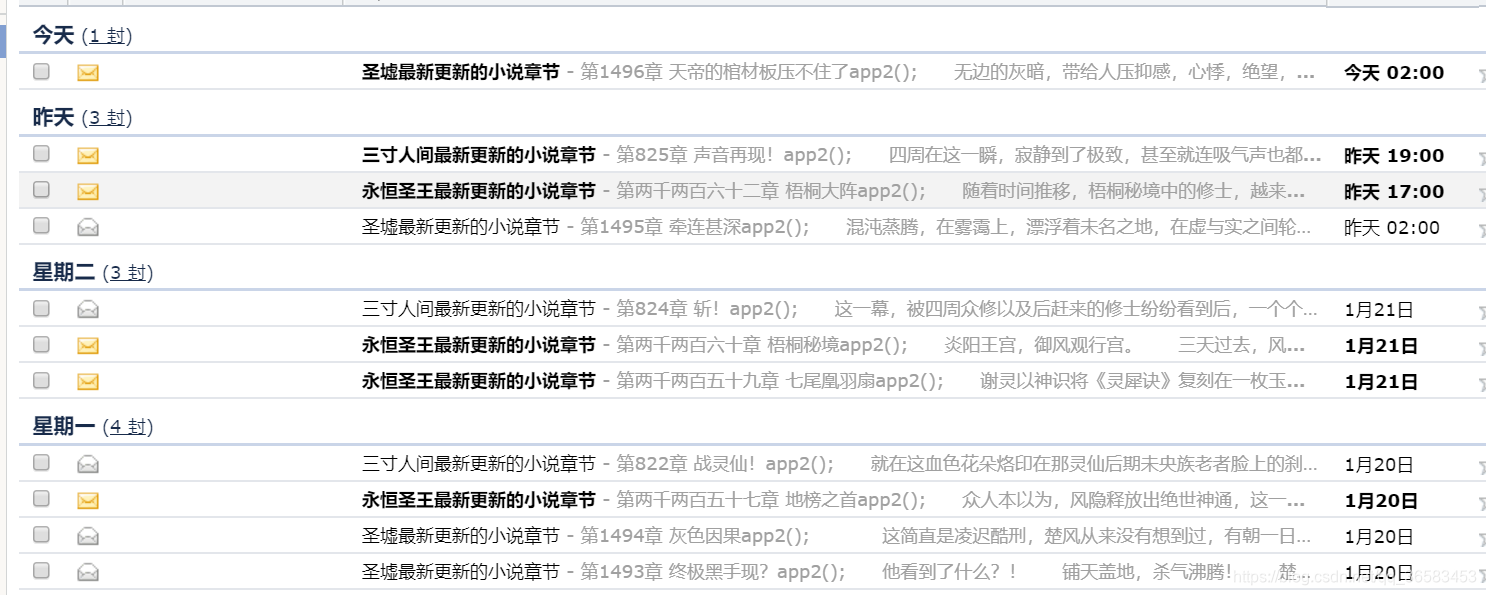
源代码
最后附上源代码
import requests,json
from lxml import etree
from email_class import SEND_MAIL
def get_newest_novel():
with open('novel_info','r',encoding='utf-8') as f:
novels=json.loads(f.read())
for novel_name in novels:
chapter_web_url=novels[novel_name]['url']
chapter_num_before=novels[novel_name]['chapter_num']
# chapter_web_url='https://www.biqiuge.com/book/12426/' #小说章节页面的url
chapter_web_res=requests.get(chapter_web_url) #获取小说页面的源代码
chapter_web_res.encoding=chapter_web_res.apparent_encoding #正确解码小说章节页面的编码,不然中文会乱码
chapter_web_html=etree.HTML(chapter_web_res.text) #使用lxml模块解析源代码
# //div[@class='listmain']//dd/a 是定位到章节名和url所在的a标签
# //div[@class='listmain']//dd/a/text() 获取a标签的文本
# //div[@class='listmain']//dd/a/@href 获取a标签的href属性的值
all_chapter_name=chapter_web_html.xpath("//div[@class='listmain']//dd/a/text()")
all_chapter_url=chapter_web_html.xpath("//div[@class='listmain']//dd/a/@href")
all_chapter_name=all_chapter_name[6:]
all_chapter_url=all_chapter_url[6:]
chapter_num_now=len(all_chapter_name)
print(chapter_num_now)
if chapter_num_now == chapter_num_before:
print('{}没更新'.format(novel_name))
exit()
else:
update_num=chapter_num_now-chapter_num_before
num=chapter_num_before-1
novel_content=''
for i in range(update_num):
num+=1
chapter_name=all_chapter_name[num]
chapter_url=all_chapter_url[num]
print(chapter_name,chapter_url)
novel_content=novel_content+chapter_name+'\n\n'
novel_content_url='https://www.biqiuge.com'+chapter_url
novel_content_res=requests.get(novel_content_url)
novel_content_res.encoding=novel_content_res.apparent_encoding
novel_content_html=etree.HTML(novel_content_res.text)
disordered_novel_content=novel_content_html.xpath("//div[@id='content']//text()")
for content in disordered_novel_content:
if 'app2();' in content or 'chaptererror();' in content:
continue
# content=content.replace('1111','\u3000\u3000')
novel_content=novel_content+content+'\n'
print(novel_content)
sm=SEND_MAIL()
email_subject='{}最新更新的章节'.format(novel_name)
sm.email_heading(email_subject)
sm.send_text(novel_content)
sm.send_mail()
print('发送邮件成功')
#发送邮件之后,需要把最新的章节数写入文本中
update_novel_info={novel_name:{"url": "https://www.biqiuge.com/book/12426/", "chapter_num":chapter_num_now}}
data=json.dumps(update_novel_info)
with open('novel_info','w',encoding='utf-8') as f:
f.write(data)
get_newest_novel()
邮件模块的代码
import smtplib
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.header import Header
class SEND_MAIL:
def __init__(self):
'''
# 初始化收件人,发件人,发送人的账号和授权密码
:param day:
'''
self.mail_server = 'smtp.qq.com'
self.mail_user = '@qq.com'
self.mail_passwd = ''
self.sender = '@qq.com'
# self.receiver = '@qq.com'
self.receiver = '@qq.com'
# 构建邮件对象Multipart对象
self.msg=MIMEMultipart('mixed')
def email_heading(self,subject):
'''
构建主题,发件人,收件人,日期是显示在邮件页面上的。
:return:
'''
self.msg['From'] = Header(self.sender, 'utf-8').encode()
self.msg['To'] = Header(self.receiver, 'utf-8').encode()
self.msg['Subject'] = Header(subject, 'utf-8').encode()
def send_text(self,text):
'''
发送文本邮件,传入的参数为邮件内容
:return:
'''
mail_content = MIMEText(text, 'plain', 'utf-8')
self.msg.attach(mail_content)
def send_image(self,pic_path):
'''
构建邮件附件图片
:param pic_path: 传入图片的绝对路径
:return:
'''
picture=open(pic_path,'rb').read()
mail_image=MIMEImage(picture)
mail_image.add_header('Content-ID', '<image1>')
mail_image.add_header('Content-Disposition', 'attachment', filename=Header(pic_path, 'utf-8').encode())
self.msg.attach(mail_image)
def send_mail(self):
'''
发送邮件
:return:
'''
smtp = smtplib.SMTP()
smtp.connect(self.mail_server, 25)
smtp.login(self.mail_user, self.mail_passwd)
smtp.sendmail(self.sender, self.receiver, self.msg.as_string())
smtp.quit()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









