







文章目录
- 一、源码时序图
- 二、源码解析
- 1. 运行案例程序启动类
- 2. 解析AnnotationConfigApplicationContext类的AnnotationConfigApplicationContext(Class<?>... componentClasses)构造方法
- 3. 解析AbstractApplicationContext类的refresh()方法
- 4. 解析AbstractApplicationContext类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory)方法
- 5. 解析PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, ListbeanFactoryPostProcessors)方法
- 6. 解析PostProcessorRegistrationDelegate类的invokeBeanDefinitionRegistryPostProcessors(Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup)方法
- 7. 解析ConfigurationClassPostProcessor类的postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)方法
- 8. 解析ConfigurationClassPostProcessor类的processConfigBeanDefinitions(BeanDefinitionRegistry registry)方法
- 9. 解析ConfigurationClassParser类的parse(SetconfigCandidates)方法
- 10. 解析ConfigurationClassParser类的parse(AnnotationMetadata metadata, String beanName)方法
- 11. 解析ConfigurationClassParser类的processConfigurationClass(ConfigurationClass configClass, Predicatefilter)方法
- 12. 解析ConfigurationClassParser类的doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass, Predicatefilter)方法
- 13. 解析ComponentScanAnnotationParser类的parse(AnnotationAttributes componentScan, String declaringClass)方法
- 14. 解析ClassPathBeanDefinitionScanner类的doScan(String... basePackages)方法
- 15. 解析ClassPathScanningCandidateComponentProvider类的findCandidateComponents(String basePackage)方法
- 16. 解析ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
- 17. 解析ClassPathScanningCandidateComponentProvider类的isCandidateComponent(MetadataReader metadataReader)方法
- 18. 回到ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
- 19. 回到ClassPathBeanDefinitionScanner类的doScan(String... basePackages)方法
- 20. 解析ClassPathBeanDefinitionScanner类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法
- 21. 解析BeanDefinitionReaderUtils类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法。
- 22. 解析DefaultListableBeanFactory类的registerBeanDefinition(String beanName, BeanDefinition beanDefinition)方法
一、源码时序图
以源码时序图的方式,直观的感受下@ComponentScans注解与@ComponentScan注解在Spring源码层面的执行流程。@ComponentScans注解与@ComponentScan注解在Spring源码层面的执行流程如图所示:
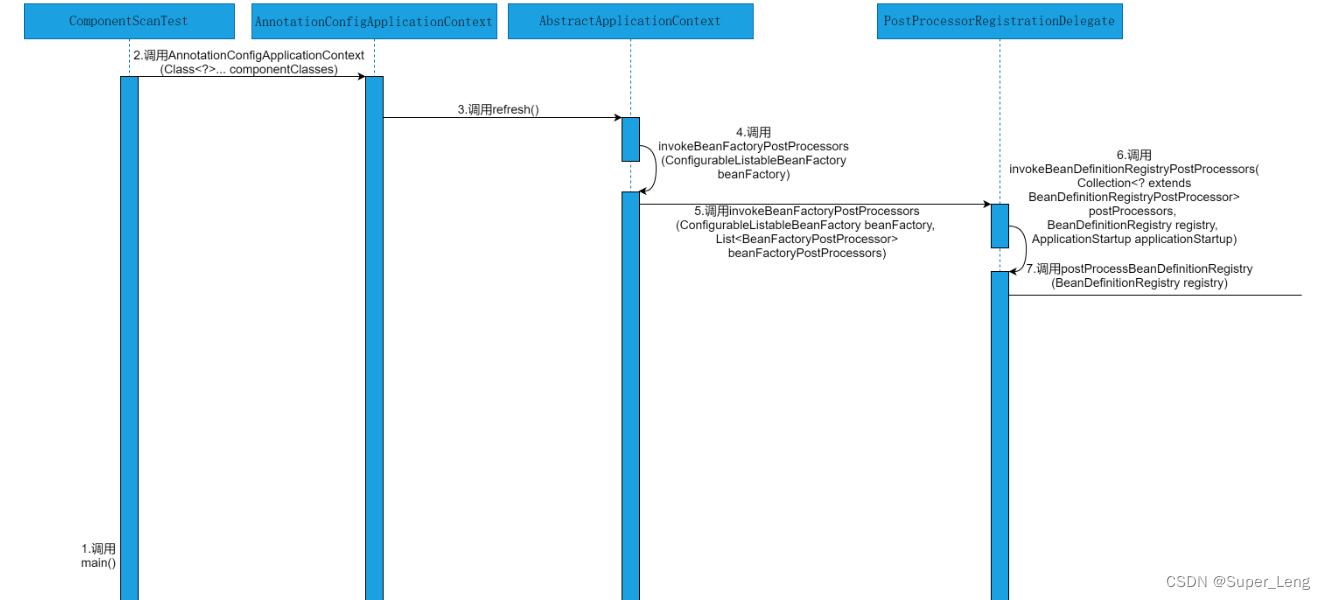
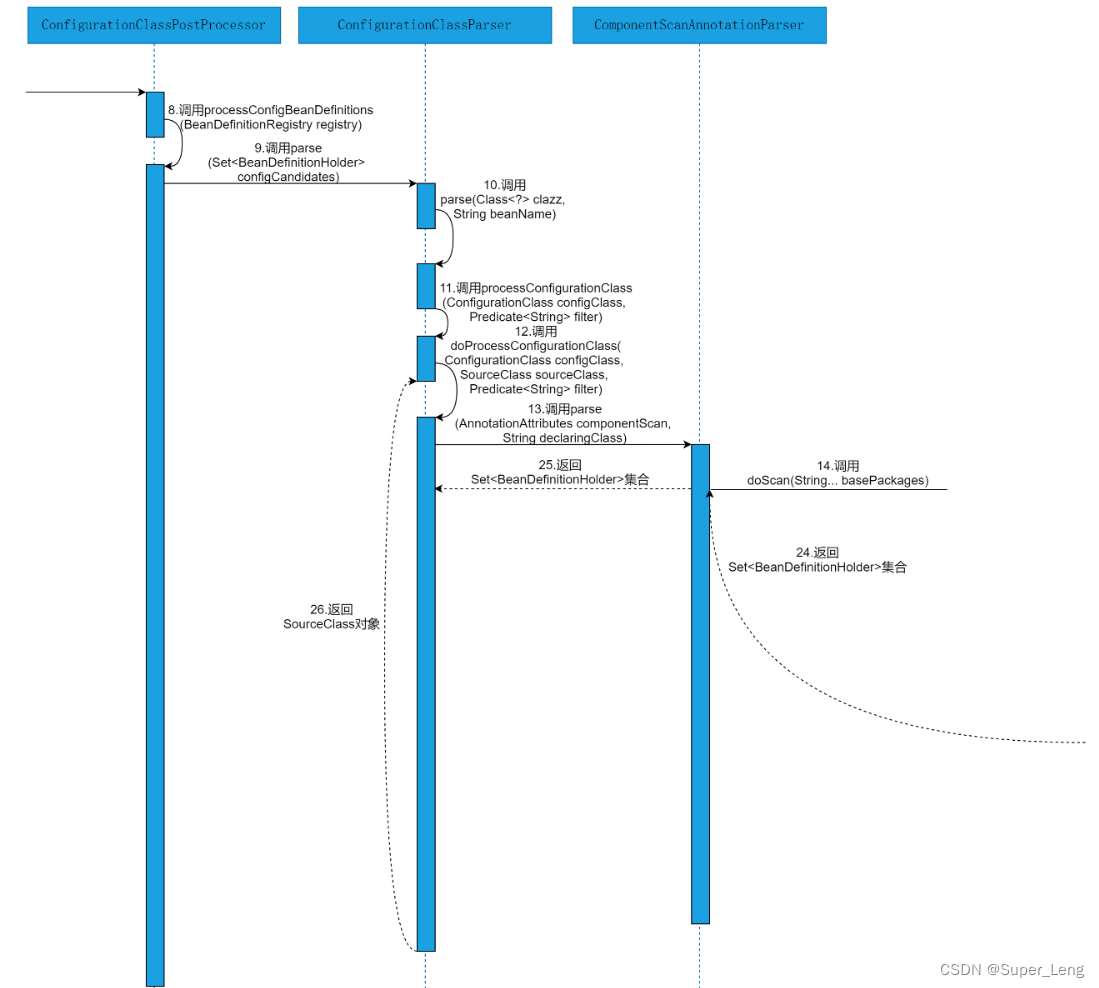
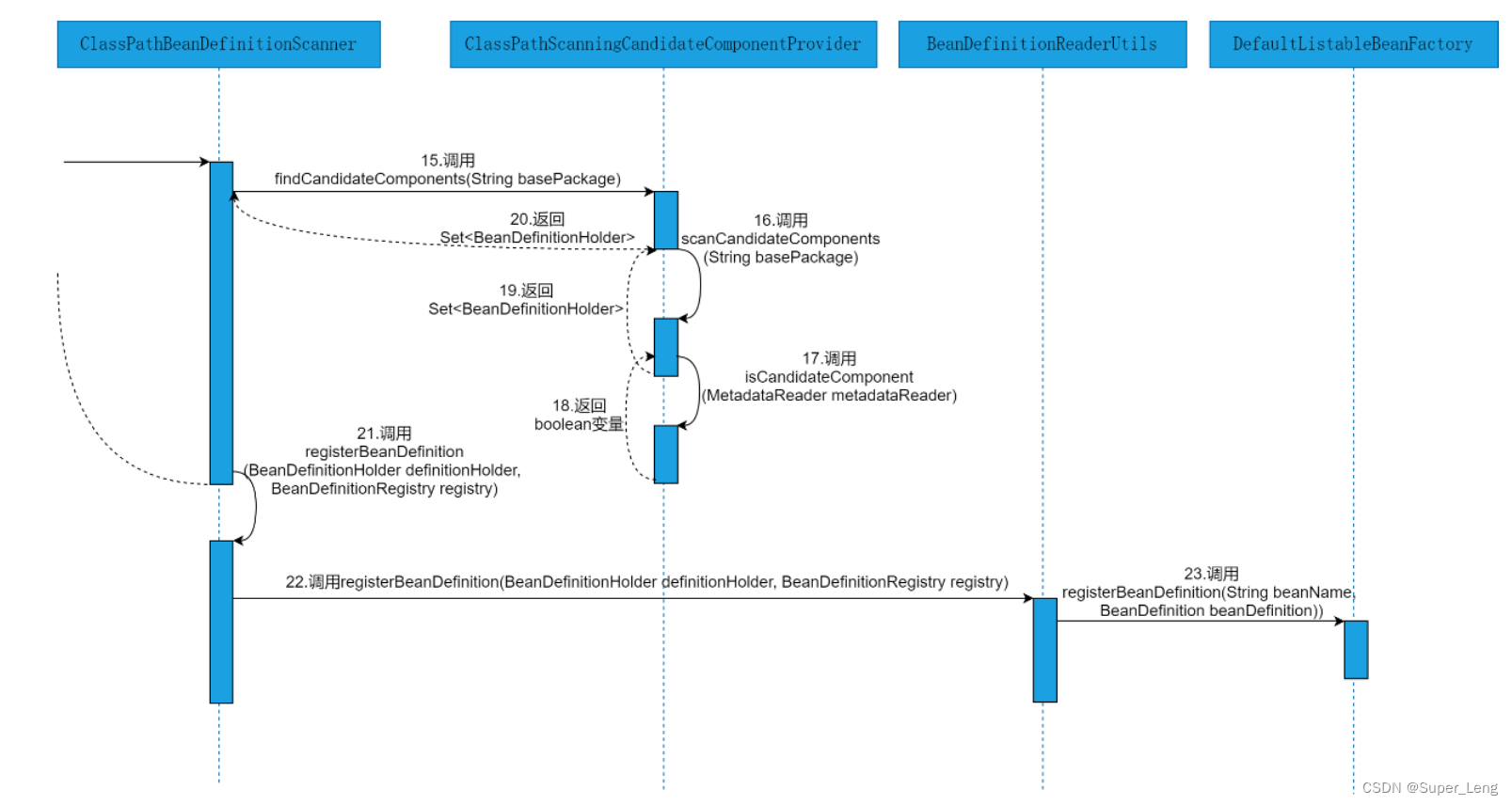
由图可以看出,解析@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程,会涉及到ComponentScanTest类、AnnotationConfigApplicationContext类、AbstractApplicationContext类、PostProcessorRegistrationDelegate类、ConfigurationClassPostProcessor类、ConfigurationClassParser类、ComponentScanAnnotationParser类、ClassPathBeanDefinitionScanner类、ClassPathScanningCandidateComponentProvider类、BeanDefinitionReaderUtils类和DefaultListableBeanFactory类等。具体的源码执行细节参见源码解析部分。
二、源码解析
@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程,结合源码执行的时序图,会理解的更加深刻。
1. 运行案例程序启动类
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(ComponentScanConfig.class);
String[] names = context.getBeanDefinitionNames();
Arrays.stream(names).forEach(System.out::println);
}
可以看到,在ComponentScanTest类的main()方法中调用了AnnotationConfigApplicationContext类的构造方法,并传入了ComponentScanConfig类的Class对象来创建IOC容器。接下来,会进入AnnotationConfigApplicationContext类的构造方法。
2. 解析AnnotationConfigApplicationContext类的AnnotationConfigApplicationContext(Class<?>… componentClasses)构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
register(componentClasses);
refresh();
}
可以看到,在上述构造方法中,调用了refresh()方法来刷新IOC容器。
3. 解析AbstractApplicationContext类的refresh()方法
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//############省略其他代码##############
try {
//############省略其他代码##############
invokeBeanFactoryPostProcessors(beanFactory);
//############省略其他代码##############
}catch (BeansException ex) {
//############省略其他代码##############
}finally {
//############省略其他代码##############
}
}
}
refresh()方法是Spring中一个非常重要的方法,很多重要的功能和特性都是通过refresh()方法进行注入的。可以看到,在refresh()方法中,调用了invokeBeanFactoryPostProcessors()方法。
4. 解析AbstractApplicationContext类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory)方法
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
if (!NativeDetector.inNativeImage() && beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
可以看到,在AbstractApplicationContext类的invokeBeanFactoryPostProcessors()方法中调用了PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors()方法。
5. 解析PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, ListbeanFactoryPostProcessors)方法
由于方法的源码比较长,这里,只关注当前最核心的逻辑,如下所示:
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
//############省略其他代码##############
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
}
//############省略其他代码##############
}
可以看到,在PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, ListbeanFactoryPostProcessors)方法中,BeanDefinitionRegistryPostProcessor的实现类在执行逻辑上会有先后顺序,并且最终都会调用invokeBeanDefinitionRegistryPostProcessors()方法。
6. 解析PostProcessorRegistrationDelegate类的invokeBeanDefinitionRegistryPostProcessors(Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup)方法
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
StartupStep postProcessBeanDefRegistry = applicationStartup.start("spring.context.beandef-registry.post-process")
.tag("postProcessor", postProcessor::toString);
postProcessor.postProcessBeanDefinitionRegistry(registry);
postProcessBeanDefRegistry.end();
}
}
可以看到,在invokeBeanDefinitionRegistryPostProcessors()方法中,会循环遍历postProcessors集合中的每个元素,调用postProcessBeanDefinitionRegistry()方法注册Bean的定义信息。
7. 解析ConfigurationClassPostProcessor类的postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)方法
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
//##########省略其他代码###################
processConfigBeanDefinitions(registry);
}
可以看到,在postProcessBeanDefinitionRegistry()方法中,会调用processConfigBeanDefinitions()方法。
8. 解析ConfigurationClassPostProcessor类的processConfigBeanDefinitions(BeanDefinitionRegistry registry)方法
这里,重点关注方法中的如下逻辑:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
//############省略其他代码#################
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
StartupStep processConfig = this.applicationStartup.start("spring.context.config-classes.parse");
parser.parse(candidates);
parser.validate();
//############省略其他代码#################
}
while (!candidates.isEmpty());
//############省略其他代码#################
}
可以看到,在processConfigBeanDefinitions()方法中,创建了一个ConfigurationClassParser类型的对象parser,并且调用了parser的parse()方法来解析类的配置信息。
9. 解析ConfigurationClassParser类的parse(SetconfigCandidates)方法
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
this.deferredImportSelectorHandler.process();
}
可以看到,在ConfigurationClassParser类的parse(SetconfigCandidates)方法中,调用了类中的另一个parse()方法。
10. 解析ConfigurationClassParser类的parse(AnnotationMetadata metadata, String beanName)方法
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
processConfigurationClass(new ConfigurationClass(metadata, beanName), DEFAULT_EXCLUSION_FILTER);
}
可以看到,上述parse()方法的实现比较简单,直接调用了processConfigurationClass()方法。
11. 解析ConfigurationClassParser类的processConfigurationClass(ConfigurationClass configClass, Predicatefilter)方法
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
//###############省略其他代码####################
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
可以看到,在processConfigurationClass()方法中,会通过do-while()循环获取配置类和其父类的注解信息,SourceClass类中会封装配置类上注解的详细信息。在processConfigurationClass()方法中,调用了doProcessConfigurationClass()方法。
12. 解析ConfigurationClassParser类的doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass, Predicatefilter)方法
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
//##############省略其他代码################
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
//##############省略其他代码################
// No superclass -> processing is complete
return null;
}
这里,只关注与@ComponentScan注解相关的逻辑,可以看到,在上述处理@ComponentScan注解的逻辑中,通过componentScanParser的parse()方法对@ComponentScan注解进行解析。
13. 解析ComponentScanAnnotationParser类的parse(AnnotationAttributes componentScan, String declaringClass)方法
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
看到这里,大家是不是有一种豁然开朗的感觉,原来@ComponentScan注解是在这里解析的!!!!
可以看到,在parse()方法中,会创建一个ClassPathBeanDefinitionScanner类型的扫描器scanner,将@ComponentScan注解上配置的信息都设置到扫描器scanner中,最后调用扫描器scanner的doScan()方法进行扫描。
14. 解析ClassPathBeanDefinitionScanner类的doScan(String… basePackages)方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
在doScan()方法中,会遍历传入的每个包路径,调用findCandidateComponents()方法来扫描带有注解(例如@Component注解)的类。
15. 解析ClassPathScanningCandidateComponentProvider类的findCandidateComponents(String basePackage)方法
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
可以看到,Spring在扫描类时,会调用scanCandidateComponents()方法。
16. 解析ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
String filename = resource.getFilename();
if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) {
// Ignore CGLIB-generated classes in the classpath
continue;
}
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
//################省略其他代码###################
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
可以看到,在scanCandidateComponents()方法中,会调用isCandidateComponent()方法来判断当前注解是不是要扫描的注解。
17. 解析ClassPathScanningCandidateComponentProvider类的isCandidateComponent(MetadataReader metadataReader)方法
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
可以看到,isCandidateComponent()方法的逻辑还是比较简单的,就是遍历匹配excludeFilters和includeFilters指定的规则。
优先匹配excludeFilters指定的规则,如果匹配excludeFilters指定的规则,直接返回false。接下来,匹配includeFilters指定的规则,匹配成功,则调用isConditionMatch()方法进行条件匹配。
其中,对于includeFilters而言,默认的过滤规则如下所示:
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'jakarta.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Jakarta EE) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.inject.Named", cl)), false));
logger.trace("JSR-330 'jakarta.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
可以看到,对于includeFilters而言,默认的过滤规则会匹配@Component注解,JSR-250中的注解和JSR-330中的注解。
18. 回到ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法
在ClassPathScanningCandidateComponentProvider类的scanCandidateComponents(String basePackage)方法中,会将标注了@Component注解,JSR-250中的注解和JSR-330中的注解的类信息封装成ScannedGenericBeanDefinition类对象,也就是类的Bean定义信息。
ScannedGenericBeanDefinition类的构造方法如下所示:
public ScannedGenericBeanDefinition(MetadataReader metadataReader) {
Assert.notNull(metadataReader, "MetadataReader must not be null");
this.metadata = metadataReader.getAnnotationMetadata();
setBeanClassName(this.metadata.getClassName());
setResource(metadataReader.getResource());
}
19. 回到ClassPathBeanDefinitionScanner类的doScan(String… basePackages)方法
在ClassPathBeanDefinitionScanner类的doScan(String… basePackages)方法中,会将扫描到的类的Bean定义信息注册到IOC容器中,如下代码片段所示:
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
可以看到,在doScan()方法中,会调用registerBeanDefinition()注册Bean定义信息。
20. 解析ClassPathBeanDefinitionScanner类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法
protected void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) {
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry);
}
可以看到,在方法中直接调用了BeanDefinitionReaderUtils类的registerBeanDefinition()方法。
21. 解析BeanDefinitionReaderUtils类的registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)方法。
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
//###########省略其他代码###################
}
可以看到,在上述代码中,会继续调用BeanDefinitionRegistry类型的对象registry的registerBeanDefinition()方法,将类的Bean定义信息注册到IOC容器。
22. 解析DefaultListableBeanFactory类的registerBeanDefinition(String beanName, BeanDefinition beanDefinition)方法
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
//##############省略其他代码#################
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
//##############省略其他代码#################
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
//##############省略其他代码#################
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
可以看到,Spring会将扫描到的标注了符合过滤规则的注解的类封装成对应的Bean定义信息,最终会将这些Bean定义信息注册到beanDefinitionMap中。这一点和前面章节注册ConfigurationClassPostProcessor类的Bean定义信息有点类似。
好了,至此,@ComponentScans注解与@ComponentScan注解在Spring源码中的执行流程分析完毕。














 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









