







本文主要是学习open-r1-text2graph:开源复现DeepSeek R1的文本到图谱抽取训练方案
信息提取领域,特别是零样本的文本到图提取任务要求在给定实体和关系类型列表的情况下,从目标文本中提取实体列表以及它们之间的关系。
文本到图输出示例
{
"entities": [
{
"id": 0,
"text": "Microsoft",
"type": "company"
},
{
"id": 1,
"text": "Satya Nadella",
"type": "person"
},
{
"id": 2,
"text": "Azure AI",
"type": "product"
}
],
"relations": [
{
"head": "Satya Nadella",
"tail": "Microsoft",
"type": "CEO of"
},
{
"head": "Microsoft",
"tail": "Azure AI",
"type": "developed"
}
]
}
这是一项相当复杂的任务,尤其对于小型生成式语言模型来说。如果我们不按照所需的实体和关系类型来限制输出,允许模型自由地从文本中提取所有实体和关系,那么语言模型可以完成得相对较好。但是,当我们根据实体和关系类型来限定输出时,这对语言模型而言就成了真正的难题。从我的实验来看,以监督学习的方式训练小型语言模型,使其根据输入的实体类型有条件地从文本中输出图结构是很困难的。强化学习方法带来了希望。
强化学习与监督学习的不同之处在于,我们不会明确告诉模型为实现预期目标应该采取哪些行动。在我们的任务中,目标是根据输入的实体和关系类型正确提取图结构,而行动则是模型生成的标记。我们可以通过最大化以期望格式生成输出的概率,直接告诉模型如何以JSON格式重现这个图结构。
许多人认为思维链是强化学习为大语言模型领域带来的主要助力之一,而且许多论文也表明思维链能够提高模型的性能,因此思维链能提升性能这一观点似乎相当合理。不过,我认为强化学习的其他几个特性也会产生重大影响。但首先,让我们讨论一下DeepSeek提出的GRPO方法。下面是该团队使用的损失函数:
J
G
R
P
O
(
θ
)
=
E
[
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
o
l
d
(
O
∣
q
)
]
1
G
∑
i
=
1
G
(
min
(
π
θ
(
o
i
∣
q
)
π
θ
o
l
d
(
o
i
∣
q
)
A
i
,
clip
(
π
θ
(
o
i
∣
q
)
π
θ
o
l
d
(
o
i
∣
q
)
,
1
−
ε
,
1
+
ε
)
A
i
)
−
β
D
K
L
(
π
θ
∥
π
r
e
f
)
)
J_{GRPO}(\theta)=\mathbb{E}\left[q \sim P(Q), \{o_i\}_{i = 1}^{G} \sim \pi_{\theta_{old}}(O|q)\right] \frac{1}{G} \sum_{i = 1}^{G}\left(\min \left(\frac{\pi_{\theta}(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)} A_{i}, \text{clip}\left(\frac{\pi_{\theta}(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)}, 1 - \varepsilon, 1 + \varepsilon\right) A_{i}\right)-\beta \mathbb{D}_{KL}(\pi_{\theta} \| \pi_{ref})\right)
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∥πref))
D
K
L
(
π
θ
∥
π
r
e
f
)
=
π
r
e
f
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
log
π
r
e
f
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
1
\mathbb{D}_{KL}(\pi_{\theta} \| \pi_{ref})=\frac{\pi_{ref}(o_{i}|q)}{\pi_{\theta}(o_{i}|q)}-\log\frac{\pi_{ref}(o_{i}|q)}{\pi_{\theta}(o_{i}|q)}-1
DKL(πθ∥πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1
其中,
ε
\varepsilon
ε和
β
\beta
β是超参数,
A
i
A_{i}
Ai是优势值,通过每组输出对应的一组奖励
{
r
1
,
r
2
,
⋯
,
r
G
}
\{r_1, r_2, \cdots, r_G\}
{r1,r2,⋯,rG} 计算得出:
A
i
=
r
i
−
mean
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
std
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
A_{i}=\frac{r_{i}-\text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})}
Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})
这里不深入探讨数学细节,我简单从高层次解释一下它的含义。基本上,我们为给定问题生成一组候选解决方案,并根据某个解决方案获得的奖励来最大化该方案作为问题答案返回的概率。此外,通过KL散度收敛项,我们试图最小化与作为起点的原始模型之间的偏差。
这样的训练算法具有一些有趣的特性。例如,我们迫使模型生成多个先验上对于给定问题来说是困难负样本的解决方案,因为模型对它们的生成赋予了相对较高的概率。从某种意义上说,模型在训练过程中既看到了正样本,也看到了负样本。
此外,正如安德烈·卡帕西(Andrej Karpathy)指出的,直接的标签示例无法促使模型利用其知识来推断一些新的涌现属性,比如那种“顿悟”时刻:
“模型永远无法通过模仿学习到这一点,因为模型的认知和人类标注者的认知是不同的。人类永远不知道如何正确标注这类解决问题的策略,甚至不知道它们应该是什么样的。这些策略必须在强化学习过程中被发现,因为从经验和统计角度来看,它们对最终结果是有用的。”
强化学习的另一个有趣特性是,我们可以优化不同的目标,并手动控制它们的影响。例如,如果我们发现模型在关系提取方面存在困难,那么与其他特征相比,我们可以为正确提取关系的示例分配更高的奖励。
那么,下面让我们讨论一下使用GRPO训练模型进行文本到图推理的具体做法,你可以通过下面的可视化图表来了解:
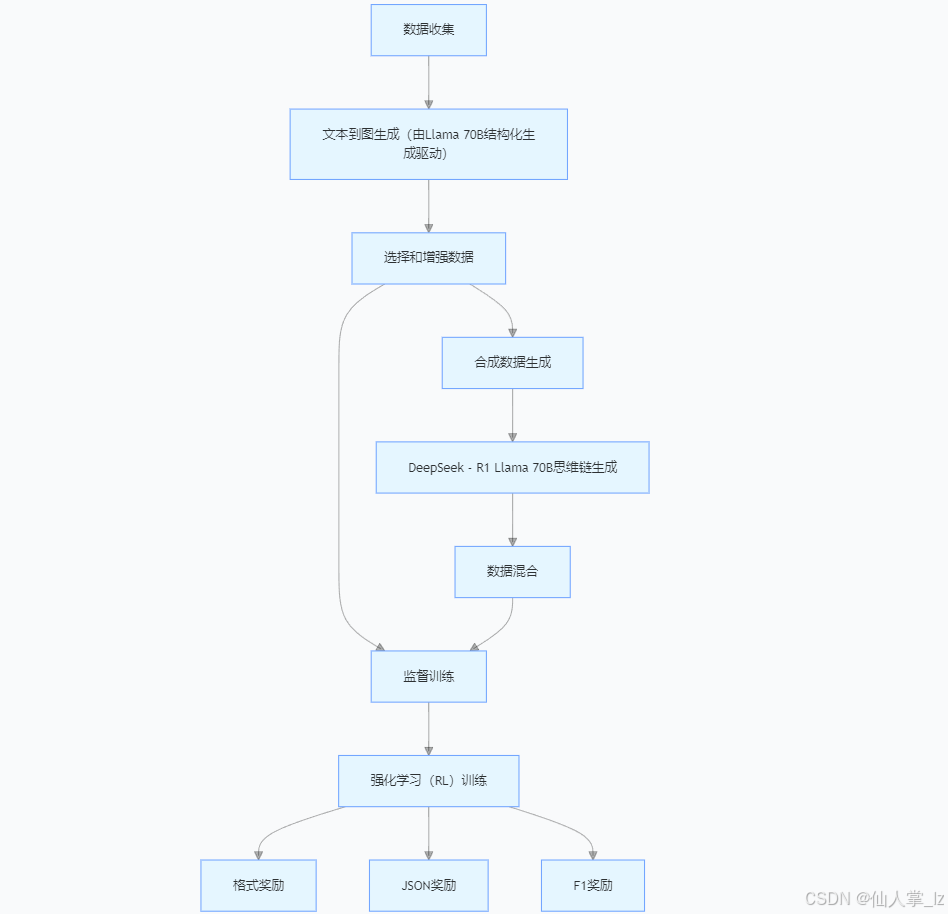
训练过程主要包括三个阶段:合成数据生成、监督训练和强化学习(RL)训练。这些阶段对于提高模型执行结构化信息提取的能力都至关重要。
合成数据生成
为启动整个流程,项目从数据收集开始,收集与目标领域相关的各种文本来源。由Llama 70B结构化生成驱动的文本到图生成步骤,将非结构化文本转换为基于图的表示形式,也就是进行抽取,形成如下形式
{
"entities": [
{
"id": 0,
"text": "Microsoft",
"type": "company"
},
{
"id": 1,
"text": "Satya Nadella",
"type": "person"
},
{
"id": 2,
"text": "Azure AI",
"type": "product"
}
],
"relations": [
{
"head": "Satya Nadella",
"tail": "Microsoft",
"type": "CEO of"
},
{
"head": "Microsoft",
"tail": "Azure AI",
"type": "developed"
}
]
}
。然而,这一步并不完美,因此选择和增强数据对于过滤掉低质量的提取结果,并使用更多样化的结构丰富数据集至关重要。
此外,将结构化预测生成的JSON数据(这里用到的数据在:https://huggingface.co/datasets/Ihor/Text2Graph-Open-R1)以及文本输入到DeepSeek - R1 Llama 70B中,以生成能够解释提取过程的思维链(但是思维链数据并未开放,合成数据prompt 如下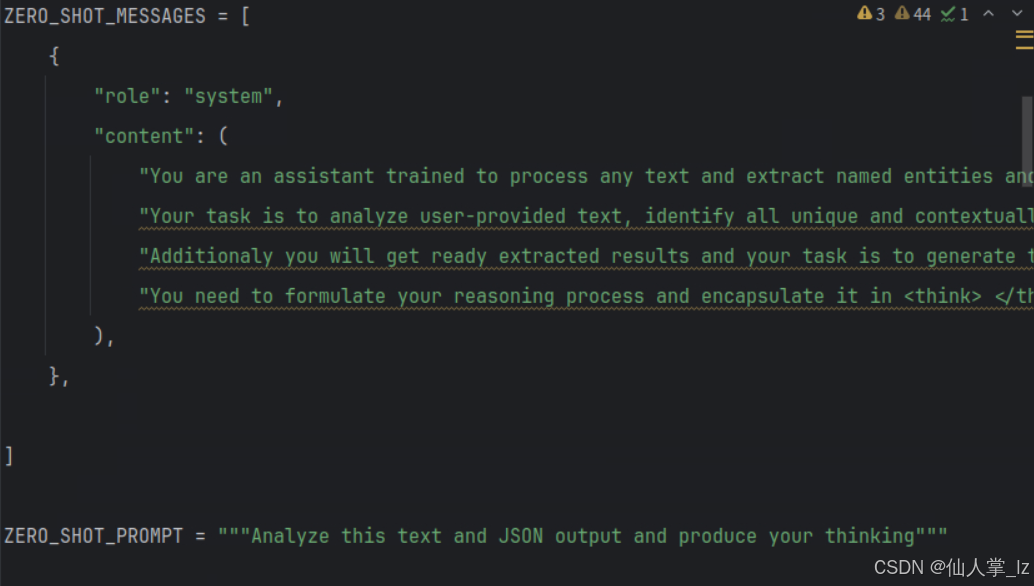
,脚本在:https://github.com/Ingvarstep/open-r1-text2graph/blob/main/src/generate.py)。运行后获取到的思维链数据格式如下:
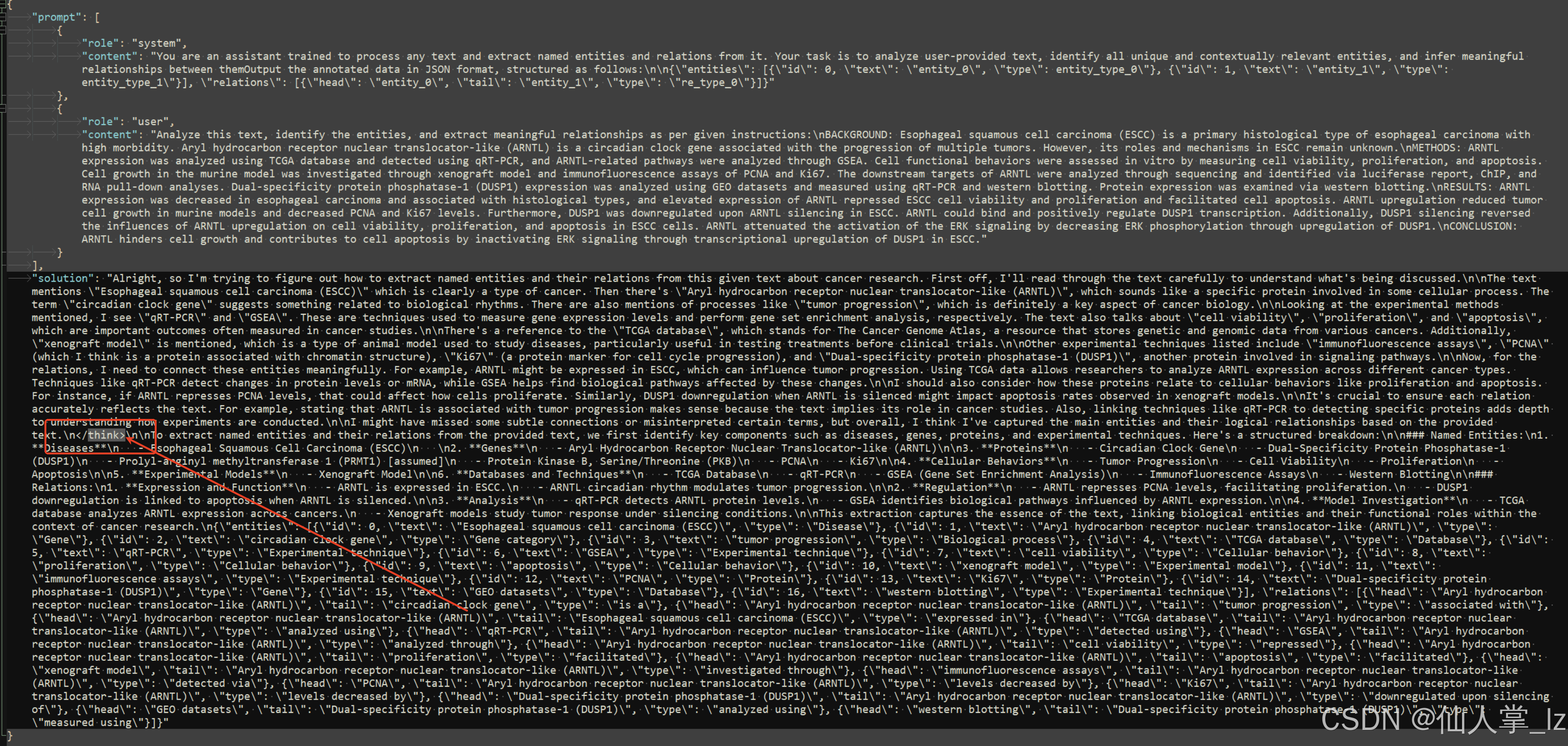
监督训练
在开始强化学习之前,考虑到项目使用的是小型模型,需要进行额外的监督训练,以确保模型返回的数据格式正确。为此,项目仅使用了1000个示例。微调的代码在:https://github.com/Ingvarstep/open-r1-text2graph/blob/main/src/train_supervised.py
使用GRPO的强化学习
仅靠监督训练并不能完全解决问题,尤其是在根据预定义的实体和关系类型来限定模型输出方面。为了解决这个问题,项目在强化学习中采用了群体相对策略优化(GRPO)方法。
格式奖励确保输出遵循结构化格式,在启用思维链模式的情况下,思维链会封装在相应的标签中。
def format_reward(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
completion_contents = [completion[0]["content"] for completion in completions]
matches = [("<think>" in content and "</think>" in content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]
JSON奖励专门用于验证格式良好、机器可读的JSON表示形式,并且其结构符合期望的格式。
def json_consistency_reward(completions, solution, **kwargs):
"""
计算JSON一致性奖励。
根据完成情况和解决方案中的JSON内容是否唯一一致来分配奖励。
参数:
- completions: 完成的任务列表,其中每个任务包含一个带有内容的字典。
- solution: 标准解决方案的列表,用于比较。
- **kwargs: 其他可变关键字参数,这里未使用。
返回:
- rewards: 一个奖励列表,每个完成的任务对应一个奖励值。
"""
# 提取所有完成任务的内容
contents = [completion[0]["content"] for completion in completions]
# 初始化奖励列表
rewards = []
# 遍历每个完成的任务内容和对应的解决方案
for content, sol in zip(contents, solution):
# 从内容中提取JSON对象
extracted_jsons = extract_json_from_text(content)
# 如果提取的JSON对象唯一,则认为完成情况良好,给予奖励
if len(extracted_jsons)==1:
rewards.append(0.1)
else:
rewards.append(0.0)
return rewards
def json_structure_reward(completions, solution, **kwargs):
"""
计算JSON结构奖励。
根据完成情况中的JSON内容是否唯一且结构有效来分配奖励。
参数:
- completions: 完成的任务列表,其中每个任务包含一个带有内容的字典。
- solution: 标准解决方案的列表,用于比较。
- **kwargs: 其他可变关键字参数,这里未使用。
返回:
- rewards: 一个奖励列表,每个完成的任务对应一个奖励值。
"""
# 提取所有完成任务的内容
contents = [completion[0]["content"] for completion in completions]
# 初始化奖励列表
rewards = []
# 遍历每个完成的任务内容和对应的解决方案
for content, sol in zip(contents, solution):
# 从内容中提取JSON对象
extracted_jsons = extract_json_from_text(content)
# 如果提取的JSON对象唯一,则进一步验证其结构
if len(extracted_jsons)==1:
extracted_json = extracted_jsons[0]
# 验证JSON结构是否有效
val = validate_json_structure(extracted_json)
if val:
rewards.append(0.1)
else:
rewards.append(0.0)
else:
rewards.append(0.0)
return rewards
F1奖励通过将提取的实体和关系与真实图结构进行比较,来评估提取的准确性。
def f1_entities_reward(completions, solution, **kwargs):
"""
计算预测实体的F1分数奖励。
参数:
- completions: 预测的完成情况,包含预测的实体信息。
- solution: 正确的解决方案,包含实际的实体信息。
- **kwargs: 其他可变关键字参数。
返回:
- rewards: 每个预测的F1分数奖励列表。
"""
# 提取每个完成情况的内容
contents = [completion[0]["content"] for completion in completions]
rewards = []
# 遍历每个预测内容和解决方案
for content, sol in zip(contents, solution):
# 从文本中提取预测和真实的JSON信息
extracted_jsons_pred = extract_json_from_text(content)
extracted_jsons_true = extract_json_from_text(sol)
# 如果预测和真实的JSON都只有一个,则计算F1分数
if len(extracted_jsons_pred)==1 and len(extracted_jsons_true)==1:
json_pred = extracted_jsons_pred[0]
json_true = extracted_jsons_true[0]
f1_reward = 0
try:
# 计算并累加实体的F1分数
f1_reward += get_entities_f1_score(json_pred['entities'], json_true['entities'])
except:
# 异常情况下不进行操作
pass
# 将计算的F1分数添加到奖励列表中
rewards.append(f1_reward)
else:
# 如果预测或真实的JSON数量不是1,则奖励为0
rewards.append(0)
return rewards
def f1_relations_reward(completions, solution, **kwargs):
"""
计算预测关系的F1分数奖励。
参数:
- completions: 预测的完成情况,包含预测的关系信息。
- solution: 正确的解决方案,包含实际的关系信息。
- **kwargs: 其他可变关键字参数。
返回:
- rewards: 每个预测的F1分数奖励列表。
"""
# 提取每个完成情况的内容
contents = [completion[0]["content"] for completion in completions]
rewards = []
# 遍历每个预测内容和解决方案
for content, sol in zip(contents, solution):
# 从文本中提取预测和真实的JSON信息
extracted_jsons_pred = extract_json_from_text(content)
extracted_jsons_true = extract_json_from_text(sol)
# 如果预测和真实的JSON都只有一个,则计算F1分数
if len(extracted_jsons_pred)==1 and len(extracted_jsons_true)==1:
json_pred = extracted_jsons_pred[0]
json_true = extracted_jsons_true[0]
f1_reward = 0
try:
# 计算并累加关系的F1分数
f1_reward += get_relations_f1_score(json_pred['relations'], json_true['relations'])
except:
# 异常情况下不进行操作
pass
# 将计算的F1分数添加到奖励列表中
rewards.append(f1_reward)
else:
# 如果预测或真实的JSON数量不是1,则奖励为0
rewards.append(0)
return rewards
为不同的奖励函数设置了不同的系数,并优先考虑F1奖励,因为在早期实验中,发现模型在生成小JSON输出时容易陷入局部最优解。
强化学习阶段使模型能够动态调整其生成策略,在必要时强调正确的关系提取。此外,GRPO使模型能够生成多个候选解决方案,并从正样本和负样本中学习,从而实现更强大的文本到图提取能力。
下面你可以看到不同奖励随时间的变化情况。
可以看出,由于监督预训练,JSON奖励很快就趋于饱和,而F1奖励则持续增长。
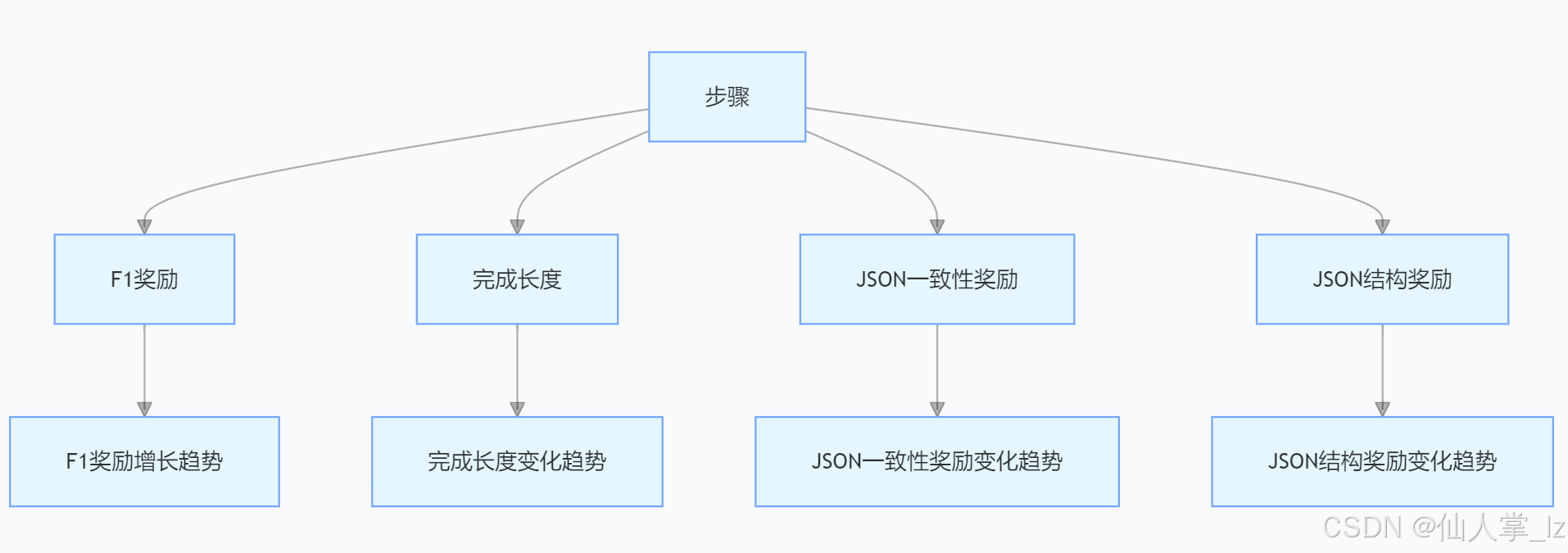
经过短暂的无监督学习后,模型的性能有所提升,如果进行更多的强化学习训练步骤,其性能可能会更好。
项目计划使用更大的模型和更多高质量的数据进行更多实验,敬请期待。在此期间,你可以尝试项目实验中的一个模型:
https://huggingface.co/Ihor/Text2Graph-R1-Qwen2.5-0.5b
要运行该模型,请参考以下代码片段:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Ihor/Text2Graph-R1-Qwen2.5-0.5b"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = """Your text here..."""
prompt = "Analyze this text, identify the entities, and extract meaningful relationships as per given instructions:{}"
messages = [
{"role": "system", "content": (
"You are an assistant trained to process any text and extract named entities and relations from it. "
"Your task is to analyze user-provided text, identify all unique and contextually relevant entities, and infer meaningful relationships between them"
"Output the annotated data in JSON format, structured as follows:\n\n"
"""{"entities": [{"type": entity_type_0", "text": "entity_0", "id": 0}, "type": entity_type_1", "text": "entity_1", "id": 0}], "relations": [{"head": "entity_0", "tail": "entity_1", "type": "re_type_0"}]}"""
)},
{"role": "user", "content": prompt.format(text)}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
对于知识图谱这种任务,其实直接sft,还是主流的方法。不过这个项目还是为我们打开了一个思路,如何利用GRPO去提高真实效果1
模型也已经出来了的,放在https://huggingface.co/Ihor/Text2Graph-R1-Qwen2.5-0.5b,体验了下,效果不是很好。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











