







JuDGE(Judgment Document Generation Evaluation),清华大学法律科技与社会研究中心贡献了首个针对中文法律判决书生成的评测基准,旨在解决法律领域生成任务中缺乏标准化评估框架的问题。通过构建包含真实案例事实描述与对应判决书的大规模数据集,结合外部法律条文库与历史判例库,提出多维度自动化评估体系,并系统测试了多种生成方法(如微调、RAG)的性能差异,为法律文本生成研究提供了重要参考。

核心贡献
-
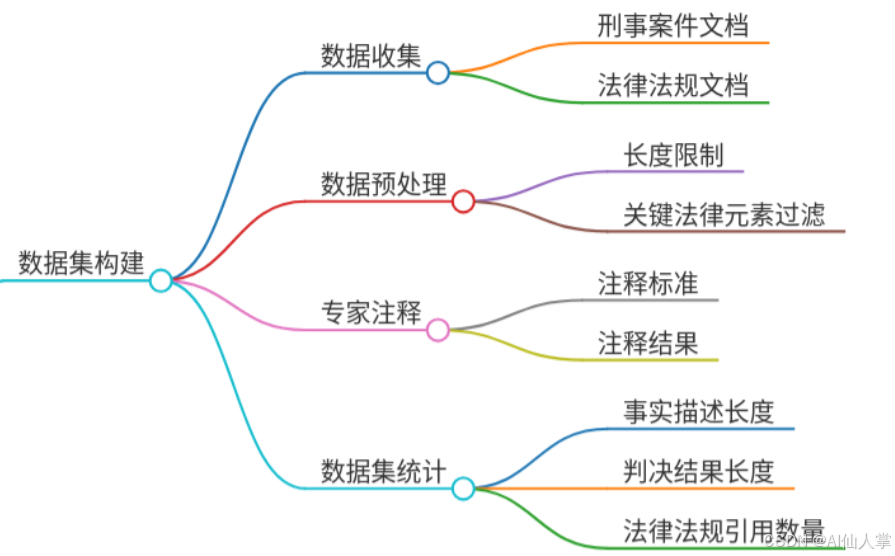
构建高质量法律数据集
- 数据来源:从中国裁判文书网收集2505个刑事案件,覆盖142种罪名、182条法律条款,确保案例多样性。
- 结构化处理:将判决书拆解为事实描述(Fact)、司法推理(Reasoning)、**判决结果(Judgment)**等字段,形成(key, value)对。
- 外部知识库:补充103,251份历史判决书与55,348条法律法规,增强检索增强生成(RAG)的上下文支持。
-
自动化多维度评估框架
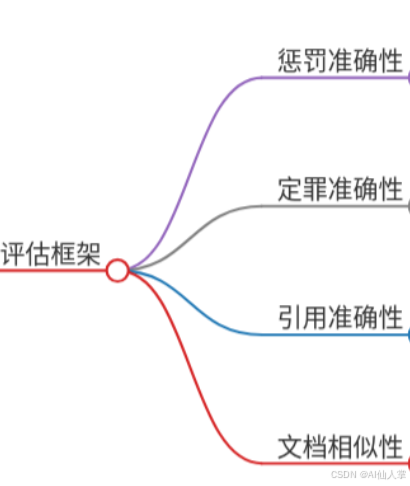
联合法律专家设计四维度评估指标:
- 刑罚准确性(Penalty Accuracy):量化刑期与罚金预测误差(公式: S = 1 − ∣ L pred − L true ∣ max ( L pred , L true ) S=1-\frac{|L_{\text{pred}}-L_{\text{true}}|}{\max(L_{\text{pred}}, L_{\text{true}})} S=1−max(Lpred,L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











