







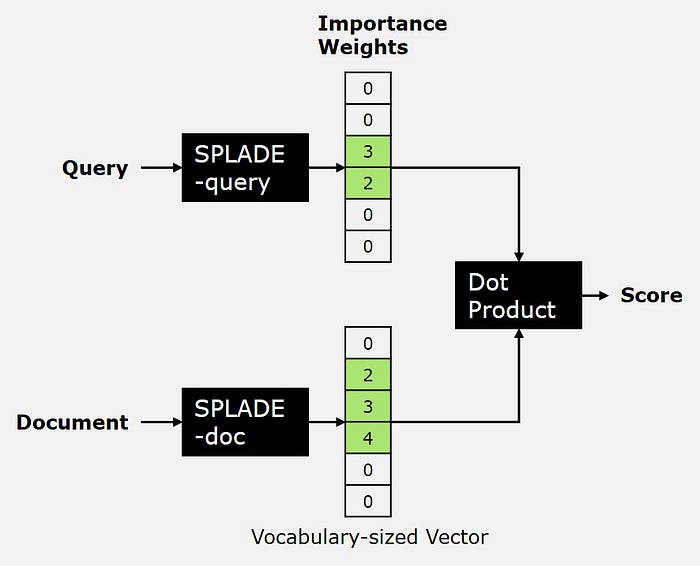
这是检索 SPLADE 模型的高级概述,它会根据用户查询对文档进行评分。Dr. Leon Eversberg 在 AI Advances 中的分享。
大型语言模型(LLMs)的知识是基于它们的训练数据有限的。
检索增强型生成(RAG)旨在通过引入通常存储在数据库中的文档,为 LLMs 提供额外的外部知识。这使得 LLMs 能够提供更准确且与上下文更相关的回答。RAG 系统的一个关键组成部分就是检索器。检索器的工作是根据用户的查询找到匹配的文档。
SPLADE 是基于 BERT 的稀疏检索模型,BERT 是一种基于 Transformer 的编码器模型。在本文中,我们将使用 SPLADE 进行信息检索,构建一个高级的 RAG 流程。
SPLADE:稀疏词汇和扩展模型,用于第一阶段排名
SPLADE 代表“稀疏词汇和扩展”(SParse Lexical AnD Expansion)。它是一种高效的检索模型,具有两个关键特性:稀疏性和查询扩展[1]。
“稀疏”意味着大多数输出向量都是零,只有少数非零向量。与稀疏相反的是密集,密集向量中通常没有零。
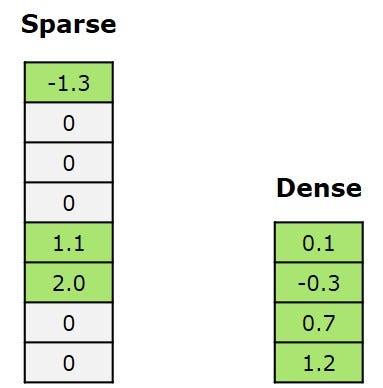
稀疏(左)与密集(右)向量的对比。图片由作者本人提供。
稀疏向量可以更高效地存储在数据库中,因为我们只关注非零值,而且稀疏计算比密集计算更快。
查询扩展会用同义词重写用户查询,以提高检索性能。SPLADE 在训练过程中自动学习执行查询扩展。
例如,给定查询“the cat”,BM25 算法只会搜索文档语料库中的“the”和“cat”这两个词。然而,SPLADE“知道”还要搜索“cats”和“kitty”等词。

这是使用 SPLADE-doc 扩展输入文本的一个例子。权重越高,标记越重要。图片由作者本人提供。
SPLADE 模型
SPLADE 模型将输入标记序列转换为N个对数向量序列。每个对数向量z的大小是词汇表的大小。这意味着对于词汇表中每一个可能的标记,对数都会输出一个数字。然而,由于对数是稀疏的,大多数对数值都是零。
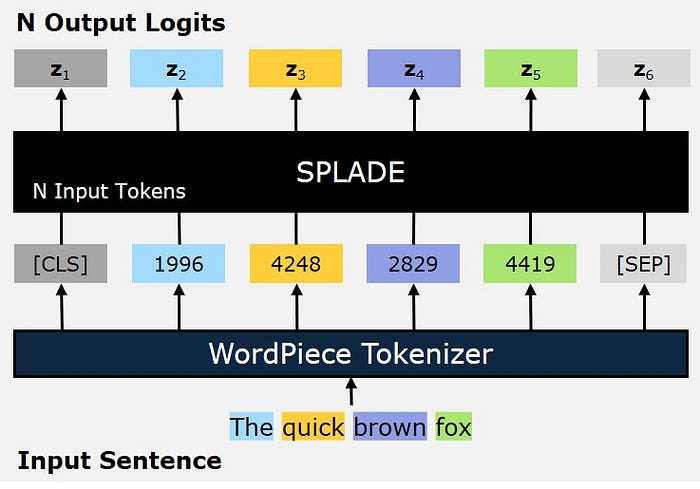
SPLADE 模型将输入标记转换为 N=6 个输出对数。每个对数向量z的大小是 30,522。图片由作者本人提供。
词汇表由分词器定义。WordPiece分词器将输入句子转换为标记序列。
WordPiece 分词器
WordPiece 是一种子词分词算法,用于预训练BERT。标记通常是一个词,但也可能是词的一部分或单个字符。WordPiece 的词汇表包含 30,522 个可能的标记,尽管其中有不少是未使用的。
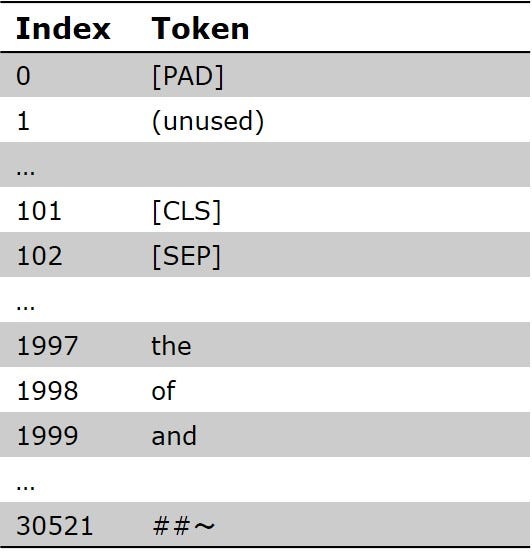
SPLADE 中使用的 WordPiece 分词器词汇表。图片由作者本人提供。
使用 WordPiece 分词器和基于 BERT 的模型时,总是会在开头添加一个特殊的[CLS]标记,结尾添加一个特殊的[SEP]标记[2]。
在 Python 中使用 SPLADE
让我们用 SPLADE 来看看它在实践中是如何工作的吧。首先,我们需要安装torch和transformers:
pip install torch transformers
现在,我们可以加载 SPLADE 模型和分词器。Efficient-SPLADE 有两个单独的模型,一个用于查询,一个用于文档。这两个模型都可以在 Hugging Face 上找到[3]。
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载 EfficientSPLADE 模型和分词器
query_model_id = "naver/efficient-splade-VI-BT-large-query"
doc_model_id = "naver/efficient-splade-VI-BT-large-doc"
query_tokenizer = AutoTokenizer.from_pretrained(query_model_id)
doc_tokenizer = AutoTokenizer.from_pretrained(doc_model_id)
query_model = AutoModelForMaskedLM.from_pretrained(query_model_id).to(device).eval()
doc_model = AutoModelForMaskedLM.from_pretrained(doc_model_id).to(device).eval()
分词器
首先,我们使用分词器将输入文本(str)转换为标记 ID 列表(int):
tokens = doc_tokenizer("The quick brown fox", return_tensors='pt').to(device)
print(tokens['input_ids'])
>> tensor([[ 101, 1996, 4248, 2829, 4419, 102]], device='cuda:0')
现在我们有N=6个标记。我们可以将其解码回文本,以确认它是否成功:
print(doc_tokenizer.decode(tokens['input_ids'][0]))
>> [CLS] the quick brown fox [SEP]
正如你所见,分词器已经自动添加了特殊标记[CLS]和[SEP]。
对数
接下来,我们计算模型输出的对数,也就是对数概率。然后我们可以验证对数的形状。
with torch.no_grad():
logits = doc_model(**tokens).logits[0]
print(logits.shape)
>> torch.Size([6, 30522])
对数的形状是[N x |V|],词汇表大小为|V|=30522。
权重
SPLADEv2 引入了一种最大池化操作,将对数矩阵缩减为大小为 30,522 的向量[4]:
def max_pool(logits: torch.Tensor) -> torch.Tensor:
"""
执行 SPLADEv2 最大池化操作。
返回一个大小为词汇表的张量,其中包含最大池化的值。
"""
return torch.log1p(torch.relu(logits)).amax(dim=0)
splade_vector = max_pool(logits)
print(splade_vector.shape)
>> torch.Size([30522])
我们将对数矩阵中的每个元素进行转换,然后只保留每一列的最大值。
SPLADE 稀疏向量中的大多数条目都是零。我们可以使用一个辅助函数来检查所有非零值的权重。
def print_splade_weights(vec: torch.Tensor, tokenizer):
"""打印非零权重的标记-权重对的排序列表。"""
reverse_vocab = {v: k for k, v in tokenizer.vocab.items()}
nonzero_indices = vec.nonzero().squeeze().tolist()
weights = vec[nonzero_indices].tolist()
# 按权重降序排序
bow = sorted(
[(reverse_vocab[idx], round(score, 2)) for idx, score in zip(nonzero_indices, weights)],
key=lambda x: x[1], reverse=True
)
print("SPLADE 权重:\n", bow)
print_splade_weights(splade_vector, doc_tokenizer)
>> SPLADE 权重:
[('fox', 2.14), ('foxes', 1.93), ('quick', 1.85), ('brown', 1.76), ('types', 0.92), ('species', 0.83), ('browns', 0.82), ...]
下面的条形图展示了输入文本“The quick brown fox”的前 15 个 SPLADE 权重。正如你所见,SPLADE 也有原始文本中未包含的相关词的权重。这是学习扩展的一个例子。
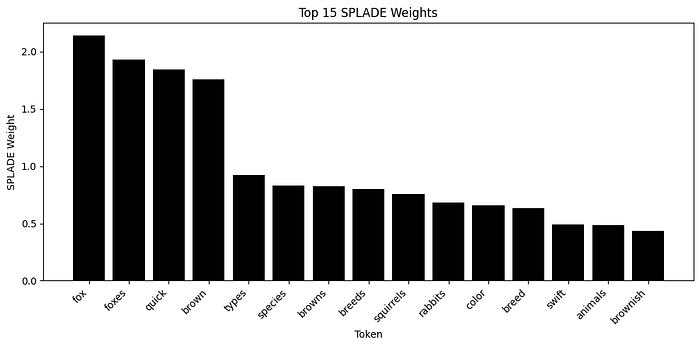
输入文本“The quick brown fox”的 SPLADE-doc 权重(前 15 个,共 55 个非零值)。图片由作者本人提供。
还有学习到的缩减。注意“the”没有被包含在内,因为它是一个如此常见的词,对搜索没有太多价值。
点积
我们可以使用点积来衡量向量之间的相似度。相似的向量会有较高的点积,而不太相似的向量会有较小的值。
def compute_score(query_vec: torch.Tensor, doc_vec: torch.Tensor) -> float:
"""
计算查询和文档张量之间的点积。
结果是一个相似度分数。
"""
return torch.dot(query_vec, doc_vec).item()
把它们全部放在一起
现在,让我们把所有的东西放在一起,使用 SPLADE 对查询和一些示例文档进行排名。
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载 EfficientSPLADE 模型和分词器
query_model_id = "naver/efficient-splade-VI-BT-large-query"
doc_model_id = "naver/efficient-splade-VI-BT-large-doc"
query_tokenizer = AutoTokenizer.from_pretrained(query_model_id)
doc_tokenizer = AutoTokenizer.from_pretrained(doc_model_id)
query_model = AutoModelForMaskedLM.from_pretrained(query_model_id).to(device).eval()
doc_model = AutoModelForMaskedLM.from_pretrained(doc_model_id).to(device).eval()
def max_pool(logits: torch.Tensor) -> torch.Tensor:
"""
执行 SPLADEv2 最大池化操作。
返回一个大小为词汇表的张量,其中包含最大池化的值。
"""
return torch.log1p(torch.relu(logits)).amax(dim=0)
def encode_splade(text: str, model, tokenizer) -> torch.Tensor:
"""使用 SPLADE 将文本编码为稀疏向量表示。"""
tokens = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
logits = model(**tokens).logits[0] # 形状为 [N, 30522] 的张量
return max_pool(logits) # 大小为 30522 的张量
def compute_score(query_vec: torch.Tensor, doc_vec: torch.Tensor) -> float:
"""
计算查询和文档张量之间的点积。
结果是一个相似度分数。
"""
return torch.dot(query_vec, doc_vec).item()
现在我们可以这样使用它:
# 示例查询和文档
query = "What is the capital of France?"
documents = [
"Paris is the capital and largest city of France.",
"The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France.",
"France, officially the French Republic, is a country located primarily in Western Europe.",
"Harry Potter is a series of seven fantasy novels written by British author J. K. Rowling."
]
# 编码查询
query_vec = encode_splade(query, query_model, query_tokenizer)
# 对每个文档进行评分
for i, doc in enumerate(documents):
doc_vec = encode_splade(doc, doc_model, doc_tokenizer) # 编码文档
score = compute_score(query_vec, doc_vec)
print(f"Document {i + 1} Score: {score:.2f}")
这给出了以下排名:
Document 1 Score: 13.93
Document 2 Score: 6.16
Document 3 Score: 9.11
Document 4 Score: 1.12
我们的 Efficient-SPLADE 实现成功地对文档语料库进行了针对查询的排名。
我们可以在 RAG 系统中使用它来检索最相关的文档。由于文档可以提前编码并存储在数据库中,因此我们只需要在线编码查询。
高级 RAG 改进
将使用 SPLADE 的稀疏检索(关键词搜索)与通常在 RAG 系统中使用的密集检索(语义搜索)结合起来是很有意义的。虽然这增加了复杂性和计算工作量,但它也提供了两全其美的优势。
将多个搜索算法合并为一个分数称为混合搜索。混合搜索通常将密集嵌入与 BM25 结合起来,但我们可以用 SPLADE 替代 BM25。
在检索到排名前 K 的文档后,我们可以添加一个重排序模型,以进一步完善结果,采用两阶段过程。重排序器以查询和文档为输入,并计算一个分数,表明查询与文档的匹配程度。
结论
SPLADE 是一个稀疏检索模型,可以在 RAG 系统中用于根据给定查询搜索匹配的文档。
“稀疏”意味着我们有一个固定大小的词汇表来表示我们的查询和文档,其中大多数值为零。SPLADE 的妙处在于,模型不仅学会了包含实际的词,还学会了包含相关的词。SPLADE 通过添加相关词来扩展输入文本,并通过移除不必要的词(如“the”)来缩减它。
SPLADE 可以高效地替代执行语义搜索的密集编码器模型。然而,它也可以与密集编码器模型结合使用,以实现最佳检索结果,使用混合搜索。
试试看吧,让你的 RAG 流程提升到一个新的水平。
参考文献
[1] T. Formal, B. Piwowarski, 和 S. Clinchant: SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking (2021), Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval
[2] J. Devlin, M.-W. Chang, K. Lee, 和 K. Toutanova: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019), Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies
[3] C. Lassance 和 S. Clinchant: An efficiency study for SPLADE models, Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022.
[4] T. Formal, B. Piwowarski, C. Lassance, 和 S. Clinchant: SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval, arXiv:2109.10086 pre-print




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











