







最近开始自学python爬虫,通过观看韦老师的教学视频。刚学会了用一些简单代码爬取一些网页上的文字,本人python代码亲测可用。我们选择爬取豆瓣网上(https://read.douban.com/provider/all)的出版社名字。
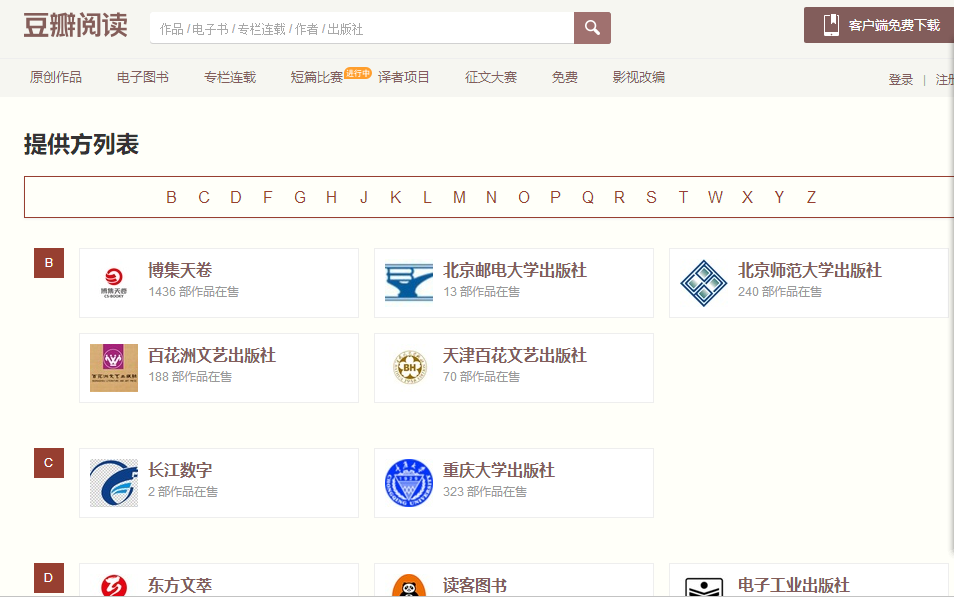
首先导入相应模块。并利用urllib.request.rulopen打开豆瓣网,并把读取到的数据赋值给data。
import urllib.request
import re
data=urllib.request.urlopen("https://read.douban.com/provider/all").read()然后将读取到的数据解码。
data=data.decode("utf-8")打开豆瓣网的源代码找到出版社出现位置。

构建正则表达式。
pat='="name">(.*?)<'
mydata=re.compile(pat).findall(data)file=open( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









