







序
参考:
Flink Timer(定时器)机制与其具体实现_LittleMagics的博客-CSDN博客
4 characteristics of Timers in Apache Flink to keep in mind
Flink程序 Timer实现定时操作_保护我方胖虎的博客-CSDN博客_flink 定时任务
其实大多数 Flink Timer 实现的都是根据 LittleMagics 发表的文章进行加工改造,但是大佬的思路有点跳跃,有些地方个人认为没有表现很清楚,所以摸索着大佬的主线,自己啃了一遍源码写出这篇文章。
全文word显示5K字,CSDN显示9K字,推荐阅读时间1hour(跟随源码)。
最后的图还是放到前面来,跟随图来查询事半功倍:
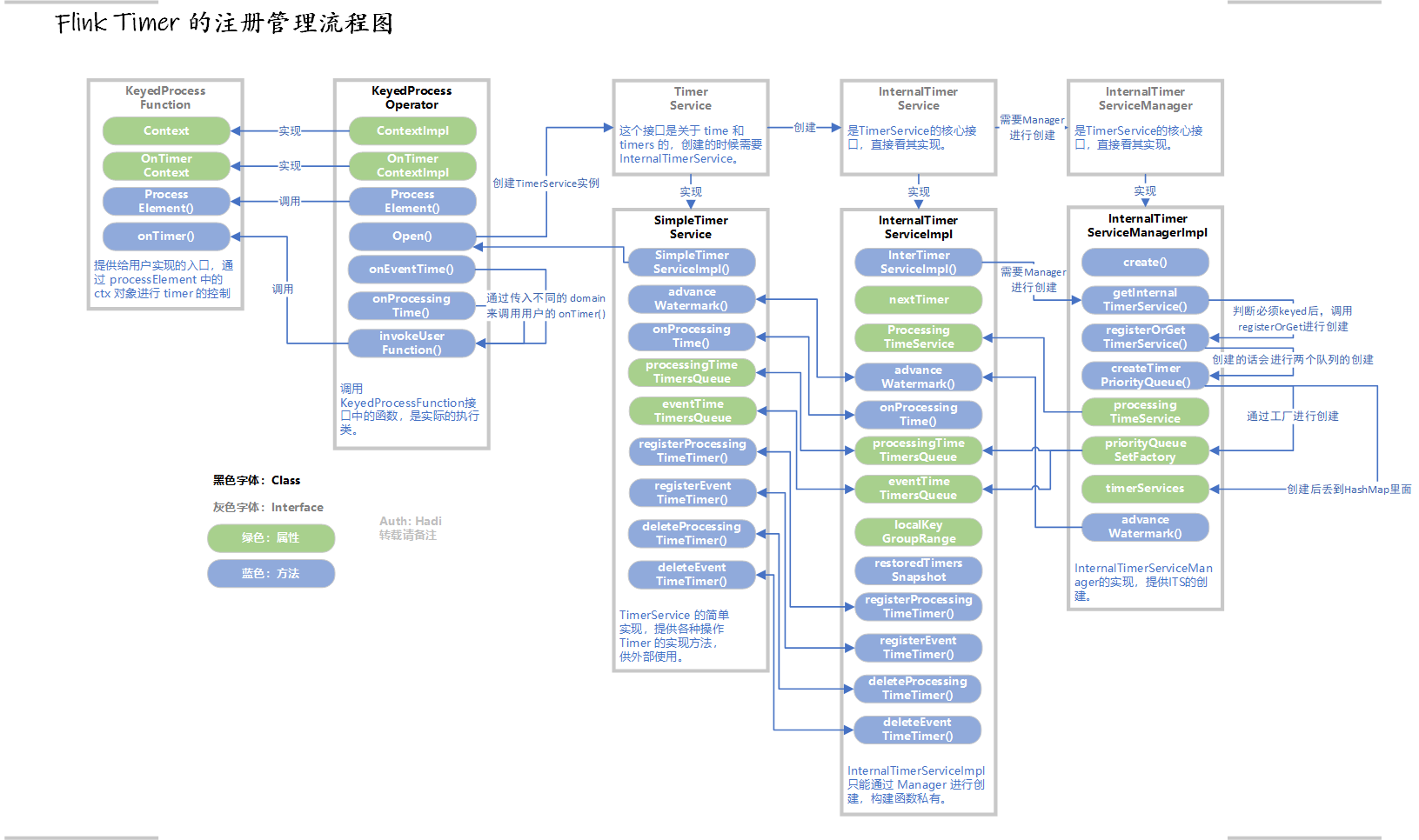
Timer 简介
Timer 定时器 是 Flink Streaming API 提供的用于感知时间变化并且进行处理的机制。
所以对于业务来说,最常用的就是在 KeyedProcessFunction 的时候利用 Timer 机制。我们在其 processElement() 方法中注册 Timer,然后覆写 onTimer() 方法作为 Timer 触发时的回调逻辑。
根据时间特征的不同,我们分为以下两种:
处理时间
调用 Context.timerService().registerProcessingTimeTimer() 注册;
onTimer() 在系统时间达到 Timer 设定的时间戳时触发。
事件时间
调用 Context.timerService().registerEventTimeTimer() 注册;
onTimer() 在 Watermark 达到或者超过 Timer 设定的时间戳时触发。
KeyedProcessFunction 最简单的 Timer 触发
KeyedProcessFunction
一般来说,我们显式的调用 Timer 比较常用的就是 KeyedProcessFunction 低阶函数进行数据处理。

我们可以在 processElement 方法中,执行我们需要的数据逻辑处理和 Timer 的开启。
onTimer 方法则是定时器触发执行的具体方法。
实例
比如我们可以设置一种来一条数据就设置一个 Timer,并且过一段时间后触发的代码:

我们将键存储在 State 中,Timer 进行调用。所以就可以使用 processElement() 方法中注册 Timer。
然后使用 DataGeneratorSource 进行数据创建,调用使用:

但一般在生产环境中并不会这样使用,单个数据的 Timer 大概率会导致 Timer 过多,而性能无法支撑。
Window Trigger 触发
除了 KeyedProcessFunction 之外, Timer 还可以在窗口机制中有重要地位。提起窗口自然就能想到 Trigger,比如 ProcessingTimeTrigger 的部分代码(这个是事件时间特征下的默认触发器)。
org.apache.flink.streaming.api.windowing.triggers.ProcessingTimeTrigger

可以看到内部有三个方法: onElement、onEventTime、onProcessingTime。
在 ProcessingTime 中就关心 onProcessingTime 和 onEventTime,而 onElement 是基于事件时间的,所以并不会在 ProcessingTrigger 中进行调用。
当 Watermark 还没有到达窗口的右边沿的时候,就注册以窗口右边沿为时间戳的 Timer。当 Timer 到期后触发 onProcessingTime() 方法,进而触发该窗口相关联的 Trigger。
Window Trigger 例子

可以看到我将 .trigger() 给注释了,那么现在这里面还有 trigger 吗?
当然是有的,当我们进行 window 操作的时候,其实已经引入了一个 Trigger,根据是 ProcessingTimeWindow 还是 EventTimeWindow 给不同的 Trigger 实现。
所以如果我们进行 .trigger() 操作也只是覆盖原有的。
那这个就必须说 Timer 到底是怎么实现的了。
Timer
所以,Timer 我们可以理解为是一个时间触发器,当数据来了后判断是否需要传递到下游,是否需要进行各种数据清除操作。
而 Flink Timer 有以下4大特点:
- 注册在 KeyedStream 中。
- 重复注册的 Timer 会被清除。
- Timer 也会被 Flink 保存在状态中。
- Timer 是可以被删除的。
根据以上四点,我们需要去剖析一下到底都是怎么实现的,或者到底怎么保存的。
TimerService & InternalTimerService
在之前的不开窗的方式中,我们直接 keyby 后调用 keyedProcessFunction 来实现了注册触发 Timer,并且在里面我们也自己定义了注册 Timer 的方法,那我们就从这里下手看看是怎么工作的。
org.apache.flink.streaming.api.functions.KeyedProcessFunction

可以看到关于我们 onTimer 调用的时候,有 TimerService 进行管理,然后调用 onTimer 方法。
看看又是谁在调用 onTimer 方法:

org.apache.flink.streaming.api.operators.KeyedProcessOperator
可以看到是 KeyedProcessOperator 进行方法的调用,或者说负责实际执行 KeyedProcessFunction 的算子是 KeyedProcessOperator,那么我们必须重点观察 KeyedProcessOperator 的使用了。
KeyedProcessOperator


通过上面的代码可以看到:
KeyedProcessOperator 下面有两个类 ContextImpl & OnTimerContextImpl ,均是实现 keyProcessFunction 的 Context 和 OnTimerContext。
然后就是我们常见的三个方法: open() & onEventTime() & onProcessingTime()。
还有一些变量,我们依次看看有哪些内容。
KeyedProcessOperator#onEventTime & onPeocessingTime
这两个方法实现都是实现 Triggerable 接口的,并且调用 invokeUserFunction 来实现指向用户函数。

其本质还是调用了 userFunction 的 onTimer (这个其实就是 KeyedProcessFunction#onTimer,最终实现为用户传入的 onTimer 方法)。
KeyedProcessOperator#open

还记得我们在 KeyedProcessFunction 中使用 context 获取 TimerService 对 Timer 进行各种操作,所以这里面我们最关心的就是 context 和 onTimerContext 是怎么实现的。
context 与 onTimerContext 一致,使用 userFunction 和 timerService 进行创建,而 timerService 是由 SimpleTimerService 实现的。
SimpleTimerService 的实现过于简单,不放代码了,里面包含的就是对 Timer 的管控,同时提供 Watermark 和 ProcessingTime 的获取方式。
在构造 TimerService 的时候必须传入一个 InternalTimerService,是通过 org.apache.flink.streaming.api.operators.AbstractStreamOperator#getInternalTimerService() 来构建的:

通过注释我们可以得知:
- 这个 InternalTimerService 可以查询 EventTime/ProcessingTime,设置 Timer。
- 并且强调了同一个 Operator 可以有多个 timerService。
- 并且通过传入的 stringKey 来标识,同一个 stringKey 会得到相同的实例。
- 并且 TimerService 记录的是一个时间戳,这个时间戳会被记录为激活的键。
需要强调的就是:
InternalTimerService 的四要素是: 名称、命名空间类型N(及其序列化器)、键类型K(及其序列化器),还有 Triggerable 的接口实现。
Triggerable 提供了 onEventTime 和 onProcessingTime。
比如 KeyedProcessOperator#open 中创建 InternalTimerService 的时候传入的参数为:
InternalTimerService<VoidNamespace> internalTimerService =
getInternalTimerService("user-timers", VoidNamespaceSerializer.INSTANCE, this);

对应的就是:
- 名称:"user_timers"。
- 命令空间:空 VoidNamespaceSerializer.INSTANCE。 new VoidNamespaceSerializer();
- Triggerable:本身 this,KeyedProcessOperator 也是实现了 Triggerable 接口的。
还需要提一下,InternalTimerService 本身只是一个接口,最终还是需要落地实现。根据我们目标就是看看 Timer 到底怎么创建和保存,那就继续深挖下去。
InternalTimeServiceManager
上面我们 keyProcessFunction 与 KeyProcessOperator 的对应关联关系,然后在其 open 方法中创建的 timerService的过程。但是仍旧没有看到对应的调用和保存。
任何东西都应该有什么来触发调用与保存的
在我们创建 InternalTimerService 的时候调用的是 AbstractStreamOperator#getInternalTimerService 方法。再看看这个流程:

先判断了 TimeServiceManager 是否存在,然后使用 TimeServiceManager#getInternalTimerService 来创建。
所以很明显, InternalTimerServiceManager 就是来管理各个 InternalTimerService 的:

InternalTimerServiceManager 是一个接口,所以我们直接看看它的实现类:
包含两个: BatchExecutionInternalTimeServiceManager & InternalTimeServiceManagerImpl

我们直接看看 InternalTimerServiceManagerImpl 这个实现,因为上面的实现很明显就是批次的使用。
InternalTimeServiceManagerImpl
直接结构,然后逐个排查比较重要的方法:

InternalTimeServiceManagerImpl#create

创建的入口必须从 create 进入。
InternalTimeServiceManagerImpl#getInternalTimerService

保证进行 InternalTimerService 调用的必须是 keySerializer。
然后根据 keySerializer 和 namespaceSerializer 去调用 registerOrGetTimerService 方法。
InternalTimeServiceManagerImpl#registerOrGetTimerService

可以看到,先从 timerServices 根据命名空间 name 去获取,如果获取不到那么就会创建一个,并且将其放入 timerServices 中。
创建的时候会进行两个 Queue 的创建,一个用于 PROCESSING_TIMER,另一个用于 EVENT_TIMER。
创建的队列使用的 createTimerPriorityQueue,本质是创建 Manager 是传入的 priorityQueueSetFactory。
org.apache.flink.streaming.api.operators.InternalTimeServiceManagerImpl#timerServices

本质上就是一个 HashMap 进行创建的。
总结
- 我们可以看到 InternalTimerService 是由 InternalTimerServiceManager 创建的,最终其实现类是存储在一个 HashMap 中。
- 初始化 InternalTimerServiceImpl 时,会创建两个包含 TimerHeapInternalTimer 的优先队列,分别用于维护事件时间和处理时间的 Timer。
TimerHeapInternalTimer
org.apache.flink.streaming.api.operators.TimerHeapInternalTimer
在进行 InternalTimerService 创建的时候,创建了两个优先队列,使用的是以下的方法:

在上面也解释了,我们的创建的工厂是创建 InternalTimerServiceManager 的时候传入的,但我们看泛型类型的时候看到,这里有一个 TimerHeapInternalTimer<K, N>。那这个是什么作用呢?
看看代码结构:


根据备注所说,其实现了 InternalTimer,并且可以使用 HeapPriorityQueueSet。
HeapPriorityQueueSet 后面一点我们会讲到。
HeapPriorityQueueElement 说明 TimerHeapInternalTimer 肯定是可以装填到 HeapPriorityQueueSet 中的。
然后被装填到最开始 InternalTimerServiceImpl 中的两个队列中。
而 InternalTimer 则是 Timer 的统一接口了。
所以这个类就是装填的 Timer 实现类,根据成员变量可以看到一共就是4个:
- key
- namespace
- timestamp
- timerHeapIndex
key & namespace
所以明显 Timer 的 scope 有两个: key & namespace。我们之前可以看到 我们创建的 namespace 是 VoidNamespaceSerializer.INSTANCE。而大多数情况下也是如此。所以我们可以简单的认为 Timer 是以 key 为级别来注册的。所以要很清楚的认知 key 的量级,来帮助我们控制 Timer 的数据量。
timestamp
就是到期的时间戳
timerHeapIndex
是这个 Timer 在优先队列中的下标,一般来说时使用二叉堆的逻辑存储在数组中的,所以让 Timer 持有对应的下标可以很快的从队列中进行删除。
comparePriorityTo()
该方法则用于确定 Timer 的优先级,Timer 很显然的优先级顺序是 timestamp 来排序的最小堆。
HeapPriorityQueueSet
org.apache.flink.runtime.state.heap.HeapPriorityQueueSet

这个名字就很有深度,Heap/Priority/Queue/Set。基础来讲就是存储在堆中的 Set,但是又有优先队列的属性,肯定是可以通过 key 去重的。所以其实就是 优先队列 + 去重的 Set。
KeyGroup & KeyGroupRange。
KeyGroup 是 Flink 内部 KeyedState 的原子单位,是一些 key 的组合。一个 Flink App 的 KeyGroup 数量与最大并行度相同,将Key 分配到 KeyGroup 的操作就是最经典的 hashCode 并取模。而 KeyGroupRange 则是一些连续的 KeyGroup 范围,每个 Flink subTask 都只包含一个 KeyGroupRange。也就是说,KeyGroupRange 可以看做当前 subTask 在本地维护的所有的 key 范围。

所以,上述代码中的 HashMap<T, T>[] 数组就是在 KeyGroup 级别对 key 进行去重的容器,数组中的每个元素对应一个 KeyGroup。当我们需要插入一个 Timer,那么它的流程为:
- 从 Timer 中取出 key,查看该 key 属于哪一个 KeyGroup。
- 计算出该 KeyGroup 在整个 KeyGroupRange 中的偏移量,按照偏移量定位到 HashMap<T, T>[] 数组的下标。
- 根据 putIfAbsent() 方法,只有当对应的 HashMap 不存在该 Timer 的 Key 时,才将 Timer 插入最小堆中。

create
创建 HeapPriorityQueueSet 的方法就是走的构造函数,而调用构造函数的地方只有其工厂类 HeapPriorityQueueSetFactory。
org.apache.flink.runtime.state.heap.HeapPriorityQueueSetFactory#create
这个类我们一开始看见过,其实就是 InternalTimeServiceManagerImpl#createTimerPriorityQueue 方法,创建了一个,在生成 InternalTimerService的时候一共创建了两个。
InternalTimeServiceImpl 再谈
回头过来再看看这个 InternalTimeServiceImpl 类,我们了解了其怎么被 InternalTimeServiceManagerImpl 创建管理的,也知道其内部中的两个优先队列是怎么创建的。现在还差具体了解到底怎么创建 Timer,怎么触发调用,怎么删除或者保存的了。
看看结构:

InternalTimeServiceImpl#registerProcessingTimeTimer 注册一个 ProcessingTimeTimer

我们知道了所有的注册操作其实都是保存在 HeapPriorityQueueSet 中,add 方法会返回是否添加成功(原来并没有)。而添加使用的是我们之前讲的 TimerHeapInternalTime,传参为 time 时间戳、keyContext.getCurrentKey() 键、namespace 命名空间。
添加成功后会进行一些额外操作:
如果添加的 time 是 HeapPriorityQueueSet 中最小的,那么意味着此时的 time 比堆中的要早,就会重新进行 timer 的调度,因为处理时间是永远线性增长的。
重新注册一次
InternalTimeServiceImpl#registerEventTimeTimer & delete 其他注册删除操作。

InternalTimeServiceImpl#onProcessingTime 处理时间触发
在这个 InternalTimeSrviceImpl 中有个变量 nextTimer,这个是注册下一个时间调用的,当满足时间后进行调用。

而当 onProcessingTime() 方法被触发的时候,会按照顺序将获取到比时间戳 time 小的所有 Timer 挨个执行 Triggerable.onProcessingTime()。根据实现类的不同,具体执行的就是用户定义的 onTimer() 逻辑了。
ProcessingTimeService
还记得这个吧,我们在 registerProcessingTimeTimer() 的时候就是让 nextTimer = processingTimeService; 说明在底层调用上,还是这个类进行了最底层的调用方法。查看它的实现类 ProcessingTimeService 可以看到几个实现类,其中里面的 SystemProcessingTimeService 才是我们需要查看的具体实现类。
NeverFireProcessingTimeService 永远不会发送数据。

最后来到 SystemProcessingTimeService,这个使用调度线程池实现回调的:

将任务注册到了 timerService 中,而这个 timerService 是一个 ScheduledThreadPoolExecutor 线程池。
传入的参数是 new ScheduledTask(), delay, 时间单位。
InternalTimeServiceImpl#advanceWatermark 事件时间触发

与 onProcessingTime 处理时间处理逻辑几乎一致,也是从小到大一直获取到传入的 time,然后挨个执行。
只是这个需要使用到 Watermark 相关的指标进行,然后回调的是 onEventTime() 方法。
InternalTimeServiceManagerImpl
那么是谁在进行 advanceWatermark 的触发呢?
org.apache.flink.streaming.api.operators.InternalTimeServiceManagerImpl#advanceWatermark

可以在 InternalTimeServiceManagerImpl 中看到,Event 类是 ManagerImpl 来进行调用的。
通过不断的提升 currentWatermark 来进行 eventTimeTimersQueue 的判断和执行。
意思是如果我们有其他并非是 event 的 Timer,也会被调用,但由于 Queue 中为 null 所以无法被调用。
这个也是由统一的 watermark 管理来调用的,最终可以追溯到org.apache.flink.streaming.api.operators.AbstractStreamOperator#processWatermark 中:

总结
到这里我们差不多讲完了整个 Timer 是怎么提供给开发者、怎么回调、怎么进行构建、保存的了。但,貌似还不够,还缺少了些什么,感觉什么都看了,又什么都没看。
所以我们开始画图吧: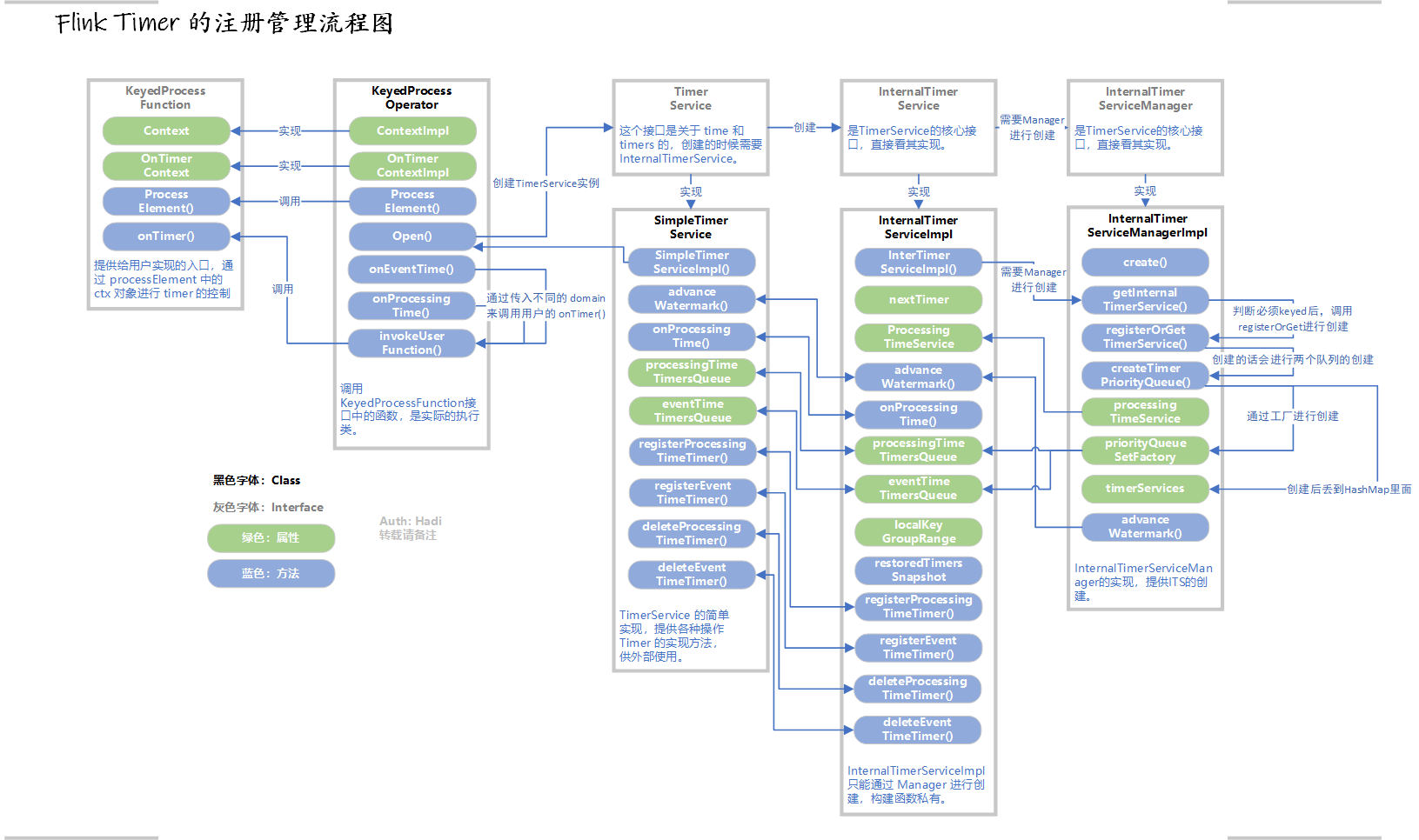
好的 画完了。















 8244
8244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









