









序
参考: Flink 中文社区
预计阅读时间:15min,共5700字。
Join
Join 语义以及实现现在有很多的成熟方案,然而近年来,实时流之间的Join 却是刚刚起步。
在 Join 之中,最重要的就是我们一般实现 join 需要依赖于缓存整个数据集,但是在实时数据中,他是一个无限的数据流,内存压力和计算效率在长时间运行时,都会带来不可避免的问题。
那么我们先讲讲对于 Join的基础知识。
Batch SQL Join
传统的离线Batch SQL 有三种基础的实现方式,分别是Nested-loop Join、Sort-Merge Join & Hash Join。
Nested-loop Join
直接将两个数据集加载到内存(Spark 中的 broadcaset join 参考),在内存中遍历的方式来逐个比较两个数据集内的元素是否符合 Join 条件。虽然器的时间效率以及空间效率比较低,但是可以比较灵活的适用于各个方向,因此他的变体 BNL 常被传统数据库作为 Join 的默认基础选项。
Sort-Merge Join
将分为两个 Sort 和 Merge 两个阶段。首先将两个数据集分别进行排序,然后对两个有序的数据集分别进行遍历和匹配(类似于归并)。值得注意的是,Sort-Merge 只适用于 Equi-Join(Join条件都使用等于作为比较算子)。Sort-Merge 要求对两个数据集进行排序,成本很高,通常作为样本有序数据集的情况下的优化方案。
Hash Join
也是分为两个阶段:将第一个数据集转为 Hash Table 后遍历第二个数据集并与 Hash Table内的元素进行匹配。
第一阶段和第一个数据集称为 build 阶段和 build table,第二个阶段和第二个数据集称为:probe 和 probe table。Hash Join 效率较高,但对空间要求较大,通常是作为Join其中一个表为合适放入内存的小表的情况下的优化方案,他也只能适用于 Equi-Join。
Streaming SQL Join
相对于离线的Join,实时Streaming SQL(面向无界数据集的SQL)无法缓存所有数据,因此Sort-Merge Join 要求的对数据集的排序基本上来说是无法做到的,而 Nested-loop Join 和 Hash Join 经过一定的改良则可以满足实时 SQL 的要求。
我们通过例子来看基本的 Nested Join 在实时情况下的基础实现。

TableA 与 TableB 之间的关联得到 Result,是因为我们需要保留 TableA 和 TableB 两个输入表的所有内容。此时如果 TableA 来了新值 7,那么 Result 就会追加 7 这个值,是因为匹配到了 TableB 中有7。
但由于 TableA 和 TableB 在流的情况下是无止境的增长的,导致很不合理的内存以及磁盘的占用(存储数据才能去 lookup),而且单个元素的匹配效率也会越来越低,相同的问题在 Hash Join 中也一样存在。
我们知道,一般来说新的数据的匹配率比老的多,某些热点 key 比其他的匹配率也多,那能不能像 Redis 或者其他什么数据库一样,来一个缓存剔除策略,将不必要的历史数据及时清理。
所以在 Flink 中关键是实现了缓存剔除策略,这也是 Flink SQL 提供的三种 Join 的主要区别。
Flink SQL 中的 Join
Regular Join
Regular Join是最为基础的没有缓存剔除策略的 Join。 其的两张表的输入和更新操作都是对互相的全局可见,影响之后的 Join 结果。怎么理解呢,就是在如下 Join 查询里, Orders 表的新纪录会对 Product 表所有历史记录以及未来的记录进行匹配,输出结果。
SELECT * FROM OrdersINNER JOIN ProductON Orders.productId = Product.id;
Regular Join 允许对输入表进行各种更新插入删除操作,其表现结果都会被输出。
"啊,发送一条删除了的数据,怎么输出?"
"在Flink SQL 中的 Sink 类型多种多样,有些就支持这样的删除操作。"
上面也提到了,如果历史数据不会被清理,但是不过一会存储空间就会被无限流式数据给干满,一般只能作为有界数据流的Join。或者说基本不能于生产使用。
Time-Windowed Join
Time-Windowed Join 是利用时间窗口给两个输入表进行一个 Join 的时间界限,超出时间范围的数据对整体来说没有影响,可以被清理掉。
所以这个功能依赖于两个输入表的数据有其时间定义的语义。
(对,又是 Flink 的特性:数据时间语义 Processing Time/ Event Time)
根据不同的时间定义,Flink 来自己清理数据,PT 根据系统时间自动划分 Join 的时间窗口并定时清理数据;如果是 ET,则根据ET 来进行时间窗口划分,并且根据 Watermark 来清理数据。(有什么区别嘛,其实没啥区别,思考在 PT 下的 Watermark 是什么?)
一般生产环境下,我们都是使用 Event Time 进行时间之间的 Join,比如下表就是将 Orders 订单表和 Shipments 运输单表依据订单时间和运输时间进行 Join 的示例:
SELECT
*
FROM
Orders o
,Shipments s
WHERE
o.id = s.orderId AND
s.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
;
写的格式咱不说,单看 WHERE 条件中的时间语义字段之间的限制:
s.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
既然有时间的要求,那么我们可以根据时间的语义来决定倒地保留哪部分数据。
Orders表的数据清除
对于 Orders 表来说,保存的数据是会对结果集产生一定影响我们才会保留,所以考虑因素应该是当 Shipments 表来了一条数据,会跟哪些 Orders 进行关联:
+ INTERVAL '4' HOUR 的意思是 Shipments 表可以跟 Orders 前4个小时的数据进行关联。
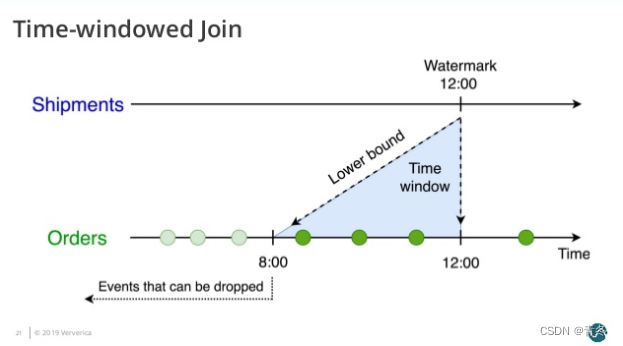
所以意味着 我们需要保留 Orders 表4个小时到现在的数据,那么等于 Orders 表获得了一个上=下界,超过下届的数据将会被删除。
Shipments表的数据清除
对于 Shipments 表来说,相同的是 Orders表来了一条数据会与哪些 Shipments 中的数据进行关联:
+ INTERVAL '4' HOUR 的意思是 Orders 表可以跟 Shipments 后4个小时的数据进行关联。

这意味着 我们需要保留 Shipments 表 现在到4个小时之后的数据,那么等于 Shipments 表获得了一个下界,超过下界的数据将会被删除。
注意是根据时间下界来清除数据。
总结
在整个逻辑上,我们确定 一个 interval join 的数据保存计划,其实很简单。但是在SQL语法定义时间仍然是一个难点。Flink 实现的 Event Time、Processing Time、Watermark 这些已经被大众所接受,但是在SQL领域对时间数据类型的支持仍旧很弱。(Flink 1.10开始已经可以实现,通过拓展 SQL 方言完成,FLIP-66[7])
Tempoarl Table Join
虽然上面我们的 Timed-Windowed Join 解决了很多资源的问题,但也极大的限制了我们 Join 时必须两张表都有时间下界,并且超过之后不可方案。这对于我们很多 Join 维表来说是不适用的,因为很多维表并没有下界,针对这个问题,我们可以使用 Temporal Table Join。
Tempoarl Table Join 类似于 Hash Join,将输入分为 Build Table 和 Probe Table。前者一般是维度表的 ChangeLog,后者一般是业务数据流,所以后者的数据量应该会远远地大于前者。
在 Tempoarl Table Join 中,Build Table 是一个基于 append-only 数据流并且带时间版本的视图(只能增加,不能 update 或者delete 操作),所以称之为 Tempoarl Table。其要求定义一个主键和用于版本变化的字段(通常就是 Event Time 时间字段),以反映记录在不同时间的内容。
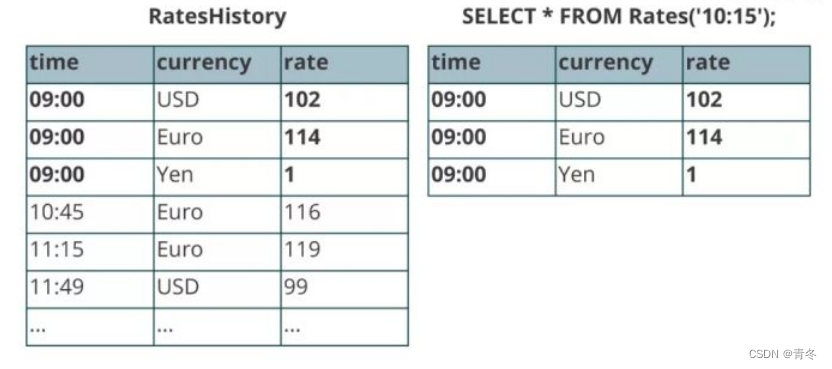
比如典型的一个例子就是对电商订单进行汇率转换,每天有很多人的转换订单 Orders 表,也有一个汇率维度 RatesHistory 表。两者进行 join操作,每当 RatesHistory 进行变化的时候都会有一条更新操作记录。两张表的时间节点内容如下:

将 RatesHistory 表注册成为一个 Temporal Table ,并设置主键为 Currency,版本字段为 time。

这样,对 RatesHistory 表进行查询,会基于 time 字段来计算符合时间版本的汇率转换内容:
在这样的情况下,我们可以将业务逻辑用一下的查询来表达:
SELECT
o.amount * r.rate
FROM
Orders o,
LATERAL Table(Rates(o.time)) r
WHERE
o.currency = r.currency
;
值得注意的是,前两种(Regular Join 和 Time-Windowed Join)中的两个表是平等的,任意一个表的变化都会与另一个表的历史记录进行匹配。但是在 Temporal Table Join 中, Temoparal Table 的更新对另一表该时间节点以前的记录是不可见的。这意味着我们只需要保存 Build Side (维度表)的记录,直到 Watermark 超过记录版本的字段,因为 Probe Side 的输入理论上不会再有早于 Watermark 的记录(早于 Watermark 的记录被丢弃),这些版本的数据可以被安全的清理掉。
总结
SQL 这种释义的表达式语言,不同于操作语言,可以很多实现方式,这很考验方言特性。
在离线和实时的过程中,SQL也有不同的变化和实现方式。
关联表
上面讲述了 SQL 的整个流程,SQL 会被解析为 DataStream 来进行计算,我们也可以直接使用 DataStream API 来进行维表的关联操作。这章节将会主要讲述 DataStream 实现 Join 维表的常见方式。
衡量指标
关联维度表有三个基础的方式:
- 实时数据查找关联 Per-Record Reference Data Lookup
- 预加载为表关联 Per-Loading of Reference Data
- 维表变更日志关联 Rederence Data Change Stream
而根据实现上的优化可以衍生出多种关联方式,且这些优化还可以灵活组合,产生不同的效果。对于不同的关联方式,有以下7个关键指标来衡量。
- 实现是否简单
- 吞吐量
- 维表数据的实时性
- 数据库的负载
- 内存资源占用
- 可扩展性
- 结果确定性
实时数据库查找关联 Per-Record Reference Data Lookup
实时数据库查找关联是在 DataSteam API 用户函数中直接访问数据库来进行关联的方式,这种方式通常开发量很小,但会对查询数据库带来很大的压力,而且关联是基于 Processing Time 的,如果数据有延迟或者重放,会破坏数据的一致性。
同步数据库查找关联
同步实时数据库查找关联是最为简单的关联方式,只需要在 RichMap 或者 RichFlatMap 函数中访问数据库,处理好关联逻辑后,将结果数据输出即可。

这种方式主要优点在于实现简单、不需要额外内存且维表的更新延迟低,但有明显的缺点:
- 每条数据都需要进行一次 look up 操作,大多数数据库无法承受。
- 访问数据库的时候是同步调用,导致 subtask 大部分时间浪费在调用数据库上。
- 关联基于 Processing Time,结果可能有偏差。
- 瓶颈在数据库,但数据库一般扩容操作难度很大。
线上环境不推荐
异步数据库查找关联
异步数据库查找关联是通过 AsyncIO[2] 来访问外部数据库方式,利用数据库提供的异步客户端, AsyncIO 可以并发地处理多个请求,很大承诺堵上减少了对 Subtask 线程的阻塞。
因为数据库的请求响应时长是不确定的,可能导致后进的数据先出,所以 AsyncIO 分为有序和无序两种模式。

比起同步数据库查找关联,异步数据库查找关联稍微复杂一点,但是大部分的逻辑都是由 Flink AsyncIO API 进行封装,因此总体还是比较简单。但是对于有序输出来说,需要缓存,而且会被写入到 checkpoint 中,因此会耗费一些内存资源。
但仍旧存在以下的缺点:
- 每条数据都需要进行一次 look up 操作,大多数数据库无法承受。
- 关联基于 Processing Time,结果可能有偏差。
- 瓶颈在数据库,但数据库一般扩容操作难度很大。
带缓存的数据库查找关联
为了解决上述两种关联方式,对数据库会造成太大压力的问题,可以引入一层缓存来减少直接对数据库的查询请求。缓存一般并不需要 checkpoint 持久化,因此简单的用一个 WeakHashMap 或者 Guava Cache 就可以实现。

虽然在冷启动的时候,仍旧会给数据库造成一定的压力(雪崩),但是数据库得到一定程度的缓解。但是数据的更新并不能快速反应到关联操作上,这是一大欠缺(虽然可以设置一定策略,但也会削弱这个方法的优势)。
总结
对于 Lookup 的场景来说,都是强依赖于数据库查询的,对数据库的压力都不小,而且会造成我们更新数据的延迟,有一定数据错误的情况。对我们来说,在生产环境下,特殊的场景下才可使用。
预加载维表关联 Per-Loading of Reference Data
相比实时数据每一条都会访问一次数据库,预加载维表关联是在作业启动的时候就将维表读到内存中,从而在后续的运行期间,每条数据都会和内存汇总的维表进行关联,而不会直接对数据库进行访问。
与带缓存的实时数据库查询关联相比,区别是后者如果不命中缓存还可以 fallback 到数据库进行访问,而前者如果不命中则会关联不到数据。
启动预加载维表
启动预加载维表是最为简单的一种方式,即在作业初始化的时候,比如用户函数的 open() 方法,直接将数据库的维表拷贝到内存中。维表并不需要使用 State 来进行保存,因为 open() 方法总是在启动、重启、错误重启的时候被正确调用,从而得到最新的维表数据。
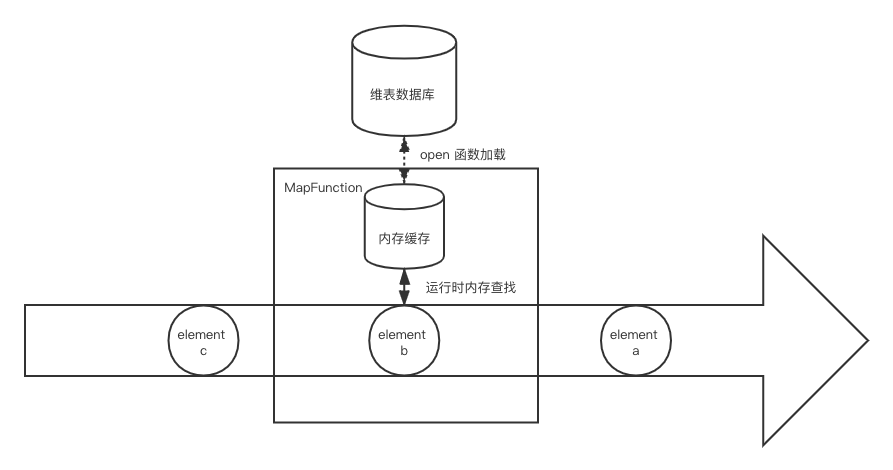
启动预加载维表对数据库的压力持续时间很短,但是要拷贝整个维表的压力还是很大的。运行期间维表数据不能进行更新,一般用于维表较小,且几乎不更新维表的场景;如果要重新加载维表,则需要重启作业。
启动预加载分区维表
对于维表比较大的情况,可以启动预加载维表基础之上增加分区功能。简单来说就是将数据流按照字段进行分区,然后每个 SubTask 只需要加载对应分区范围内的维表数据。这种分区方式实战按照业务数据定制化分区策略,然后调用 DataStream#partitionCustom 进行。比如按照 Hive p_date 进行区间划分。在 open() 方法中,再根据 subtask 的 id 和总的并行度来计算应该加载的维表数据范围:

通过这种分区方式,维表的大小上线理论上可以线性拓展,解决了维表大小受限于单个 TaskManager 内存的问题,但是也给设计和维护分区带来复杂性。
启动预加载维表并定时刷新
在上述的方式中,维表加载到了我们对应的 SubTask 中,但是并没有具备维度表定时更新的功能,我们可以引入定时刷新机制的办法来缓解这个问题。可以使用 Flink ProcessFunction 提供的 Timer 或者直接在 open() 初始化一个线程(池)来定期做这件事。不过 Timer 要求 KeyedStream,而上述的 DataStream#partition Custom 并不会返回一个 KeyedStream,因此两者并不兼容。而是用额外线程池定时获取的办法,则不受这个限制。

维表变更日志关联 Rederence Data Change Stream
维表变更日志以 changelog 数据流的方式进入 Flink 内部,从而将维表关联转变为两个数据流的 Join 操作。这里的 changelog 类似于 Mysql 的 binlog,通常需要维表数据端以 push 的方式写到 Kafka消息队列中。 Changelog 数据流被称为 build 数据流,而等待关联的数据流称为 probe 数据流。
维表变更日志的好处在于可以获取某个 key 的数据变化时间,从而使得我们能够在关联中使用 Event /Processing Time。
Processing Time 维表变更日志关联
Processing Time 保留 维表最后一个版本的数据,不保留主表数据。
如果基于 Processing Time 做关联,我们可以利用 keyby 将两个数据流中关联字段值相同的数据划分到 KeyedCoProcessFunction 的同一个分区,然后使用 ValueSate 或者 MapState 将维表数据保存下来。在普通数据流的一条记录进到函数时,到 State 中查找有无符合条件的 join 对象,然后根据规则进行输出。
这里需要注意的是 State 的大小要尽量控制好:
保证 key 最新的维度数据值。
给 state 设置好 TTL,让 Flink 可以自动清理。

当基于 Processing Time 的维表日志关联的操作时,需要两个流数据的延迟都很低,不然可能出现错位关联的情况。 Flink 内部需要存储这个维度表,可以利用 RocksDB StateBackend 将大部分的维表数据存储在磁盘中(类似于 HBase)。
Event Time 维表数据变更日志关联
Event Time 保留 维表多个版本的数据,不保留主表数据。
与 Processing Time 的十分相似,不同之处在于我们将维表 changelog 的多个时间版本都记录下来,然后将每一条记录都保存起来,然后进行关联的时候选择对应的维表版本进行关联,而不是总是用最新版本,这样准确性会大大提高。不过因为目前 State 并没有提供 Event Time 的 TTL,因此我们需要设计和实现 State 的清理策略,比如直接设置一个 Event Time Timer,或者对单个 key 只保留最近的 N 个版本。

基于 Event Time 的维表变更日志关联时,要求 Build 数据流的延迟很高,否则可能一条数据到达的时候都关联不到,或者对应 repo 关联到一个过期的维表数据,造成数据错误。
Temporal Table Join
Temporal Table Join 是 Flink SQL/Table API 的原生支持,对两个表的数据都进行了缓存处理。
可以容忍任意数据流的延迟,准确性更好。
整体思路是使用一个 CoProcessFunction,将 build 数据流以时间版本为 key 保留在 MapState 中(与基于 Event Time 的维表变更日志关联相同),再将 probe 数据流和输出结果也用 State 缓存起来(同样需要 Event Time 进行标识),一直等到 Watermark 超过,才会将数据进行舍弃掉。
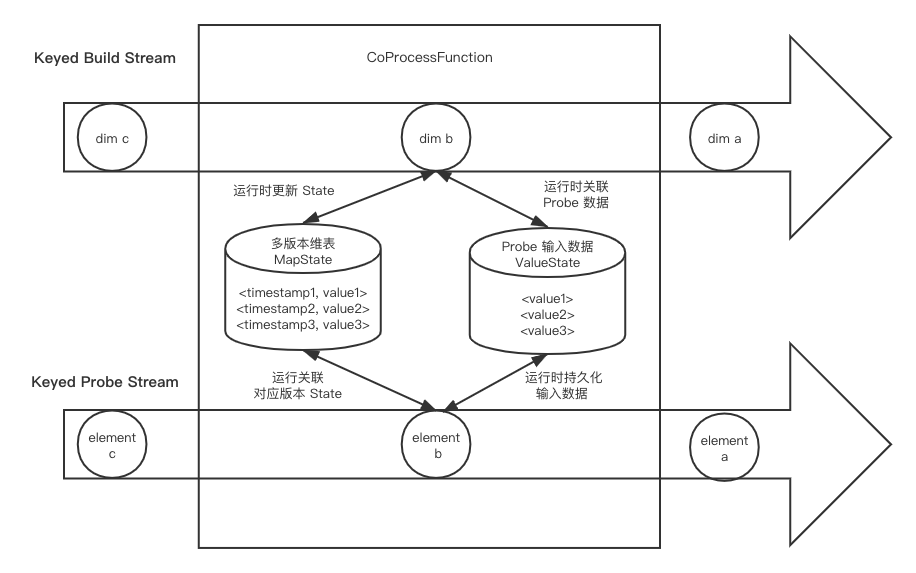
Temporal Table Join 的好处在于对两边数据流的延迟容忍度很大,但会带来一定的输出延迟和更多的内存空间的使用。这个对两个流数据的时延要求也很高,不然 probe 流数据会被缓存的很多,同时给 Source 设置一个比较短 idle timeout。
一般这种场景用于关键性业务。
总结
上面写的很复杂,但是其实主要思路只有4种:
- 全量预加载+定时刷新:适用于规模较小的缓慢变化维度(SCD),思路最简单,可以参见这个示例。
- 实时查询+缓存刷新:适用于规模较大的缓慢变化维度(SCD),在数仓维度建模过程中,这种维度最为常见,本文接下来会详细叙述其实现方式。
- 纯实时查询:适用于快速变化维度(RCD),或者对关联时效性要求极高的场合,需特别注意频繁请求对外部存储的压力。
- 流式化维度:比较特殊且灵活,将维度表的 change log 转化为流,从而把静态表的关联转化为双流 join。从 change log 解析出的维度数据可以写入状态存储,起到缓存的作用。之后再提。
并没有那个是绝对的好坏,根据业务和资源情况进行取舍。















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









