









 该研究利用大量未标记的视频数据学习场景动力学模型,用于视频识别(如动作分类)和生成任务(如未来预测)。提出了一种两流生成对抗网络,包含动态前景路径和静态背景路径,通过结合生成器和判别器,模型能够内部学习识别动作的有用特征,同时生成带有静态背景和移动前景的视频。实验表明,模型在少量监督下能有效学习,并且生成器的参数可用于下游任务。
该研究利用大量未标记的视频数据学习场景动力学模型,用于视频识别(如动作分类)和生成任务(如未来预测)。提出了一种两流生成对抗网络,包含动态前景路径和静态背景路径,通过结合生成器和判别器,模型能够内部学习识别动作的有用特征,同时生成带有静态背景和移动前景的视频。实验表明,模型在少量监督下能有效学习,并且生成器的参数可用于下游任务。
目录
1、Quantitative Results on Video Generator
2、Video Representation Learning (Video Discriminator)
论文名称:Generating Videos with Scene Dynamics(2016 NIPS)
论文作者:Carl Vondrick, Hamed Pirsiavash, Antonio Torralba
项目网站:http://www.cs.columbia.edu/~vondrick/tinyvideo/
下载地址:https://arxiv.org/abs/1609.02612
Contributions
We capitalize on large amounts of unlabeled video in order to learn a model of scene dynamics for both video recognition tasks (e.g. action classification) and video generation tasks (e.g. future prediction). We propose a two-stream generative adversarial network for video with a spatio-temporal convolutional architecture that enforces a static background and moving foreground. Experiments and visualizations show the model internally learns useful features for recognizing actions with minimal supervision, suggesting scene dynamics are a promising signal for representation learning.
After the video generation training on large-scale unlabeled dataset finished, the parameters of discriminator can be transferred to other downstream tasks [85]. (comment from paper: Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey)
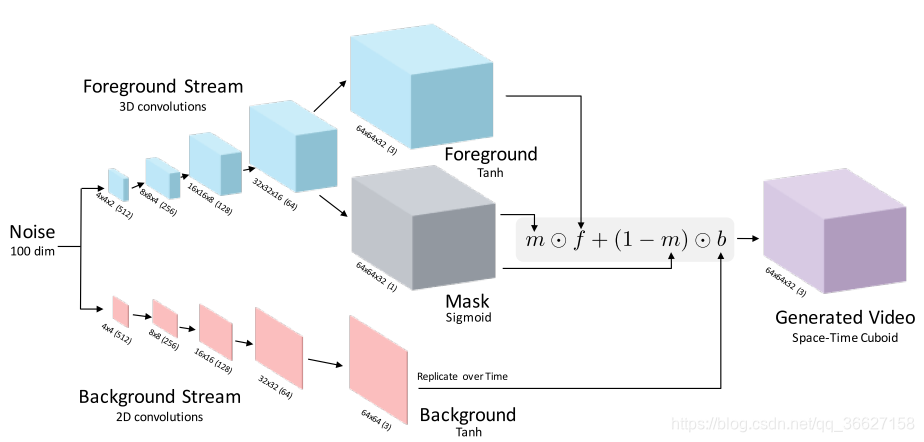
Method
1、Video Generator Network
The input is 100 dimensional (Gaussian noise). There are two independent streams: a moving foreground pathway of fractionally-strided spatio-temporal convolutions, and a static background pathway of fractionally-strided spatial convolutions, both of which up-sample. These two pathways are combined to create the generated video using a mask from the motion pathway. Below each volume is its size and the number of channels in parenthesis. We use a two-stream architecture where the generator is governed by the combination:
![]()
Our intention is that 0≥m(z)≥1 can be viewed as a spatio-temporal mask that selects either the foreground f(z) model or the background model b(z) for each pixel location and timestep. To enforce a background model in the generations, b(z) produces a spatial image that is replicated over time, while f(z) produces a spatio-temporal cuboid masked by m(z). By summing the foreground model with the background model, we can obtain the final generation. Note that ⊙ is element-wise multiplication, and we replicate singleton dimensions to match its corresponding tensor.
2、Video Discriminator Network
Firstly, it must be able to classify realistic scenes from synthetically generated scenes, and Secondly, it must be able to recognize realistic motion between frames. We use a five-layer spatio-temporal convolutional network with kernels 4 × 4 × 4 so be reverse of the foreground stream in the generator, replacing fractionally strided convolutions with strided convolutions (to down-sample instead of up-sample), and replacing the last layer to output a binary classification (real or not).
Results
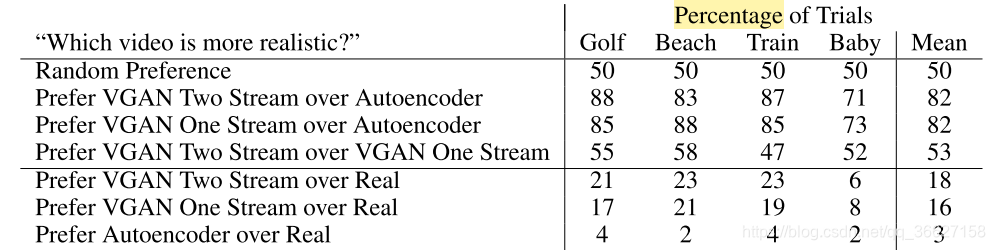
1、Quantitative Results on Video Generator
Table 1 shows the percentage of times that workers preferred generations from one model over another.
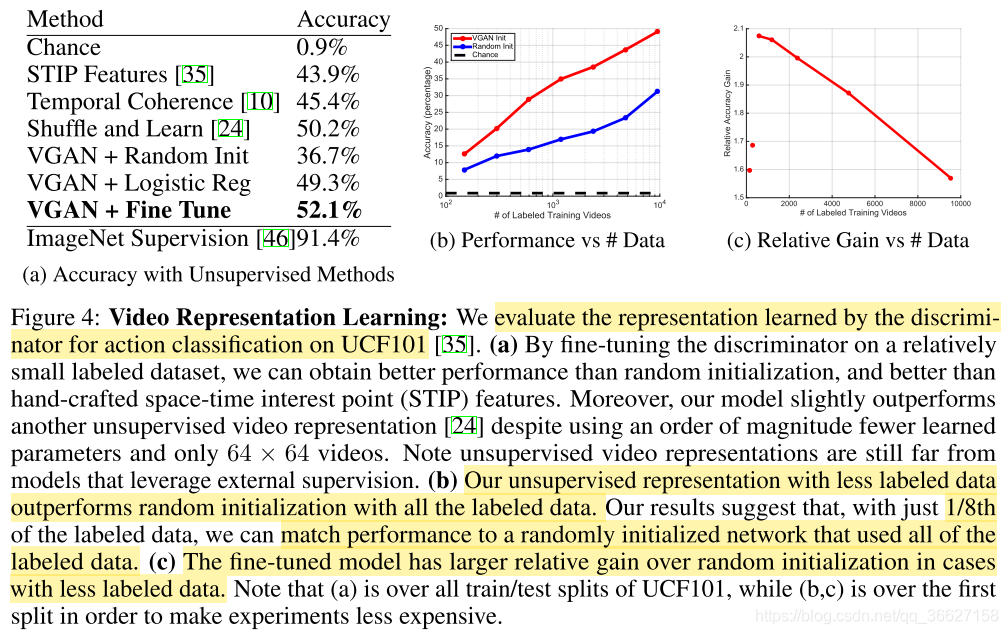
2、Video Representation Learning (Video Discriminator)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









