







Python爬虫 - 最新版12306(2018-12-26)从登录到订票
一两年前就开始写12306的爬虫,每次才开始都立了一个目标:从登录到查票、订票,如果没有票还可以抢票,一条龙服务。结果每次都是理想丰满现实骨感:
某次:能登录成功了,可把我牛逼坏了,为了奖励自己先放松一段时间(主要为偷懒找一个借口…),然后这个py文件就不知道被放在某个文件夹里多少个月了。
下一次:突然有一天打开这个文件夹,咦?怎么还有一个12306.py的文件?想了一会。。。哦,这好像是几个月前用来爬12306的,打开一看,这是谁写的啊?肯定不是我写的,这么垃圾?注释都没有?给谁看?我写一个肯定比这个好。然后心血来潮又从头开始写,然后又写到某某地方:像我这么优秀的人不能总沉迷于写代码,不行,得找室友开开黑。
…
N次:在某某某老师的压力下,重新写了12306,能登录了,能查票了,能订票了。(抢票也写了,但是没有试验过)。
在这些版本里用过python2里面的urllib、urllib2、cookielib等(好像用了储存cookie的,现在都忘了。。。)写过,后来学了Python3,又用requests这个号称:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。并且向你抛出一个警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。(我不知道Python2里有不有requests)。吓得我赶紧使用这个来写爬虫。后来又发现了selenium这个自动化测试的,感觉这个更简单。(所以没有用这个写过12306,太简单了,不能装逼啊)。如果你看了网上用selenium实现的12306爬虫,你肯定不会选择我这种。

爬虫的原理简述
自己总结的,表述可能不是很准确,能明白大概意思就ok。
我们在使用浏览器正常访问网站的时候,我们通过鼠标点点点等操作,浏览器就可以执行显示我们点击的内容。实际上是我们点击了一些特定的标签或者触发了一些绑定事件什么的,向服务器发送请求,然后接受服务器返回的响应。比如说我们在网页中看到一张图片,那么它可能就是这么来的:先找到服务器主机,对它说:喂,把XXX图片给我。服务器看你顺眼就可能把这张图片给你了(或者看你不是人(通过爬虫进行请求))。得到这张图片,通过浏览器解析就可以看到网页中的图片了。所以这张图片就是这么来的:喂,把XXX图片给我(请求)——把这张图片给你(响应)——浏览器解析(处理响应)。
所以爬虫是什么?简单说就是我们模拟浏览器发送请求——获取响应——处理响应(希望我理解的是正确的)
不批跨了,下面进入正题。(如果看了上面一个12306就爬了几年的就知道我也是个菜鸡,如有错误的地方请指出,如实在看不下去的,想拍我的,我只想对你说:求求你顺着网线来打我啊)。
准备
没有什么可准备的,python运行环境肯定没有问题吧,肯定熟悉Python基础语法以及对Python爬虫有一点了解吧,至于需要安装什么库在用到的时候会告诉安装需要什么库,如果在开头就告诉安装大量的库,如果安装顺利还好,不顺利肯定会影响自己的心情,甚至成为《Python爬虫从入门到放弃》的读者。
一、登录部分
最新版12306(2018年12月11日的)登录有两种方式进行登录:用户名密码登录和二维码登录,我们这里使用第一种方法:用户名加密码进行登录。
登录分析:在我们正常进行登录时,我们都是把账号密码、验证码都输入好了再点击登录按钮就可以进行登录了,在我们看来这就是一个登录操作。其实网页处理的时候把这个登录分为账号密码验证和验证码验证两个部分。所以我们要进行模拟登录就需要进行分析它究竟是先进行什么验证(其实想一下就可以猜到一般都是先进行验证码验证,如果成功再进行账号密码验证)。当然也可以试一下嘛。先胡乱输账号密码和验证码,点击登录按钮,发现它是先提醒你验证码验证失败了,说明是先检测验证码是否正确再检测账号密码。也可以打开F12进行正确登录,通过请求的先后顺序也可以看出验证的顺序。如果你还不信就看JS代码吧(本博文关于JS请求的内容不会讲,如果遇到就直接告诉你们url或者参数什么的,第一:我的JS也是水得很的,只能看懂很简单的代码,所以可能会错误百出;第二是怕没有接触过前端的看了就懵逼了)。既然分析出了登录处理的先后顺序,那么我们下面先对验证码进行处理,然后再对账号密码进行处理。
处理验证码图片
我们需要处理验证码,验证码从哪来?请看下面讲解。
获取验证码图片
我们需要处理验证码,验证码从哪来?肯定不是自己造一个啊。所以我们来看看它是怎么来的。进入12306登录界面,按F12或者右键检查元素,打开开发者工具(我用的QQ浏览器,浏览器不同,开发者工具有可能不同),选择Network。这样就准备就绪了。

这里面就可以看到向服务器发送的请求。现在我们要获得一张验证码,怎么获得?看到刷新那两个字没有?对,就是验证码图片右上角的那个。点它一下,在开发者工具里出现了什么?没错,这就是向服务器要图片的请求。

我们点一下第一个请求,然后又出现了一些东西,最上面有Headers、Preview、Response什么的,点击Response,也就是响应,看到中文字没有?生成验证码成功?把下面的滚动条往后拉,怎么全是一些看不懂的天文,你说我验证码生成成功了,它在哪里啊?有点经验的都知道,这些天文就是base64编码过的图片数据。其实在之前的12306版本中不会做这样的编码。
以前获取图片的链接是这个:https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561
现在获取图片的链接是这个:https://kyfw.12306.cn/passport/captcha/captcha-image64?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561。
看出主要的部分有什么不同了吗?没错,现在的就是在“captcha-image”后面多了“64”,64?不就是base64嘛。哈哈哈。

我们在点第二个看看,这次我们点Preview。看到没,这就是验证码图片。点击Headers,发现里面也有很多天文,仔细一看,好像和第一个请求的响应里面的差不多。可以猜出图片就是这些天文生成的。

下面我们开始在Python里面来获取验证码图片。
import requests # 导入requests
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561'
res = requests.get(url)
print(res.text)
运行,发现和第一个请求响应的结果一样,说明我们获取验证码图片成功了。那么怎么把天文转为图片呢?这里就需要用到base64这个库,对base64的字符串进行解码。
import requests
import base64
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url).json() # 把结果转为json形式
print(res['image']) # 打印可以看到我们已经把那些看不懂的字符串提取出来了
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res['image'])) # 把字符串转为字节,然后写入到图片文件中
找到你保存到的图片位置,可以看到我们已经把验证码图片拿到了。是不是很简单?

验证验证码图片
得到了验证码图片,现在就可以开始进行验证了。怎么验证?为什么12306知道我点击的图片是对的或者是错的?啥?不知道?不知道就打开F12,正常请求一下,看看它是怎么进行验证的。
照着下面的步骤来。

点击登录按钮后又出现了三个新的请求。点击captcha-check的那个请求,在右边可以看的你点击的验证码是否是正确的。

响应里面告诉我们点击的图片是否正确,那么它是怎么知道我们点击的图片是否是正确的呢?老司机已经猜到了,肯定在请求里携带了参数的啊。
就像我和你考试对答案,我问你:第一题我选对了吗?你肯定会说:你是傻逼吗?你都不告诉我你第一题选什么,我怎么知道你选对没有?
检测图片是否点击正确一样,图片是题目,点击的结果是答案。所以服务器知道我们点击的验证码是否正确,肯定是以某种形式把我们点击的信息传递给服务器了,这样服务器才能进行判断。
还是点击刚才的那个请求,然后点击Headers,滑动到最下面,如图。(有可能浏览器不一样,开发者工具显示就不一样,比如说火狐它就是中文的,并且把参数也给你单独分了出来,其实都是差不多的)。

在我圈出来的地方看到没?answer=答案,这意思就是我选的答案是这个,问服务器我选对没有。仔细观察,我们刚才明明只点了两个图片,怎么答案出现了四个?你再试一下点一个、三个或者更多,发现都是你点击图片的2倍。这是什么意思?在数学中,我们怎么在一个平面确定一个点?你肯定脱口而出:不就是它的横纵坐标来确定吗,这么简单的问题,中国学生都知道。再回到12306,发现12306好像也是这么判断我们点击的哪个图片了。点击一个图片,就有两个答案,不就是横纵坐标吗。我们再试一下点击验证码图片的最左上角,和最右下角,再看一下传递的答案,发现前两个数字接近0,后两个参数接近图片的大小。(忘了说了,在程序猿的世界里,数数从0开始数,坐标原点(0,0)在左上角)。
知道我们向服务器发送的答案是怎么来的了,现在我们就在Python中写。先获取一张验证码图片,保存到你指定的位置,找到你保存的图片打开,然后选择正确的图片,输入我们下面计算的点坐标,发送给服务器,让服务器告诉我们是否点击的是正确的。
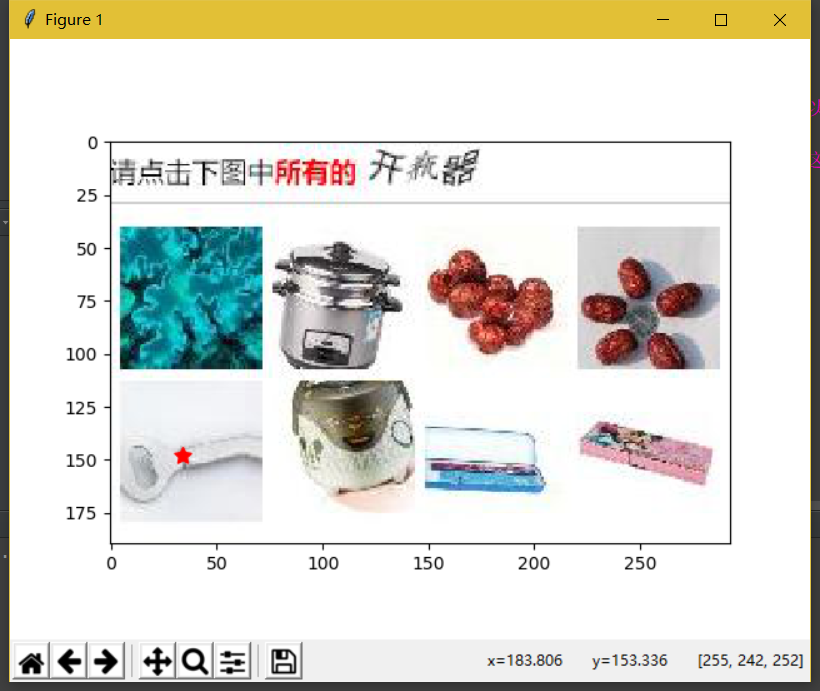
在做之前我们还有计算一下哪些范围内的点才是正确的(不计算也可以,我在后面也写了一个弹出一张验证码,点击就可以了)。比如我们要点击下面这张图片中的开瓶器。第一张和第八张是开瓶器吧。当我们点击的两个点落在这两张图片的范围内,服务器就算我们点击正确了。所以我们计算一下这些图片的中心点的大概位置。灵魂画手已上线,如图所示。

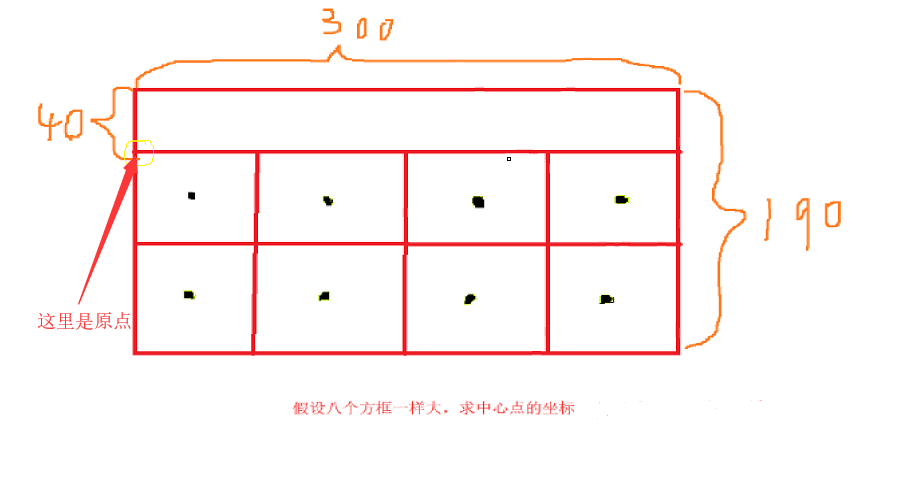
第一个点:(35,35)
第二个点:(110,35)
第三个点:(185,35)
第四个点:(260,35)
第五个点:(35,110)
第六个点:(110,110)
第七个点:(185,110)
第八个点:(260,110)
我们把获取验证码图片的代码和检测的代码封装成函数。代码如下:
import requests # 导入这个库
import base64
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = input('请输入验证码:') # 注意输入的格式: x1,y1,x2,y2
# get请求可以直接在地址后面拼接参数,也可以用params进行传递参数。
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params)
print(res.text) # 打印检测图片的响应信息
if __name__=='__main__':
get_captcha()
captcha_check()

自己试一试,看看打印,怎么样?是不是无论怎么输入都打印:验证码校验失败,信息为空?就算输入错了,也不应该告诉我们为空啊,不信在浏览器上点击错误的图片试一下,发现它是告诉你输入的是错误的。我们明明输了,为什么它说信息为空?原因:虽然你告诉了服务器你的答案,但是你没有告诉它这个答案是去检测哪张验证码图片!因为在你访问12306时,其他人有可能在访问。比如张三向服务器请求了一张图片,李四这时候也请求一张图片,张三告诉服务器:我点击的验证码是XXXX,你看我点的对不对?服务器就懵了,因为服务器和张三、李四都是通过网线连接的,就给服务器发一个答案,它总不可能顺着网线来找你,看是谁要图片。所以验证图片和答案应该也是有一个对应关系的,在发送点击的答案时也要把这个答案的图片(或者代表这张图片的标志)发给服务器验证。
那么怎么知道是验证谁的图片?我们正常登录时它是怎么知道的呢?看一下获取验证码图片请求的头信息,里面的Response Headers响应头,有一个Set-Cookie字段。查看_passport_session对应的值。再查看检测验证码的请求的头信息,里面的Request Headers请求头,有一个Cookie,找到_passport_session对应的值,把它和刚才我们在获取验证码响应头里面的对比一下,发现它们是一样的。相关Cookie和Session知识:Cookie/Session机制详解
当你向服务器请求一张验证码图片时,服务器给你通过Set-Cookie,给你一个Cookie,就相当于把你这张图片做了标记,下次在验证图片的时候,再把这个标记和你点击的答案传给服务器,服务器就知道:哦,你要我验证XXX图片的答案。

既然知道了为什么总是提醒我们信息为空了,就动手在Python里面在获取图片时拿到服务器给的cookie,然后再检测图片时,把cookie方在检测请求头里。能不能成功,试一下就知道了。
import requests # 导入这个库
import base64
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
global cookies # 设置一个全局的变量
cookies = res.cookies # 从这个响应里面获取cookies,保存到全局变量中
# print('服务器设置的Cookies:', cookies)
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = input('请输入验证码:') # 注意输入的格式: x1,y1,x2,y2
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params, cookies=cookies) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# print(res.request.headers['Cookie']) # 打印检测验证码图片请求头里的cookie
if __name__ == '__main__':
get_captcha()
captcha_check()
没有成功?不可能,你打印一下检测验证码图片请求头里的cookie是不是和服务器设置的一样。


点击式验证码图片
这里我再贴出获取验证码图片后直接显示出来可以直接点击的代码,就不用每次输入那么麻烦了。(你如果觉得下面的代码写起来更麻烦那就用输入的方式吧)。需要安装第三方库:numpy、matplotlib、PIL ,应该都可以直接用pip直接安装,如果不行就在网上找其他方法安装,满大街都是。
import requests
import base64
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import io
points = [] # 储存点击点的坐标
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
global cookies # 设置一个全局的变量
cookies = res.cookies # 从这个响应里面获取cookies,保存到全局变量中
# print('服务器设置的Cookies:', cookies)
return io.BytesIO(base64.b64decode(res.json()['image'])) # BytesIO把图片字节存入内存,使Image.open可以像文件一样操作它
# 如果要显示图片,可以直接返回图片的字节,就不用保存图片然后再用Image.open打开(当然,如果你用不来也可以先保存到本地,然后用Image.open打开)
# with open('captcha.jpg', 'wb') as f:
# f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 显示验证码图片
def show_img():
o_img = Image.open(get_captcha())
np_img = np.array(o_img) # 把这个图片GRB转为矩阵(和多维列表差不多)
plt.imshow(np_img) # 放入显示的图片矩阵
plt.gcf().canvas.mpl_connect('button_press_event', mouse_press) # 添加鼠标按下事件
plt.show() # 显示
# 鼠标按下
def mouse_press(event):
x = event.xdata # 在图片中点击的x坐标
y = event.ydata # 在图片中大奖的y坐标
if y < 40:
return
points.append([int(x), int(y)]) # 添加到全局的变量中
plt.scatter([x for x, y in points], [y for x, y in points], c='r', s=100, marker=(5, 1, 0)) # 画散点图,第一个参数是横坐标,第二个是纵坐标,c是颜色,s是大小,marker是形状
plt.gcf().canvas.draw() # 重新绘制
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = ','.join([str(x) + ',' + str(y) for x, y in points]) # 转为需要传递的参数格式
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params, cookies=cookies) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# print(res.request.headers['Cookie']) # 打印检测验证码图片请求头里的cookie
if __name__ == '__main__':
show_img()
captcha_check()
现在我们就可以直接点击正确的图片,然后关掉这个窗口(这个窗口相当于阻塞),就可以进行验证了。
显示出来的图片:
账号登录
上面我们已经把验证码验证成功了,接下来就该是登录的第二部分了:账号和密码处理。有了上面的经验,下面不就轻车熟路了吗?

账号密码检测
还是一样,在登录界面打开开发者工具,这次我们把验证码输入正确,账号密码随你输,点击登录,发现在检测验证码去请求后面又多了一个login请求。一看就知道是对登录的账号密码进行验证的请求。肯定也传递了参数,跟上面传递点击的图片答案一样,按着那个步骤找到传参的位置。可以看到你输入的用户名和密码。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









