






机器学习知识体系总结
所有的知识,无论过去,当下和未来,都可以利用某个单一,通用的学习算法中从数据中获取。–《终极算法》
什么是机器学习?
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习系统是训练出来的,而不是明确地用程序编写出来的,将与某个任务相关的许多示例,输入到机器学习系统,它会在这些示例中找到统计结构,从而最终找到规则将任务自动化。
比如,你想为度假照片添加标签,并且希望将这项任务自动化,那么你可以将许多人工打好标签的照片输入到机器学习系统,系统将学会把照片与特定标签联系在一起的统计规则。
在经典的程序设计中,人们输入的是规则(程序)和需要根据这些规则进行处理的数据,系统输出的是答案。机器学习是一种新的编程范式,利用机器学习,人们输入的是数据和从这些数据中预期得到的答案,系统输出的是规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。
机器学习是一种新的编程范式,机器学习算法需要“输入数据点、预期输出的示例、衡量算法效果好坏的方法“三个要素来进行机器学习,系统输出的是规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。
机器学习和深度学习的核心问题在于有意义地变换数据,机器学习模型都是为输入数据寻找合适的表示,对数据进行变换,使其更适合手头的任务。
深度学习是机器学习的一个分支领域,是从数据中学习表示的一种数学框架,强调从连续的层 (layer) 中进行学习,这些分层表示几乎总是通过神经网络 (neural network) 模型来学习得到的。
机器学习体系概括
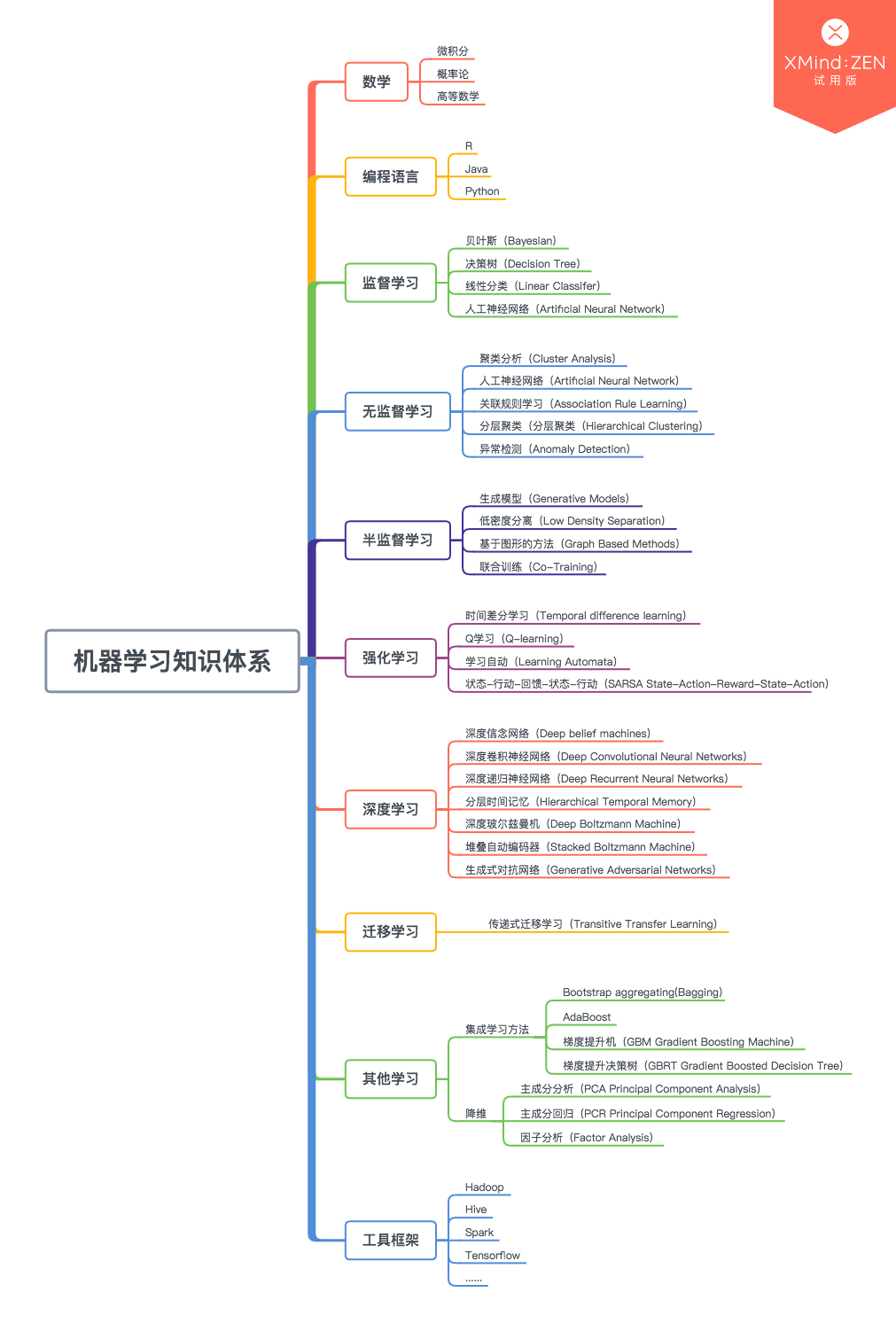
机器学习包含多交叉学科,同时也在很多方面得到应用,如自然语言处理、图像处理、数据挖掘、推荐系统领域等。机器学习包含监督学习、无监督学习、半监督学习、强化学习、深度学习、迁移学习等。
机器学习算法中常用到的便是监督学习和无监督学习,监督学习包含回归和分类两方面,无监督学习为聚类。
监督学习(Supervised Learning)
当你有一些问题和他们的答案时,你要做的有监督学习就是学习这些已经知道答案的问题,当你具备此类学习的经验时,便是学习的成果。然后当你接受到一个新的此类问题时,便可通过学习得到的经验,得出新问题的答案。当我们有一些样本数据集时,对于每个单一的数据根据他的特征向量我们要去判断他的标签,那么就是监督学习。监督学习分为**回归分析(Regression Analysis)和分类(Classification)**两类。
- 回归分析(Regression Analysis):其数据集是给定一个函数和他的一些坐标点,然后通过回归分析的算法,来估计原函数的模型,求得最符合这些数据集的函数解析式。然后我们就可以用来预估未知数据,输入一个自变量便会根据这个模型解析式输出因变量,这些自变量就是特征向量,因变量即为标签,而且标签的值是建立在连续范围的。
- 分类(Classfication):其数据集由特征变量和标签组成,当你学习这些数据之后,给你一个只知道特征向量不知道标签的数据,让你求他的标签是哪一个?分类和回归的主要区别就是输出结果是连续还是离散。
十种监督学习方法
李航统计学习方法第二版中,共介绍了十种监督学习方法:感知机、k 近邻、朴素贝叶斯、决策树、逻辑回归与最大熵模型、支持向量机、提升方法、EM 算法、隐马尔可夫模型和条件随机场。
首字联为:感 K 朴决逻,支提 E 隐条。
十种监督学习方法特点的概括总结表:
| 方法 | 适用问题 | 模型特点 | 模型类型 | 学习策略 | 学习的损失函数 | 学习算法 |
|---|---|---|---|---|---|---|
| 感知机 | 二分类 | 分离超平面 | 判别模型 | 极小化误分点到超平面距离 | 误分点到超平面距离 | 随机梯度下降 |
| K近邻 | 多类分类,回归 | 特征空间,样本点 | 判别模型 | - | - | - |
| 朴素贝叶斯 | 多类分类 | 特征与类别的联合概率分布,条件独立假设 | 生成模型 | 极大似然估计,最大后验概率估计(MAP) | 对数似然损失 | 概率计算公式,EM算法 |
| 决策树 | 多类分类,回归 | 分类树,回归树 | 判别模型 | 正则化的极大似然估计 | 对数似然损失 | 特征选择,生成,剪枝 |
| 逻辑回归与最大熵模型 | 多类分类 | 特征条件下类别的条件概率分布,对数线性模型 | 判别模型 | 极大似然估计,正则化的极大似然估计 | 逻辑损失 | 改进的迭代尺度算法,梯度下降法,拟牛顿法 |
| 支持向量机 | 二类分类 | 分离超平面,核技巧 | 判别模型 | 极小化正则化合页损失,软间隔最大化 | 合页损失 | 序列最小最优化算法(SMO) |
| 提升方法 | 二类分类 | 弱分类器的线性组合 | 判别模型 | 极小化加法模型的指数损失 | 指数损失 | 前向分步加法算法 |
| EM算法 | 概率模型参数估计 | 含隐变量的概率模型 | - | 极大似然估计,最大化后验概率估计 | 对数似然损失 | 迭代算法 |
| 隐马尔可夫模型 | 标注 | 观测序列与状态序列的联合概率分布模型 | 生成模型 | 极大似然估计,最大化后验概率估计 | 对数似然损失 | 概率计算公式,EM算法 |
| 条件随机场 | 标注 | 状态序列条件下观测序列的条件概率分布,对数线性模型 | 判别模型 | 极大似然估计,正则化极大似然估计 | 对数似然损失 | 改进的迭代尺度算法,梯度下降法,拟牛顿法 |
统计学习方法:模型+策略+学习方法
模型
监督学习中,模型就是所要学习的条件概率分布
P
(
X
∣
Y
)
P(X|Y)
P(X∣Y)或者决策函数
Y
=
f
(
X
)
Y = f(X)
Y=f(X)。
按问题类型分类:
- 简单分类方法:感知机、k 近邻法、朴素贝叶斯法、决策树。
- 复杂分类方法:逻辑回归模型、最大熵、支持向量机、提升方法。
- 标注方法:隐马尔科夫模型、条件随机场。
概率模型和非概率模型:
- 概率模型(由条件概率表示的模型):朴素贝叶斯、隐马尔科夫模型。
- 非概率模型(由决策函数表示的模型):感知机、k近邻、支持向量机、提升方法。
- 概率模型和非概率模型:决策树、逻辑回归模型、最大熵模型、条件随机场。
生成模型和判别模型:
- 判别模型(直接学习条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)或者决策函数 Y = f ( X ) Y=f(X) Y=f(X)):感知机,k 近邻,决策树,逻辑回归模型,最大熵模型,支持向量机,提升方法,条件随机场。
- 生成模型(先学习联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),从而求得条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)):朴素贝叶斯,隐马尔科夫模型。
线性模型和非线性模型:
- 线性模型:感知机
- 对数线性模型:逻辑回归模型、最大熵模型、条件随机场
- 非线性模型:k 近邻、决策树、支持向量机(核函数)、提升方法
分类与标注:
- 分类:LR,ME,NB
- 标注:CRF,HMM
策略
- 统计学习的目标在于从假设空间中选取最优模型
- 损失函数度量一次预测的好坏;风险函数度量平均意义下模型预测的好坏
- 经验风险最小化(ERM)与结构风险最小化(SRM)
- 经验风险或者结构风险是最优化的目标函数
三种损失函数
- 合页损失:线性支持向量机, m a x ( 0 , 1 − y f ( x ) ) max(0,1 - yf(x)) max(0,1−yf(x))。
- 逻辑回归损失函数:逻辑回归模型与最大熵模型, l o g ( 1 + e x p ( − y f ( x ) ) ) log(1+exp(-yf(x))) log(1+exp(−yf(x)))。
- 指数损失函数:提升方法, e x p ( − y f ( x ) ) exp(-yf(x)) exp(−yf(x))。
学习的策略是优化一下结构风险函数:
min f ∈ H 1 N ∑ i = 1 n L ( y i , f ( x i ) ) + λ J ( f ) {\underset {f\in H} {\min}} {\frac{1}{N}} \sum_{i=1}^{n}L(y_i,f(x_i))+\lambda J(f) f∈HminN1i=1∑nL(yi,f(xi))+λJ(f)
第一项为经验风险(经验损失),第二项为正则化项。
二分类推广
- 推广到多类。
- 标注问题的条件随机场可以看成是分类问题的最大熵模型推广。
- 概率模型的学习可以形式化为极大似然估计或贝叶斯估计的极大后验概率估计,极小化对数似然损失: − log P ( y ∣ x ) -\log P(y|x) −logP(y∣x)。
- 决策树的学习策略是正则化的极大似然估计,损失函数是对数损失函数,正则化是决策树的复杂度
- 逻辑回归模型与最大熵模型,条件随机场的学习策略既可以看成是极大似然估计,又可以看成是极小化逻辑回归损失。
- 朴素贝叶斯模型,隐马尔科夫模型的非监督学习也是极大似然估计或极大后验概率估计,但这时模型含有隐变量。
学习算法
统计学习问题转化为最优化问题,有显式解析解,对应的最优化问题比较简单,通常解析解不存在,需要通过数值计算的方式求解。
朴素贝叶斯法与隐马尔科夫模型:最优解就是极大似然估计值,可以由概率计算公式直接计算。
感知机,逻辑回归模型,最大熵模型,条件随机场:利用梯度下降法、拟牛顿法,无约束最优化问题的解法。
支持向量机:解凸二次规划的对偶问题,有序列最小最优化算法。
决策树:基于启发式算法,特征选择、生成、剪枝是启发式地进行正则化的极大似然估计。
提升方法:启发式地从前向后逐步学习模型。
EM算法:迭代求解含隐变量概率模型参数
支持向量机、逻辑回归模型、最大熵模型,条件随机场的学习是凸优化问题,全局最优解存在,其他学习问题不是凸优化问题。
无监督学习(Unsupervised Learning)
我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题聚集在一组……)。
所有的数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是相似的类型会聚集在一起。把这些没有标签的数据分成各个组合便是聚类。比如每天都会搜到大量新闻,然后把它们全部聚类,就会自动分成几十个不同的组(比如娱乐、科技、政治…),每个组内新闻都具有相似的内容结构。
八种无监督统计机器学习方法:
- 聚类方法(层次聚类、k均值聚类)
- 奇异值分解(SVD)
- 主成分分析(PCA)
- 潜在语义分析(LSA)
- 概率潜在语义分析(PLSA)
- 马尔科夫链蒙特卡洛法(MCMC,包括Metropolis-Hastings算法、吉布斯抽样)
- 潜在狄利克雷分配(LDA)
- PageRank算法
此外还有非负矩阵分解(NMF)、变分推理、幂法。
这些方法通常用于无监督学习的 聚类、降维、话题分析、图分析。
** 无监督学习方法的特点:**
| - | 方法 | 模型 | 策略 | 算法 |
|---|---|---|---|---|
| 聚类 | 层次聚类 | 聚类树 | 类内样本距离最小 | 启发式算法 |
| - | k均值聚类 | k中心聚类 | 样本与类中心距离最小 | 迭代算法 |
| - | 高斯混合模型 | 高斯混合模型 | 似然函数最大 | EM算法 |
| 降维 | PCA | 低维正交空间 | 方差最大 | SVD |
| 话题分析 | LSA | 矩阵分解模型 | 平方损失最小 | SVD |
| - | NMF | 矩阵分解模型 | 平方损失最小 | 非负矩阵分解 |
| - | PLSA | PLSA模型 | 似然函数最大 | EM算法 |
| - | LDA | LDA模型 | 后验概率估计 | 吉布斯抽样,变分推理 |
| 图分析 | PageRank | 有向图上的马尔可夫链 | 平稳分布求解 | 幂法 |
** 含有隐变量概率模型的学习方法的特点:**
| 算法 | 基本原理 | 收敛性 | 收敛速度 | 实现难易度 | 适合问题 |
|---|---|---|---|---|---|
| EM算法 | 迭代计算、后验概率估计 | 收敛于局部最优 | 较快 | 容易 | 简单模型 |
| 变分推理 | 迭代计算、后验概率近似估计 | 收敛于局部最优 | 较慢 | 较复杂 | 复杂模型 |
| 吉布斯抽样 | 随机抽样、后验概率估计 | 依概率收敛于全局最优 | 较慢 | 容易 | 复杂模型 |
半监督学习
未完待续。。。















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









