






前言
R语言中最常见的数据类型数据框,通常数据框一列表示一个变量(variable),一行表示观测的数据(observation),单元格的值就是观测值(value)。有时候数据一行很长,不好分析每个数据,如成绩表,想看每科的成绩比较。下面就介绍两个R语言中好用的两个函数。两个函数都属于tidyr包
提示:以下是本篇文章正文内容,下面案例仅供自己学习使用
一、使用的数据为R语言自带的鸢尾花数据
先加载数据
attach(iris)
iris
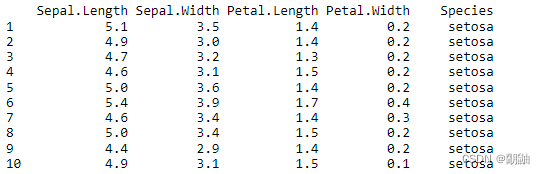
鸢尾花数据有5列,分别代表花萼长度,花萼宽度,花瓣长度,花瓣宽度,以及品种,下面我们随机使用其中1、51、101三行数据,用gather和pivot_long函数演示
二、gather
1.引入库
代码如下(示例):
library(tidyr)
2.提取其中三行数据
代码如下(示例):
t_iris <- iris[c(1,51,101),]
t_iris
数据如下:

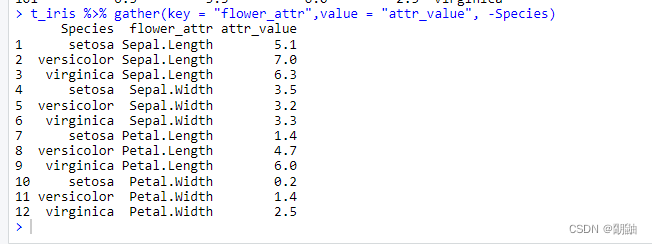
结果如上。-Species表示反选,不选该列,如果所选列太多可以这样做。
gather(data,key = “key_name”,value = “value_name”,…)
key - value表示所选的数据的键值对。key:变量名,value:变量名key对应的值
三、pivot_longer
pivot_longer(data, cols, names_to = “name”, values_to = “values”)
参数意义同gather
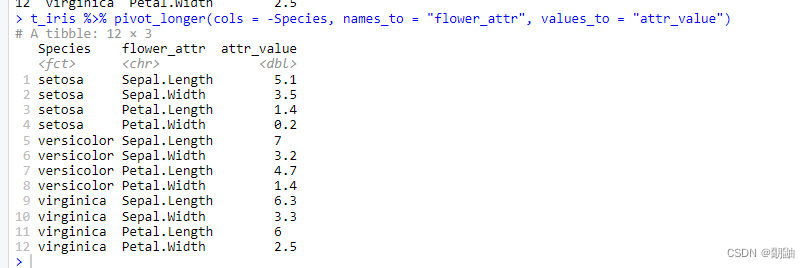
- -Species可改成**!Species**
t_iris %>% pivot_longer(cols = contains(c("Length", "width")),names_to = "flower_attr", values_to = "attr_value")
效果跟上面类似
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了数据框中两个把数据框由宽变长的两个函数gather和pivot_longer的使用,其中gather好像逐渐由后来的pivot_longer替代。tidyr包还提供了其他大量能使我们快速便捷地处理数据框的函数和方法,如spread和pivot_wider刚好与上面两个函数用法相反。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









