






Gluster节点异常更换操作
gluster版本:

场景1:
集群中主节点server1运行正常,从节点server2系统损坏,且所有盘都格式化,需要重新安装server2服务器
恢复步骤:
1.在server1机器上,剔除server2节点的残留brick信息:
命令行:
gluster volume remove-brick gluster-vol replica 1 ocloud62:/cloudstor/bcache0/data force
说明:gluster-vol为卷组名称;ocloud62为server2的主机名;/cloudstor/bcache0/data为server2的brick路径;

2.然后剔除该节点的gluster peer信息:
命令行:
gluster peer detach ocloud62
说明:ocloud62为server2的主机名

3.从节点重新搭建bcache 、gluster信息
4.在Server1从新建立peer信息:
命令行:
gluster peer probe ocloud62
以下截图是本人自己写的一个脚本,最终也是执行上述命令行,忽略截图。
5.通过命令将server2新建的brick加入集群中
命令行:
gluster volume add-brick gluster-vol replica 2 ocloud62:/cloudstor/bcache0/data force
说明:“gluster-vol”是gluster的卷名;ocloud62为server2的主机名;“/cloudstor/bcache0/data ”为server2将要新增的brick路径;

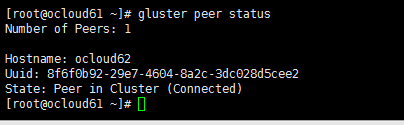
通过命令查看gluster的volume和peer状态:
查看peer状态:
gluster peer status
查看volume状态:
gluster volume status
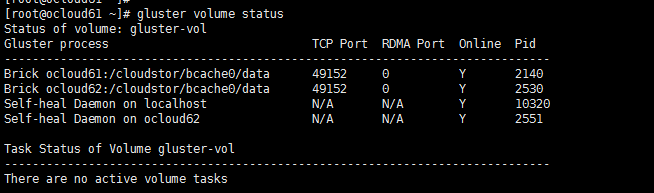
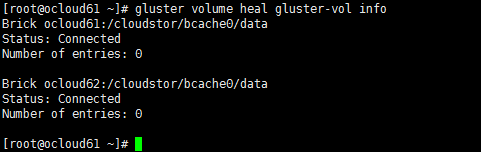
此时gluster 卷信息已经正常,一般gluster会自动触发同步机制,若新加入的brick里尚未同步数据,通过gluster volume heal sata-vol命令恢复数据
之后通过gluster volume heal sata-vol info查看状态















 1253
1253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









