






one-hot向量与word2vec
one-hot向量
1.1 one-hot编码
什么是one-hot编码?one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图: 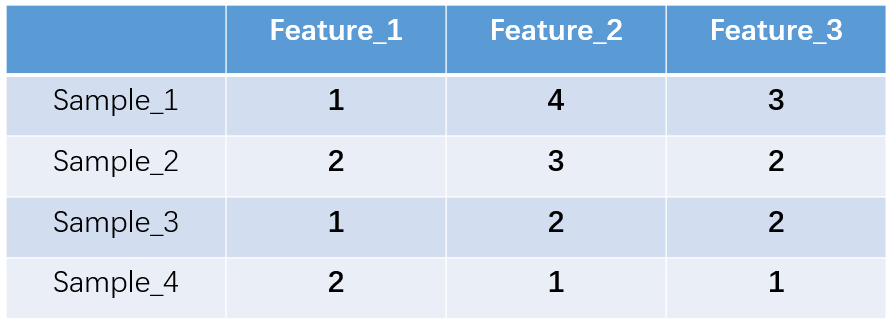
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:
这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,所以我们可以得到这些样本特征的新表示:
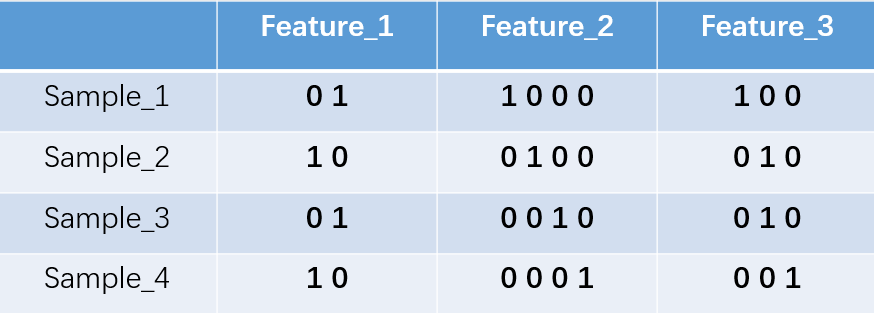
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

1.2 one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
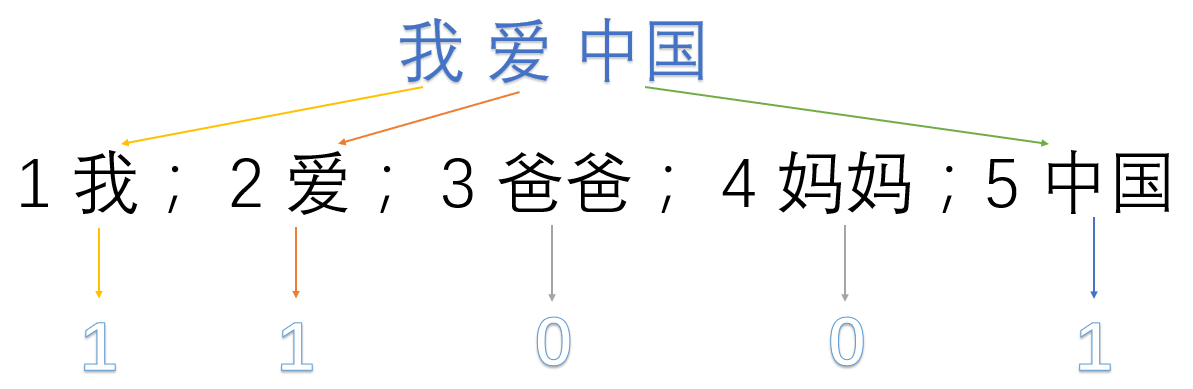
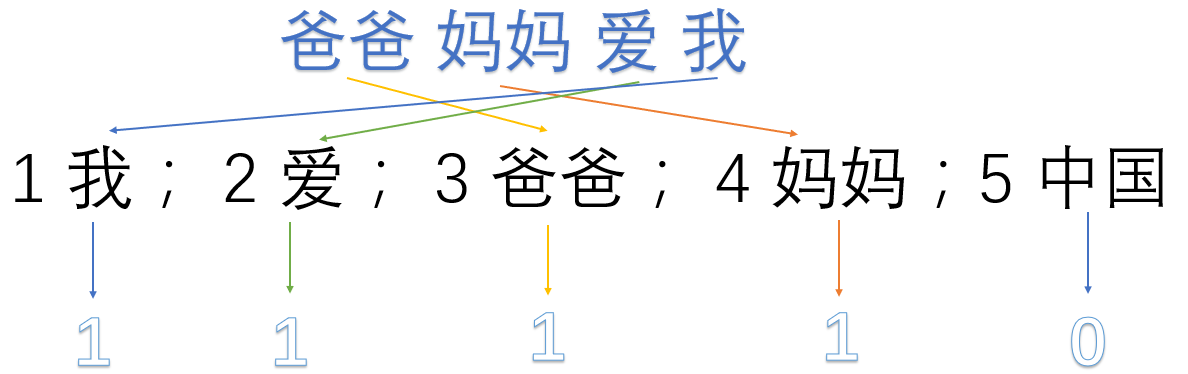
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
 ;
; ;
;
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
sklearn实现one hot encode
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder() # 创建对象
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 拟合
array = enc.transform([[0,1,3]]).toarray() # 转化
print(array)
- 1
- 2
- 3
- 4
- 5
- 6
word2vec得到词向量
word2vec是如何得到词向量的?这个问题比较大。从头开始讲的话,首先有了文本语料库,你需要对语料库进行预处理,这个处理流程与你的语料库种类以及个人目的有关,比如,如果是英文语料库你可能需要大小写转换检查拼写错误等操作,如果是中文日语语料库你需要增加分词处理。这个过程其他的答案已经梳理过了不再赘述。得到你想要的processed corpus之后,将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)就ok了。不得不说word2vec是个很棒的工具,目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)。于是我主要理解word2vec如何将corpus的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵),真真切切感受到向量的变化,不涉及加速算法。
1 Word2Vec两种模型的大致印象
刚才也提到了,Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram模型。
CBOW模型根据中心词W(t)周围的词来预测中心词
Skip-gram模型则根据中心词W(t)来预测周围词
抛开两个模型的优缺点不说,它们的结构仅仅是输入层和输出层不同。请看:

CBOW模型

Skip-gram模型
这两张结构图其实是被简化了的,读者只需要对两个模型的区别有个大致的判断和认知就ok了。接下来我们具体分析一下CBOW模型的构造,以及词向量是如何产生的。理解了CBOW模型,Skip-gram模型也就不在话下啦。
2 CBOW模型的理解
其实数学基础及英文好的同学可以参照斯坦福大学Deep Learning for NLP课堂笔记。
当然,懒省事儿的童鞋们就跟随我的脚步慢慢来吧。
先来看着这个结构图,用自然语言描述一下CBOW模型的流程:

(花括号内{}为解释内容.)
- 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N.
- 乘以输出权重矩阵W’ {N*V}
- 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word)
- 与true label的onehot做比较,误差越小越好
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
这回就能解释题主的疑问了!如果还是觉得我木有说明白,别着急!跟我来随着栗子走一趟CBOW模型的流程!
3 CBOW模型流程举例
假设我们现在的Corpus是这一个简单的只有四个单词的document:
{I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词”I”,”drink”和”everyday”来预测一个单词,并且我们希望这个单词是coffee。





假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
在我的新闻分类中由于使用的是自带的60000多词训练出的embedding层而有9000多个词并不在里面所以效果没有达到最佳,值得改进
词袋模型:离散、高维、稀疏。
离散:无法衡量词向量之间的关系
比如酒店、宾馆、旅社 三者都只在某一个固定的位置为 1 ,所以找不到三者的关系,各种度量(与或非、距离)都不合适,即太稀疏,很难捕捉到文本的含义。
高维:词表维度随着语料库增长膨胀,n-gram 序列随语料库膨胀更快。
稀疏: 数据都没有特征多,数据有 100 条,特征有 1000 个
-
word2vec词向量通俗化解释:
word2vec(word to vector)是一个将单词转换成向量形式的工具。
-
作用:
word2vec适合用作序列数据的分类,聚类和相似度计算。有用作app下载推荐系统中的,也有用在推荐系统和广告系统上的,也可以用在机器人对话类别判决系统上。
-
算法:
首先这是一个逻辑回归(分类)问题,使用最大似然估计。 在已知历史单词,要最大化下一个单词出现的概率,使用softmax函数做分类,则问题的数学描述如下:
这里计算上下文是时单词是的概率,显然上面的除法和指数计算是比较耗时,那么能否进行简化,答案就是取对数,将目标函数转换如下

假设我们的上下文是基于两个单词的,则根据the cat sits on the mat,将得到如下的训练样本:
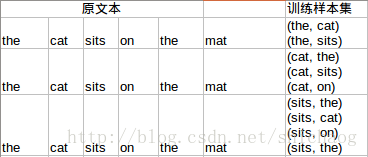
上面只罗列了CBOW下的样本集。神经网络的结构如下:

输入层:
上述过程可以描述如下:
1.首先将所有的单词做one-hot映射,这把每一个单词映射到权重矩阵的一行,这每一行对应于该单词的特征向量,

这里左侧竖条是权重矩阵,对应于上图神经网络的权重
2.右侧蓝色方框的每一行都是一个单词的特征,把上图hidden layer linear neurons旋转90°就是其表示。
这里已经说明了如何从单词映射到特征向量。
输出层:
输入层使用softmax逻辑回归进行分类。
1.输出层输出的值累加和等于1,每一个神经元的值介于0~1
2.从单词特征向量和输出权重矩阵相乘得到softmax输出,由于输入特征向量是300维的,softmax输出预测的单词数量是和输入一致的,那么可以得出输出权重矩阵将是300*10000维的,这一过程如下:
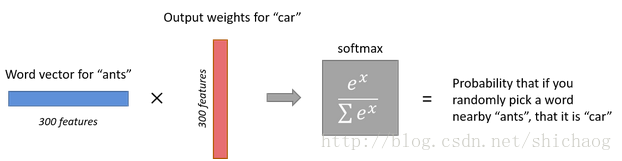
-
实践
- 1.数据下载
wiki英文数据下载:https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
wiki中文数据下载:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
- 2.数据处理
1.抽取文本 wiki数据内容比较复杂,所以在处理之前需要做一些预处理。通过 process_wiki.py 将wiki数据中的每一篇文章转为1行文本。
代码如下:
-
#--*-- coding:utf-8 --*--
-
-
from __future__
import print_function
-
-
import logging
-
import os.path
-
import six
-
import sys
-
-
from gensim.corpora
import WikiCorpus
-
#import WikiCorpus
-
-
if __name__ ==
'__main__':
-
program = os.path.basename(sys.argv[
0])
-
logger = logging.getLogger(program)
-
-
logging.basicConfig(format=
'%(asctime)s: %(levelname)s: %(message)s')
-
logging.root.setLevel(level=logging.INFO)
-
logger.info(
"running %s" %
' '.join(sys.argv))
-
-
# check and process input arguments
-
if len(sys.argv) !=
3:
-
print(
"Using: python process_wiki.py enwiki.xxx.xml.bz2 wiki.en.text")
-
sys.exit(
1)
-
inp, outp = sys.argv[
1:
3]
-
space =
" "
-
i =
0
-
-
output = open(outp,
'w')
-
wiki = WikiCorpus(inp, lemmatize=
False, dictionary={})
-
for text
in wiki.get_texts():
-
if six.PY3:
-
output.write(bytes(
' '.join(text),
'utf-8').decode(
'utf-8') +
'\n')
-
# ###another method###
-
# output.write(
-
# space.join(map(lambda x:x.decode("utf-8"), text)) + '\n')
-
else:
-
output.write(space.join(text) +
"\n")
-
i = i +
1
-
if (i %
10000 ==
0):
-
logger.info(
"Saved " + str(i) +
" articles")
-
-
output.close()
-
logger.info(
"Finished Saved " + str(i) +
" articles")
2.训练词向量
训练word2vec的开源代码非常多,使用的语言种类也很丰富,本实验使用gensim包训练词向量,其特点使用简便,训练速度快。
代码如下:
-
#!/usr/bin/env python
-
# -*- coding: utf-8 -*-
-
-
from __future__
import print_function
-
#导入日志配置
-
import logging
-
import os
-
import sys
-
import multiprocessing
-
#引入word2vec
-
from gensim.models
import Word2Vec
-
from gensim.models.word2vec
import LineSentence
-
-
if __name__ ==
'__main__':
-
program = os.path.basename(sys.argv[
0])
-
logger = logging.getLogger(program)
-
-
logging.basicConfig(format=
'%(asctime)s: %(levelname)s: %(message)s')
-
logging.root.setLevel(level=logging.INFO)
-
logger.info(
"running %s" %
' '.join(sys.argv))
-
-
# check and process input arguments
-
if len(sys.argv) <
4:
-
print(
"Useing: python train_word2vec_model.py input_text "
-
"output_gensim_model output_word_vector")
-
sys.exit(
1)
-
inp, outp1, outp2 = sys.argv[
1:
4]
-
-
model = Word2Vec(LineSentence(inp), size=
128, window=
5, min_count=
5,
-
workers=multiprocessing.cpu_count())
-
-
model.save(outp1)
-
model.wv.save_word2vec_format(outp2, binary=
False)
3.测试词向量
代码如下:
-
import gensim
#导入包
-
model = gensim.models.KeyedVectors.load_word2vec_format(
"wiki.en.text.vector", binary=
False)
-
model.most_similar(
'queen')
#测试相关词
-
model.similarity(
"woman",
"man")
#测试次间距
Word2Vec 参数:
-
min_count
model = Word2Vec(sentences, min_count=10) # default value is 5
在不同大小的语料集中,我们对于基准词频的需求也是不一样的。譬如在较大的语料集中,我们希望忽略那些只出现过一两次的单词,这里我们就可以通过设置min_count参数进行控制。一般而言,合理的参数值会设置在0~100之间。
-
size
size 是词向量维度
model = Word2Vec(sentences, size=200) # default value is 100
-
workers
workers参数用于设置并发训练时候的线程数,不过仅当Cython安装的情况下才会起作用:
model = Word2Vec(sentences, workers=4) # default = 1 worker = no parallelization
参考文献:
1.https://blog.csdn.net/shichaog/article/details/72848502
2.https://www.cnblogs.com/Climbing-Snail/p/7729795.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









