







需求
需求是根据短句查询后,不分词全包含(类似mysql的like)的语句要在最上边,其次是分词后的数据全包含的排在后边,然后是包含部分分词的数据,最后这三类数据要根据时间倒叙,自带的评分机制无法满足需求,所以使用function_score 自定义结果的评分:
创建索引
用到了ik分词器
PUT /robot1018
{
"settings" : {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "3",
"max_result_window": "10000000",
"analysis": {
"filter": {
"my_synonyms": {
"type": "synonym",
"synonyms_path": "synonyms/my_synonyms1.txt",
"updateable": "true"
},
"my_stopwords": {
"type": "stop",
"updateable": "true",
"stopwords_path": "stops/my_stopwords1.txt"
},
"my_pinyin": {
"ignore_pinyin_offset": "true",
"keep_joined_full_pinyin": "true",
"lowercase": "true",
"keep_original": "false",
"keep_first_letter": "false",
"keep_separate_first_letter": "false",
"type": "pinyin",
"keep_none_chinese": "false",
"limit_first_letter_length": "50",
"keep_full_pinyin": "true"
}
},
"analyzer": {
"pinyin_ik_max_word_analyzer": {
"filter": [
"my_pinyin"
],
"type": "custom",
"tokenizer": "ik_max_word"
},
"pinyin_ik_smart_analyzer": {
"filter": [
"my_pinyin"
],
"type": "custom",
"tokenizer": "ik_smart"
},
"synonym_stop_ik_smart_analyzer": {
"filter": [
"my_stopwords",
"my_synonyms"
],
"tokenizer": "ik_smart"
}
}
},
"number_of_replicas": "3"
}
},
"mappings": {
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"guid": {
"type": "keyword"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"question": {
"type": "text",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyin_ik_max_word_analyzer",
"search_analyzer": "pinyin_ik_smart_analyzer"
},
"question_text": {
"type": "keyword"
}
},
"analyzer": "ik_smart",
"search_analyzer": "synonym_stop_ik_smart_analyzer"
}
}
}
}
}
由于match_phrasa 查询会自动过滤标点符号,所以在question下加了个question_text字段 类型为keyword 不分词,用于通过 wildcard 过滤第一层的全匹配条件
例如:
"match_phrase": {
"question": {
"query": "供暖申请",
"slop": 0
}
}
查询的结果集中 会出现 “个人能否申请市政供暖?申请市政供暖条件及流程?“的结果,客户觉得这种不是全匹配的,所以我用wildcard 过滤全匹配的,也有说修改ik源码的,可自行尝试那种方法。
查询语句
GET robot1020/_search
{
"from": 0,
"size": 30,
"query": {
"function_score": {
"query": {
"bool": {
"adjust_pure_negative": true,
"must": [
{
"match": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?",
"minimum_should_match": "1",
"max_expansions": 50
}
}
}
]
}
},
"functions": [
{
"filter": {
"wildcard": {
"question.question_text": "*老小区后期申请市政供暖交换站选址安装有无相关要求?*"
}
},
"weight": 2
},
{
"filter": {
"match_phrase": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?",
"slop": 0
}
}
},
"weight": 2
},
{
"filter": {
"match_phrase": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?",
"slop": 4
}
}
},
"weight": 2
},
{
"filter": {
"match_phrase": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?",
"slop": 10
}
}
},
"weight": 2
},
{
"filter": {
"match": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?",
"minimum_should_match": "2"
}
}
},
"weight": 2
},
{
"filter": {
"match": {
"question": {
"query": "老小区后期申请市政供暖交换站选址安装有无相关要求?"
}
}
},
"weight": 2
}
],
"boost_mode": "replace"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
},
{
"create_time": {
"order": "desc"
}
}
],
"track_total_hits": 2147483647,
"_source": [
"question",
"create_time"
]
}
每满足一个条件评分都会乘以2,所以全部满足filter条件的话评分是所有过滤方法里的weight 乘积,这样就实现了需求,也可以多些几个filter过滤,把结果集分的更细一些
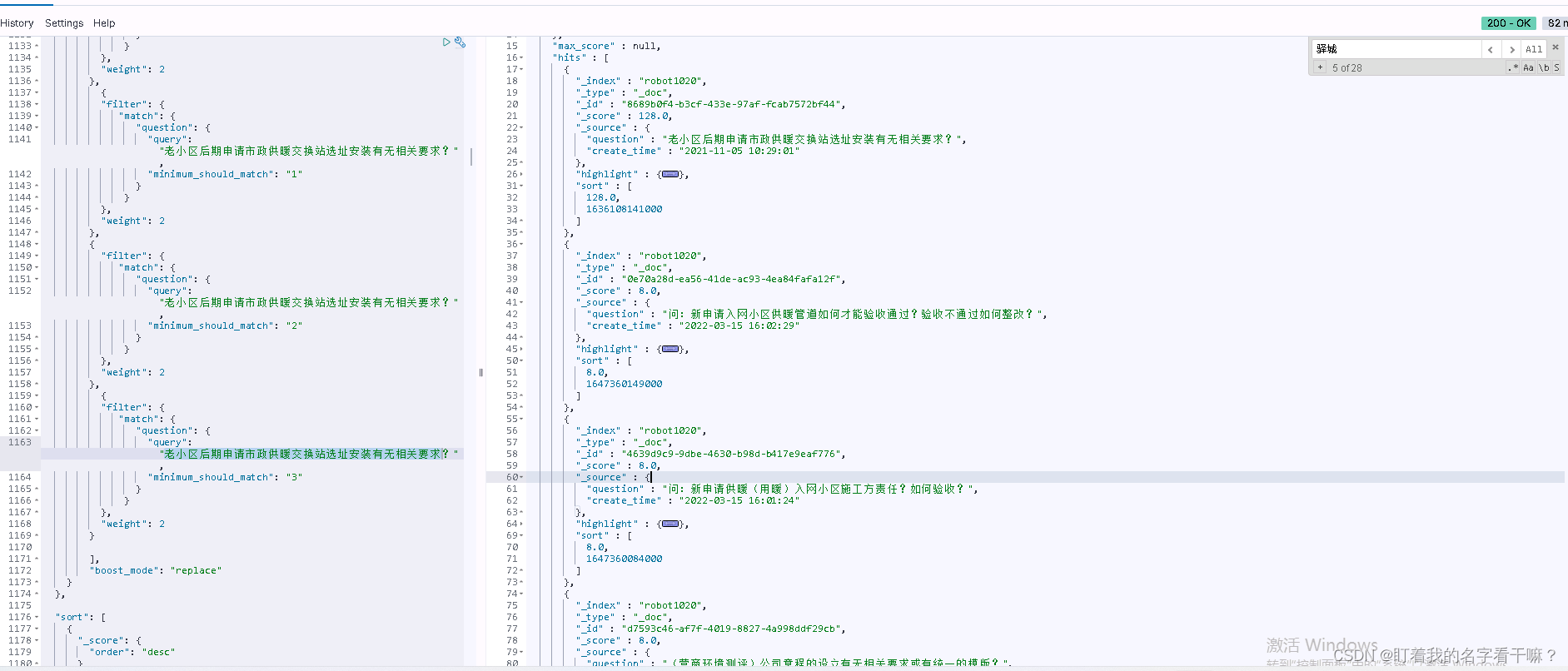
结果满足预期,问题解决
另外 boost_mode : replace 指的是 用自己的函数的得分替换掉原先的评分,默认是 multiply (与原评分相乘)
其他相关的参数含义 都很容易搜到














 5354
5354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









