







PSA论文笔记:Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
Abstract
- 切入点
由于训练模型只能分割目标的局部有判别力的区域,而不是完整的目标,因此可以尝试将这种局部响应传播到同一语义类别的区域 - 方案
本文提出一种AffinityNet,用来预测图像中相邻坐标像素对之间的语义相似性,语义的传播通过随机游走策略来实现
Introduction
问题描述
使用图像级标签监督学习语义分割明显是一个病态问题,因为图像级标签仅表示某个对象类别的存在,而没有学习分割所必需的目标位置和形状信息。
常用方法
- 惯用方法
关于定位线索的获取有一个常用的方法是生成类激活映射CAM,能够对目标的局部判别区域突出显示,因此通常被作为种子用于传播到目标完整区域 - 基于上述思想的优化
为了能够根据种子得到精确的目标区域,以前的方法通过采用超像素、视频动作以及类不可知的显著性检测方法来获取目标形状相关的信息进行优化,但是这些方法可能需要额外的数据样本和监督信息或者现成的分割技术,并没有充分利用深度神经网络的表征学习 - 本文提出的方法
(1) 概述
本文提出一种方法来补偿目标形状的信息,不用额外的数据及监督信息。该框架的关键元素就是AffinityNet。AffinityNet的输入输出分别是原始图像和图像中相邻坐标像素对的语义相似度
(2) 具体流程
根据给定的图像和生成的CAM,首先建立一个邻域图,其中每个像素都在一定半径内与其邻域相连,通过AffinityNet估计图中连通像素对的语义相似度。针对每一个类别,CAM中稀疏的激活区域通过随机游走策略传播到周围语义相同的区域,并对传播到其他语义类别的区域进行处罚。这种语义扩散对CAMs区域起到了很大的修正作用。本文利用这个过程来进行训练,通过获取的每个像素位置与CAM对应类标签的关联性合成像素级的分割标签。生成的分割标签用于训练分割模型。
(3) 方案依据
还有一个问题未解决,即如何再没有额外数据及监督信息的情况下学习AffinityNet?我们可将生成的初始CAM作为监督信息的来源。尽管CAM的定位区域十分粗糙,不能直接用于分割,但是我们发现CAM的局部正确性为小的图像区域语义相似度的判断提供了依据。为生成可靠的标签,我们忽视CAM中低激活分数的区域,只保留高置信度的目标和背景区域。例如,在图像CAM高置信度区域中取一对相邻坐标的像素,若他们属于同一类别则标记为1,否则为0。
(4) 整体思路
A. 利用训练图像生成CAM并用于生成语义相似度标签(该标签用于训练AffinityNet);
B. 利用训练好的AffinityNet对每张图像的邻域图计算语义相似度矩阵,利用随机游走策略对CAM进行优化,生成像素级标签;
C. 生成的像素级标签用于训练分割网络
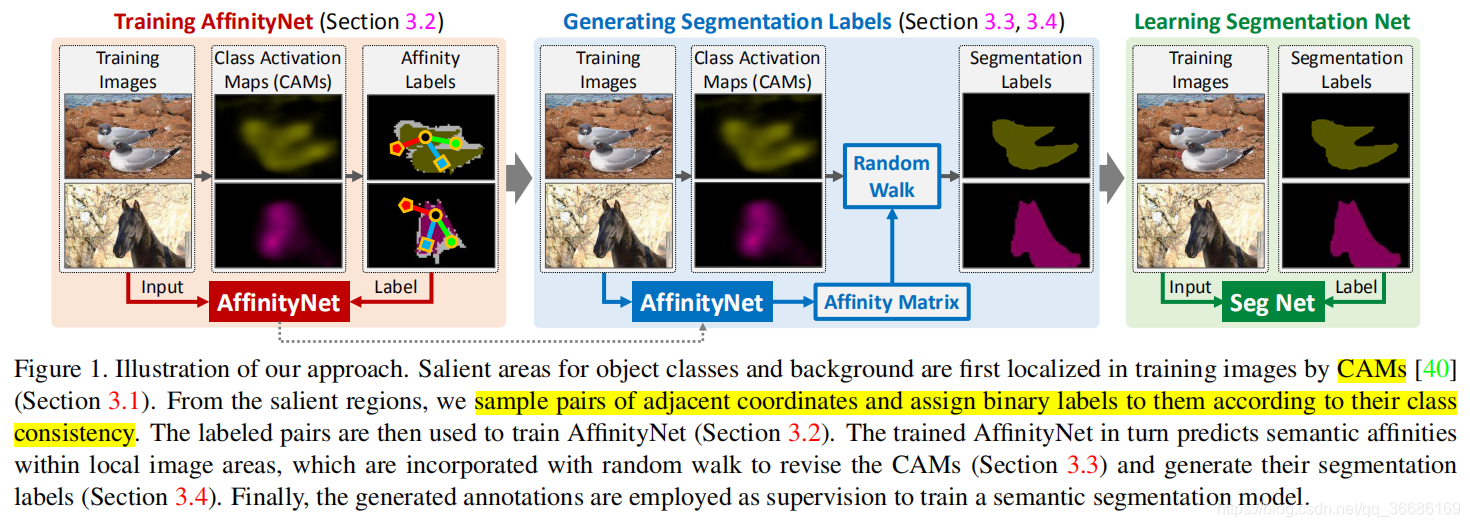
贡献
- 提出AffinityNet仅通过图像级标签预测像素级别的语义相似度
- 不像以往的文献一样依赖于现成的技术,通过端到端训练AffinityNet利用表征学习
Related Work
- 弱监督的不同形式:边界框标注、简笔标注、点标注、图像级标注
- 图像级标签的语义分割
直接利用图像级标签训练分割网络,性能较差
利用生成的CAM作为分割种子,结合超像素、分割建议和视频动作等有助于估计目标形状的额外的监督信息以及现成的无监督技术,生成像素级标注
Proposed Method
整个框架基于3个深度神经网络:
- 计算CAM
- AffinityNet
- 分割模型
计算CAM
CAM在该框架中发挥着重要作用,是我们训练AffinityNet的监督信息的来源
架构为典型的分类网络,全局池化层后连全连接层,利用只含图像级标签的数据训练
本文中计算两个CAM,一个针对目标Mc,一个针对背景Mbg

学习AffinityNet
目的:预测训练图像中相邻坐标的像素对的类不可知的语义相似性。预测得到的相似性被用于随机游走策略,作为生成的CAM向周围传播相同语义信息的迁移概率,由此提高了CAM的质量
细节:考虑到计算效率,AffinityNet用于预测卷积特征映射,其中一对特征向量之间的语义相似度是由他们之间的L1距离决定的
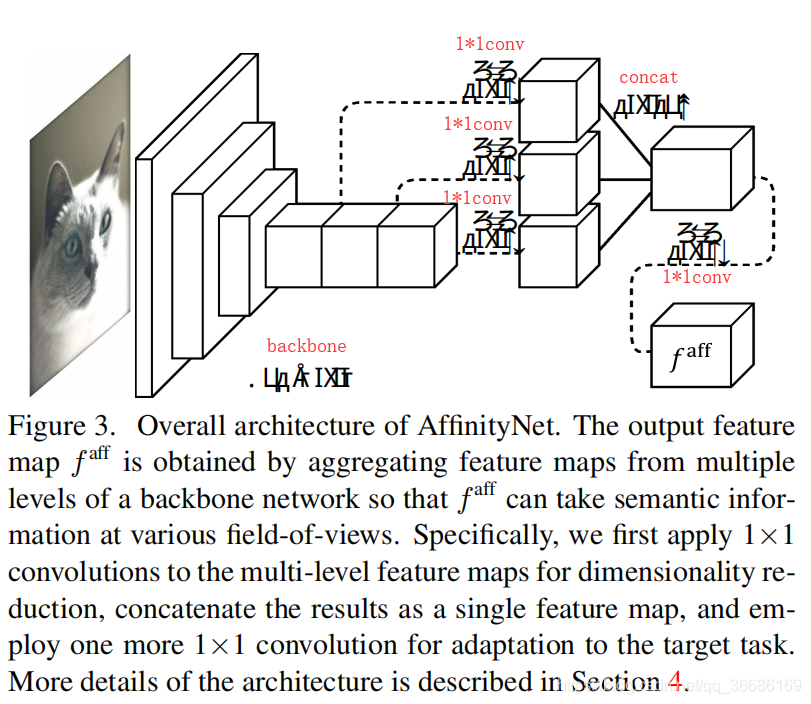
- 生成语义相似度标签
基本思想:从生成的CAM中识别可靠的目标区域和背景区域,并仅从这些这些区域中提取样本进行训练这样就可以可靠地确定一对采样坐标点之间的语义等价性
细节:为估计目标区域的可靠性,调节参数扩大Mbg的值,使得背景分数来支配CAM中目标的不显著激活值。当该位置的类别k激活分数大于其他任一类别的激活分数及放大的背景分数使,可认为该位置坐标属于k类别。应用dense CRF进行优化,并按上述方法获取对应类别的置信区域。此外,在相反的设定下(即减小Mbg),可以按同样的方式确定背景的置信区域。剩余区域则被设为中性的。举例如下图4(a)
分配标签:可根据每个置信区域的类别标签为图像中相邻的像素对分配一个二进制的语义标签。若两个像素属于同一类别,则记为1,不同类别则记为0,若像素对中至少有一个为中性的,则忽略该像素对,如图4(b),这样我们则可获得足够多的训练样本。
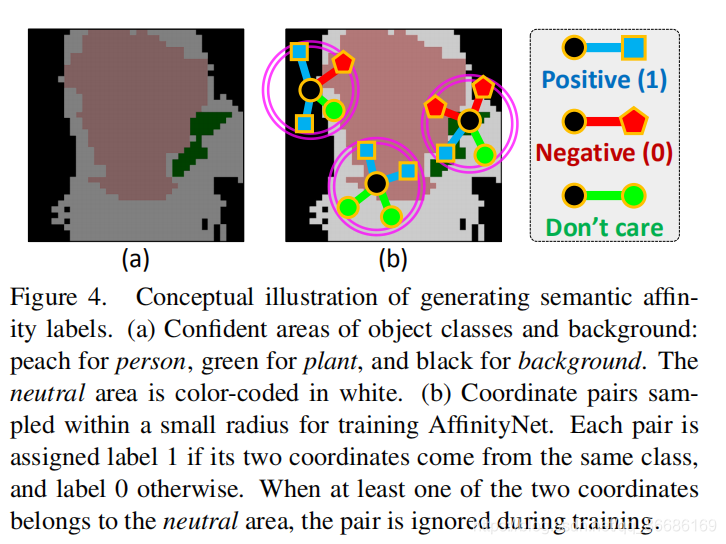
- 训练AffinityNet
AffinityNet以梯度下降的方式训练。考虑到缺乏上下文信息和计算量两个因素,样本提取的过程中只考虑充分相邻的像素对。因此由一个像素对组成的训练样本用P表示如下
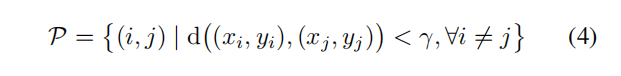
其中d(,)代表欧式距离,γ代表搜索半径用来对像素对之间的距离进行约束
然而,由于类不平衡问题,直接从P学习AffinityNet是不可取的。在P中,类别分布明显偏向于正分布,因为负对仅在目标边界附近采样。并且在正对的子集中,背景对的数目明显大于目标对,因为在许多照片中背景区域大于目标区域。为了解决这个问题,我们将P分为三个子集,首先将P分为正对和负对的两个子集:
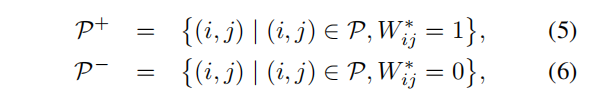
然后将正对子集P+分为目标对P+fg和背景对P+bg。分别对每个子集计算交叉熵损失,汇总得到综合的AffinityNet的损失函数。注意AffinityNet决定了两个相邻坐标之间的类一致性,而不清楚它们的类别。但这种类不可知的方案使得AffinityNet学习一种更通用的表示,可以在多个目标类和背景之间共享,并且显著地扩大了每个类的训练样本集。 - 利用AffinityNet修正CAM
训练后的AffinityNet用于修正训练图像的CAM。由AffinityNet预测的局部语义相似度被转换成转移概率矩阵,使得随机游走策略能够感知图像中的语义边界,并促使它在这些边界内扩散激活值。实验结果表明,带有语义转换矩阵的随机游走策略可以显著提高CAMs的质量,生成准确的分割标签。
随机游走的转移概率矩阵T按以下公式计算
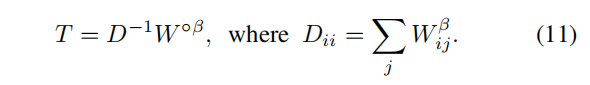
通过T的随机游走,并将T与CAM相乘,则实现了一次语义传播过程。然后通过迭代训练重复这个语义传播过程,得到优化后的CAM - 学习一个语义分割网络
Experiments
- PASCAL VOC2012数据集用于验证
- mIoU VOC2012数据集 test 63.7
- 对比实验
通过随机游走策略学习AffinityNet,生成的分割标注的质量显著提升


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









